初印象:dropout通过随机的将一些输出置为零 来增强学习性能
实现dropout的难点在于 如何生成mask
使用情况: 在深度学习中 模型参数太多 训练样本太少 训练出来的模型容易产生过拟合
实际执行:在每个训练批次中 忽略一半的特征(让一半的隐藏层的节点为0) 相当于给模型学习增加难度 降低模型的学习力 从而缓解过拟合问题
最后输出特征的大小不变 只不过有些位置被置为0
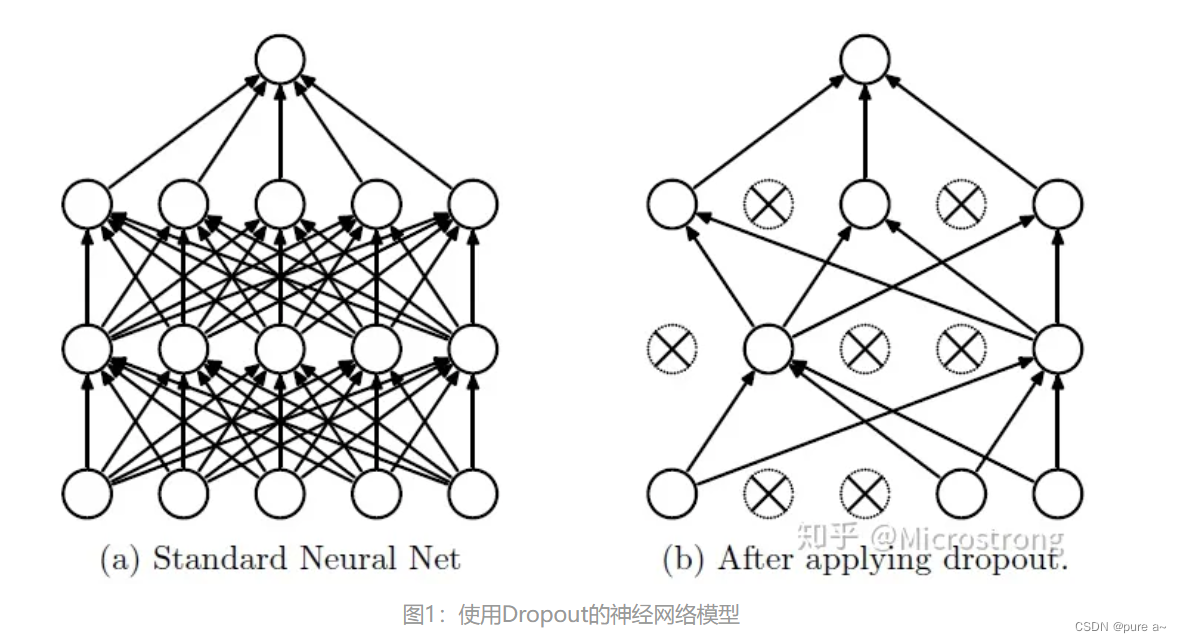
问题 dropout如何进行反向传播(置为0部分的梯度不更新?) 应该是 置为0 部分的神经元被视为删除 这部分就不会再继续进行更新了? 神经元置为0表示的是相应的参数没用了 为什么不直接采用一个小的神经元呢?
恢复被删除的神经元?
(没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)
参数保留问题 参数更新问题
为了理解dropout是对哪里进行筛选 回去学习了一下感知机
感知机说明
感知机的输入是一个样本的特征们 每个感知机用于区分一个特征 drop是将感知机选择性的扔掉 所以选择性的不用某些特征
dropout是针对每一层进行 对隐层的某些输出进行选择性的丢弃
**对向量进行缩放? 主要是 保障测试神经元和训练神经元的数据量一致 缓解测试的时候输出不稳定问题(具体解释来说,在训练过程中 选择了一些特征进行丢弃 但是在测试的时候 用上了所有的特征 这会导致测试结果的不稳定性 为了让二者保持平衡 所以在参数部分要乘以一个缩放因子 来保证相同的权重)
dropout缩放参照文章
dropout对应的计算公式
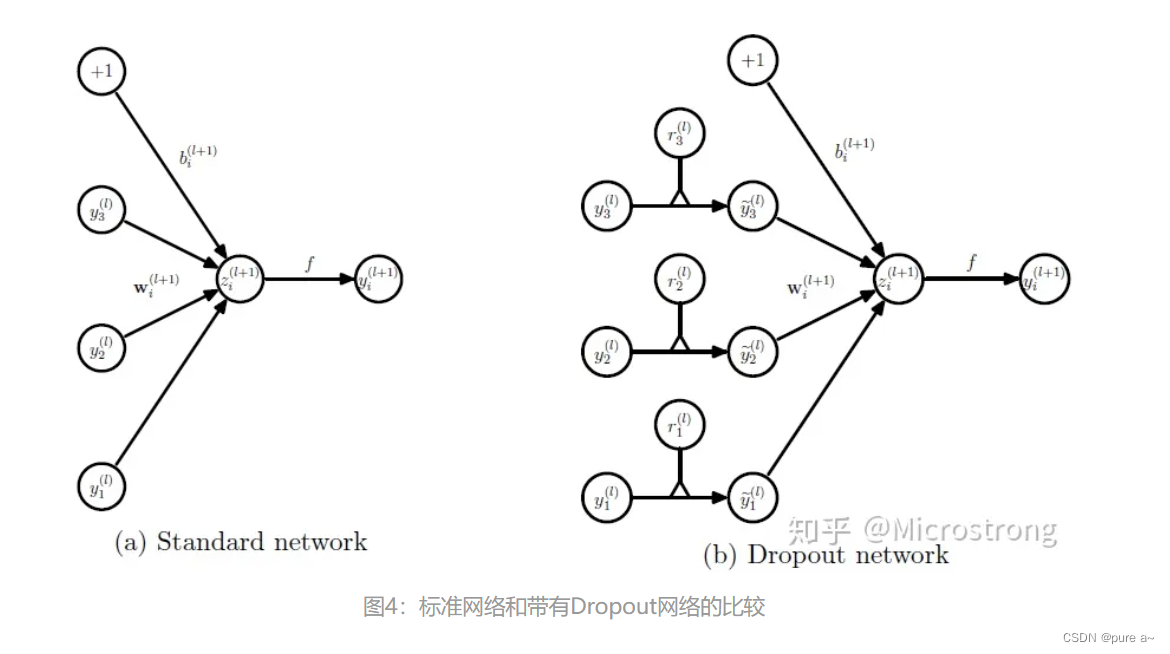

可以直观的看到 就是将一些中间层的特征置为0 让一部分感知机无法进行更新
所有层都进行dropout还是只有部分?