数据准备
首先使用的是make_blobs函数,用来生成数据集,make_blobs函数的第一个参数为n_samples,这个参数可以设置为一个整数或者是array-like也就是类似列表的参数,如果这里输入的整数类型则就是产生对应数量的样本,默认值是100,程序中设置为了100表明生成100个数据集;参数n_features表示样本的特征维数,这里默认是2,程序中没有给出就是表示有2个特征;参数noise是表示向产生的数据集中添加高斯噪声,默认是没有的但是程序中设置的是0.25;random_state是随机数种子,保证实验结果的可重现性。这个函数的第一个返回值为样本数据,第二个返回参数为该样本数据的标签值。
# two_moons数据集
x, y = make_moons(n_samples=100, noise=0.25, random_state=3)
模型训练
生成完实验所需要的数据集之后,分别创建了两个列表,一个列表中存放优化方法,包括adam和sgd两种,另一个列表中存放着激活函数,包括logistic、tanh和relu。然后对使用MLPRegressor生成一个MLP分类器,也就是多层感知机的分类器,在这里使用的是MLPClassifier函数来生成一个指定的MLP分类器,这个函数的参数包括hidden_layer_sizes,也就是隐含层的相关设置;slover这个是权重优化的求解器,可选值包括lbfgs、sgd和 adam,在默认情况下是adam;activation是激活函数,可选值有identity,logistic,tanh以及relu,默认值为relu;max_iter是最大的迭代次数,默认值为200。
代码中的多层神经网络是含有两层隐含层的神经网络,每一层有10个神经元,然后分别使用列表中的两种优化函数和激活函数的笛卡尔积,也就是两两分别组合对数据集进行测试,在matplotlib中显示出两种优化方法和三种激活函数对loss曲线的影响。
mlp = MLPRegressor(max_iter=300,
solver=opt, # 可选 adam,lbfgs,sgd。 其中lbfgs不支持loss_curve_
activation=act_fun, # 激活函数, identity,logistic, tanh, relu
hidden_layer_sizes=[10, 10],# [10,10]包含两个隐层,每个隐层包含10个隐单元
random_state=0, verbose=False)
结果分析
结果如下图所示
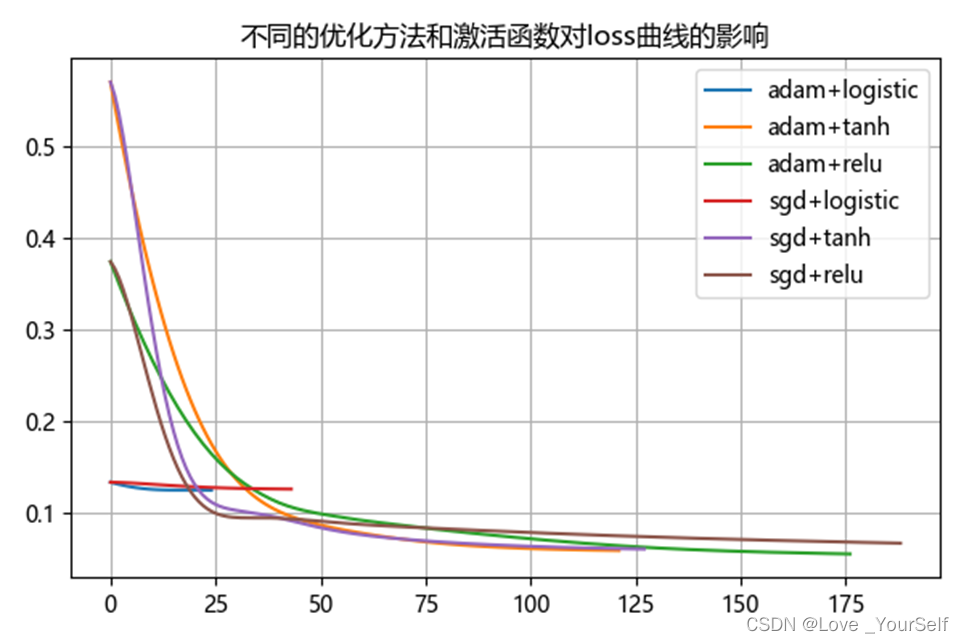
(1)分类器的损失函数的曲线一般呈现出逐步下降的趋势,下降的趋势先快后慢,等下降到一定的数值之后就会处于收敛的状态,在收敛的状态下loss损失函数的值基本趋于一个稳定的数值,变化的幅度很小几乎处于不变的状态。收敛的含义就是loss函数的值基本趋于稳定,模型的性能达到该方式下的最优状态,一般也就是loss函数的值取到了最小,在此数据集在此方式下的优化过程结束。
(2)从实验结果上看adam和tanh的组合下收敛的情况最好,因为这两个组合的收敛的速度最快同时收敛时loss函数的值能取到最小。损失函数是值实际值与预测值之间的不一致程度,也不一定就是损失值越小越好,还要考虑算法收敛的快慢,如果一个算法优化之后的损失值比另一个算法优化后的损失值小,但是所耗费的时间要比它长的多,在这种情况下就会偏向于选择时间较快同时损失函数的值相差不大的优化方法。还有一种情况是出现了过拟合现象,导致训练集上的损失函数的值为0也就是所有的预测值和实际值都相等,但是对测试集上的数据预测效果不好,同样也不是一种好的优化方法。
(3)对测试集的损失函数也有意义但是一般意义不太大,它可以通过查看测试集的loss和训练集的loss函数值来评判训练模型的状况,如果训练集loss函数下降而测试集的loss函数收敛说明这个训练模型很可能出现了过拟合现象;如果测试集的loss函数值不断增大说明数据集可能出现了问题。所以测试集的loss函数值也有意义。
(4)分类器的性能评价时一般使用训练集的loss_curve和测试集的accuracy_curve来评价,因为loss函数是值测试值和实际值之间的一致程度,可以通过优化这个loss函数的值来不断的调整训练模型的参数值,使loss函数的值不断减小以使训练模型的预测性能不断提高。这里的loss函数一般是非线性的函数,可以使用梯度下降的函数进行不断优化,寻找到loss函数最优解,所以对训练集更有效;准确率一般是指实际值和预测值的一致率,也就是预测正确的值除以整个预测的数量,所以对于测试集更有效。