目录
文章目录
Traffic Control
要想在 IP 网络上承载具有 QoS(Quality of Service,服务质量保障)特性的实时业务并不容易,主要原因有 2 点:
- IP 协议是 “尽力而为“ 的,无法保证传输的可靠性。例如:突发流量容易导致的网络拥塞、增加转发时延、严重时还会丢包,从而导致上层业务质量下降甚至不可用。
- TCP 协议虽然是可靠传输曾协议,但对于实时业务来说,TCP 的 ACK 重传机制反而成为了一个限制。例如:时延敏感的实时业务不能接受重传所引入的延时。
要想解决这些问题最简单的思路就是增加网络带宽,让所有用户的流量都保证宽裕,但从网络建设成本的角度考虑这并不现实,所以才需要有 Traffic Control(流量控制)技术,使得投入更多财力的用户能够享有更好的网络。
Traffic Control 的基本实现原理
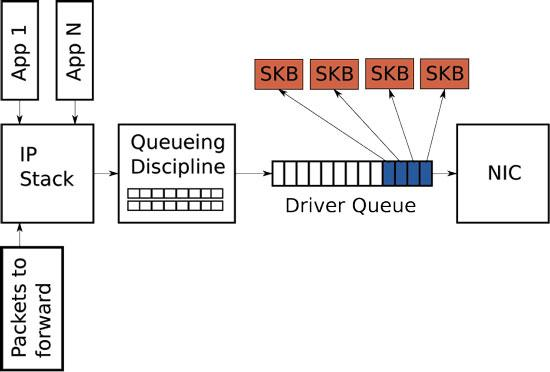
Traffic Control 技术实现的基本原理就是 Queue(队列),通过在网络设备(包括:主机网卡、交换机、路由器等)的 Ingress 和 Egress 处使用一系列的 Queues 来对数据报文进行排队,继而控制它们的发送优先顺序和速率。同时,还可以针对不同的 Queues 施加相应的 Policy(策略),实现更灵活的功能特性。
根据被控制的数据报文类型的不同,可以细分为以下 2 种 TC 场景:
- L2 Frame Traffic Control
- L3 Packet Traffic Control
在本文中,我们主要讨论的是第 2 种场景。
流量处理的三个层面
要想实现基于 Queues 的 Traffic Control,需要从 3 个不同的层面进行设计。
-
流量分类(Classifier):识别不同的 Packets(基于 Header)或 Flows(基于 IP 5-tuple),并将它们 INQUEUE 到相应的 Queues 中,以此实现流量的分类。
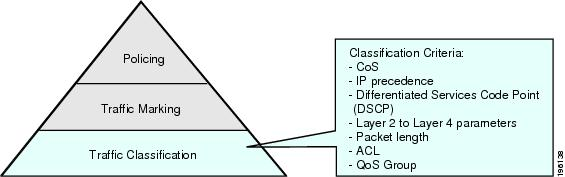
-
流量标记(Marker):根据用户业务类型的不同,Traffic Marker(应用程序或者网络设备)通过对 Packet 的 Header 进行修改(例如:修改 IPv4 Header 中的 ToS 字段),以此来标记出具有不同含义的 Packets。流量标记可以根据功能需求,在任意的网络节点中完成,再结合流量分类,共同实现 “可灵活定义的流量分类" 特性。
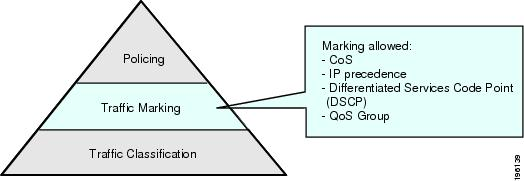
- 流量策略(Policier):在完成了流量的分类和标记之后,最终通过对相应的 Queues 施加 Policy 来实现流量控制,例如:Rate Limits。
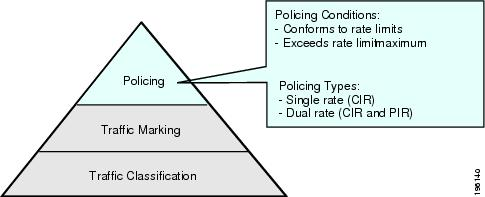
流量处理的实现模型
基于上述 3 个层面的考量,下图所示为一个常规的 Traffic Control 实现理论模型,描述了 Packets 从 Ingress 到 Egress 过程中所需要经历的流量处理功能模块。
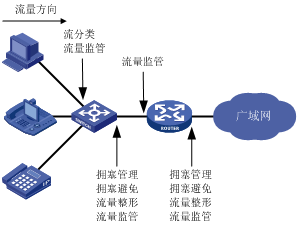
-
Ingress 流分类和标记:
- 对感兴趣的 Packets 进行标记(e.g. DSCP 优先级数值);
- 对不同匹配规则的 Packets 进行分类到不同的 Queues 上。
-
Ingress/Egress 流量监管:对 Ingress/Egress 流量进行监管,只放行合法数据,保护网络资源不受非法数据侵害。同时,当流量超出阈值时,应该采取限制措施。
-
Egress 拥塞避免:监控下游链路,当拥塞水位超过阈值时,应该主动丢弃报文,并通过调整 Queues 长度来缓解网络过载。可以通过实时监控网络资源(e.g. 队列或内存缓冲区)的使用情况来实现。
-
Egress 拥塞管理:当发生实际的拥塞时,所采取的策略:
- 带宽管理:将 Queue 的流量限制在特定的带宽内。当流量超过额定带宽时,超过的部分将被丢弃,防止个别用户的业务无限制地占用带宽。
- 接口限速:针对某个特定的网络接口设备的输出速率进行粗粒度的限制。
-
Egress 流量塑形:Queue 主动调整流量的输出速率,将超出速率的流量缓存到内存中,再根据实际情况发出。使流量能够比较平稳地传送给下游设备,避免不必要的报文丢弃和拥塞。

流量队列的常见类型
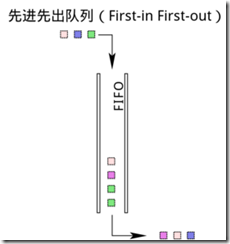
FIFO 队列
FIFO(先入先出)是最简单的队列类型,不考虑流量分类,Network Interface 总是以最大的速率顺序发出。
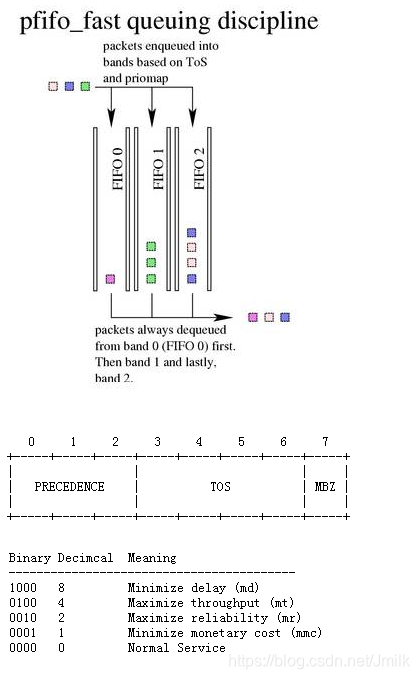
PFIFO_FAST 队列
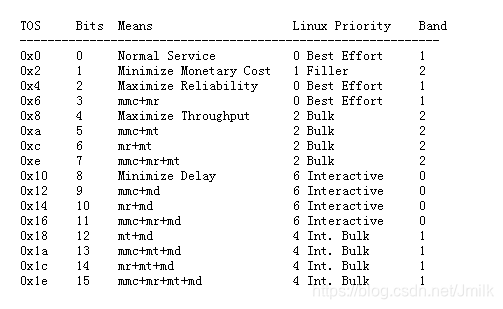
Classless Queuing Disciplines(无分类队列)默认为 PFIFO_FAST,是一种不把网络包分类的技术。PFIFO_FAST 根据网络包中的 TOS 对应的数字,在 TOS 的 priomap 中查看对应的 Band,不同的 Band 对应的不同的队列。
SFQ 队列
SFQ(Stochastic Fair Queuing,随机公平队列)对所有 IP Packets 都一视同仁,随机分配。有很多的 FIFO 的队列,TCP Session 或者 UDP Stream 会被分配到某个队列。数据包会 RoundRobin 的从各个队列中取出发送。这样一个 Session 就不会占据所有的流量。但不是每一个 Session 都具有一个队列,而是通过 Hash 算法,将大量的 Session 分配到有限的队列中。这样两个或若干个 Session 会共享一个队列,也有可能互相影响。因此 Hash 函数会经常改变,从而 Session 不会总是相互影响。

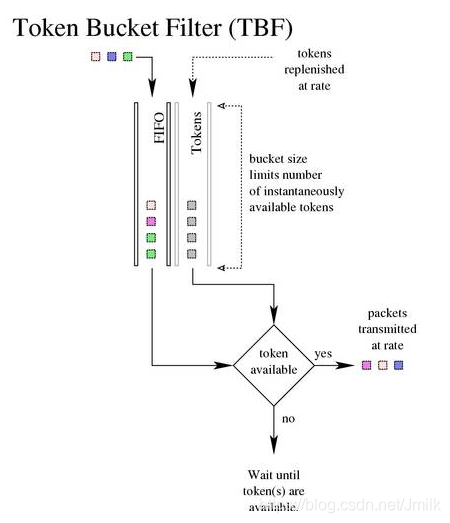
令牌桶队列
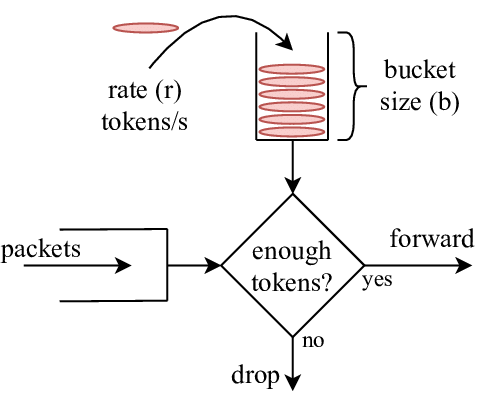
令牌桶队列(Token Bucket)实现了令牌桶算法,该算法的设计思路比较简单:
- 一个固定容量的 Bucket(桶)装着一定数量的 Tokens(令牌),Bucket 会以一定的 Rate(速率)生产 Tokens,知道装满。即:Bucket 的容量即 Tokens 数量的上限。
- 一个 Packet 对应一个 Token,进入到 Queue 中的 Packet 只有从 Bucket 中获得了 Token 之后才可以 DEQUEUE。
- Bucket 通过控制 Token 生成的 Rate,从而控制 Packet 出队的 Rate。
- 当没有 Packet 要出队时,Bucket 中的 Tokens 会累积起来,以应对一定程度的 Burst(突发)流量,突发时长 = 令牌桶容量 / (发送速率 - 令牌补充速率)。
可见,网络流量比较恒定的场景中适合使用较小的令牌桶,而经常有突发流量的网络则适合使用大的令牌桶。另外值得注意的是,当令牌桶中的令牌耗尽时,在不同的场景中应该提供额外的处理流程,例如:
- Traffic Policing(流量监管)场景:直接丢弃。
- Traffic Shaping(流量整形)场景:缓存等候。
Policing 和 Shaping 都可以对流量进行限制。区别在于 Shaping 能保存并延迟发送数据包,而 Policing 只会直接丢弃数据包。
在 Linux Kernel Traffic Control 中,令牌桶队列主要有 2 种:
- TBF(Token Bucket Filter,令牌桶队列):所有的网络包排成队列进行发送,但不是到了队头就能发送,而是需要拿到 Token 的包才能发送。Token 根据设定的速率(Rate)生成,所以即便队列很长,也会按照 Rate 进行发送。当没有包在队列中时,Token 还是以既定的速度生成,但是并非无限累积,而是到 Buckets 放满为止,篮子(buckets)的大小常用 burst/buffer/maxburst 参数来设定。Buckets 会避免下面这种情况:当长时间没有包发送的时候,积累了大量的 Token,突然来了大量的包,每个都能得到 Token,造成瞬间流量大增。
- HTB(Hierarchical Token Bucket,分层令牌桶队列):是最典型的 Classful Queuing Disciplines(分类队列),具有以下特性:
- Shaping:仅仅发生在叶子节点,依赖于其他的 Queue。
- Borrowing:当网络资源空闲的时候,借点过来为我所用。
- Rate:设定的速率。
- Ceil:最大的速率,与 Rate 之间的差值表示最多能向别人借多少。

Kernel Traffic Control
2001 年,在 Linux Kernel v2.4 版本中引入了 TC(Traffic Control)模块,作为一个内核级的流量控制器。其在上文中提到的基本实现原理的基础之上,还实现了一种以 Qdisc-Class-Filter 树状结构来对流量进行分层控制的机制。
随后,TC 由增加了 Classifier-Action Subsystem,可以根据 IP Packet 的 Header 内容进行 Classifier 并执行相应的 Action。这是一个 Plugin 系统,支持用户根据需求定义自己的 Classifier。
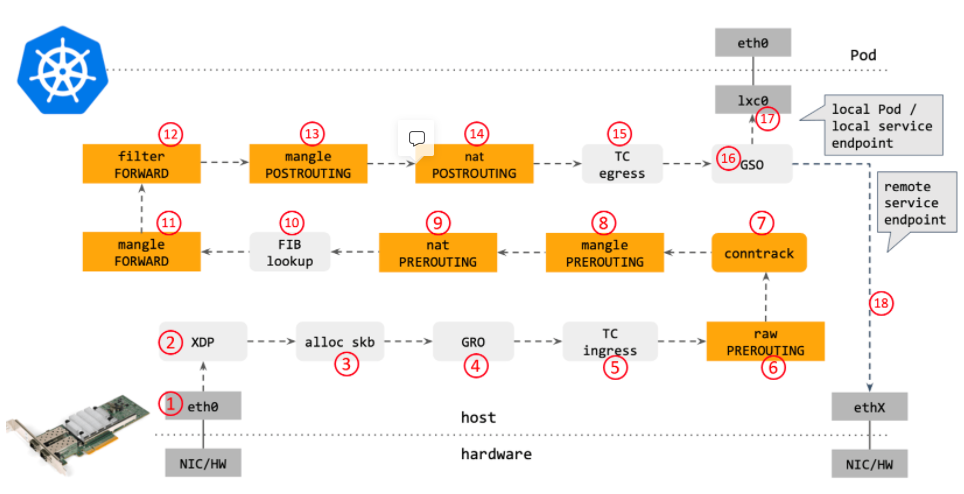
如下图所示,TC 模块位于 L3 Sub-system 的外边界,实际上属于 L2 Sub-system,针对某个具体的 Network Interface 生效。
- 收包时,IP Packets 先进入 TC Ingress(入方向)处理后,再进入 L3 Sub-system。
- 发包时,IP Packets 从 L3 Sub-system 确定了 Next Hop 之后,需要从先经过 TC Egress(出方向)的处理再发出。
Qdisc(队列规则)
Qdisc(Queue Discipline,队列规则)是一种 “可配置队列“ 实现,具有类型、规则、配置等信息。具有以下类型:
- Classless Qdiscs(无类别队列):无法对 Packets 进行分类。包括:PFIFO_FAST、SFQ、TBF(令牌桶过滤器)、ID(前向随机丢包)等队列类型。
- Classful Qdiscs(分类别队列):支持对 Packets 进行分类,需要结合 Class(流量控制类别)来完成分类。包括:HTB 等队列类型。
在 Linux 中,每个 Network Interface 都可以同时具有 Ingress Qdisc 和 Egress Qdisc。但 Ingress Qdisc 只能使用 Classless 类型,支持 Policing 和简单的 Shaping 特性。而 Egress 则可以使用 Classful Qdiscs,支持更多样化的流量控制特性。
Class(流量控制类别)
Class(流量控制类别)用于表示一个流量控制的分类,记录了流量控制的配置参数,用于关联到一个 Qdisc。
虽然 一个 Class 仅可以关联一个 Qdiscs,但 Class 被设计成树状结构,支持创建多个 Sub-classes(子类别)。所以 Class 理论上可以无限扩展,这样的设计使得 Linux 流量控制系统具有了极大的可扩展性和灵活性。
在一棵 Class Tree 中,根据层级的不同,可以分为:
- Root Class(根类别)
- Inner Class(内部类别)
- Leaf Class(叶子类别)
需要注意的是,一个 Qdisc 只能关联到与其具有相同队列类型的 Class。例如:HTB Qdisc 只能包含 HTB Class。

Filter(过滤器)
区别于 Class 用于表示流量控制的类别,Filter 才是实际上的流量分类器,可以直接关联到 Root Qdisc、Leaf Qdisc 或 Inner Class。Filter 由 Classifier 和 Policer 组成。其中,Policer 可以配置 2 个 Actions:当流量高于用户指定值时执行一种 Action,反之执行另一种 Action。
所有的 Egress 流量首先会进入 Interface 关联的 Root Qdisc,然后被 Root Qdisc 关联的 Filter 进行分类到不同的 Class 中执行其流量控制配置。
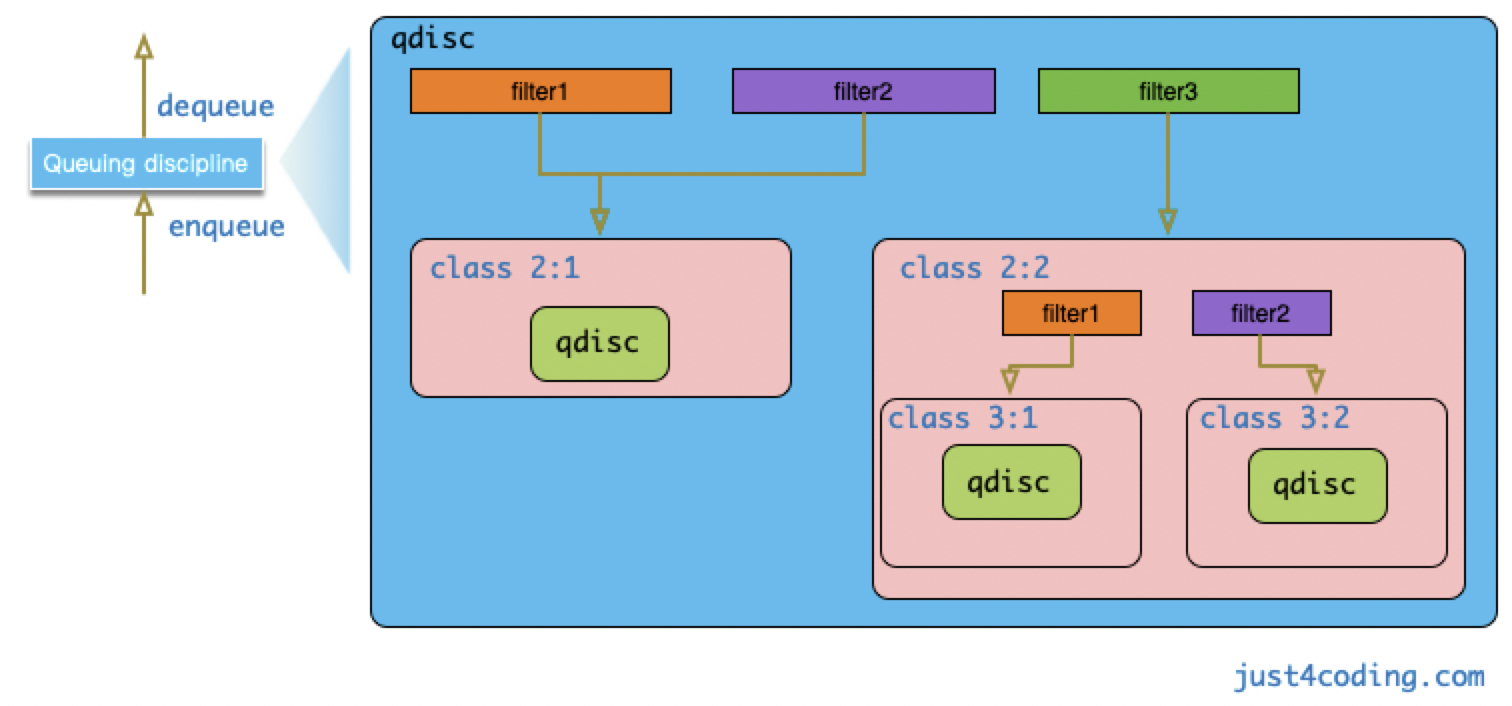
如果该 Class 还有 Sub-class,则继续根据其关联的 Filter 进行分类。
- 如果该 Sub-class 是 Inner Class,则 Filter 可以与 Inner Class 建立关联。
- 如果该 Sub-class 是 Leaf Class,则必须要关联 Qdisc,然后 Filter 才可以与 Qdisc 建立关联。
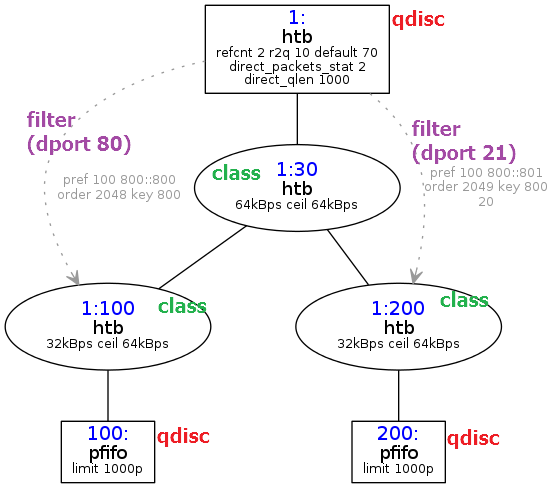
使用 tc CLI 进行流量控制的示例
常规配置流程示例
1. 创建队列
$ tc qdisc add dev eth0 root handle 1: htb default 11
- dev eth0:表示操作网卡 eth0;
- root:表示为 eth0 添加的是一个 Root Qdisc;
- handle 1::表示 Qdisc 的 Handle(句柄)为 1:;
- htb:表示 Qdisc 的类型为 HTB;
- default 11:是 HTB Qdisc 特有的参数,表示所有未分类的流量都将被分配给默认类别 1:11;
2. 创建类别
$ tc class add dev eth0 parent 1: classid 1:11 htb rate 40mbit ceil 40mbit
$ tc class add dev eth0 parent 1: classid 1:12 htb rate 10mbit ceil 10mbit
- parent 1::表示父类别为 Root Qdisc 1:;
- classid 1:11:表示创建一个 Handle 为 1:11 的子类别;
- rate 40mbit:表示该子类别的带宽为 40mbit;
- ceil 40mbit:表示该子类别的最大带宽为 40mbit;
- burst 40mbit:表示该子类别的峰值带宽为 40mbit;
3. 设置过滤器
$ tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 80 0xffff flowid 1:11
$ tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 25 0xffff flowid 1:12
- protocol ip:表示该 Filter 匹配的协议类型;
- parent 1:0:表示父类别为 Root Class 1:0;
- prio 1:表示该 Filter 的优先级。系统将按照从小到大的优先级顺序来执行 Filters,而对于相同的优先级,系统则按照执行命令的先后顺序执行 Filters。
- u32:表示该 Filter 所使用的 Classifier(分类器),u32 是最常用的分类器,后续的 match 选项用来表示匹配不同的数据报文。
- dport 80 0xffff:表示匹配 IP Header 中的 Destination Port 字段,如果该字段的值与 0xffff 进行 “与” 操作得到的结果是 80 的话,则匹配。
- flowid 1:11:表示将把匹配的流量分配到子类别 1:11,从而使得父类别为 Root Qdisc 继承子类别 1:11 的速率参数。
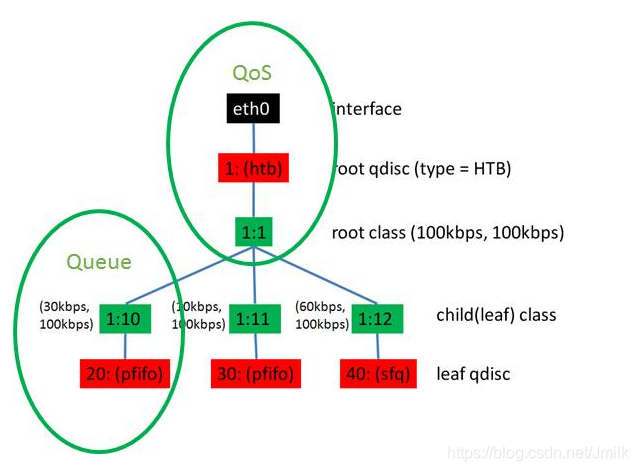
使用 TC 创建一个 HTB 树
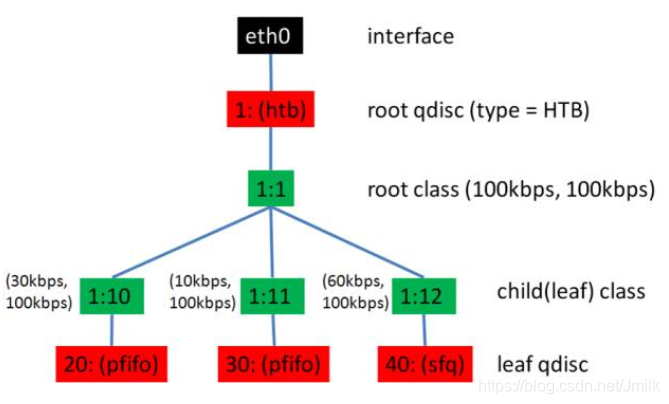
# 创建一个 HTB 的 qdisc 在 eth0 上,句柄为 1:,default 12 表示默认发送给 1:12。
tc qdisc add dev eth0 root handle 1: htb default 12
# 创建一个 root class,然后再创建几个 sub class。
# 同一个 root class 下的 sub class 可以相互借流量,如果直接不在 qdisc下面创建一个 root class,而是直接创建三个 class,他们之间是不能相互借流量的。
tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:10 htb rate 30kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:11 htb rate 10kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps
# 创建叶子 qdisc,分别为 fifo 和 sfq。
tc qdisc add dev eth0 parent 1:10 handle 20: pfifo limit 5
tc qdisc add dev eth0 parent 1:11 handle 30: pfifo limit 5
tc qdisc add dev eth0 parent 1:12 handle 40: sfq perturb 10
# 设定规则:从 IP 1.2.3.4 来的并且发送给 port 80 的包,从 1:10 走;其他从 1.2.3.4 发送来的包从 1:11 走;其他的走默认。
# 实现了限速与分流。
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip src 1.2.3.4 match ip dport 80 0xffff flowid 1:10
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip src 1.2.3.4 flowid 1:11

# add qdisc
$ tc qdisc add dev eth0 root handle 1: htb default 2 r2q 100
# add default class
$ tc class add dev eth0 parent 1:0 classid 1:1 htb rate 1000mbit ceil 1000mbit
$ tc class add dev eth0 parent 1:1 classid 1:2 htb prio 5 rate 1000mbit ceil 1000mbit
$ tc qdisc add dev eth0 parent 1:2 handle 2: pfifo limit 500
# add default filter
$ tc filter add dev eth0 parent 1:0 prio 5 protocol ip u32
$ tc filter add dev eth0 parent 1:0 prio 5 handle 3: protocol ip u32 divisor 256
$ tc filter add dev eth0 parent 1:0 prio 5 protocol ip u32 ht 800:: match ip src 192.168.0.0/16 hashkey mask 0x000000ff at 12 link 3:
# add egress rules for 192.168.0.9
$ tc class add dev eth0 parent 1:1 classid 1:9 htb prio 5 rate 3mbit ceil 3mbit
$ tc qdisc add dev eth0 parent 1:9 handle 9: pfifo limit 500
$ tc filter add dev eth0 parent 1: protocol ip prio 5 u32 ht 3:9: match ip src "192.168.0.9" flowid 1:9
Egress 带宽限制示例
$ tc qdisc del dev eth0 root
$ tc qdisc add dev eth0 root handle 1: htb
$ tc class add dev eth0 parent 1: classid 1:1 htb rate 20mbit ceil 20mbit
$ tc class add dev eth0 parent 1:1 classid 1:10 htb rate 10mbit ceil 10mbit
$ tc qdisc add dev eth0 parent 1:10 sfq perturb 10
# 让 172.20.6.0/24 走默认队列,为了让这个 IP 的数据流不受限制
$ tc filter add dev eth0 protocol ip parent 1: prio 2 u32 match ip dst 172.20.6.0/24 flowid 1:1
# 默认让所有的流量都从特定队列通过,带宽受到限制
$ tc filter add dev eth0 protocol ip parent 1: prio 50 u32 match ip dst 0.0.0.0/0 flowid 1:10
Ingress 带宽限制示例
Ingress 流量控制需要依赖 ifb(Intermediate Functional Block)内核模块。因为 Ingress 流量实际上是无法直接控制的。而是需要先将这些流量引流到一个 “中间队列”,而该队列就是处于 ifb 设备上的。然后再让这些流量重新进入 Ingress TC 执行处理,最后在进入 L3 Sub-system。如下图所示,具体而言还有 3 种不同的情况。
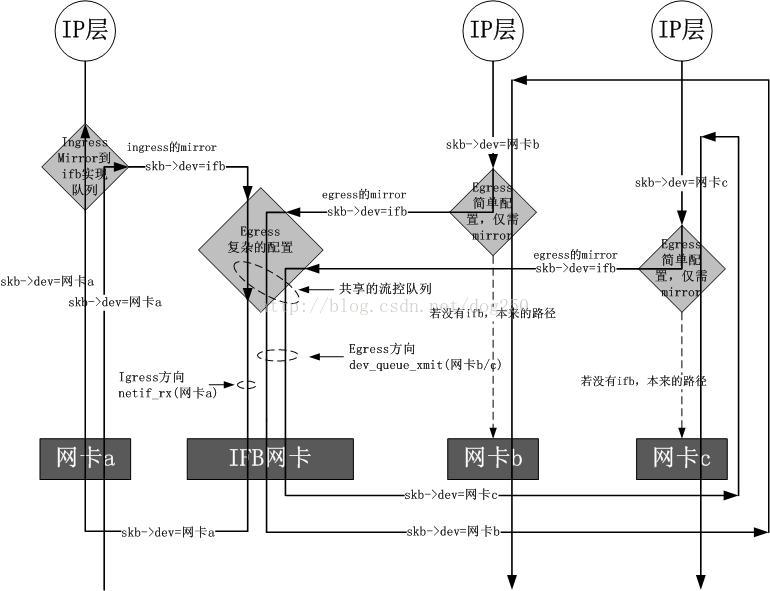
# init ifb
$ modprobe ifb numifbs=1
$ ip link set ifb0 up
# redirect ingress to ifb0
$ tc qdisc add dev eth0 ingress handle ffff:
$ tc filter add dev eth0 parent ffff: protocol ip prio 0 u32 match u32 0 0 flowid ffff: action mirred egress redirect dev ifb0
# add qdisc
$ tc qdisc add dev ifb0 root handle 1: htb default 2 r2q 100
# add default class
$ tc class add dev ifb0 parent 1:0 classid 1:1 htb rate 1000mbit ceil 1000mbit
$ tc class add dev ifb0 parent 1:1 classid 1:2 htb prio 5 rate 1000mbit ceil 1000mbit
$ tc qdisc add dev ifb0 parent 1:2 handle 2: pfifo limit 500
# add default filter
$ tc filter add dev ifb0 parent 1:0 prio 5 protocol ip u32
$ tc filter add dev ifb0 parent 1:0 prio 5 handle 4: protocol ip u32 divisor 256
$ tc filter add dev ifb0 parent 1:0 prio 5 protocol ip u32 ht 800:: match ip dst 192.168.0.0/16 hashkey mask 0x000000ff at 16 link 4:
# add ingress rules for 192.168.0.9
$ tc class add dev ifb0 parent 1:1 classid 1:9 htb prio 5 rate 3mbit ceil 3mbit
$ tc qdisc add dev ifb0 parent 1:9 handle 9: pfifo limit 500
$ tc filter add dev ifb0 parent 1: protocol ip prio 5 u32 ht 4:9: match ip dst "192.168.0.9" flowid 1:9
对指定 srcIP 进行限速示例
$ tc qdisc add dev ifb0 root handle 1: htb default 20
$ tc class add dev ifb0 parent 1: classid 1:1 htb rate 10000mbit
$ tc class add dev ifb0 parent 1:1 classid 1:10 htb rate 2000mbit
$ tc class add dev ifb0 parent 1:1 classid 1:20 htb rate 1000mbit
$ tc class add dev ifb0 parent 1:1 classid 1:30 htb rate 500mbit
$ tc filter add dev ifb0 protocol ip parent 1:0 prio 1 u32 match ip src 129.9.123.85 flowid 1:10
$ tc filter add dev ifb0 protocol ip parent 1:0 prio 1 u32 match ip src 129.9.123.89 flowid 1:20
$ tc filter add dev ifb0 protocol ip parent 1:0 prio 1 u32 match ip src 129.9.123.88 flowid 1:20
IP QoS 服务模型的演进过程
Best-Effort
Best-Effort 是最简单的 QoS 服务模型,用户可以在任何时候,发出任意数量的报文,而且不需要通知网络。提供 Best-Effort 服务时,网络尽最大的可能来发送报文,但对时延、丢包率等性能不提供任何保证。
Best-Effort 服务模型适用于对时延、丢包率等性能要求不高的业务,是现在 Internet 的缺省服务模型,它适用于绝大多数网络应用,例如:FTP、E-Mail 等。
IntServ 服务模型
由于网络带宽的限制,Best-Effort 服务模型不能为一些实时性要求高的业务提供有力的质量保障,于是 IETF 在 1994 年的 RFC1633 中提出了 InterServ 模型。
IntServ 模型是指用户在发送报文前,需要通过信令(Signaling)向网络描述自己的流量参数,申请特定的 QoS 服务。网络根据流量参数,预留资源以承诺满足该请求。在收到确认信息,确定网络已经为这个应用程序的报文预留了资源后,用户才开始发送报文。用户发送的报文应该控制在流量参数描述的范围内。网络节点需要为每个流维护一个状态,并基于这个状态执行相应的 QoS 动作,来满足对用户的承诺。
IntServ 使用了 RSVP(Resource Reservation Protocol,资源预留协议)协议,它使得应用程序可以向网络提出每条流的服务质贯要求。即:在一条已知路径的网络拓扑上预留带宽、优先级等资源,路径沿途的各网元必须为每个要求服务质量保证的数据流预留想要的资源。
通过 RSVP 信息的预留,各网元可以判断是否有足够的资源可以使用,只有所有的网元都给 RSVP 提供了足够的资源,“路径” 方可建立。
简单来说,InterServ 服务模型下,网络需要为某个业务预留一条专用通道。这种资源预留的状态称为 “软状态”。为了保证这条通道不被占用,RSVP 会定期发送大量协议报文进行探测。通过 RSVP,各网元可以判断是否有足够的资源可以预留。只有所有的网元都预留了足够的资源,专用通道方可建立。
IntServ 模型为业务提供了一套端到端的保障制度,其优点显而易见,但是其局限性一样明显。
- 实现难度大:IntServ 模型要求端到端所有网络节点支持。而网络上存在不同厂商的设备,核心层、汇聚层和接入层的设备功能参差不齐,要所有节点都支持 IntServ 模型,很难达到这方面要求。
- 资源利用率低:为每条数据流预留一条路径,意味着一条路径只为一条数据流服务而不能为其他数据流复用。这样导致有限的网络资源不能得到充分的利用。
- 带来额外带宽占用:为了保证这条通道不被占用,RSVP 会发送大量协议报文定期进行刷新探测,这在无形中增大了网络的负担。
DiffServ 服务模型
为了克服 InterServ 可扩展性差的问题,IETF 在 1998 年提出了 DiffServ(差分服务)模型。
DiffServ 模型的基本原理是将网络中的流量分成多个类,每个类享受不同的处理,尤其是网络出现拥塞时不同的类会享受不同级别的处理,从而得到不同的丢包率、时延以及时延抖动。同一类的业务在网络中会被聚合起来统一发送,保证相同的时延、抖动、丢包率等 QoS 指标。
Diffserv 模型中,业务流的分类和汇聚工作在网络边缘由边界节点完成。边界节点可以通过多种条件,例如:报文的源地址和目的地址、ToS 域中的优先级、协议类型等,灵活地对报文进行分类,对不同的报文设置不同的标记字段,而其他节点只需要简单地识别报文中的这些标记,即可进行资源分配和流量控制。
与 IntServ 模型相比,DiffServ 模型不需要 RSVP 信令。在 DiffServ 模型中,应用程序发出报文前,不需要预先向网络提出资源申请,而是通过设置报文的 QoS 参数信息,来告知网络节点它的 QoS 需求。网络不需要为每个流维护状态,而是根据每个报文流指定的 QoS 参数信息来提供差分服务,即对报文的服务等级划分,有差别地进行流量控制和转发,提供端到端的 QoS 保证。
DiffServ 模型充分考虑了 IP 网络本身灵活性、可扩展性强的特点,将复杂的服务质量保证通过报文自身携带的信息转换为单跳行为,从而大大减少了信令的工作,是当前网络中的主流服务模型。因此,DiffServ 模型成为 QoS 设计和应用的主要方案。
DiffServ 的实现原理
DiffServ 采用了 “边缘监管 + 分配 + 业务优先级” 的结合,为不同的 QoS 要求的数据流分配不同的服务优先级,从而实现业务差分(Differential Service)的 QoS 保障。
DiffServ 模型需要在网络入口处,根据用户和 ISP 签订的 SLA(Service Level Agreement,服务等级协定),为指定的业务分配一个 DSCP(区分服务代码)。
路由器根据 DSCP 值来决定分组的 PHB(Per Hop Behavior,逐调行为)。具有相同的 DSCP 值的分组将接受相同的处理,这些处理构成了一个 BA(Behavior Aggragate,行为聚合)。
DiffServ 机制还提出了 DiffServ Domain 的概念,定义了一个 DiffServ Domain 由许多路由器组成。处于域边缘的路由器称之为 ER(边缘路由器),处于域核心的路由器称之为 CR(核心路由器)。DiffServ 将针对单一流的复杂处理推向网络的边缘,由 ER 来完成数据包的分类和流量调节;CR 不再维护节点的状态信息,仅完成相应的 PHB 操作。因此,对于这种 Core-Stateless 方式的模型来说,具有很好的扩展性和伸缩性。
DSCP 字段
DiffServ 机制重新命名了 IPv4 Header 的 ToS 字段和 IPv6 Header 的 TC 字段,统一定义为 DS 字段。
- IPv4 的 Type of Service(业务类型)字段:用于区分 IPv4 承载的上层业务类型,具有两种模式:
- 模式 1:前 3bit 标识优先级(Precedence),4-7bit 分别标识时延、吞吐量、可靠性、开销(一个数据包只能有一位生效),最后 1bit 备用
- 模式 2(DSCP,差分服务代码点):使用 0-5bit(64 种业务类型),最后 2bit 备用,例如:作为 2bit 的 ECN(显式拥塞通知)。
- IPv6 支持 QoS 增强:IPv4 使用 6 位 DSCP(差分服务代码点)和 2 位 ECN(显式拥塞通知)来提供 QoS,但它只能在端到端设备都支持它时使用。而在 IPv6 中,增加了流量类(Traffic Class,TC)和流标签(Flow Label)字段,用于告诉底层路由器如何有效地处理数据包和路由它。
在实际网络中,每个 DSCP 值就对应了一种特定的 SLA。此外,DiffServ 还定义了 3 种业务类型:
- EF(快速转发业务):提供类似专线和租用线的业务,DSCP 值为 101110。
- AF(保证转发):提供比 besteffort 尽量好的业务,分四类,没类又定义了三种不同的丢弃优先级,共有 12 种推荐的 DSCP 值;
- 尽力而为:DSCP 值为 000000。
L2 QoS 服务模型
L2 QoS 服务模型使用了 Frame 的 PCP(Priority Code Point)字段值,标识了 L2 QoS 优先级,0-7(最低-最高)。如下图所示,默认情况下,TCP 的流量走 Priority0,RoCE 流量走 Priority3。L2 QoS 实现原理和 IP QoS 类型,这里不再赘述。
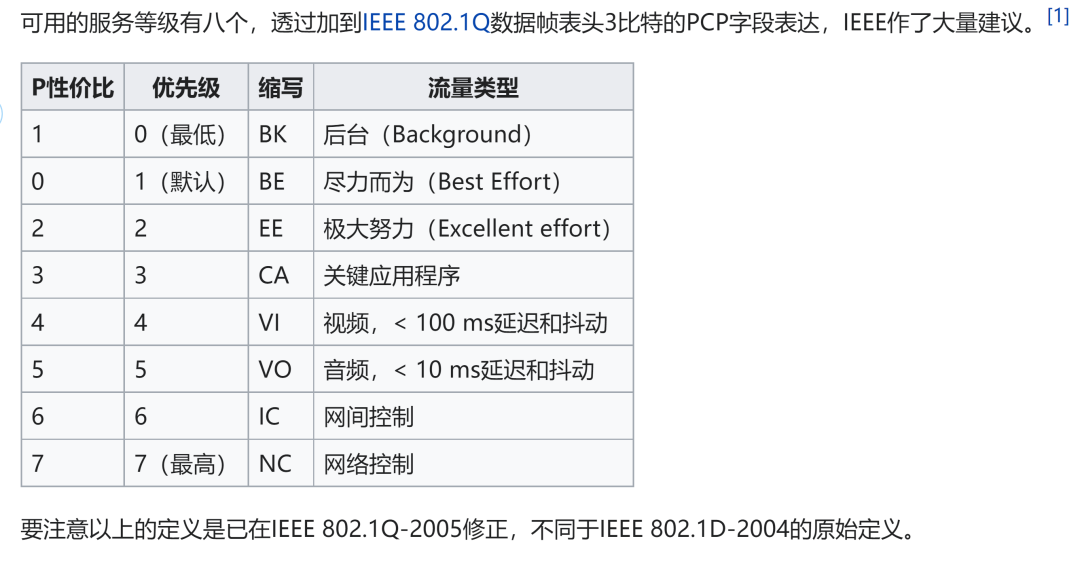
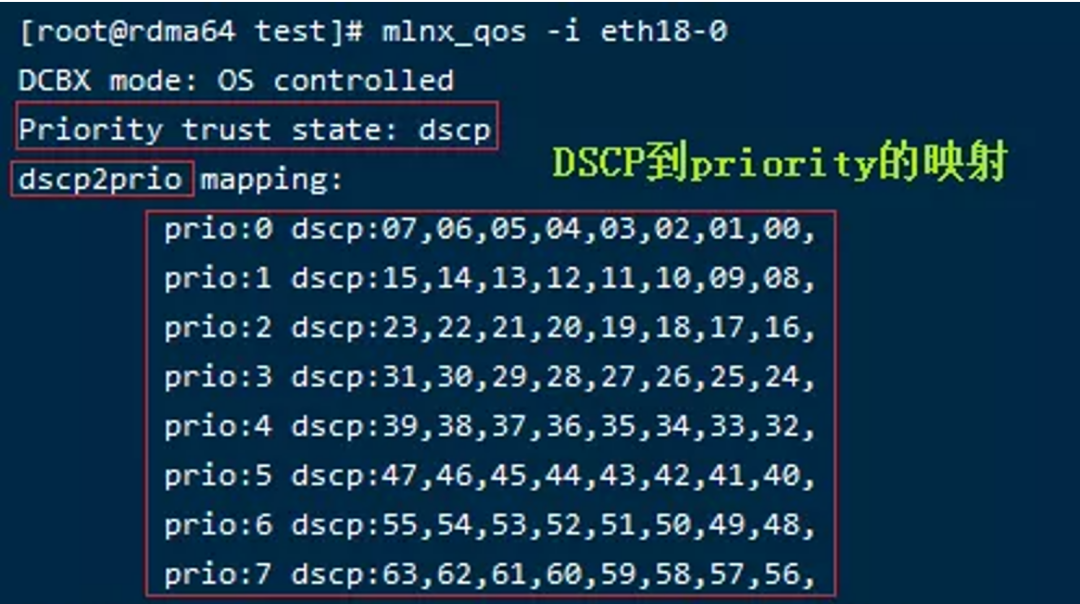
DSCP 与 PCP 的映射表如下图所示。
QoS 在企业网络中的应用
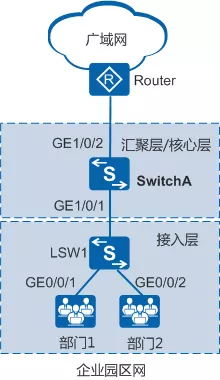
在企业网络中,QoS 的一系列技术不要求在同一台设备上应用,而应根据业务需要在不同位置应用。
-
接入层业务识别:接入交换机 LSW1 作为边界交换机,在接入侧需要担负数据流的识别、分类以及流标记的工作;在网络侧需要担负不同应用数据流的拥塞管理、拥塞避免、流量整形等工作。
-
汇聚层/核心层提供差分服务:汇聚层和核心层设备端口信任基于接入层标识的 QoS 参数,通过队列调度、流量整形、拥塞避免等方式实施 QoS 策略,保证高优先级业务优先获得调度。
