文章目录
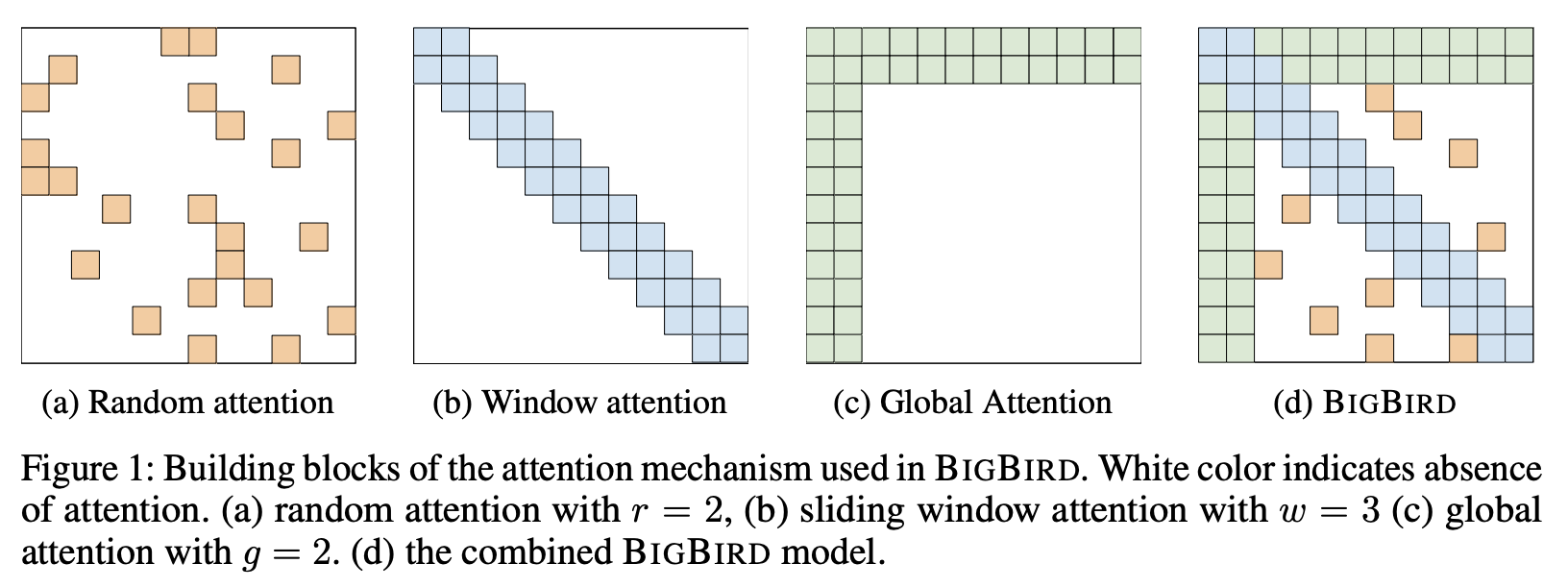
一、BigBird
BigBird 是一个具有稀疏注意力机制的 Transformer,可以将自注意力的二次依赖性减少到令牌数量的线性。 BigBird 是序列函数的通用逼近器,并且是图灵完备的,从而保留了二次全注意力模型的这些属性。 具体来说,BigBird 由三个主要部分组成:
一套参与序列所有部分的全局标记。
所有代币都参与一组本地相邻标记。
所有代币都参与一组随机令牌。
二、Levenshtein Transformer
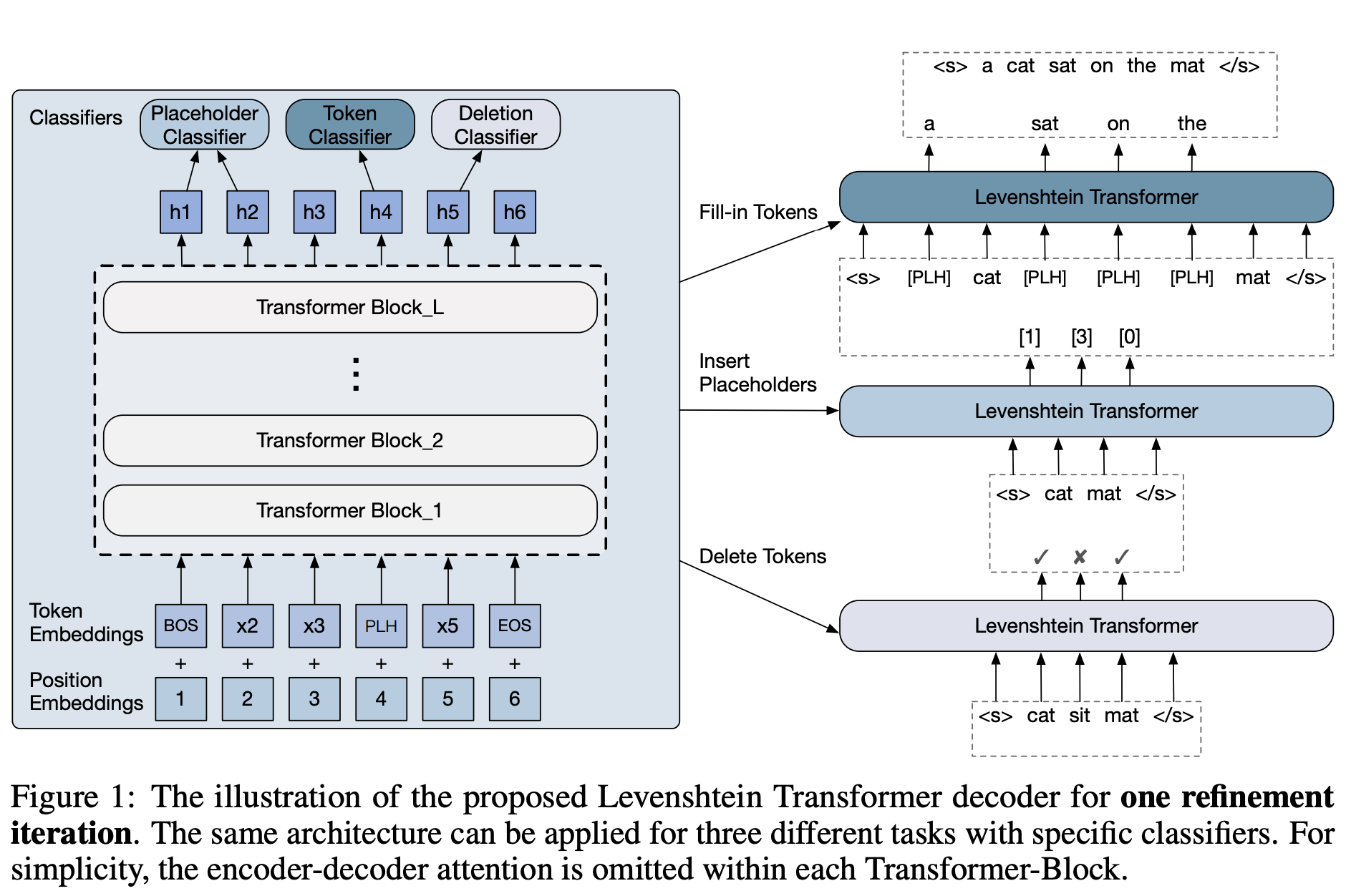
Levenshtein Transformer (LevT) 是一种变压器,旨在解决以前解码模型缺乏灵活性的问题。 值得注意的是,在以前的框架中,生成的序列的长度要么是固定的,要么随着解码的进行而单调增加。 作者认为这与人类水平的智能不相容,人类可以修改、替换、撤销或删除其生成文本的任何部分。 因此,LevT 被提出通过打破目前标准化的解码机制并用插入和删除这两个基本操作来代替它来弥补这一差距。
LevT 使用模仿学习进行训练。 结果模型包含两个策略,并且它们以交替方式执行。 作者认为,通过这种模型,解码变得更加灵活。 例如,当给解码器一个空令牌时,它会退回到正常的序列生成模型。 另一方面,当初始状态是低质量的生成序列时,解码器充当细化模型。
LevT 框架的关键组成部分之一是学习算法。 作者利用了插入和删除的特征——它们是互补的,但也是对抗的。 他们提出的算法称为“双策略学习”。 这个想法是,当训练一个策略(插入或删除)时,我们使用其对手在前一次迭代中的输出作为输入。 另一方面,专家政策则被用来提供修正信号。
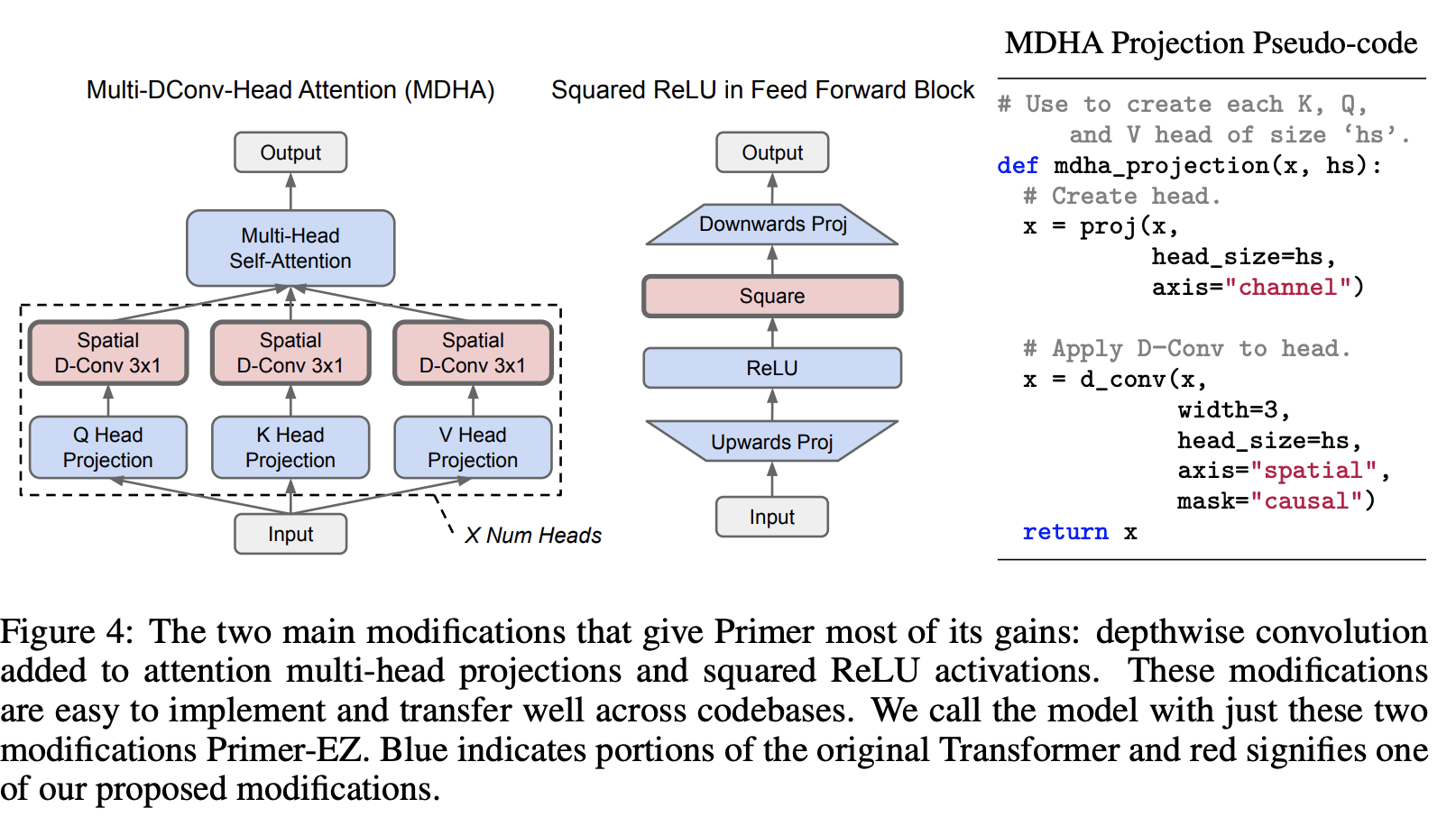
三、Primer
Primer 是一种基于 Transformer 的架构,它在 Transformer 架构的基础上进行了改进,通过神经架构搜索发现了两项改进:前馈块中的平方 RELU 激活,以及添加到注意力多头投影中的深度卷积:产生了一个名为 Multi- DConv-头部注意力。
四、ProphetNet
ProphetNet 是一种序列到序列的预训练模型,引入了一种称为未来 n 元语法预测的新型自监督目标和所提出的 n 流自注意力机制。 ProphetNet 没有优化传统序列到序列模型中的一步预测,而是通过以下方式进行优化:
预测下一步的超前预测在每个时间步基于先前的上下文标记同时标记。 未来的 n-gram 预测明确鼓励模型规划未来的 token,并进一步帮助预测多个未来的 token。

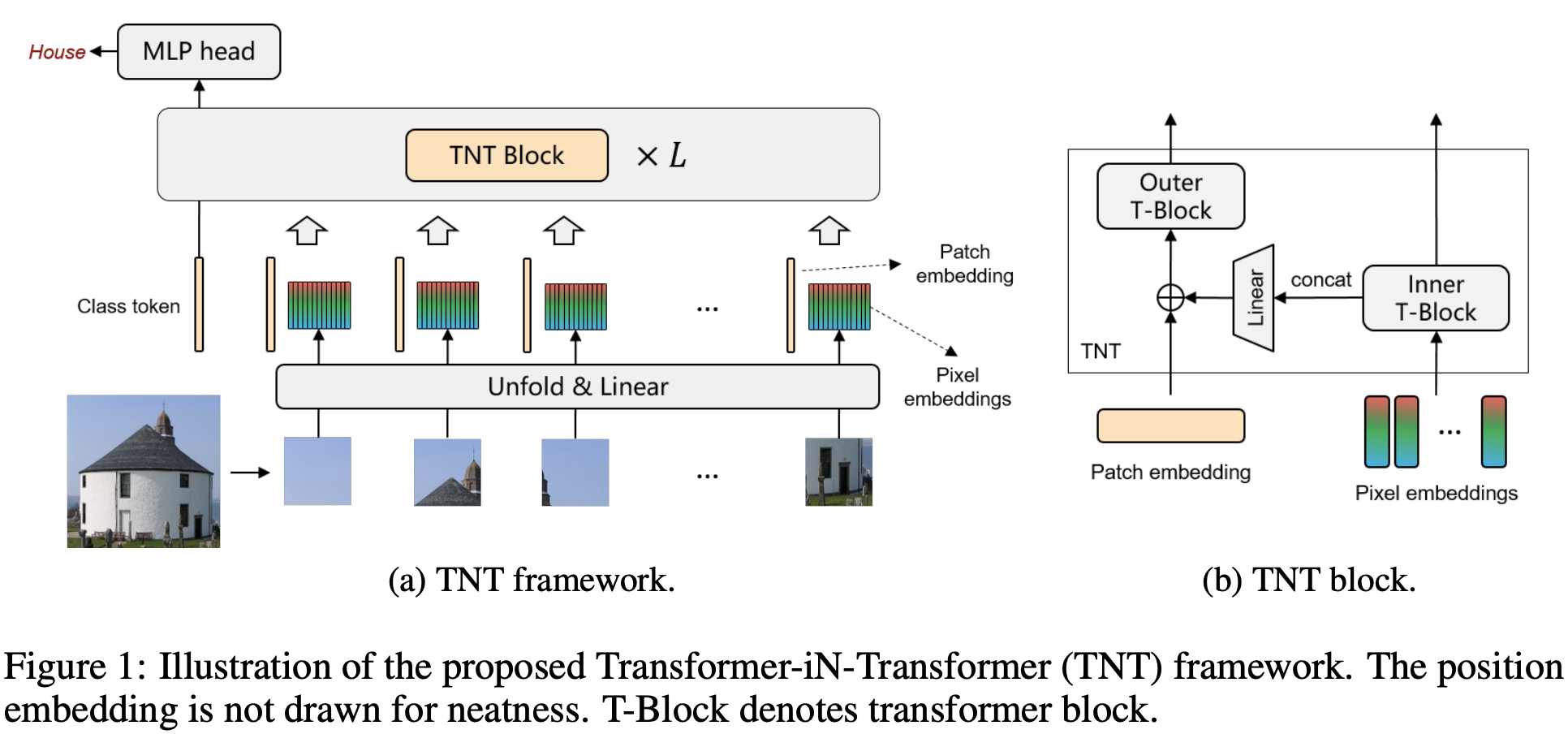
五、Transformer in Transformer(TNT)
Transformer 是一种最初应用于 NLP 任务的基于自注意力的神经网络。 最近,提出了纯基于变压器的模型来解决计算机视觉问题。 这些视觉转换器通常将图像视为一系列补丁,而忽略每个补丁内部的内在结构信息。 在本文中,我们提出了一种新颖的 Transformer-iN-Transformer (TNT) 模型,用于对块级和像素级表示进行建模。 在每个 TNT 块中,外部变压器块用于处理补丁嵌入,内部变压器块从像素嵌入中提取局部特征。 像素级特征通过线性变换层投影到补丁嵌入的空间,然后添加到补丁中。 通过堆叠 TNT 块,我们构建了用于图像识别的 TNT 模型。
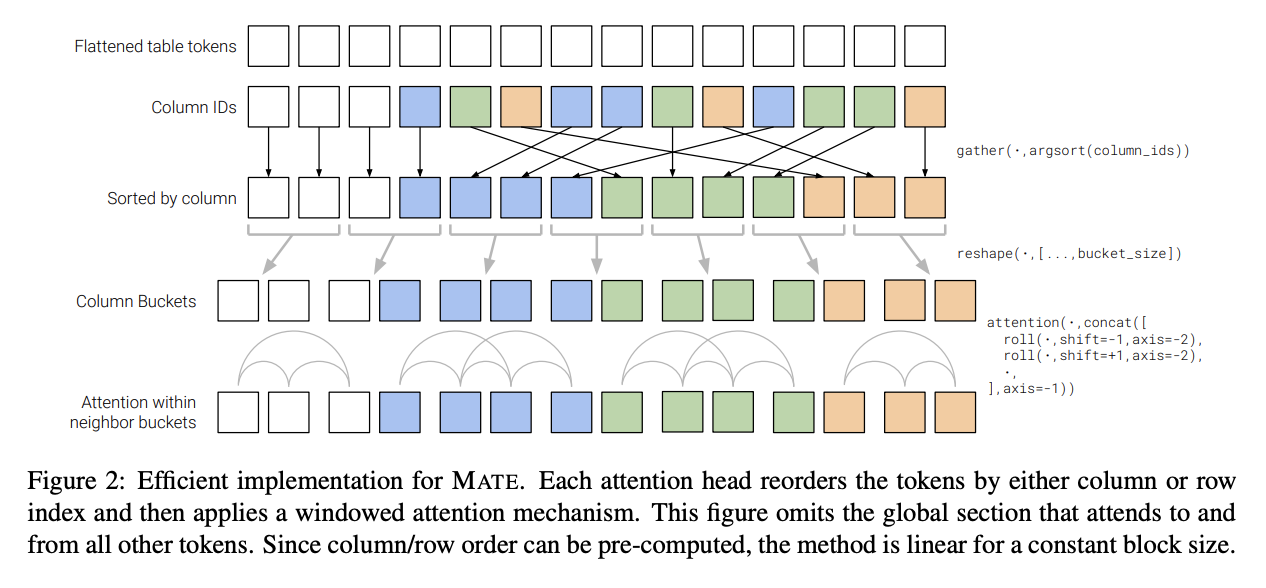
六、MATE
MATE 是一种 Transformer 架构,旨在对 Web 表的结构进行建模。 它使用稀疏注意力的方式允许头有效地关注表中的行或列。 每个注意力头按列或行索引对标记重新排序,然后应用窗口注意力机制。 与传统的自注意力机制不同,Mate 在序列长度上线性缩放。
七、Bort
Bort 是 BERT 架构的参数化架构变体。 它通过神经架构搜索方法提取 BERT 架构的架构参数的最佳子集; 特别是完全多项式时间近似方案(FPTAS)。 这个最佳子集 - “Bort” - 显然更小,

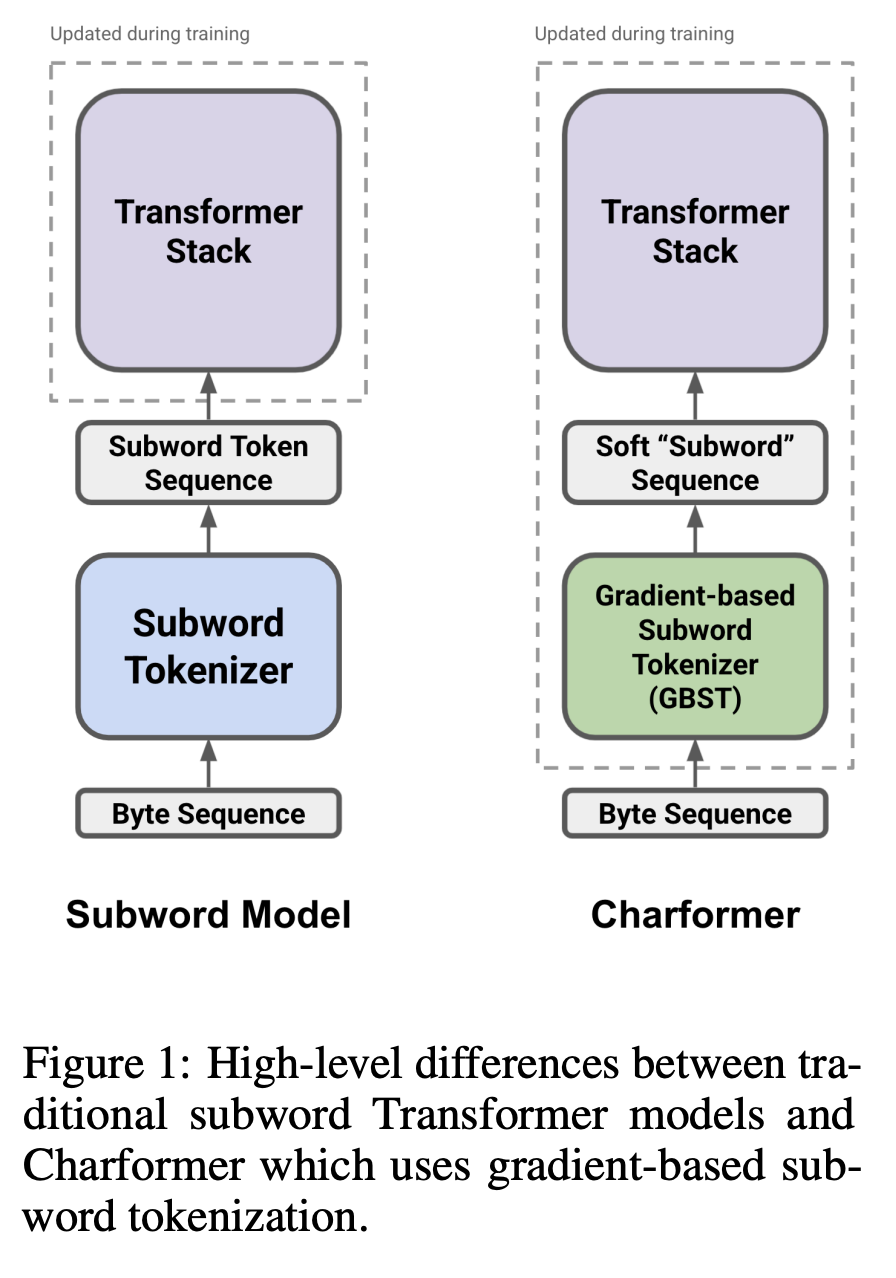
八、Charformer
Charformer 是 Transformer 模型的一种,它作为模型的一部分端到端地学习子词标记化。 具体来说,它使用 GBST 以数据驱动的方式自动从字符中学习潜在的子词表示。 GBST 之后,软子字序列通过 Transformer 层。
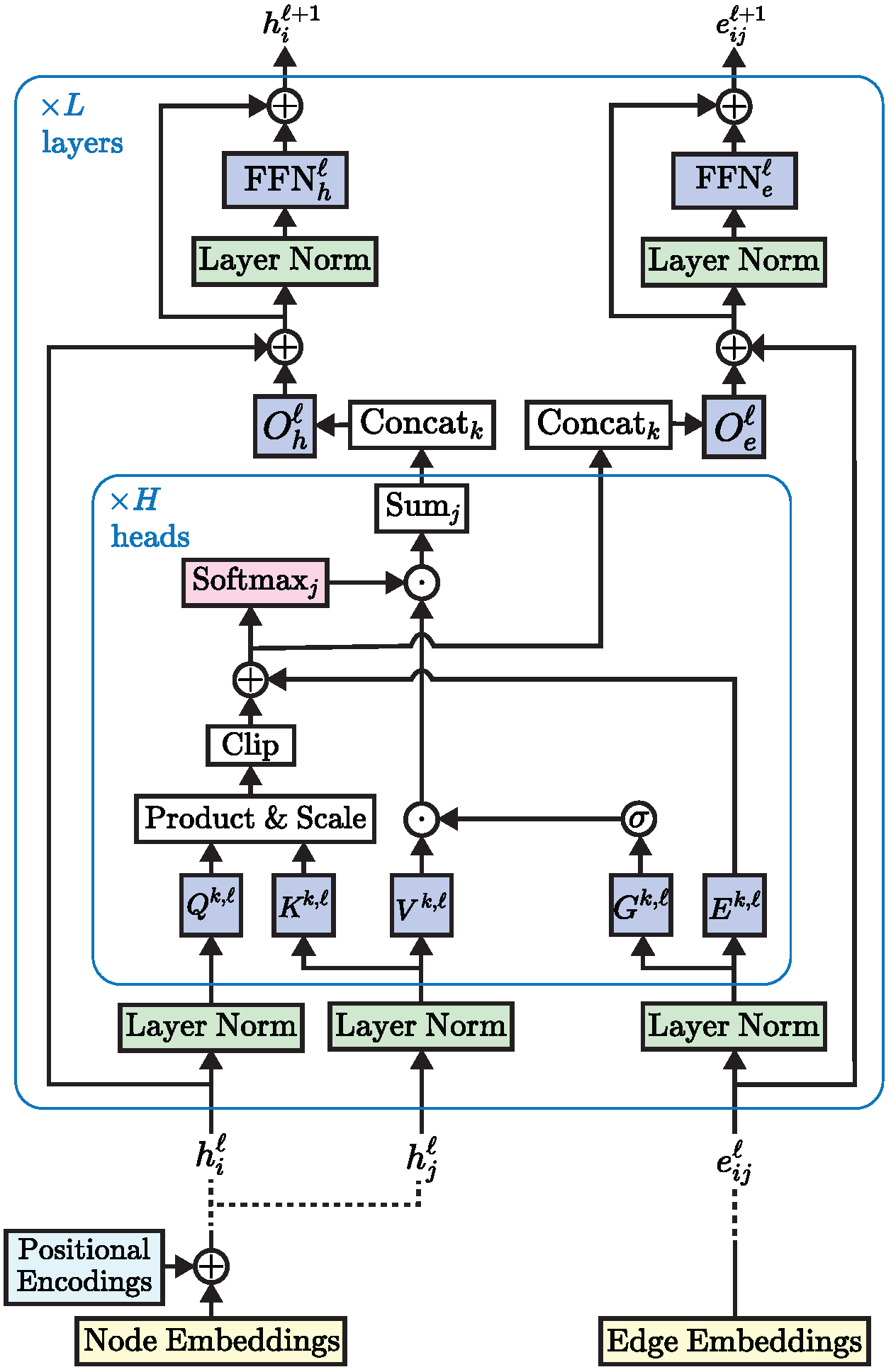
九、Edge-augmented Graph Transformer(EGT)
Transformer 神经网络已经在文本和图像等非结构化数据上取得了最先进的结果,但它们在图结构化数据上的采用受到了限制。 这部分是由于将复杂的结构信息纳入基本变压器框架中的困难。 我们提出了一个简单但强大的变压器扩展 - 剩余边缘通道。 由此产生的框架,我们称之为边缘增强图变换器(EGT),可以直接接受、处理和输出结构信息以及节点信息。 它允许我们直接将全局自注意力(变压器的关键元素)用于图,并具有节点之间远程交互的好处。 此外,边缘通道允许结构信息从一层演变到另一层,并且边缘/链接上的预测任务可以直接从这些通道的输出嵌入执行。 此外,我们引入了一种基于奇异值分解的广义位置编码方案,可以提高 EGT 的性能。 与依赖邻域内的局部特征聚合的卷积/消息传递图神经网络相比,我们的框架依赖于全局节点特征聚合,实现了更好的性能。 我们在基准数据集上进行了广泛的实验,在监督学习环境中验证了 EGT 的性能。 我们的研究结果表明,卷积聚合并不是图的本质归纳偏差,全局自注意力可以作为灵活且自适应的替代方案。
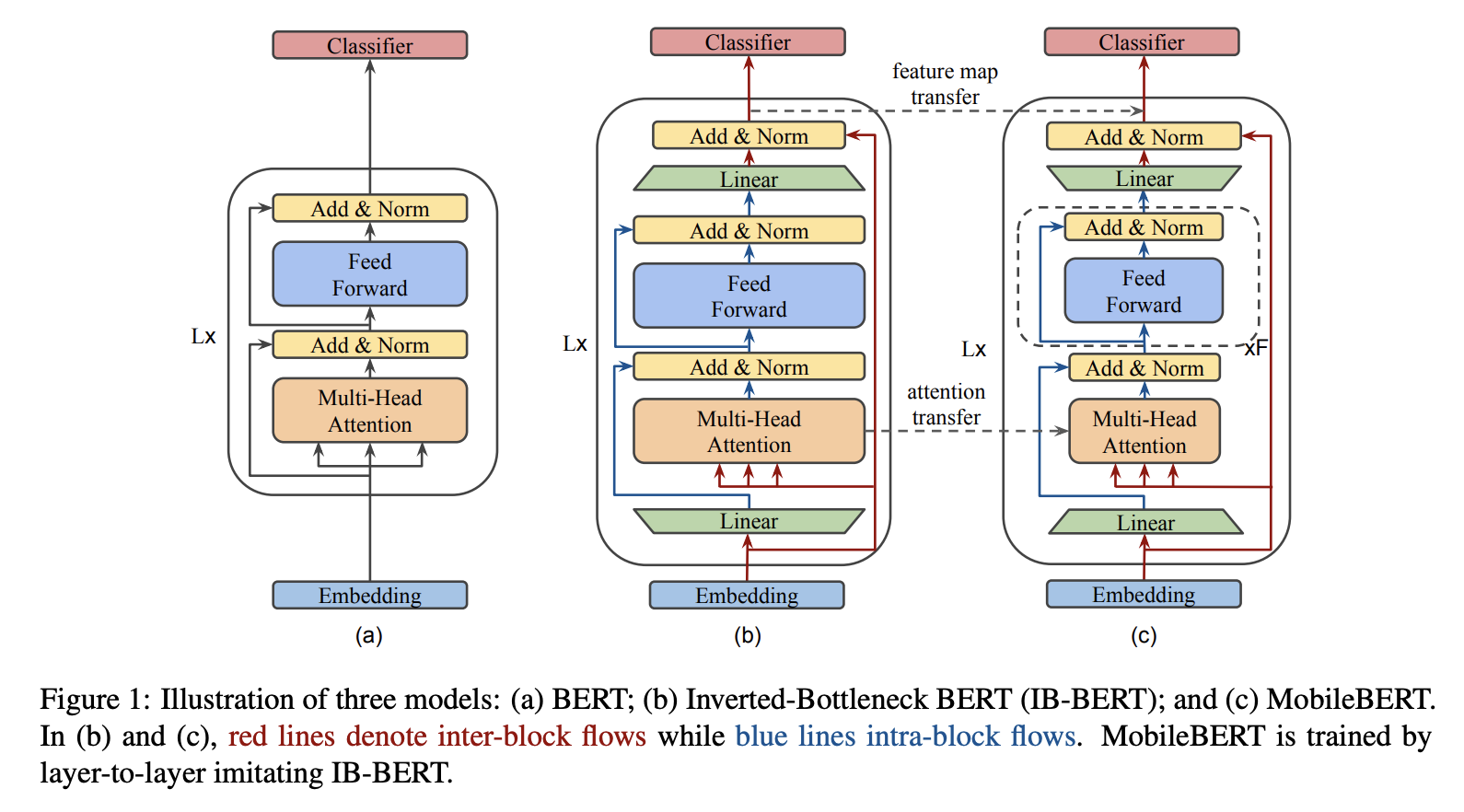
十、MobileBERT
MobileBERT 是一种反向瓶颈 BERT,它压缩并加速了流行的 BERT 模型。 MobileBERT 是 BERT_LARGE 的瘦身版本,同时配备了瓶颈结构以及精心设计的自注意力和前馈网络之间的平衡。 为了训练 MobileBERT,我们首先训练一个专门设计的教师模型,一个包含 BERT_LARGE 的倒瓶颈模型。 然后,我们将这位老师的知识迁移到 MobileBERT。 与原始 BERT 一样,MobileBERT 是与任务无关的,也就是说,它可以通过简单的微调普遍应用于各种下游 NLP 任务。 它是通过模仿反向瓶颈 BERT 进行逐层训练的。