我们最近尝试实现一种事务消息解决方案。接上文:分布式事务?No, 最终一致性 - 知乎专栏
我们希望这个方案是轻量级的,能实际解决目前业务痛点。
本文几乎看不到任何理论分析,只谈做什么,怎么做。因为涉及到一些内部资料,有所省略。
实现事务消息核心是需要有一个支持消息重试的MQ。经调研,我厂有个自研的基于Redis的延时MQ服务。我们暂且叫他DelayQ吧。目前我厂还没有类似RMQ的事务消息方案。
据称RocketMQ和ActiveMQ等均有相似特性。您猜对了,我都没用过。请各位客官帮忙告知下还有哪些有此特性。
DelayQ
DelayQ主要功能是支持不同的消息延迟策略。提供两个核心接口:addMsg, deleteMsg.
1. addMsg负责将一个重试消息注册到DelayQ中。其核心参数有:
最大重试次数,重试间隔, 生效时间,下游Url级对应业务参数。
2. deleteMsg负责主动将上面注册的消息删除掉。
大致流程是:producer通过addMsg注册一条延迟消息,DelayQ负责在生效时间点将次消息push给下游consumer。如果下游返回成功,则不再继续发送。否则,会每隔重试间隔尝试发送,直到最大重试次数为止。
在一些特殊场景,producer或consumer可以通过deleteMsg接口主动删除该消息。
我厂DelayQ是基于Redis的zset实现的。我们只是个业务团队,所以也没有参与其开发。下面根据个人理解,简单说明下他大概是如何工作的(对显示器发誓,此图只是本人yy之作。如有雷同切莫当做泄露公司机密。我确实也没看到详细的设计文档。正因此也是仅供参考,实操性不大)。
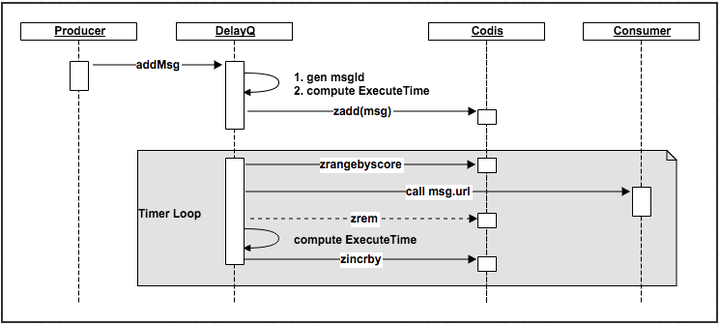 如上所述,关键数据结构就是zset。Redis集群方案选用Codis.
如上所述,关键数据结构就是zset。Redis集群方案选用Codis.
每次addMsg时,都会给该消息生成一个唯一id。然后计算其下次尝试时间。这里就是DelayQ要实现的核心策略部分。比如,我们可以每次间隔相同时间,也可以是指数衰减的间隔去尝试。为了实现这些,我们还需要在消息体上面额外记录一些信息。比如,上次尝试时间,总共已尝试次数等信息。这些都搞定了就将消息和其他一些必要信息写到zset中。zset以ExecuteTime作为Score排序。
消息进到zset后,DelayQ会通过timer触发(比如秒级),fork相应的消费线程去处理zset里ExecuteTime大于当前时间的消息。DelayQ拿到一条消息后,解析其中的callbackurl,并组装参数,push业务消息给Consumer.
Consumer返回处理成功,那么zrem Codis里的消息。如果处理失败,则计算其下次尝试时间,并更新其ExecuteTime.
YY主要流程如上。相信实际实现过程中,还有很多问题需要解决。比如,定时处理,如何提高并发度?考虑到redis丢消息情况,还需要做些啥?回调接口超时和限流问题等等。因为理解不深,所以不敢继续写了,怕露馅^_^
事务消息
基于上面的DelayQ,我们尝试提出一种可靠的消息传递机制(事务消息)。核心思想抄袭RMQ。直接上图。
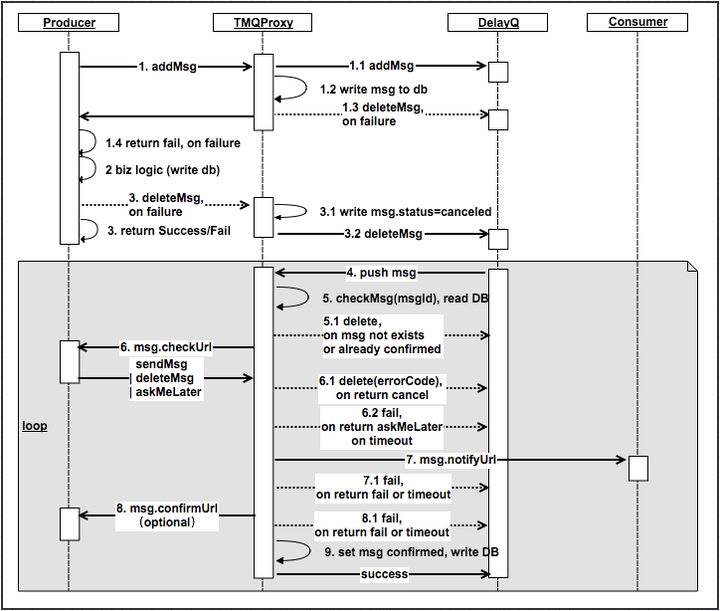 我们在DelayQ前面增加一层Proxy,暂且就叫TMQProxy吧。producer将通过TMQProxy跟DelayQ交互,不会直接跟DelayQ进行交互。
我们在DelayQ前面增加一层Proxy,暂且就叫TMQProxy吧。producer将通过TMQProxy跟DelayQ交互,不会直接跟DelayQ进行交互。
TMQ相对于DelayQ要求Producer多提供两个信息,一个是checkUrl, 一个是confirmUrl(可选)。producer需要分别实现这两个接口。
check接口:主要是告知TMQProxy,当前消息是否可以发送。对应上面步骤6.
confirm接口:可选接口。TMQProxy将消息处理成功后会通过该主动通知Producer消息已经处理成功。如果producer对此结果不感兴趣,就可以不必实现。
详细过程如上面交互图。就不一一解释了。如果对实现感兴趣,还是建议稍微仔细看下上图,画这个还是费了点脑细胞的。相信大家还是能看明白大致思想。
我们引入TMQProxy还有一个目的是,不想让内部业务使用DelayQ上太过花哨。比如其内部topic这些,我们都屏蔽掉了。重试策略这些也不希望业务层玩得太灵活,所以只能提供枚举的策略。
另外一个考虑是,DelayQ可能也只是个阶段性方案,后续如果切换其他MQ。我们希望尽量做到业务方无感知。直接通过Proxy屏蔽底层具体的MQ实现。
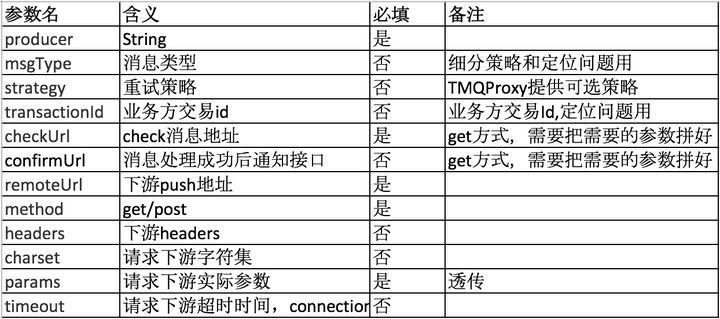
TMQProxy提供的接口大致如下(示例):
 (知乎不支持表格?)
(知乎不支持表格?)
稍微啰嗦下timeout。timeout设置合理性还是很重要的。这里check和confirm的超时时间,我们会限制比较小的时间。如果不满足,则可能拒绝接入TMQProxy。而下游的处理时间一般都会比较长。这里,我们可以容忍第一次超时。但是处理成功后第二次请求还耗很长时间是接受不了的。所以需要下游该加结果cache加结果cache,该优化幂等算法优化幂等算法。如果连续timeout多次,其实这条消息可以考虑丢弃。
简化
细心的朋友可能发现上一节的图里多出了个DB,主要是存储消息的一些状态。引入DB目的是完全代替业务侧的消息表。可以在消息状态查询,故障恢复等中起到兜底作用。当然,也可以有效减少查询check接口的次数。
实际应用中,我们认为这个DB的引入有点过重。因为Redis和DelayQ稳定性已然经受住了更大业务量的考验。目前已经趋于成熟了,也没发生过大面积丢消息等严重事故。
所以我们在TMQProxy中,把DB先抛弃了。上面所有DB相关操作实际上,我们是没有实现的。所以消息Id实际上也是用了DelayQ返回的消息Id。消息Id,主要用于delete。这里有点小坑,就不扩展了。实际应用中,因为我们通过同步接口中返回码控制消息是否要删除掉,所以饶过了这个坑。
所以,很多时候,我们设计时候尽量考虑全,实际实现和应用的时候会做很多tradeoff。据说这个是架构师关键素养。这话题小的就不敢扩展了。
还有啥
一个系统,如果只是画几张图,把代码写完就万事大吉该多好?可惜,我们想让他上线,还需要考虑很多很多问题(考虑的永远都不够多)。因为有点跑题,所以就不再扩展,只是蜻蜓点水,纯属凑字数了。
1. 限流。对于一个通用服务,因为接入方杂七杂八,所以不管是producer请求频次控制,还是对下游的保护,都离不开限流措施。可以在不同层进行限流。接口层,我们考虑按producer+msgType等多个维度进行限流。做全局限流还有点麻烦。假设loadbalancer足够均匀,我们只对单机做限流基本就够了。这里推荐com.google.common.util.concurrent.RateLimiter,非常好用。感谢肖少早前推荐。
2. 监控。不怕出问题,就怕出了问题不知道。监控非常重要。关键是监控些啥?不展开了,这个真的非常非常重要。相信大部分厂子都有自己的一套相对完整的监控系统。
3. 降级和兜底。首先Producer可以把TMQProxy当做直接调用下游失败后的补充手段。这样就不会对TMQProxy产生强依赖。TMQProxy自身没有存储,所以除了逻辑错误,最大可能就是下游DelayQ故障了。此时,因为没有存储,只能通过日志进行恢复了。我们需要规范日志打印,并准备好处理脚本。把故障期间消费失败的消息重新处理一遍。理论上只要DelayQ不丢消息,我们也可以等待DelayQ恢复后重试。不过如果add就失败,那根据上面流程,业务上肯定是会有损失的。所以我们对DelayQ的稳定性,要求至少是4个9。所以更多的降级,应该在producer侧结合业务去考虑。对于DelayQ丢消息场景,目前大部分业务场景只能通过对账进行发现和补账。当然,有些业务自己会实现主动查询机制。通过定期或人为(可能是用户查询,也可能是后台查询)触发查询下游,并同步状态。
4. 部署。如果有条件,最好独立部署。作为proxy,可能性能瓶颈在网络IO上。所以消息体不应过大。一种常见做法是Producer发给下游的只是一个Id,下游获得该消息后,还得查一下producer才能拿到全部信息。实际情况还是看量。
5. 压测。线上线下压测还是要经常做一做的。上线前做一次可能不够。因为逻辑可能会有变化。线下压测可能也不够,因为线上应用场景跟线下模拟的可能不同。线上线下机器配置可能也不一致。所以有条件做全链路压测,那就圆满了。全链路压测是个浩大的工程,大厂似乎都在玩。比如微信动不动就演练....