一、前言
如何快速搭建图像分割网络? 要手写把backbone ,手写decoder 吗? 介绍一个分割神器,分分钟搭建一个分割网络。
仓库的地址:
https://github.com/qubvel/segmentation_models.pytorch
该库的主要特点是:
- 高级 API(只需两行即可创建神经网络)
- 用于二元和多类分割的 9 种模型架构(包括传奇的 Unet) 124 个可用编码器(以及 timm 的 500 多个编码器)
- 所有编码器都有预先训练的权重,以实现更快更好的收敛
- 训练例程的流行指标和损失
二、快速引入—使用 SMP 创建您的第一个分割模型
分割模型只是一个 PyTorch nn.Module,创建起来很简单:
import segmentation_models_pytorch as smp
model = smp.Unet(
encoder_name="resnet34", # choose encoder, e.g. mobilenet_v2 or efficientnet-b7
encoder_weights="imagenet", # use `imagenet` pre-trained weights for encoder initialization
in_channels=1, # model input channels (1 for gray-scale images, 3 for RGB, etc.)
classes=3, # model output channels (number of classes in your dataset)
)
三、Architectures
我们可以用到的 model 有:
- Unet
- Unet++
- MAnet
- Linknet
- FPN
- PSPNet
- PAN
- DeepLabV3
- DeepLabV3+
3.1 UNet
UNet是一种常用于图像分割任务的深度学习架构。它由Olaf Ronneberger、Philipp Fischer和Thomas Brox于2015年在他们的论文《U-Net: Convolutional Networks for Biomedical Image Segmentation》中提出。
UNet的名字来自其U形的网络结构。它的设计目标是从输入图像中捕获低层次和高层次特征,然后利用这些信息生成像素级别的分割掩码。UNet在医学图像分析中特别受欢迎,因为它对于分割器官、肿瘤和其他感兴趣的结构非常有效。
UNet架构主要由两个部分组成:
-
收缩路径:该部分类似于典型的卷积神经网络架构,包含多个卷积和池化层。它被称为"收缩路径",因为每个卷积层减小空间维度,同时增加特征通道数量。
-
扩展路径:该部分涉及将特征映射进行上采样,恢复原始空间维度。它被称为"扩展路径",因为它增加空间维度,同时减少特征通道数量。
在U形架构的中心,有一个瓶颈层,它保留了局部和全局的上下文信息。
收缩路径和扩展路径是对称的,并通过跳跃连接相连接。这些跳跃连接有助于在上采样过程中保留细粒度的空间信息,使UNet特别适合图像分割任务。
在原始的UNet论文中,作者将该架构应用于生物医学图像分割任务,例如在电子显微镜数据中分割神经结构。然而,自那时以来,UNet架构已广泛应用于其他领域的图像分割任务,如自然图像、卫星图像等。
由于其有效性,UNet已成为各种扩展和改进的基础,并且在深度学习领域仍然是图像分割任务的热门选择。
3.2 UNet++
Unet++是对UNet进行改进和扩展的深度学习架构。它是由Zhou et al.于2018年在论文《UNet++: A Nested U-Net Architecture for Medical Image Segmentation》中提出的。
Unet++在原始UNet的基础上增加了一些重要的结构来提高图像分割的性能。主要的改进是引入了多层级的嵌套结构,使得模型能够更好地捕获不同尺度下的特征信息。以下是Unet++的主要特点:
-
多层级嵌套:Unet++采用了一种层级嵌套的结构,将UNet的每个阶段进行进一步细分。这样可以在不同的阶段获取更多的细节和语义信息,从而提高了分割的准确性。
-
密集跳跃连接:Unet++引入了密集的跳跃连接,将不同层级的特征图进行融合。这样可以使低层级的特征图能够直接参与到高层级的特征表示中,有助于更好地整合多尺度的信息。
-
自适应选择性上采样:在Unet++的解码器部分,采用了自适应选择性上采样技术,根据不同特征图的重要性进行选择性地上采样。这样可以减少计算量,并且避免了不必要的信息传递。
通过这些改进,Unet++在医学图像分割等任务中取得了较好的性能,相对于原始UNet,它能够更准确地定位和分割感兴趣的目标结构。
需要注意的是,自从Unet++的提出以来,还可能有其他进一步的改进和扩展,因为深度学习领域一直在不断发展和演进。
3.3 FPN
**FPN是"Feature Pyramid Network" 的缩写,是一种用于目标检测和语义分割任务的深度学习架构。它由Tsung-Yi Lin、Piotr Dollár、Ross Girshick和Kaiming He于2017年在论文《Feature Pyramid Networks for Object Detection》中提出。
FPN的目标是解决多尺度信息的问题。在许多计算机视觉任务中,目标可能在图像的不同尺度下出现,而且较小的目标可能在较低层级的特征图中丢失细节。FPN通过构建特征金字塔来解决这个问题。
FPN的主要思想是将不同层级的特征图进行融合,以提取多尺度的特征信息。它包含以下主要组件:
- 底层特征:从卷积神经网络的底层获得的特征图。这些特征图具有高分辨率但缺乏语义信息。
- 顶层特征:从网络的顶层获得的特征图。这些特征图具有较低的分辨率但包含丰富的语义信息。
FPN的构建过程如下:
-
首先,通过一个卷积层,将顶层特征图的通道数降低,使其与底层特征图的通道数相同。
-
然后,将降低通道数的顶层特征图与底层特征图相加,产生一组新的特征图,这些特征图在不同的层级上融合了多尺度的信息。
-
接下来,将融合后的特征图通过上采样操作(通常使用插值方法)增加分辨率,得到高分辨率的多尺度特征金字塔。
FPN的特征金字塔允许目标检测器或分割器在不同尺度下检测或分割目标,从而显著提高了算法的性能。由于其有效性和简单性,FPN已成为许多目标检测和语义分割任务的常用组件,并被广泛应用于许多深度学习模型中。
3.4 DeepLabV3
DeepLabV3是用于图像语义分割的深度学习模型,由Google于2018年推出。它是DeepLab系列模型的第三个版本,是对前两个版本的改进和扩展。
DeepLabV3的目标是对输入图像的每个像素进行分类,将每个像素标记为属于不同类别的某个目标或背景。该模型在图像分割任务中取得了很好的性能,尤其在细粒度的分割和边界细化方面表现出色。
主要的改进点包括:
-
空洞卷积(Atrous Convolution):DeepLabV3引入了空洞卷积来增大感受野,允许模型在保持计算效率的同时,获取更大范围的上下文信息。这有助于识别更大和更细微的目标。
-
多尺度信息融合:为了解决多尺度信息的问题,DeepLabV3使用了多尺度空洞卷积,将不同尺度的信息进行融合,从而提高了模型的语义分割性能。
-
引入特征金字塔池化(ASPP):ASPP模块进一步增加了感受野,帮助模型更好地理解图像中的上下文信息。ASPP模块由一组并行的空洞卷积层组成,每个卷积层的空洞率不同,从而捕获不同尺度的信息。
-
使用深度可分离卷积:为了减少模型的参数量和计算量,DeepLabV3采用了深度可分离卷积,这是一种将标准卷积分解为深度卷积和逐点卷积的方法。
DeepLabV3模型在PASCAL VOC 2012和Cityscapes等图像分割数据集上取得了显著的性能提升,成为当时图像语义分割领域的先进模型。其优秀的性能使得DeepLabV3被广泛应用于许多图像分割任务,特别是在需要准确分割细节的场景中。
四、Encoders
以下是 SMP 中支持的编码器列表。 选择适当的编码器系列,然后单击展开表格并选择特定的编码器及其预训练权重(encoder_name 和encoder_weights 参数)。
- ResNet
- ResNeXt
- ResNeSt
- Res2Ne(X)t
- RegNet(x/y)
- GERNet
- SE-Net
- SK-ResNe(X)t
- DenseNet
- Inception
- EfficientNet
- MobileNet
- DPN
- VGG
- Mix Vision Transformer
- MobileOne
我这里只展示其中一个,以 ResNet 为例:
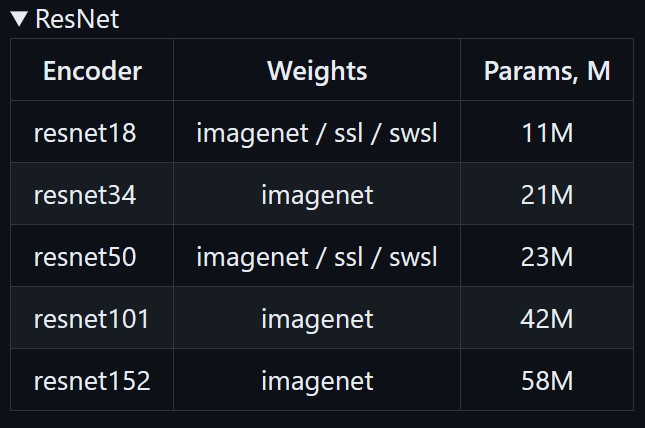
更多权重详见我的kaggle数据集:
https://www.kaggle.com/datasets/holmes0610/pretrained-resnet-resnext
https://www.kaggle.com/datasets/holmes0610/timm-pretrained
Pytorch 图像模型(又名 timm)有很多预训练模型和接口,允许使用这些模型作为 smp 中的编码器,但是,并非所有模型都受支持。
- 并非所有 Transformer 模型都实现了编码器所需的 features_only 功能
- 一些模型的步幅不合适
支持的编码器总数:549
https://smp.readthedocs.io/en/latest/encoders_timm.html
这个网址里面总结了所有可用的 Encoders。
五、Models API
- model.encoder:预训练主干提取不同空间分辨率的特征
- model.decoder:取决于模型架构(Unet / Linknet / PSPNet / FPN)
- model.segmentation_head:最后一个块产生所需数量的掩模通道(还包括可选的上采样和激活)
- model.classification_head:在编码器顶部创建分类头的可选块
- model.forward(x):按顺序将 x 通过模型的编码器、解码器和分段头(以及分类头,如果指定)
六、安装
PyPI version:
pip install segmentation-models-pytorch
Latest version from source:
pip install git+https://github.com/qubvel/segmentation_models.pytorch