先说一条新闻,一家专注大数据的数据服务提供商公司巧达科技,因为大量使用爬虫访问其他公司接口获取数据,整个公司被抓,最后不光管理者,干活的程序员也被抓了。

很多学python的同学都接触过爬虫,即便是没接触过应该也听过,看到这种新闻你会不会心里也发虚,担心自己哪天因为不小心写了什么爬虫锒铛入狱?
这么本期视频,我们就来讲一下爬虫到底违不违法,以免你好好的吃着泡面写着代码,第二天就进去跟吴老师一起踩缝纫机。

一、爬虫是什么
首先,我们要明白爬虫到底是什么东西。抛开复杂的定义,爬虫就是一种自动获取互联网内容的程序。简单来说,爬虫通过模拟一个人类浏览网页的行为,到各个网站溜达溜达,看看有没有需要的数据,有的话就记录保存下来。
这么看起来,爬虫就是把人能干的事情给自动化了,高效地获取互联网上的内容。

二、爬虫能做什么
既然是模拟人的行为,那么人能干的事,爬虫都能干,比如你想下载优酷上某个电视剧全集,按照以前的方式,你得一集一集的点进去,然后想办法解析视频资源,挨个下载,现在不用了,你只需要一开始编辑好程序,使用的时候输入一个电视剧名就可以了。爬虫程序会自动地解析网页上所有的选项,找到所有剧集的下载方式。
又或者你喜欢某个明星,想大量地获取一些他的表情包,就可以将爬取的网站设定为微博、百度图片等一些有图的网站,然后等待爬虫获取就可以了。
除了个人写的爬虫,像百度、谷歌这些搜索公司,依据的基本技术也是爬虫,搜索公司每天放出百万级别的网络爬虫,爬取各个页面的资源,写进自己的数据库,为搜索结果提供数据,还可以定期的保存网页快照供用户快速查看。

三、为什么要反爬虫
那不禁要问了,像百度、谷歌这样的大公司就能安全的用爬虫?像前面提到的巧达科技,连程序员也会被抓?你会不会有种感觉,大公司有恃无恐,小公司如履薄冰?
那必须要介绍下巧达科技曾经的几个王牌业务,前面说了,巧达科技获取网站上的大量数据,这里的数据多是各个招聘网站上的数据,比如用户的简历等。用来做啥呢,说两个代表性产品。
第一个,简历时光机。
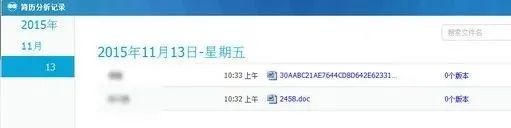
求职者的简历,所有的修改记录,全部被保存下来。
只要你曾经修改过简历,每一次的修改都会被记录,比如你曾经公开现在不愿意公开的信息,HR都能看到。
类比一下,你想想你十年前在QQ空间发的“45度角仰望天空,泪流满面,忘了爱”,十年后还能被大家看到。或者是你跟前男友前女友发的合照,随时都能被翻出来,你恶不恶心?
第二个,爱伙伴。
多么有爱的名字,听起来就感觉很温暖,那么它能干什么呢?
通过爬虫收集各个招聘网站的数据,包括用户投递简历、修改简历、简历被查看,来决定是否通知用户的公司HR。
简单来说,就是员工离职预警。

你要是修改了简历,那说明你可能想跑了,你如果投递了简历,那你就是在跑了,赶紧通知你的老板。
确实是爱伙伴,不过看起来你跟老板不是一伙的。
介绍了这几个业务,你觉得这公司被抓冤枉吗?
爬虫本身作为一种技术,是没有好坏的,重要的是如何使用。反爬虫,反的也是这种恶意爬虫。
还有些爬虫,虽然并没有做出恶心的产品,但对被爬取的网站造成了大量负载,最出名的就是12306的各种抢票软件了。
数年前有一款产品,叫做12306助手,20元可以注册会员,可以帮你在12306上抢票。
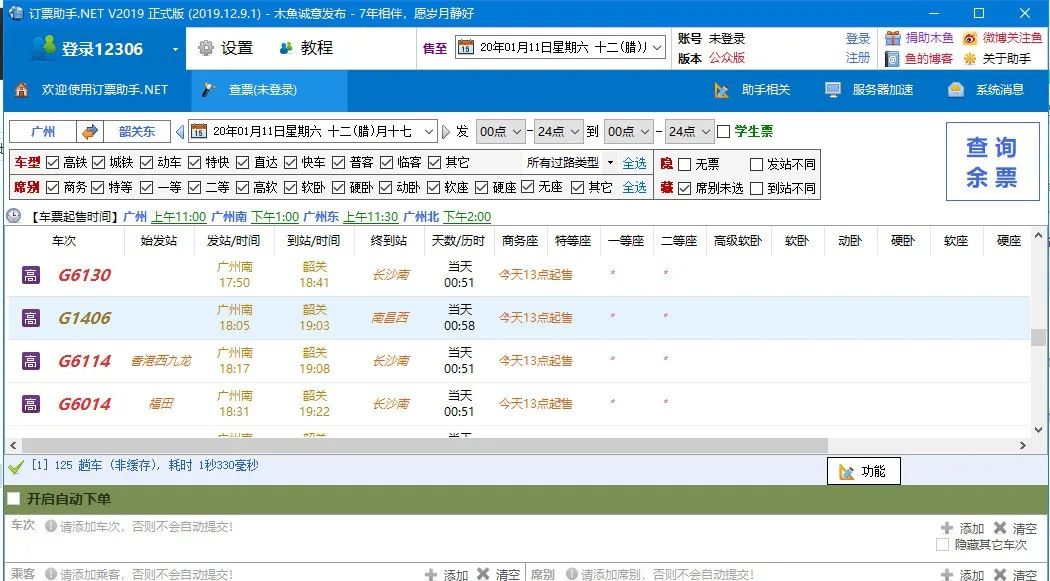
实际上原理也就是使用爬虫,模拟人点击抢票的方式。
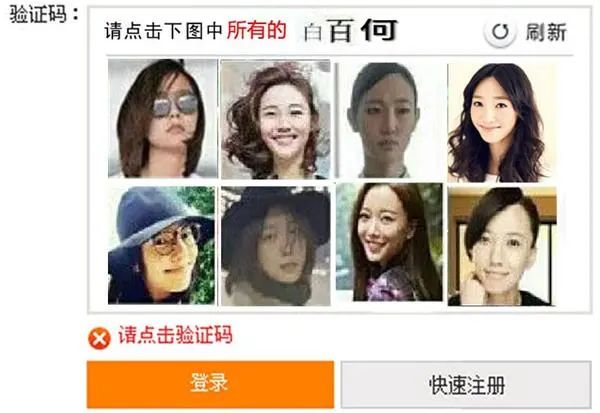
为了对付这些抢票爬虫,12306的验证方式不断升级,包括丧心病狂的认人脸方式。
比如,请找出图片里的白百何。
对于12306来说,这些爬虫形成了大量的流量冲击,正常的用户请求被淹没无法处理,就导致你使用正常方式抢不到,必须得用爬虫,用了还不行还得买流量包。
明明是铁路公司提供的运输服务,一部分互联网公司却能从中渔利。你说12306能不反这些爬虫吗?到了最后,他们干脆推出候补购票,你抢吧,你刷吧,反正有票我就先给候补的。

四、我们该如何分清违法和不违法的界限
讲到这里,其实大家对爬虫是否违法可能有了一个模糊的概念。爬虫本身并不违法,但你用爬虫做的事情就可能违法了。
那我们该如何分清违法和不违法的界限呢?其实作为普通人,并不需要太担心自己写的爬虫把自己送进监狱,这里给大家介绍几个注意事项,按照这个规范来,你就可以放心大胆、自由自在的爬取数据了。
第一,不要爬取公民隐私信息。有些网站可能自身安全建设不足,不小心在某个隐秘的链接暴露了自己的用户数据,正常情况下你可能看不到这些数据,但爬虫本来就喜欢逛这些犄角旮旯。
如果你获取了公民的身份证、手机号等隐私信息,就有可能触犯侵犯隐私罪、非法获取公民个人信息罪。
第二,不要爬取网站不公开的数据,比如某些政府网站的数据,某些互联网公司的后台日志,一旦获取就可能犯罪。
第三,不要对被爬取的网站造成实际影响。大部分网站是欢迎百度、谷歌来爬的,作为一个需要流量的网站,恨不得拿着喇叭大声吆喝:百度,给老子爬!
不然你在百度上没数据,别人搜不到,你的流量就无法保证。
但是,你不能造成影响,你说我爬取了网站数据保存下来,好,可以。但是你每秒请求的三十万次,直接给人家服务器搞崩溃了,那大概率是可以追你一个破坏计算机信息系统罪的。
第四,尽量遵守robots.txt协议
robots.txt协议是爬虫届的一个潜规则协议,网站声明自己欢迎哪些爬虫来爬,自己的哪些链接能够被爬。
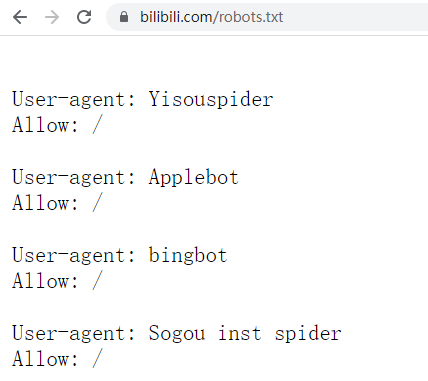
bilibili的robots协议
相当于我这是个博物馆,我给你说三号展厅能看,你去看吧,四号展厅只能办了月卡的能看,办公场所不能看。
当然,这个协议是个君子协议,并没有强制的要求,所以许多公司是灵活对待的。
围绕robots.txt协议,国内两大互联网巨头百度和360也曾发生过冲突。

360为了拓展自己的搜索业务,去爬取百度的数据,这事儿就有意思,百度爬了别人的数据,我360再去爬你的数据。那百度肯定不能干啊,就在自己的robotx.txt协议里写明了“其他爬虫可以来,你360的爬开”。
哎,robots协议不是强制协议,也没法限制别人真的来爬取,于是360就接着爬,爬完之后就存到自己的快照给用户搜索。
百度就告360不正当竞争,最终结果360违反《反不正当竞争法》判赔百度70万。
但这件事没完,360马上告百度滥用协议,搞排斥竞争者的恶意竞争。
结果360也胜诉了,百度被判赔20万。
所以说,很多时候爬虫做的事情都是在违法与不违法的边缘反复横跳,但只要你完全遵守上面几条规则,那作为个人开发者就还是安全的。