目录
4.1.1 第一种写法:sum()over( partition by ..)
4.1.2 第二种写法:sum()over( order by ..)
4.1.3 第三种写法:sum()over( partition by .. order by .. )

4.2.2 第二种写法:count()over( partition by ..)
4.2.3 第三种写法:count()over( order by ..)
4.2.4 第四种写法:count()over( partition by .. order by ..)
4.3.2 第二种方式 avg()over(partition by ..)
4.3.3 第三种方式 avg()over(order by ..)
4.3.4 第四种方式 avg()over(partition by .. order by ..)
4.4.2 第二种写法:min()over(partition by ..)
4.4.3 第三种写法:min()over(order by ..)
4.4.4 第四种写法:min()over(partition by .. order by ..)
4.5.2 第二种写法:max()over(partition by ..)
4.5.3 第三种写法:max()over(order by ..)
4.5.4 第四种写法:max()over(partition by .. order by ..)
前提准备:Student 表

--创建Student表
CREATE TABLE STUDENT(
"ID" NUMBER(11,0) PRIMARY KEY NOT NULL,
"STUDENT_NAME" VARCHAR2(255 BYTE),
"CLASS_NAME" VARCHAR2(255 BYTE),
"SCORE" NUMBER(18,0)
)
--插入数据
INSERT INTO "CERPAWCSADM"."STUDENT" VALUES ('1', 'Tom', '1班', '60');
INSERT INTO "CERPAWCSADM"."STUDENT" VALUES ('2', 'Mary', '2班', '77');
INSERT INTO "CERPAWCSADM"."STUDENT" VALUES ('3', 'Timir', '1班', '80');
INSERT INTO "CERPAWCSADM"."STUDENT" VALUES ('4', 'Airo', '1班', '99');
INSERT INTO "CERPAWCSADM"."STUDENT" VALUES ('5', '小红', '2班', '80');
INSERT INTO "CERPAWCSADM"."STUDENT" VALUES ('6', '小美', '3班', '65');1、rank()over(..)
语法:rank()over( partition by 要分区的字段 order by 要排序的字段)
其中 order by 必须写,不写会报错,partition by 可以省略
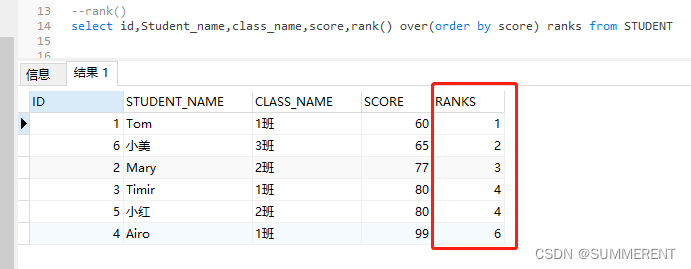
1.1 根据score 升序排序,ranks 为排序后的序号,从1开始,依次递增,如果有两个重复的score则序号会一样(下图中的score = 80,则ranks = 4),因为两个为4的序号,所以接着跳到序号6
select id,Student_name,class_name,score,rank() over(order by score) ranks from STUDENT
1.2 根据class_name分区(相当于分组),然后在根据score 升序排序,ranks 为排序后的序号,从1开始,依次递增,如果存在重复数据则跳过序号
select id,Student_name,class_name,score,rank() over(partition by class_name order by score) ranks from STUDENT

2、row_number()over(..)
语法:row_number()over( partition by 要分区的字段 order by 要排序的字段)
其中 order by 必须写,不写会报错,partition by 可以省略
2.1 根据score 升序排序,ranks 为排序后的序号,从1开始,依次递增,无论是否有重复的score则序号为递增,不会跳序号
select id,Student_name,class_name,score,row_number() over(order by score) ranks from STUDENT

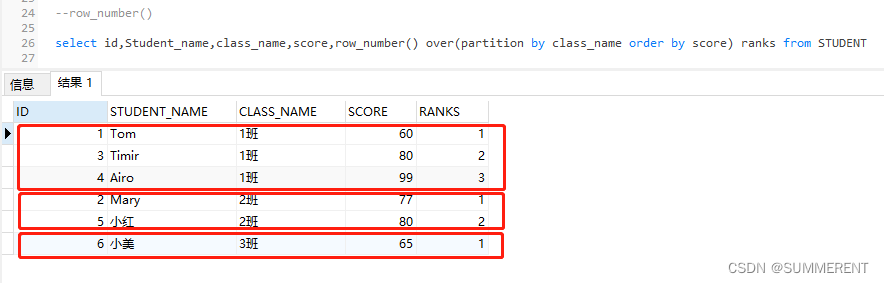
2.2 根据class_name分区(相当于分组),然后在根据score 升序排序,ranks 为排序后的序号,从1开始,依次递增,不会跳号
select id,Student_name,class_name,score,row_number() over(partition by class_name order by score) ranks from STUDENT
3、dense_rank()over(..)
语法:dense_rank()over( partition by 要分区的字段 order by 要排序的字段)
其中 order by 必须写,不写会报错,partition by 可以省略
3.1 根据score 升序排序,ranks 为排序后的序号,从1开始,依次递增,如果有两个重复的score则序号会一样(下图中的score = 80,则ranks = 4),接着序号为5
select id,Student_name,class_name,score,dense_rank() over(order by score) ranks from STUDENT

4、聚合函数配合使用 over
语法:sum() / count() / avg() / min() / max() over( partition by 要分区的字段 order by 要排序的字段)
语法含义:sum() over 根据条件累计数据 (4.1中已详细说明)
count() over 根据条件统计行数
avg() over 根据条件求平均值
min() over 根据条件求最小值
max() over 根据条件求最大值
其中 partition by 和 order by 可以全部写上,也可以写其中一个,也可以全部都不写
4.1 sum()over(..)
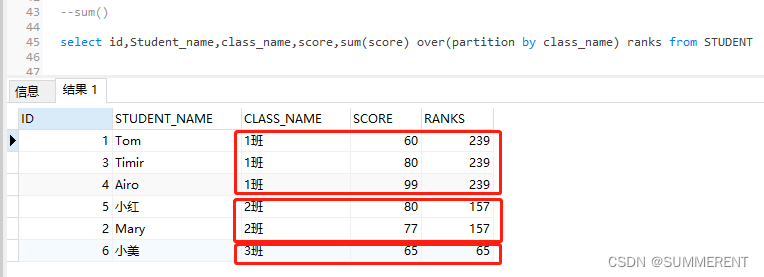
4.1.1 第一种写法:sum()over( partition by ..)
先根据class_name 分区(分组),然后对score 进行求和,看结果Ranks列
select id,Student_name,class_name,score,sum(score) over(partition by class_name) ranks from STUDENT
4.1.2 第二种写法:sum()over( order by ..)
先根据score 排序,然后 根据score 依次进行累加,看累加结果Ranks列
select id,Student_name,class_name,score,sum(score) over(order by score) ranks from STUDENT

4.1.3 第三种写法:sum()over( partition by .. order by .. )
先根据class_name 分区(分组),在根据score 排序,根据分区对score依次进行累加,看累加结果Ranks列
select id,Student_name,class_name,score,sum(score) over(partition by class_name order by score) ranks from STUDENT

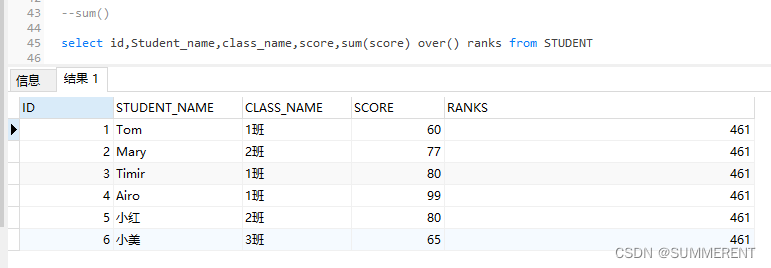
4.1.4 第四种写法:sum()over()
累加所有的score值,看累加结果Ranks列
select id,Student_name,class_name,score,sum(score) over() ranks from STUDENT
4.2 count()over(..)
4.2.1 第一种写法:count()over()
统计所有行数
select id,Student_name,class_name,score,count(*) over() studentCount from STUDENT

4.2.2 第二种写法:count()over( partition by ..)
根据class_name 分区统计学生人数
select id,Student_name,class_name,score,count(student_name) over(partition by class_name) studentCount from STUDENT

4.2.3 第三种写法:count()over( order by ..)
根据score排序,依次累计统计行数,注意看如果分数相同的情况下,接着统计相同的studentCount为:上一次统计到的数(3)+相同score数量(2)= 5,接下来就是依次排序为6

4.2.4 第四种写法:count()over( partition by .. order by ..)
根据class_name 分区,然后根据score排序,依次累计统计行数
select id,Student_name,class_name,score,count(student_name) over(partition by class_name order by score) studentCount from STUDENT

4.3 avg()over(..)
4.3.1 第一种方式 avg()over()
求所有score的平均值
select id,Student_name,class_name,score,AVG(score) over() ranks from STUDENT

4.3.2 第二种方式 avg()over(partition by ..)
根据class_name分区,求每个班级成绩score的平均值
select id,Student_name,class_name,score,AVG(score) over(partition by class_name) ranks from STUDENT

4.3.3 第三种方式 avg()over(order by ..)
根据score排序,累加计算score的平均值
select id,Student_name,class_name,score,AVG(score) over(order by score) ranks from STUDENT

4.3.4 第四种方式 avg()over(partition by .. order by ..)
根据class_name分区然后根据score排序,累加计算(各个分区内)score的平均值
select id,Student_name,class_name,score,AVG(score) over(partition by class_name order by score) ranks from STUDENT

4.4 min()over(..)
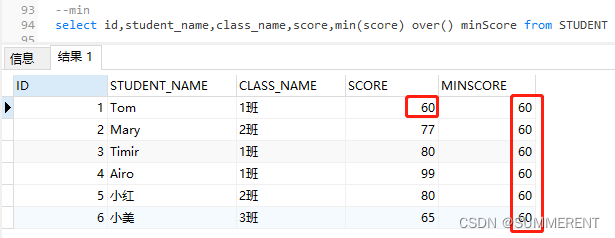
4.4.1 第一种写法:min()over()
求全部学生成绩score最低分
select id,student_name,class_name,score,min(score) over() minScore from STUDENT
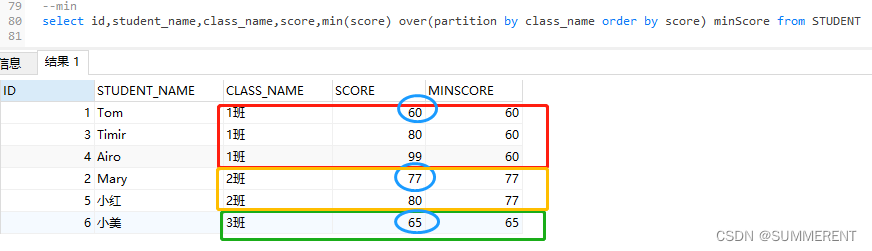
4.4.2 第二种写法:min()over(partition by ..)
根据class_name分区,求每个班级学生成绩score最低分
select id,student_name,class_name,score,min(score) over(partition by class_name ) minScore from STUDENT

4.4.3 第三种写法:min()over(order by ..)
根据score排序,求所有学生成绩score最低分
注意:min over(order by score )是升序排序求最小值,对于(order by score desc)是降序排序没有作用
select id,student_name,class_name,score,min(score) over(order by score ) minScore from STUDENT

4.4.4 第四种写法:min()over(partition by .. order by ..)
根据class_name分区,然后根据score排序,求每个班级学生成绩score最低分
注意:使用 order by score 是升序排序求最小值,对于order by score desc 是降序排序没有作用
select id,student_name,class_name,score,min(score) over(partition by class_name order by score) minScore from STUDENT
4.5 max()over(..)
4.5.1 第一种写法:max()over()
求全部学生成绩score最高分
select id,student_name,class_name,score,max(score) over() maxScore from STUDENT

4.5.2 第二种写法:max()over(partition by ..)
根据class_name分区,求每个班级学生成绩score最高分
select id,student_name,class_name,score,max(score) over(partition by class_name) maxScore from STUDENT

4.5.3 第三种写法:max()over(order by ..)
根据score排序,求所有学生成绩score最高分
注意:max over(order by score desc)是降序排序求最大值,对于(order by score)是升序排序没有作用
select id,student_name,class_name,score,max(score) over(order by score desc) maxScore from STUDENT

4.5.4 第四种写法:max()over(partition by .. order by ..)
根据class_name分区,然后根据score排序,求每个班级学生成绩score最高分
注意:使用 order by score desc 是降序排序求最大值,对于order by score 是升序排序没有作用
select id,student_name,class_name,score,max(score) over(partition by class_name order by score desc) maxScore from STUDENT

5、案例: 根据 601. 体育馆的人流量 改编
编写一个 SQL 查询学生分数大于或等于 80且
id连续的三行或更多行记录,返回结果按照班级名升序排序
子查询第一种写法:
select b.id,b.Student_name,b.class_name,b.score from
(select a.id,a.Student_name,a.class_name,a.score,count(*) over(partition by a.a1) a2 from
-- a2 表示根据a1分区统计数量
(
select id,Student_name,class_name,score,id - row_number() over(order by id) a1
-- a1 表示的是id 是否连续,也就是id - row_number()的值是否相同
from STUDENT where score >= 80 -- 分数大于或等于 80
) a
)b
where b.a2>=3 order by b.class_name --找出结果大于3条的并且根据班名升序排序
子查询第二种写法:
with a as
(
select id,Student_name,class_name,score,id - row_number() over(order by id) a1
from STUDENT where score >= 80
),
b as
(
select id,Student_name,class_name,score,count(*) over(partition by a1) a2 from a
)
select id,Student_name,class_name,score from b where b.a2>=3 order by b.class_name