在指标监控的世界里,应用和业务层面的监控有两种典型手段,一种是在应用程序里埋点,另一种是分析日志,从日志中提取指标。埋点的方式性能更好,也更灵活,只是对应用程序有一定侵入性,而分析日志的话对应用程序侵入性较小,但由于链路较长、需要做文本分析处理,性能较差,需要更多算力支持。
所谓的埋点,就是指应用程序内嵌了埋点的 SDK(一个 lib 库),然后在一些关键代码流程里调用 SDK 提供的方法,记录下各种关键指标。比如某个 HTTP 服务,提供了 10 个接口,每个接口的处理花费了多少毫秒,就可以作为指标记录下来。
核心原因是 SDK 可以帮我们封装一些通用的计算逻辑。比如有个指标是 Summary 类型,可以提供某个接口 99 分位的延迟数据。如果没有 SDK,我们需要怎么做呢?每当这个接口响应一次请求,就记录一个延迟时间,然后存入一个内存数据结构,等到一个时间间隔,比如 10 秒钟,就把这段时间内所有的延迟数据排个序,然后取 99 分位的值,最后调用 Pushgateway 的接口推过去。很麻烦是不是?
而 SDK 就是做这些通用逻辑的,应用程序要做的,就是拿到延迟数据之后,调用 SDK 的方法告知 SDK,说又有一次新的接口调用,延迟数据是多少,SDK 就能完成剩余所有的事情。
界比较知名的跨语言埋点工具是 StatsD 和 Prometheus。当然,有些语言有自己生态的常用工具,比如 Java 生态的 Micrometer,不过一般公司都会使用多种语言,这些跨语言的埋点方案通常使用频率会更高。
StatsD 有个很大的特点是使用 UDP 传输协议,大部分计算逻辑都挪到了 StatsD 的 Server,SDK 层面的工作非常轻量。
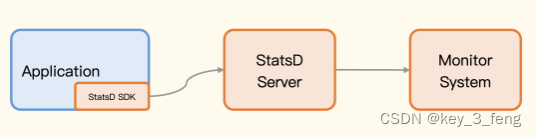
StatsD SDK 与 StatsD Server 之间通信使用的是 UDP 协议,UDP 协议是 fire-and-forget,无需建立连接,即使 StatsD Server 挂了,也不影响应用程序,而对于延迟分布区间这样的计算逻辑,是在 StatsD Server 里计算的,也不会影响应用程序,所以整个 StatsD 的设计是非常轻量的,对应用程序基本没有影响。
由于 StatsD 相当知名,所以很多采集器都实现了 StatsD 的协议,比如 Telegraf、Datadog-agent,也就是说,图上的 StatsD Server 是可以换成 Telegraf 或 Datadog-agent 的。这样就不用部署太多进程,一个采集器包打天下,就拿 Telegraf 来说吧,替换后架构就变成了这样。
Prometheus 的埋点方式跟 StatsD 很像,对于请求数量和延迟这样的监控指标,也是在请求处理完成之后,调用 SDK 的方法进行记录的。不过,如果每个方法都要加这么几行代码就显得太冗余了,最好还是通过 AOP 的方式做一些切面逻辑,Nightingale 的 Webapi 模块就是这么干的。
Webapi 的职能是提供一系列 HTTP 接口给 JavaScript 调用,我们需要监控这些接口的调用量、成功率、延迟数据。埋点之前我们先规划一下标签,我们给每个 HTTP 接口规划 4 个标签。
- service:服务名称,要求全局唯一,可以和其他服务区分开。
- code:HTTP 返回状态码,可以根据这个信息得知 4xx 的比例是多少,5xx 的比例是多少,计算成功率。
- path:接口路径,比如 /api/v1/users ,有时候我们会在接口路径中放置 URL 参数,比如 /api/v1/user/23、/api/v1/user/12 是请求 id 为 23 和 12 的用户信息。这个时候不能直接把这个 URL 作为接口路径的标签值,否则这个指标颗粒度就太细了,应该把接口路径的标签值设置成 /api/v1/user/:id。
- method:HTTP 方法,GET、POST、DELETE、PUT 等。
使用 StatsD 的埋点方式,数据通过 UDP 推给 Telegraf,Telegraf 推给后端监控系统。如果是通过 Prometheus 的方式来埋点,就是暴露 /metrics 接口,等待监控系统来拉。如果应用是部署在物理机或虚拟机上,直接通过本地的监控 agent 来拉取即可。如果应用是部署在 Kubernetes 的 Pod 里,则有两种办法来拉取数据,一个是 Sidecar 模式,一个是中心端服务发现的模式。下面这个示意图展示的是 Sidecar 模式。
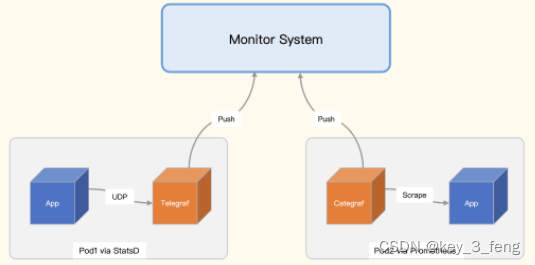
左侧 Pod1 里有两个容器,App 通过 StatsD 埋点,然后通过 UDP 推给 Telegraf,Telegraf 接收到数据之后做二次计算,把结果推给监控服务端;右侧 Pod2 里也有两个容器,App 通过 Prometheus SDK 埋点,暴露 /metrics 接口,Categraf 通过这个接口拉取数据,然后推给监控服务端。
这种方式的优点是比较灵活,Pod 内怎么做应用自己说了算。即使给 /metrics 接口增加一些认证鉴权、指标过滤、扩展标签的逻辑,都不影响其他的 Pod。数据是推给监控服务端的,监控服务端接收数据的组件可以做成无状态集群,前面架设负载均衡,整个架构非常简单、扩展性也很好。当然缺点也很明显,每个 Pod 里都伴生 Sidecar agent,浪费资源。

此文章为8月Day12学习笔记,内容来源于极客时间《运维监控系统实战笔记》,推荐该课程。