获奖啦!
比赛题目:中文语义病句识别与纠正挑战赛
比赛链接:https://challenge.xfyun.cn/topic/info?type=identification-and-correction&option=phb
“请介绍你们团队”
“各位评委老师,我是来自WOT团队的选手AMBT,口号是将中文语义病句识别与纠正提升到新高度”
“你们参加比赛的初衷是什么?”
“为了中文自然语言处理崛起而奋斗”
“请AMBT务实一点”
“为了参赛拿奖金买坦克”
“请介绍你们解决问题的思路”
“我们将中文语义病句识别与纠正分成【识别】与【纠正】两个流水线任务,先识别出哪些是病句,然后对病句进行修正。识别是否病句基于传统预训练模型+是否为病句进行二分类微调,修正基于端到端以及LLM进行微调,生成病句纠正之后的正确句子”
文字过多,下面直接贴图了:

“你们比赛思路确实很全面,恭喜你们团队获得第一”
醒醒吧!
某日下午,“叮叮叮”,“叮叮叮”,“叮叮叮”,扭头一看桌面上手机响了,接了电话。
“请问你是来自中文语义病句识别与纠正挑战赛的top1团队是吧”
“对,请问你是”
“赛题方审核结果是存在违规使用其他标注数据行为,直接取消比赛成绩”
“请问赛题方检测出什么了”
“你们使用了2022年数据的标注”
后来扯皮了很久,后来苦苦婆心解释了一达通,就是直接取消成绩,对,就是这么残忍。

因为比赛规则里面确实规定了禁用额外标注数据,主办方说取消成绩也只能强忍头皮认了。

感触!
- 为什么会使用2022年的数据。
一个是没注意到比赛规则。另外一个就是大家可以翻一番这两个比赛任务和主办方是一样的,所以一开始做任务1的时候就理所当然用了去年数据:
2023年比赛链接:https://challenge.xfyun.cn/topic/info?type=identification-and-correction&option=phb
2022年比赛链接:https://challenge.xfyun.cn/topic/info?type=sick-sentence-discrimination

为什么有同样格式的、同样比赛任务、同样出题方的数据,能提升效果为啥不能用呢?是学术倒退还是野鸡反噬?是选手眼瞎还是规则严厉?
都不是!可能就是太“理所当然了”,太小看一个国内比赛剧本精彩程度了!
自己在复现方案里面如实提到了,也不是故意使用的,下面就是提交的复现说明。后来和他们沟通,重新跑一次没有使用去年数据的模型提交也不行,就是直接取消成绩!主办方应该是从这里看到的吧。
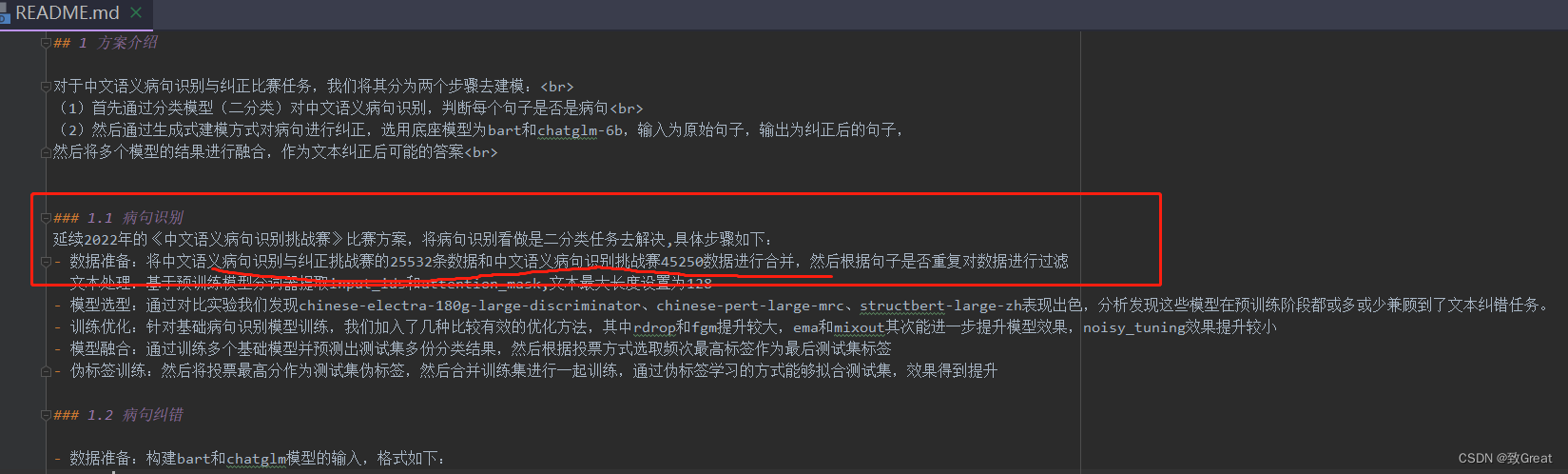
- 主办方与选手的关系
主办方到底有没有认真去复现选手的代码?
结合以往经历选手辛苦准备的从1GB到20GB代码和权重有没有去看过,更有甚者选手准备的百度云文件他们下载次数为0?
主办方确实可以拿着一个规则否定选手几个月的付出,这个时候选手略显苍白无力
你在键盘巧了几百字,几十行微信消息,可能被别人搪塞一句“我和主办方沟通了,确实不行”,其实是不是她下班回家,懒的管你?
- 选手应该怎么保护自己呢
仔仔细细看好规则,在规则下玩比赛。
野鸡有野鸡的玩法,用平常心态对待比赛,不要拿Kaggle视角对待国内比赛
记录证据,比赛和微信等相关,互联网是有痕迹的?
国内比赛还是挺香的,恰钱是不是挺香的,权衡利弊下好好想想怎么做到高性价比
比赛过程中的隐性利益冲突很多,学会躲避