目录
1、numpy
为什么要用numpy
Python中提供了list容器,可以当作数组使用。但列表中的元素可以是任何对象,因此列表中保存的是对象的指针,这样一来,为了保存一个简单的列表[1,2,3]。就需要三个指针和三个整数对象。对于数值运算来说,这种结构显然不够高效。Python虽然也提供了array模块,但其只支持一维数组,不支持多维数组(在TensorFlow里面偏向于矩阵理解),也没有各种运算函数。因而不适合数值运算。NumPy的出现弥补了这些不足
(——摘自张若愚的《Python科学计算》)
1.1、创建 numpy.array
1.1.1、常规创建 numpy.array 的方法
import numpy as np
# 常规创建方法
a = np.array([2,3,4])
b = np.array([2.0,3.0,4.0])
c = np.array([[1.0,2.0],[3.0,4.0]])
d = np.array([[1,2],[3,4]],dtype="float") # 指定数据类型, numpy中默认类型为float
1.1.2、其他创建 numpy.array 的方法
import numpy as np
# 创建全零数组
np.zeros(10) # array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
np.zeros(10, dtype=float) # array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
np.zeros((3, 5)) # array([[ 0., 0., 0., 0., 0.],
# [ 0., 0., 0., 0., 0.],
# [ 0., 0., 0., 0., 0.]])
np.zeros(shape=(3, 5), dtype=int) # array([[0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0]])
# 创建全一数组
np.ones(10) # array([ 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
np.ones((3, 5)) # array([[ 1., 1., 1., 1., 1.],
# [ 1., 1., 1., 1., 1.],
# [ 1., 1., 1., 1., 1.]])
# 创建指定值数组
np.full((3, 5), 666) # array([[666, 666, 666, 666, 666],
# [666, 666, 666, 666, 666],
# [666, 666, 666, 666, 666]])
np.full(fill_value=666, shape=(3, 5)) # array([[666, 666, 666, 666, 666],
# [666, 666, 666, 666, 666],
# [666, 666, 666, 666, 666]])
# 创建arange数组
np.arange(0, 10) # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(0, 20, 2) # array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
np.arange(0, 1, 0.2) # array([ 0. , 0.2, 0.4, 0.6, 0.8])
# 创建等差数列
np.linspace(0, 20, 10) # array([ 0. , 2.22222222, 4.44444444, 6.66666667, 8.88888889, 11.11111111, 13.33333333, 15.55555556, 17.77777778, 20. ])
np.linspace(0, 20, 11) # array([ 0., 2., 4., 6., 8., 10., 12., 14., 16., 18., 20.])
np.linspace(0, 1, 5) # array([ 0. , 0.25, 0.5 , 0.75, 1. ])
1.1.2、其他创建随机数 random
import numpy as np
# 创建随机整数
np.random.randint(0, 10) # [0, 10)之间的随机整数
np.random.randint(0, 10, 10) # array([2, 6, 1, 8, 1, 6, 8, 0, 1, 4])
np.random.randint(0, 1, 10) # array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
np.random.randint(0, 10, size=10) # array([3, 4, 9, 9, 5, 2, 3, 3, 2, 1])
np.random.randint(0, 10, size=(3,5)) # array([[1, 5, 3, 8, 5],
# [2, 7, 9, 6, 0],
# [0, 9, 9, 9, 7]])
np.random.randint(10, size=(3,5)) # array([[4, 8, 3, 7, 2],
# [9, 9, 2, 4, 4],
# [1, 5, 1, 7, 7]])
# 创建随机种子
np.random.seed(666)
np.random.randint(0, 10, size=(3, 5)) # array([[2, 6, 9, 4, 3],
# [1, 0, 8, 7, 5],
# [2, 5, 5, 4, 8]])
np.random.seed(666)
np.random.randint(0, 10, size=(3,5)) # array([[2, 6, 9, 4, 3],
# [1, 0, 8, 7, 5],
# [2, 5, 5, 4, 8]])
# 创建随机小数
np.random.random() # (0, 1)之间的随机小数
np.random.random((3,5)) # array([[ 0.8578588 , 0.76741234, 0.95323137, 0.29097383, 0.84778197],
# [ 0.3497619 , 0.92389692, 0.29489453, 0.52438061, 0.94253896],
# [ 0.07473949, 0.27646251, 0.4675855 , 0.31581532, 0.39016259]])
# 正态分布数
np.random.normal() # 0.9047266176428719
np.random.normal(10, 100) # -72.62832650185376
np.random.normal(0, 1, (3, 5)) # array([[ 0.82101369, 0.36712592, 1.65399586, 0.13946473, -1.21715355],
# [-0.99494737, -1.56448586, -1.62879004, 1.23174866, -0.91360034],
# [-0.27084407, 1.42024914, -0.98226439, 0.80976498, 1.85205227]])
1.2、numpy.array 基本操作
1.2.1、numpy.array 的基本属性
import numpy as np
x = np.arange(10)
X = np.arange(15).reshape((3, 5))
# 查看维数
x.ndim # 1
X.ndim # 2
x.shape # (10,)
X.shape # (3, 5)
x.size # 10
X.size # 15
1.2.2、numpy.array 的数据访问
import numpy as np
x = np.arange(10)
X = np.arange(15).reshape((3, 5))
x[0] # 0
x[-1] # 9
X # array([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14]])
X[0, 0] # 0
X[0, -1] # 4
x # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
x[0:5] # array([0, 1, 2, 3, 4])
x[:5] # array([0, 1, 2, 3, 4])
x[5:] # array([5, 6, 7, 8, 9])
x[::2] # array([0, 2, 4, 6, 8])
x[1::2] # array([1, 3, 5, 7, 9])
x[::-1] # array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
X[:2, :3] # array([[0, 1, 2],
# [5, 6, 7]])
X[:2][:3] # 结果不一样,在numpy中使用","做多维索引
# array([[0, 1, 2, 3, 4],
# [5, 6, 7, 8, 9]])
X[:2, ::2] # array([[0, 2, 4],
# [5, 7, 9]])
X[::-1, ::-1] # array([[14, 13, 12, 11, 10],
# [ 9, 8, 7, 6, 5],
# [ 4, 3, 2, 1, 0]])
X[0, :] # array([0, 1, 2, 3, 4])
X[:, 0] # array([ 0, 5, 10])
1.2.3、numpy.array 合并和分割
import numpy as np
# numpy.array 的合并
x = np.array([1, 2, 3])
y = np.array([3, 2, 1])
np.concatenate([x, y]) # array([1, 2, 3, 3, 2, 1])
A = np.array([[1, 2, 3],
[4, 5, 6]])
np.concatenate([A, A]) # array([[1, 2, 3],
# [4, 5, 6],
# [1, 2, 3],
# [4, 5, 6]])
np.concatenate([A, A], axis=1)
# array([[1, 2, 3, 1, 2, 3],
# [4, 5, 6, 4, 5, 6]])
np.vstack([A, z]) # array([[ 1, 2, 3],
# [ 4, 5, 6],
# [666, 666, 666]])
B = np.full((2,2), 100)
np.hstack([A, B]) # array([[ 1, 2, 3, 100, 100],
# [ 4, 5, 6, 100, 100]])
# numpy.array 的分割
x = np.arange(10) # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
x1, x2, x3 = np.split(x, [3, 7]) # x1 array([0, 1, 2])
# x2 array([3, 4, 5, 6])
# x3 array([7, 8, 9])
x1, x2 = np.split(x, [5]) # x1 array([0, 1, 2, 3, 4])
# x2 array([5, 6, 7, 8, 9])
A = np.arange(16).reshape((4, 4)) # array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [12, 13, 14, 15]])
A1, A2 = np.split(A, [2]) # A1 array([[0, 1, 2, 3],
# [4, 5, 6, 7]])
# A2 array([[ 8, 9, 10, 11],
# [12, 13, 14, 15]])
A1, A2 = np.split(A, [2], axis=1) # A1 array([[ 0, 1],
# [ 4, 5],
# [ 8, 9],
# [12, 13]])
# A2 array([[ 2, 3],
# [ 6, 7],
# [10, 11],
# [14, 15]])
1.3、numpy.array 中的运算
import numpy as np
X = np.arange(1, 16).reshape((3, 5))
# 给定一个数组,让数组中每一个数加1
X + 1
# 给定一个数组,让数组中每一个数减1
X - 1
# 给定一个数组,让数组中每一个数乘以2
X * 2
# 给定一个数组,让数组中每一个数除以2
X / 2
# 给定一个数组,让数组中每一个数地板除2
X // 2
# 数学公式
np.abs(X)
np.sin(X)
np.cos(X)
np.tan(X)
np.arctan(X)
np.exp(X)
np.exp2(X)
np.power(3, X)
np.log(X)
np.log2(X)
np.log10(X)
# 矩阵运算
A = np.arange(4).reshape(2, 2)
B = np.full((2, 2), 10)
# 矩阵加法
A + B
# 矩阵减法
A + B
# 矩阵乘法
A.dot(B)
# 矩阵转置
A.T
# 求逆矩阵
np.linalg.inv(A)
1.4、numpy 中的聚合操作
注意:axis描述的是将要被压缩的维度
求和
np.sum
X = np.arange(16).reshape(4,-1)
np.sum(X) # 120
np.sum(X, axis=0) # array([24, 28, 32, 36])
np.sum(X, axis=1) # array([ 6, 22, 38, 54])
最小值
np.min
最大值
np.max
乘
np.prod
平均值
np.mean
中位数
np.median
百分比分位数
np.percentile
方差
np.var
标准差
np.std
1.5、numpy 中arg运算
import numpy as np
# 索引
x = np.random.normal(0, 1, 1000000)
np.argmin(x) # 886266
x[886266] # -4.8354963762015108
np.min(x) # -4.8354963762015108
# 排序和使用索引
x = np.arange(16)
np.random.shuffle(x) # array([13, 2, 6, 7, 11, 10, 3, 4, 8, 0, 5, 1, 9, 14, 12, 15])
np.sort(x) # array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
np.argsort(x) # array([14, 7, 12, 10, 5, 9, 8, 3, 2, 6, 4, 13, 11, 15, 0, 1])
1.6、numpy 中的比较和Fancy Indexing
1.6.1、Fancy Indexing
import numpy as np
x = np.arange(16)
# 取第四个元素
x[3] # 3
# 取4-10元素
x[3:9] # array([3, 4, 5, 6, 7, 8])
x[3:9:2] # array([3, 5, 7])
# 按索引取值
ind = [3, 5, 7]
x[ind] # array([3, 5, 7])
X = x.reshape(4, -1) # array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [12, 13, 14, 15]])
row = np.array([0, 1, 2])
col = np.array([1, 2, 3])
X[row, col] # array([ 1, 6, 11])
X[0, col] # array([1, 2, 3])
X[:2, col] # array([[1, 2, 3],
# [5, 6, 7]])
col = [True, False, True, True]
X[0, col] # array([0, 2, 3])
1.6.2、使用 numpy.array 的比较结果
import numpy as np
# 比较运算
x = np.arange(16)
# 统计 x <= 3 元素个数 count_nonzero 统计非零元素 x <= 3 是一个boolean 结果集
np.count_nonzero( x <= 3)
np.sum(x <= 3)
# 存在一个元素等于0
np.any(x == 0) # True
# 所有元素大于等于0
np.all(x >= 0) # True
# 找 3 < x < 10元素个数
np.sum((x > 3) & (x < 10)) # 6
# 找x 是偶数或者大于10 的元素个数
np.sum((x % 2 == 0) | (x > 10)) # 11
# 取反运算
np.sum(~(x == 0)) # 15
# 比较结果和Fancy Indexing
x < 5 # array([ True, True, True, True, True, False, False, False, False,
# False, False, False, False, False, False, False], dtype=bool)
x[x < 5] # array([0, 1, 2, 3, 4])
x[x % 2 == 0] # array([ 0, 2, 4, 6, 8, 10, 12, 14])
X[X[:,3] % 3 == 0, :] # array([[ 0, 1, 2, 3],
# [12, 13, 14, 15]])
2、机器学习基础概念
2.1、数据
著名的鸢尾花数据

- 数据整体叫数据集(data set)
- 每一行数据称为一个样本(sample)
- 除最后一列,每一列表达样本的一个特征(feature)
- 最后一列,称为标记(label)
第i行样本行写作为 X ( i ) X^{(i)} X(i),第i个样本第j个特征值 X j ( i ) X_j^{(i)} Xj(i),第i个样本的标记写作为 y ( i ) y^{(i)} y(i)
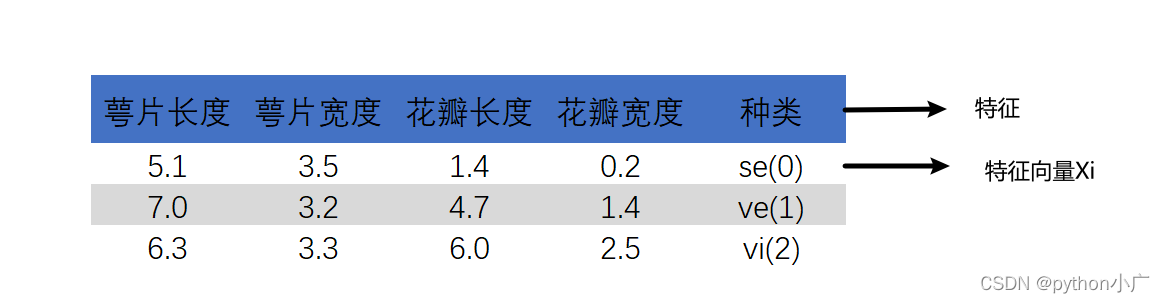
特征也可以很抽象,图像每一个像素点都是特征,28×28的图像有28×28=784个特征。
2.2、机器学习的基本任务
2.2.1、分类任务
在二分类的问题中,我们经常用 1 表示正向的类别,用 0 或 -1 表示负向的类别。
- 二分类任务
- 判断邮件是垃圾邮件;不是垃圾邮件
- 判断发放给客户信用卡有风险;没有风险
- 判断病患良性肿瘤;恶性肿瘤
- 判断某支股票涨;跌
- 多分类任务
- 数字识别
- 图像识别
- 判断发放给客户信用卡的风险评级
2.2.2、回归任务
- 结果是一个连续数字的值,而非一个类别
- 房屋价格
- 市场分析
- 学生成绩
- 股票价格
2.2.3、分类与回归的区别
- 输出不同
- 分类任务输出的是物体所属的类别,回归问题输出的是物体的值
天气可以分为:晴、阴、雨 三类,我们只知道今天及之前的天气,我们会预测明天及以后几天的天气情况,如明天阴,下周一晴,这就是分类;
每一天的天气温度,我们知道今天及以前几天的温度,我们就要通过之前的温度来预测现在往后的温度,每一个时刻,我们都能预测出一个温度值,得到这个值用的方法就是回归。
- 分类问题输出的值是离散的,回归问题输出的值是连续的
这个离散和连续不是纯数学意义上的离散和连续。
- 分类问题输出的值是定性的,回归问题输出的值是定量的
所谓定性是指确定某种东西的确切的组成有什么或者某种物质是什么,这种测定一般不用特别的测定这种物质的各种确切的数值量。
所谓定量就是指确定一种成分(某种物质)的确切的数值量,这种测定一般不用特别的鉴定物质是什么,
举个例子,这是一杯水,这句话是定性;这杯水有10毫升,这是定量。
- 目的不同
分类的目的是为了寻找决策边界,即分类算法得到是一个决策面,用于对数据集中的数据进行分类。
回归的目的是为了找到最优拟合,通过回归算法得到是一个最优拟合先,这条线可以最好的接近数据集中的各个点。
机器学习一般步骤
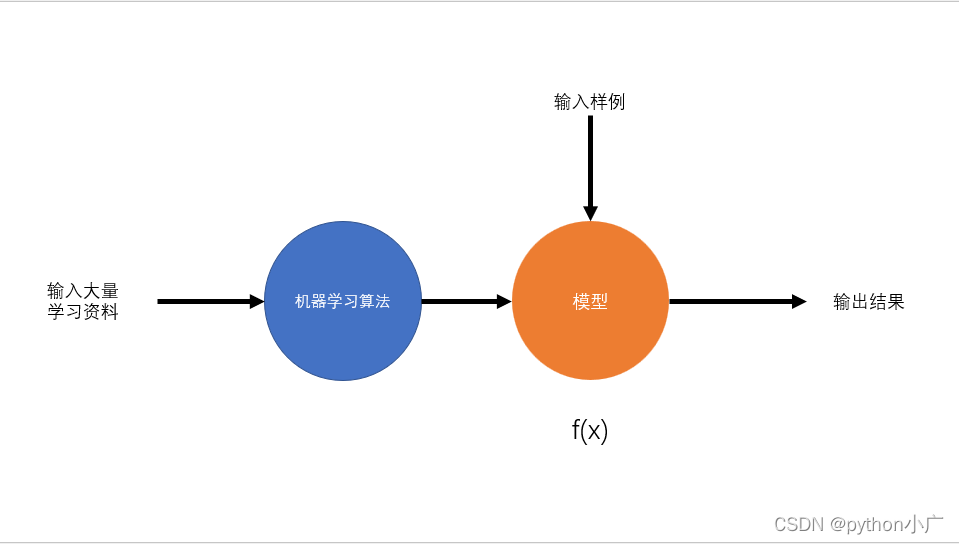
2.3、机器学习方法的分类
- 监督学习
给机器的训练数据拥有“标记”或者“答案”
- k近邻
- 线性回归和多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林
- 非监督学习
对没有“标记”的数据进行分类-聚类分析
1、主成分分析法 PCA - 半监督学习
一部分数据有“标记””或者“答案”,另一部分数据没有
通常都是使用无监督学习手段对数据做出来,之后使用监督学习手段做模型的训练和预测 - 强化学习
根据周围环境的情况,采取行动,根据采取行动的结果,学习行为方式
2.4、机器学习的其他分类
-
在线学习和批量学习(离线学习)
-
参数学习和非参数学习
- 参数学习
一旦学习到参数,就不再需要原来的数据集 - 非参数学习
不对模型进行过多假设,不等于没有参数