维基百科对深度学习的精确定义为“一类通过
多层
非线性变换对
高复杂度数据建模算法的合集”。
高复杂度是无法通过直线(或者高维空间的平面)划分的
一、线性模型的局限性
在线性模型中,模型的输出为输入的加权和。
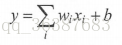
被称之为线性模型是因为当模型的输入只有一个的时候,X和Y形成了二维坐标系上的一条直线。当模型有N个输入时,X和Y形成了N+1维空间中的一个平面。
线性模型的最大特点是任意线性模型的组合仍然还是线性模型。只通过线性变换,任意层的全连接神经网络和单层神经网络模型的表达能力没有任何区别,而且他们都是线性模型。所以线性模型能够解决的问题是有限的。
在现实生活中,绝大部分问题都是无法线性分割的,所以我们要引入非线性激活函数。
二、激活函数
如果将每一个神经元(也就是神经网络中的节点)的输出通过一个非线性函数,那么整个神经网络的模型就不再是线性的了。
常用的激活函数有ReLU函数:f(x) = max(x, 0); sigmoid函数:f(x) = 1/(1+ e**(-x));
tanh函数:f(x) = (1-e**(-2x))/(1+e**(-2x))

三、多层网络解决异或运算
异或运算直观来说就是如果两个输入的符号相同时(同时为正或者同时为负)则输出为0,否则(一个正一个负)输出为1.
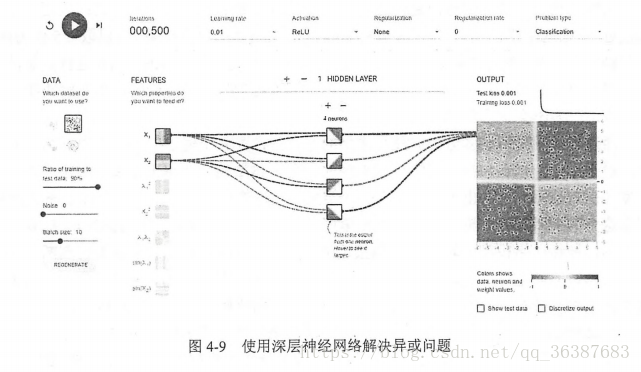
四个隐藏节点可以被认为代表了从输入特征中抽取的更高维的特征。比如第一个节点,可以大致代表了两个输入的逻辑和操作的结果(当两个输入都为正数时,该节点输出为正数)。这点有点迷糊,不知道怎么解释更合理。
四、损失函数
1、分类问题和回归问题是监督学习的两大种类。分类问题希望解决的是将不同的样本分到事先定义好的类别中。回归问题解决的是对具体数值的预测,比如房价预测,销量预测等。
2、通过神经网络解决多分类问题最常用的方法是设置N个输出节点,其中N为类别的个数。每个输出结果是一个N位的数组,数组中的每个维度对应一个类别。所以一般我们都把类别转换成one-hot类型。
3、我们用softmax回归处理输出的结果,转化为概率:
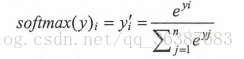 ,然后用交叉熵来刻画两个概率分布之间的距离。给定两个概率分布P和Q,通过Q来表示P的交叉熵为:
,然后用交叉熵来刻画两个概率分布之间的距离。给定两个概率分布P和Q,通过Q来表示P的交叉熵为:
 ,它刻画的是通过概率分布Q来表达概率分布P的困难程度。P代表的是正确答案,Q代表的是预测值,交叉熵越小,说明Q越接近P,也就是越正确。
,它刻画的是通过概率分布Q来表达概率分布P的困难程度。P代表的是正确答案,Q代表的是预测值,交叉熵越小,说明Q越接近P,也就是越正确。
,然后用交叉熵来刻画两个概率分布之间的距离。给定两个概率分布P和Q,通过Q来表示P的交叉熵为:
,它刻画的是通过概率分布Q来表达概率分布P的困难程度。P代表的是正确答案,Q代表的是预测值,交叉熵越小,说明Q越接近P,也就是越正确。
4、我们自己来实现以下交叉熵的计算公式:
cross_entropy = -tf.reduce_mean(y * tf.log(tf.clip_by_value(prediction, 1e-10, 1.0)))。
通过tf.clip_by_value()可以将张量中的数值限制在一个范围内,(小于min的全部赋值为min,大于max的全部赋值为max)可以避免一些运算错误(比如log0是无效的)。
通过计算可以得到一个N * M的二维矩阵,N是一个batch中样本数量,M为分类类别数。根据交叉熵的公式,应该将每行中的M个结果相加,然后除以N得到一个batch的平均交叉熵。
但是因为分类问题的类别数量是不变的,所以对整个矩阵做平均并不改变计算结果的意义。
5、回归问题最常用的损失函数是均方误差(MSE,mean squared error):

mse = tf.reduce_mean(tf.square(y - prediction))
6、在一些实际问题中,我们需要自定义损失函数,让神经网络优化的结果更加接近实际问题的需求。
比如预测销量,一个商品成本是1元,利润是10元,那么少预测一个就少挣10元,多预测一个只少挣1元。为了最大化利润,需要将损失函数和利润直接联系起来,因为是损失函数,所以用损失函数来刻画成本或代价。
以下公式给出一个当预测多与真实值和预测少于真实值有不同损失系数的损失函数:

loss = tf.reduce_sum(tf.where(tf.greater(v1, v2), (v1-v2) * a , (v2-v1) * b ))
tf.greater的输入是两个张量,比较两个张量中每一个元素的大小,并返回比较结果(布尔型)。当tf.greater的输入维度不一样时,TensorFlow会进行类似numpy广播操作(broadcasting)的处理。
tf.where函数有三个参数,第一个是选择条件,为True时,使用第二个参数的值,为false使用第三个参数的值。也就是C#的条件运算符。