一、背景与目标
我们业务维护了两个代码仓库,两端的代码很多都是一个平台先开发好,几乎直接copy到另一个仓库。于是产生了一个技术需求,实现这两个仓库代码复用。在技术预研阶段,需要统计早先copy的代码文件有多少,提前预估双端代码的大概可复用文件比例。早先我是利用Beyond Compare 手动遍历文件,依据“肉眼”去对比的,花了大概一天的时间,而且估计的数据比较粗略。考虑到这个工作以后还会碰到,而且这个过程就是纯粹机械的文件“相似度”对比,所以期望这个过程可以采取自动化脚本完成。大家都经历过论文查重,主流的有PaperPass、中国知网等;不同的是,我要做的是一个批量文件的对比,当然它的每一步其实是两个文件之间的相似度比较。之前有人推荐我用simian等工具,很短时间就能完成对比,可以设定相似代码行数的阈值,并且可以输出相似代码。我觉得这款工具的确是好,但是毕竟是第三方工具,算法不可控,还收费。而且我们重复的不仅有代码,还有重复图片。
二、算法的设计
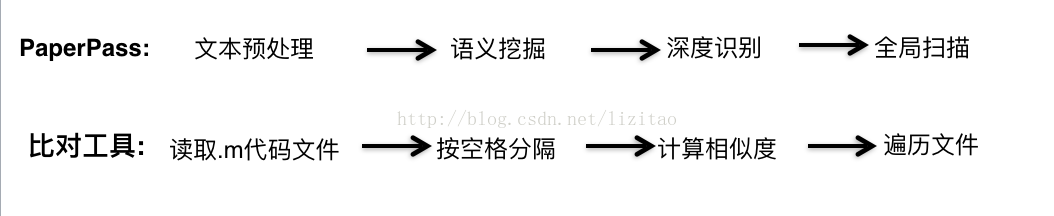
大家在学校论文查重时,应该用过至少听说够PaperPass。PaperPass文件比对是以句子为单位检测的,它的对比过程大致是文本预处理、语义挖掘、深度识别、全局扫描等,如下:

当然,具体还会涉及文字颜色、大小的比对,比较复杂。我们来看一下PaperPass的处理大致过程:t是要对比的文章,T是PP的论文库,S是重复计数器,M是分割后的t的string数据大小:

然后开始遍历查找,具体操作状态如下:

查找到则S=S+1,否则,t数组继续遍历,
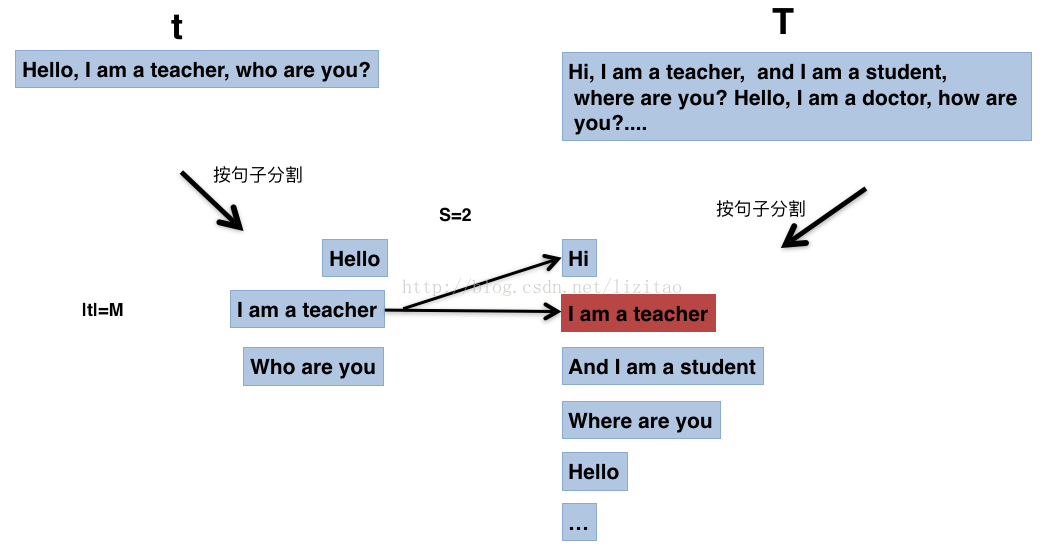
直到t数据遍历完,循环结束。
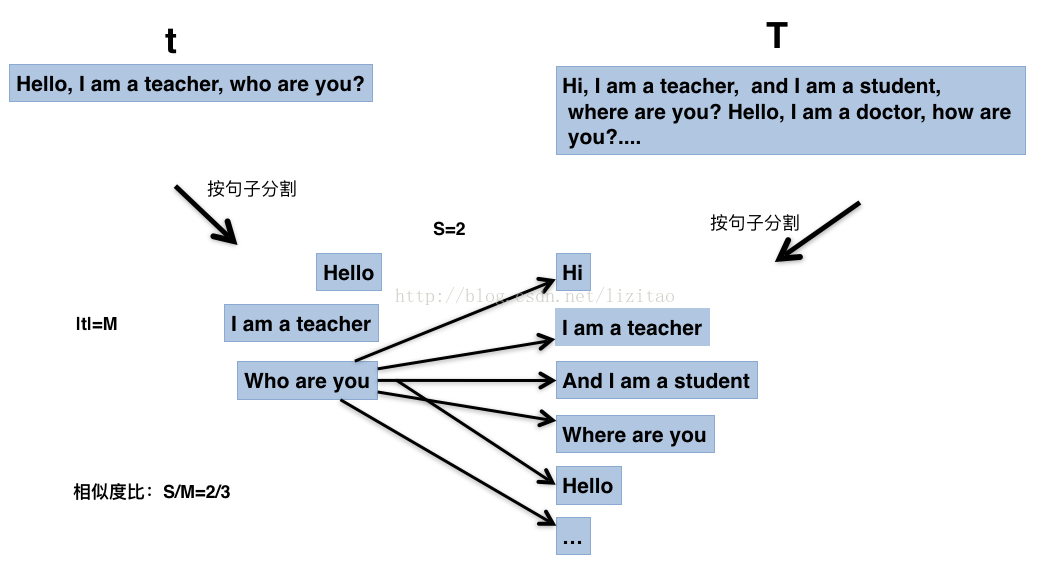
那么t文章的相似比例为2/3。
但是这样的算法对于代码比对来说,有下面两个问题:
1、PP是以句子为单位检测的,但是代码不是简单的句子分隔,如下:

2、既然代码文件不能按语句分隔,该如下结合代码copy场景找到最佳的分隔单位呢?是按空格、还是按行呢?

实际copy常常会因人习惯不同,增加些个人习惯的换行,尤其“左大括号换行派”与不换行派的互相copy代码的时候有一定的误差;我们来看看按空格分隔,分隔后的数组示意图如下:
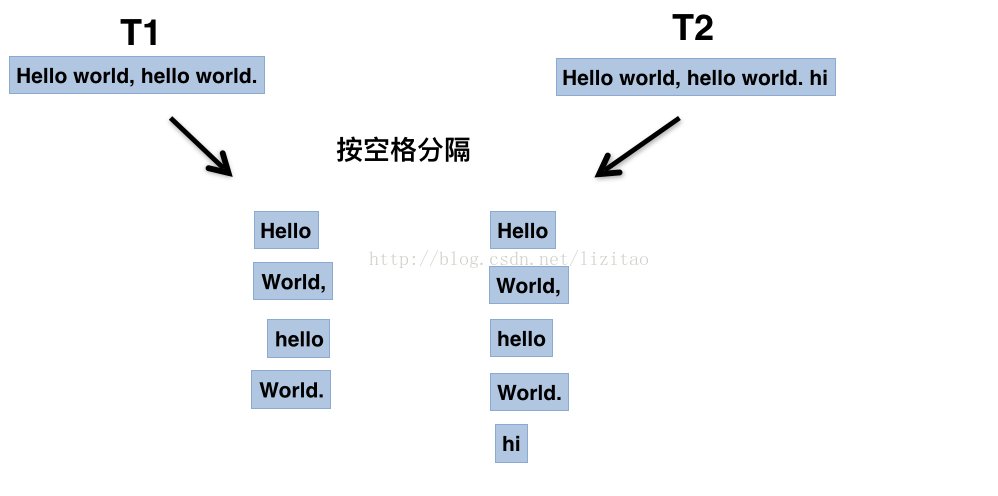
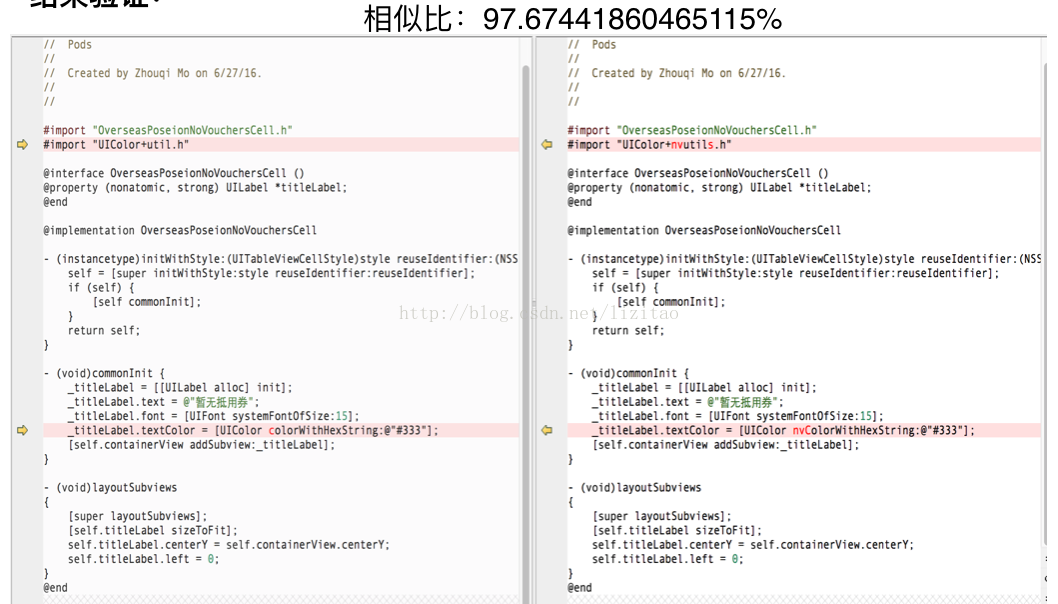
根据这个分隔原理,我用ruby脚本憝了这个算法,并验证了下算法的情况,如下:

三、工具的原理
上面内容已经基本验证了按空格分隔的效果,根据PaperPass的过程,写了一个完整的工具,进行扫描:
我可以根据工具进行灵活性调整,筛选出相似比超过90%的文件或者其他。
四、算法的不足与改进
这个小工具的目的本身就是为了方便自己使用,出发点也没打算做的很牛逼,没有花过多时间去改进它,但是还是有很多方案可以改进这个算法提升比对效率的:
1、由于算法的比对以及遍历工程目录下的文件时,使用的都是“暴力”循环遍历,时间复杂度较高,我最高比对库代码达到7000个.m文件,脚本执行了一天没跑完;后来执行时,去除了不必要的底层pod代码库,只对比了业务层的代码,发现不到2小时,就跑完了。
2、中间也提过,如果你不想那么精确地比对,可以按单行进行分隔,或者按多行为分隔单位。
3、原子算法的复杂度是O(n2)的,如果再想着优化,就要优化原子算法本身了。对于T1文件与T2文件的比对过程中,如果发现T1中的某一行在T2中找不到重复的(这种情况应该是较大概率的),可以对T1针对这一行进行一次去重处理O(n);如果这一行在T2中找到了,去重处理并且计数器S累加。如果想把复杂度降到O(nlogn),那么恐怕要采取二叉树这样的数据结构去处理T2了。
4、针对代码文件,我们发现前面几行文本往往都是很相似的,这些文本的对比会影响代码内容的相似度的精确性,例如:
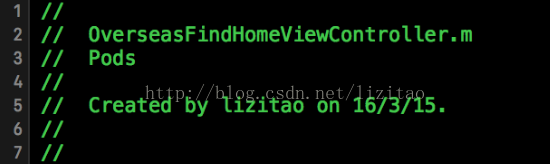
我们也可以直接过滤掉这些代码段。