❝本文所有文章配图都是使用 AI 绘画工具 Midjourney 来画的。
全球最受欢迎的开源机器学习社区和平台 Hugging Face 发表了一篇新的博客,介绍一种新的解码方法来解决大语言模型(英文:Large Language Model,缩写LLM)文本生成的延迟问题,最终可以将 LLM 的回复延迟降低到 10 倍以上!
要生成文本,模型需要做一件事:输入一段文字,然后逐层计算,最后输出下一个可能的词(比如汉字、字母等)。这个过程就像给你一个谜题,然后你要猜下一个词是什么。
但是,LLM 猜词的速度有时候就慢得像乌龟一样。为什么呢?
因为模型计算时要不断地读取和传输数据。
这就好比你在玩游戏时,画面卡顿的原因是因为游戏数据传输速度不够快。这也是 LLM 生成文本慢的根本原因。
那么用什么办法可以让这个过程加速呢?目前有三个方法:
优化模型的硬件。就跟你换更好的手机和电脑是一个道理。
同时处理多个文本。这就好比你一边吃饭一边看电视,可以让你同时完成两件事,提高效率。
使用多个设备共同完成工作。就像你和朋友们一起完成一个大型拼图,大家分工合作,可以更快地完成任务。
一般通过这三个方法,就可以让 LLM 变得更快。但要完全解决延迟问题,还需要继续努力。就像我们一直在努力提高游戏画面的流畅度一样,科学家们也在不断研究,让 LLM 回复得更快、更准确。
更快的语言解码器
我们来了解一下什么叫模型前向传播。
想象一下,我们的模型就像是一个会说话的机器人,它可以根据我们给它的词,想出下一个词是什么。在讲故事的过程中,机器人接收到刚刚说出的词,然后利用自己的大脑(缓存)快速找到下一个词。这样做可以避免重复思考,提高速度。不过,机器人也可以不用缓存,把整个故事都当作输入。

再想象一下,有一个神奇的辅助模型(你可以想象成一个助手机器人),它能和我们的模型一起说出相同的故事。虽然这个助手不能直接和我们说话,但它可以帮助模型快速生成故事。利用前面提到的方法,助手可以提前告诉模型下一个词是什么,然后模型再确认这个词是否正确。这样一来,讲故事的复杂度将会直接从 O(n) 提高到 O(1),其中 n 是故事的长度。故事越长,提速效果越明显。
但现实中,这个助手并不完美。它可能会猜错下一个词。因为讲故事是一个接一个的过程,一旦助手犯了错误,后面的词就都不能用了。但这并不妨碍模型在纠正错误之后,再次咨询助手,并重复这个过程。即使助手有时会出错,讲故事的速度也会比原来快很多。使助手犯了一些错误,文本生成的延迟也会比原来低一个数量级。

虽然没有零延迟的辅助模型,但我们可以找到一个能近似另一个模型的文本生成输出的模型,比如同一架构的迷你版模型。当两个模型的大小差距变得很大时,使用较小的模型作为助手的成本就可以忽略不计了。
贪婪解码与辅助生成
辅助模型究竟是如何工作的呢?
这里就涉及到一个概念叫“贪婪解码”。所谓贪婪解码,就像一个贪吃的小猫一样,总是想选最好吃的食物。大模型的助手会在每个时刻挑选最有可能出现的词,然后一个接一个地把这些词串联成一个完整的故事。虽然有时候这种方法可能不是最理想的选择,但它简单快速,对于许多任务来说已经足够好了。

理解了贪婪编码,我们再来看看这个助手是如何与大模型一起协同工作的。
首先,我们要让这大模型与助手说同一种语言。如果他们说不同的语言,那么就需要额外的时间来翻译,这样就太慢了。所以,我们要确保他们用的是同一个“分词器”,这样他们才能理解彼此。
然后,我们需要一个聪明的方法来让他们俩之间互相协作。我们可以让助手先用贪婪解码猜一些故事里最可能出现的词,然后让大模型看看这些词对不对。这样一来,大模型就可以更快地讲出正确的故事了。虽然助手有时候也会猜错,但我们可以记录这些错误,并调整它下次猜词的数量。说白了,这就是在讲故事的过程中嵌套讲故事,和电影《盗梦空间》有些相似之处。
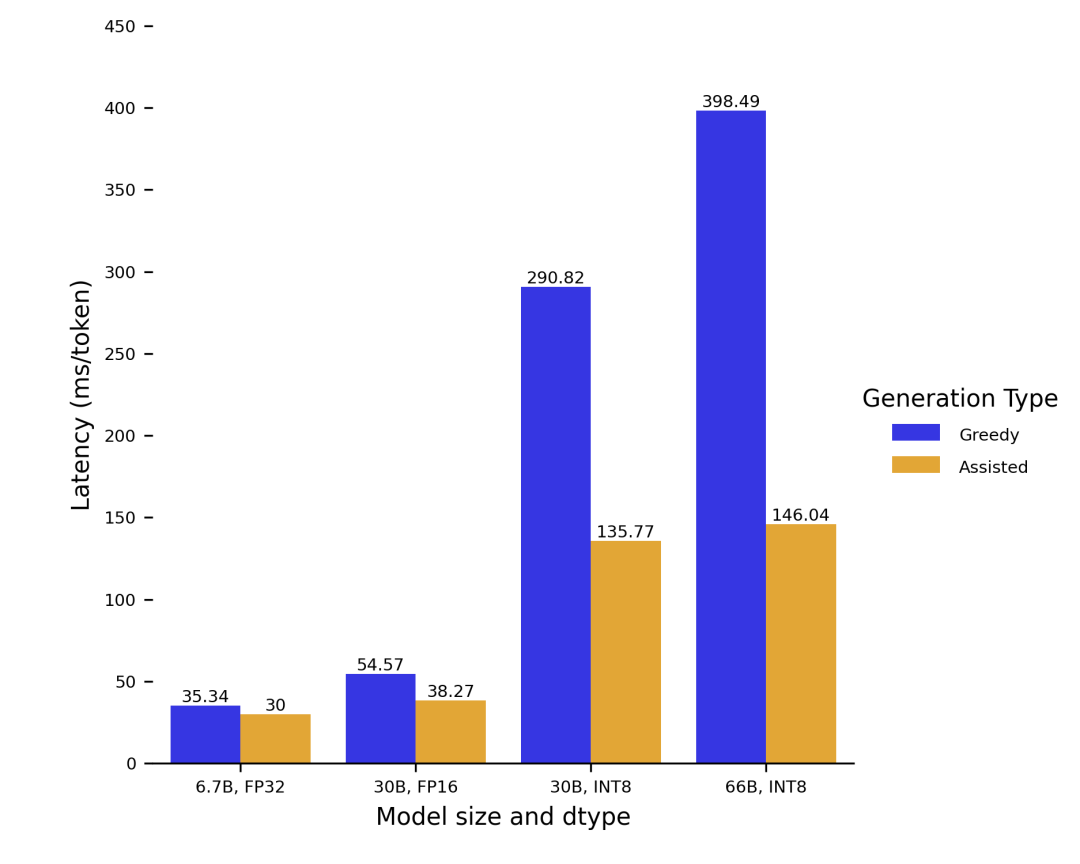
来看看加速效果吧:
总结
最后再来总结一下。
想象我们正在玩一个猜词游戏,贪婪解码就像是我们只猜最可能的词,采样则是根据每个词的可能性来随机猜测,温度系数就像是猜词游戏的“调皮”程度。当温度接近 0 时,我们几乎总是猜最可能的词。当温度大于 1 时,我们的猜测就会变得混乱,就像在抽奖一样。
现在,让我们再次回到辅助生成的概念。辅助生成是用一个小机器人(辅助模型)来帮助一个大机器人(主模型)更快地猜词。当我们使用采样而不是贪婪解码时,小机器人可能猜错的次数会增加,从而降低了协助生成的效果。但是,通过调整温度系数,我们可以让小机器人在猜词时更接近贪婪解码,从而保留协助生成的大部分优势。
博客链接:https://huggingface.co/blog/assisted-generation

本文文章配图都是使用 AI 绘画工具 Midjourney 来画的。
未来只有两种人,一种是懂 AI 的会用 AI 工具的人,一直是不会用 AI 的人。我们已经帮助了 60 多人(社群已经有 60+),从零开始学习使用 AI 绘画工具,帮你大幅节省效率。
我们的星球主要会分享 Midjourney 和 Stable Diffision 等 AI 绘画工具的使用方法,最新资讯以及行业价值。同时还会有定期的直播现场传授“玩转 AI 绘画与 ChatGPT”的秘籍。
加入星球的福利:
免费使用 Midjourney!
免费使用 Stable Diffision!
免费使用 ChatGPT!
免费使用 Claude!
