背景介绍
首先要讲一个故事,不知道那个经纬度有个地方有两个部落,分别是 红点部落 和 绿点部落
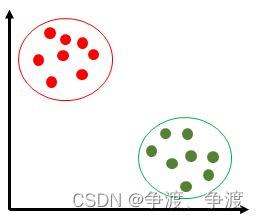
在他们的圈圈里有很多个居民—— 小点,红点部落的居民在他们部落内是红色,绿点部落的居民在他们部落内是绿色,两个部落的居民都偶尔会出来狩猎,但是当他们从部落里面出来之后就会变成灰色
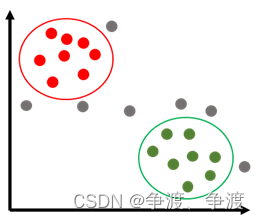
由于部落的居民都有群聚习惯,所以他们会离自己的部落更近一些才更优安全感,如果我想知道一个灰色的家伙是属于什么颜色的,只需要看他离那个部落更近一些就知道了,但是这个时候有一个大胆的家伙灰长大胆走到了两个部落的中间位置。
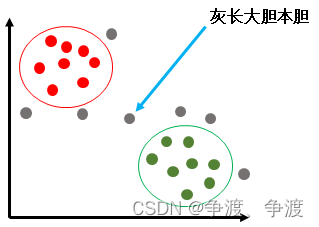
为了弄清楚灰长大胆属于哪个部落,科学家们根据两个部落居民的群聚特性对灰长大胆和两个部落内全部居民的坐标进行定位,并计算他们之间的距离。
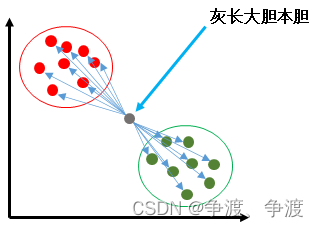
然后找到离灰长大胆最近的k个居民,并查看他们的护照,结果发现有一大部分都是绿点部落的人,然后就下定结论:灰长大胆属于绿点部落!
这也就是为什么这种分类算法叫做“k-近邻算法”
实际应用
在实际应用中大多数时候并不会用到距离这个概念,但是可以通过一定的方式把各个指标转变为距离信息。
例如,如果我们想评价一个人的胖瘦就可以用这种方法,比如横坐标是身高,纵坐标是体重。
我不知道灰长大胆是胖还是瘦,也不知道胖瘦的标准。但是我知道有很多胖子和瘦子的身高和体重,我只需要对这群胖子的和瘦子的体重和身高做简单的归一化之后,同样带入归一化后的灰长大胆的身高和体重计算就可以。
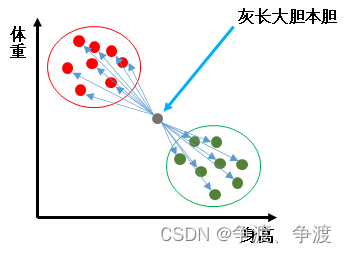
计算结果发现跟灰长大胆身高体重更接近的k=7个人,其中有5个都是瘦子,那么就认为灰长大胆是个瘦子,所以k一般选奇数。
但是出乎意料的是,如此简单粗暴的方法准确率却出了奇的高。缺点是如果样本比较大(已知胖子和瘦子特别多),且评价指标(身高、体重、肤色、年龄等)又比较多的时候计算效率就会很慢。