林轩田机器学习技法(Machine Learning Techniques)笔记(一)
林轩田机器学习技法(Machine Learning Techniques)笔记(三)
Dual Support Vector Machine
P6 2.1

L1 讲的是线性支持向量机,接下来L2讲的是对偶支持向量机。

上节就讲了下求non-linear SVM的方法,转换到z空间的时候,QP问题会有 d~ + 1 个变数(和N个常数)来解,要解决 d~ 很大,甚至是无穷的问题,让SVM不依赖于d~ :

我们可以把original的SVM转成等效的SVM

这就是对偶问题:

我们可以仿照之前regularization,引入λ,将条件问题转换为非条件问题,而λ的个数就是N


定义拉格朗日函数,相关文献通常把 λ 写成 α

把SVM转换成右式子

如果满足不了 s.t. 的(b,w)那么1-yn(wTzn+b)就是整数,选取max的话,就会到达无穷大,因为最终要到是min,这样就会筛掉这种不满足 s.t. 的(b,w)
如果满足了的话,yn(wTzn+b)会是个非负数,因为有个max且a>=0,所以 yn(wTzn+b)=0(注意可以不要 ∑ \sum ∑,因为a>=0,只能是每一项都=0,才可以求和=0),那么式子就是 1 2 w T w \frac{1}{2} w^Tw 21wTw。
这样即有效地筛掉不满足 s.t. 的数据,又能找到最小的 1 2 w T w \frac{1}{2} w^Tw 21wTw。
P7 2.2
上节把SVM转成拉格朗日式子,那么,如何找到该式子的下限?对于任何(b,w)来说,都有这个:

因为对于任何都成立,所以取右式子最大的,还是成立的:

右式成为拉格朗日的对偶(dual)问题,如果解决了这个问题,也就找出SVM的下限。

因为满足绿色的三个条件,所以是个强关系(对于QP问题),所以就可以直接等同了,也说明了有组(b,w,α)满足等式两边:

现在没有什么限制了,所以开始解这个:
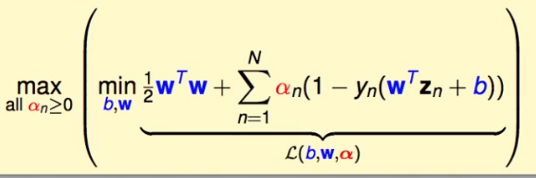
因为是min,所以要求:
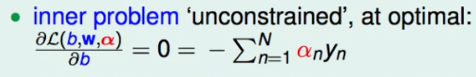
因此我们可以加上这个限制,并把式子化一化:

可以看出最后一项是 b*0 ,所以变成:

同样,因为min,所以要给L求个w的偏导=0,得出w为一个固定的数,然后开始化简,min可以不用看了,是因为max有了下面一系列规定之后,式子里头没有b和w,剩下的就只用考虑 α 就可以了。

最后成这个满足最佳化的4个条件为KKT。补充一下:第四点(哈利波特和伏地魔必须活一个)那个,yn(wTzn+b)=1的话(说明点正好在分界线上,这些α>=0点就是SV),式子自然为0,>1的话,根据2.1最后那个图,使得2.1那个图的式子取min,那么αn就只能取0了,所以最终这里的式子也是0。

最后是funtime小练习巩固,感觉挺有意思的,②要去看回 L(b,w,α) 的定义,就知道了yn和zn=1,然后w= ∑ α n y n z n \sumα_ny_nz_n ∑αnynzn就出来了。③是因为sigma的每一项都要是0(KKT下),所以就 = 0,对于α2(w-3)的问题,感觉可以不用管具体w和yn,zn怎么弄的,总之整体要为0就是了。
P8 2.3
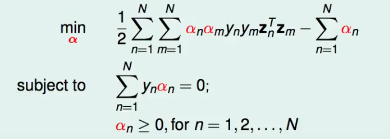
把上节的式子简单化简一下,max->min,然后把平方化开。不加上w = … 的条件是因为这个十字关注点是在 αn 上。然后发现这是个凸(convex)QP问题,有N个变量(αn),然后又N+1的条件(constraint)(N个αn要大于零,1个 ∑ n = 1 N y n α n = 0 \sum_{n=1}^N y_nα_n=0 ∑n=1Nynαn=0,共N+1个),然后开始套QP。

注:一般QP输入的时候可以不用把"="拆成两个不等式,直接写,然后范围bound也可以直接写。

然而,注意到q是dense的,稠密的矩阵,即里面的值很多不是非零的,计算量和存储量很大,所以要用一个专门为SVM设计的方法。

通过KKT的4个条件,我们可以推出w和b。特别的,当 α n > 0 α_n>0 αn>0的时候, 1 − y n ∗ ( w T z n + b ) = 1 1-y_n*(w^Tz_n+b) = 1 1−yn∗(wTzn+b)=1,而=1 恰好表示点是在SVM胖胖的边界上的(fat boundary),至于为什么嘛。。估计又得看看超平面了。

P9 2.4

我们在上节知道了α > 0 的时候,点在边界上。但是在分类线上的点不一定支持向量(可能有α = 0的情况),所以现在称α>0的点为support vectors(SV),仅针对这些SV(就是α>0的)做研究,范围可能会缩小一些。

因此 w和b 都可以只靠SV算出来,因为不是SV的话,即 α = 0 的话,它俩没有意义。
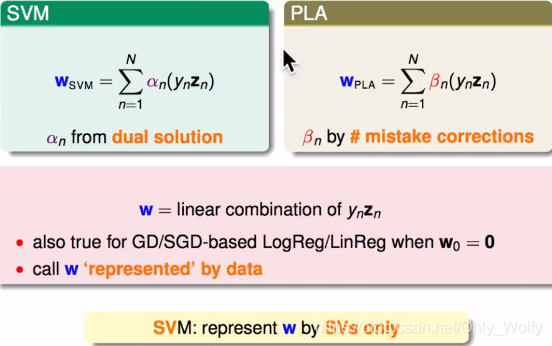
SVM和PLA的式子很像,他们都是 y n z n y_nz_n ynzn的线性组合,其他的w也差不多,可以说,w是资料表现出来的。SVM中的w是只由SV表示的,PLA则是由犯错的点表示出来。哲学上,我们要知道要用什么东西,来表现我们的w。

对比两种SVM的表示方法:原始(primal)和对偶(dual),hard-margin就是ooxx严格分类不容出错的意思。一般是用Dual SVM。

最后:虽然说dual svm只和N有关,但其实 d~藏在了q中,接下来会讲解怎么避开这个 d~。
最最后的总结:
