可以说在 Rust 开发中,泛型编程是我们必须掌握的一项技能。在你构建每一个数据结构或者函数时,最好都问问自己:**我是否有必要在此刻就把类型定死?**是不是可以把这个决策延迟到尽可能靠后的时刻,这样可以为未来留有余地?如果我们能通过泛型来推迟决策,系统的架构就可以足够灵活,可以更好地面对未来的变更。
前面学习到trait可以实现参数多态,就是函数或者数据结构用T表示,不是具体类型;
还可以实现特设多态,也就是函数重载,一个函数接口不同的参数有不同的实现;
更牛逼的就是trait做参数的时候,可以实现特征约束,以及多重约束,这体现了组合大于继承的思想,在C++中就是多重继承。KV server的例子就是用实现了store的trait作为泛型参数,实现延迟绑定,同一个数据结构对同一个trait有不同实现,比如kv中以后增加新的存储类型,就会为新的存储类型实现trait,实现就不一样了,在C++中,就是把基类作为参数,相当于把子类赋值给基类,不过这时运行时多态,有运行时虚函数表的开销,而泛型就是静态分发了,运行速度快,但是编译速度慢了
参数是泛型trait
泛型参数的三种使用场景
使用泛型参数延迟数据结构的绑定;
使用泛型参数和 PhantomData,声明数据结构中不直接使用,但在实现过程中需要用到的类型;
使用泛型参数让同一个数据结构对同一个 trait 可以拥有不同的实现。
用泛型参数做延迟绑定
先来看我们已经比较熟悉的,用泛型参数做延迟绑定。kv server中store就是一个泛型参数,这个泛型参数在随后的实现中可以被逐渐约束。只要实现存储trait就可以作为参数。
pub fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse { … }
// 等价于
pub fn dispatch<Store: Storage>(cmd: CommandRequest, store: &Store) -> CommandResponse { … }
使用泛型参数和幽灵数据提供额外类型
现在要设计一个 User 和 Product 数据结构,它们都有一个 u64 类型的 id。然而我希望每个数据结构的 id 只能和同种类型的 id 比较,也就是说如果 user.id 和 product.id 比较,编译器就能直接报错,拒绝这种行为。
先用一个自定义的数据结构 Identifier 来表示 id:
pub struct Identifier { inner: u64,}
然后,在 User 和 Product 中,各自用 Identifier 来让 Identifier 和自己的类型绑定,达到让不同类型的 id 无法比较的目的。
#[derive(Debug, Default, PartialEq, Eq)]
pub struct User {
id: Identifier<Self>}
#[derive(Debug, Default, PartialEq, Eq)]
pub struct Product {
id:Identifier<Self>}
然而它无法编译通过。为什么呢?因为 Identifier 在定义时,并没有使用泛型参数 T,编译器认为 T 是多余的,所以只能把 T 删除掉才能编译通过。但是,删除掉 T,User 和 Product 的 id 就可以比较了,我们就无法实现想要的功能了,怎么办?
PhantomData 中文一般翻译成幽灵数据,这名字透着一股让人不敢亲近的邪魅,但它被广泛用在处理,数据结构定义过程中不需要,但是在实现过程中需要的泛型参数。
#[derive(Debug, Default, PartialEq, Eq)]
pub struct Identifier
{
inner: u64,
_tag: PhantomData,}
这样就可以,其实PhantomData 正如其名,它实际上长度为零,是个 ZST(Zero-Sized Type),就像不存在一样,唯一作用就是类型的标记。
比如用户这个结构体,有name,id,以及一个泛型参数T被幽灵数据拥有,代表免费用户还是付费用户。免费用户可以通过订阅方法变成付费用户,into一下.使用 PhantomData 处理这样的状态,可以在编译期做状态的检测,避免运行期检测的负担和潜在的错误。
泛型是静态分发,编译时分配好对应的类型代码。
使用泛型参数来提供多个实现
有时候,对于同一个 trait,我们想要有不同的实现,该怎么办?比如一个方程,它可以是线性方程,也可以是二次方程,我们希望为不同的类型实现不同 Iterator。
#[derive(Debug, Default)]
pub struct Equation
{
current: u32,
_method: PhantomData,
}// 线性增长
#[derive(Debug, Default)]
pub struct Linear;// 二次增长
#[derive(Debug, Default)]
pub struct Quadratic;
impl Iterator for Equation
{
type Item = u32;
fn next(&mut self) -> Option {
self.current += 1; if self.current >= u32::MAX {
return None; } Some(self.current) }}
impl Iterator for Equation
{
type Item = u32;
fn next(&mut self) -> Option {
self.current += 1; if self.current >= u16::MAX as u32 {
return None; } Some(self.current * self.current) }}
这样做有什么好处么?为什么不构建两个数据结构 LinearEquation 和 QuadraticEquation,分别实现 Iterator 呢?
的确,对于这个例子,使用泛型的意义并不大,因为 Equation 自身没有很多共享的代码。但如果 Equation,只除了实现 Iterator 的逻辑不一样,其它大量的代码都是相同的,并且未来除了一次方程和二次方程,还会支持三次、四次……,那么,用泛型数据结构来统一相同的逻辑,用泛型参数的具体类型来处理变化的逻辑,就非常有必要了。
类似于C++中继承的意思,Equation是基类,有iterator这个方法,LinearEquation 和 QuadraticEquation是子类,具体实现iterator。
额外的情况:
返回值携带泛型参数怎么办?
比如,对于 get_iter() 方法,并不关心返回值是一个什么样的 Iterator,只要它能够允许我们不断调用 next() 方法,获得一个 Kvpair 的结构,就可以了。
Rust 目前还不支持在 trait 里使用 impl trait 做返回值。那怎么办?很简单,我们可以返回 trait object,它消除了类型的差异,把所有不同的实现 Iterator 的类型都统一到一个相同的 trait object 下
pub trait Storage {
...
/// 遍历 HashTable,返回 kv pair 的 Iterator
fn get_iter(&self, table: &str) ->
Result<Box<dyn Iterator<Item = Kvpair>>, KvError>;
}
当然,泛型编程也是一把双刃剑。任何时候,当我们引入抽象,即便能做到零成本抽象,要记得抽象本身也是一种成本。当我们把代码抽象成函数、把数据结构抽象成泛型结构,即便运行时几乎并无添加额外成本,它还是会带来设计时的成本,如果抽象得不好,还会带来更大的维护上的成本
总结一下trait:
1、特征约束。比如store trait作为参数,下次添加新的类型根本不需要修改代码,只需要在为新的存储类型添加新的方法,开闭原则;并且如果C++必须要用多态运行时,有开销,而且组合优于继承(破坏封装,方法污染,耦合强,多重继承的问题)
2、还可以有幽灵数据,数据结构定义过程中不需要,但是在实现过程中需要的泛型参数。用泛型数据结构来统一相同的逻辑,用泛型参数的具体类型来处理变化的逻辑,就非常有必要了。也是用来替代C++的继承的;
3、特殊情况就是返回值不能是trait,比如返回一个迭代器,不需要知道它的具体类型,可以用特征对象,根C++的多态很像了。最好不用吧。
trait object 是如何在实战中使用
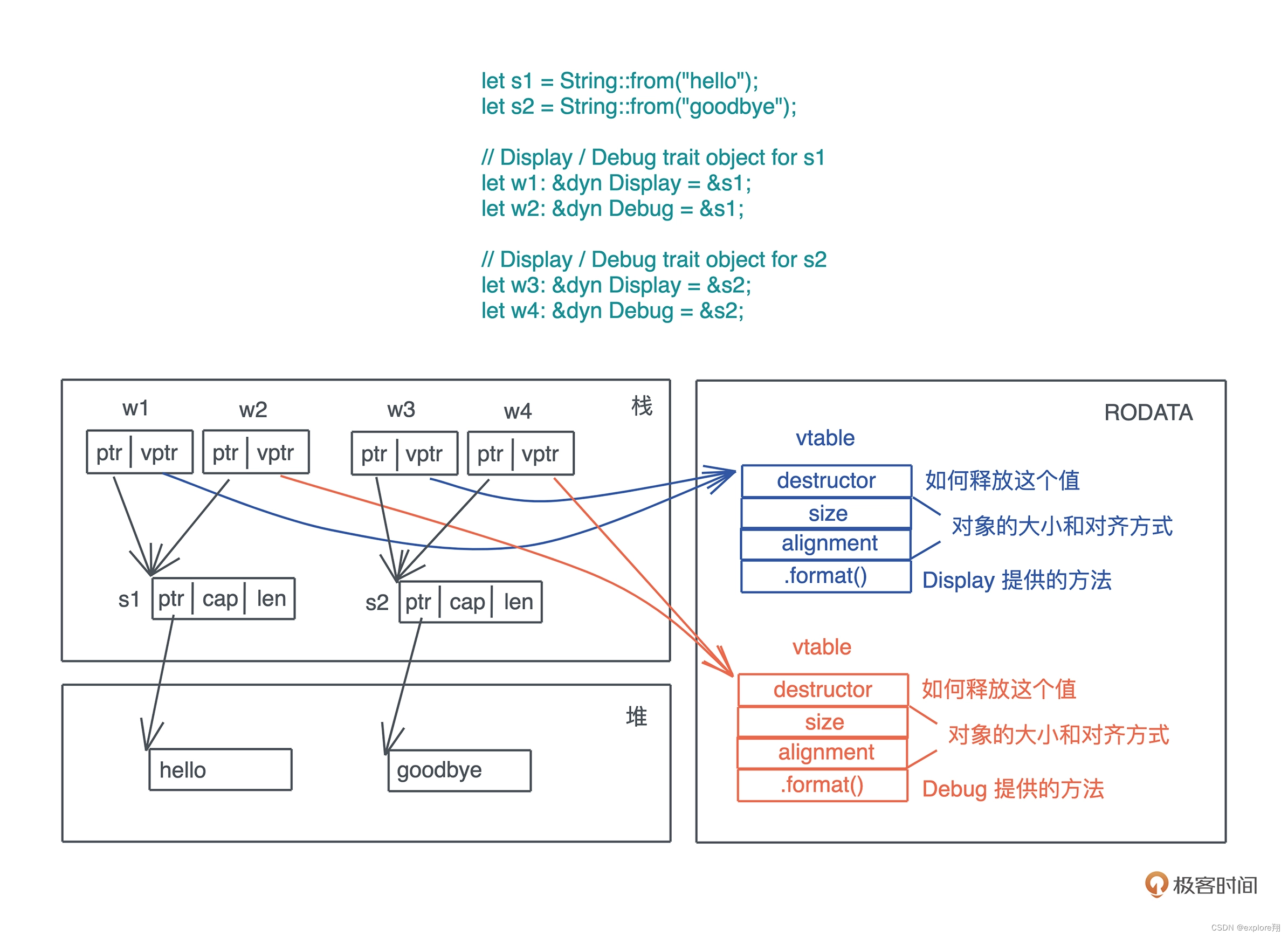
这个例子表示,特征对象就是用&dyn trait的方式,把实际类型表示为实现了trait的上层类型,和C++类似,有一个table,里面是具体类型对于trait的实现。相当于多态,把子类退化成基类,只不过基类有个table虚函数表,存储了实际类型对于trait的实现。
这里的疑问就是,前面说过,trait做参数就可以实现特设多态,达到类似于传入泛型参数,而根据不同实际类型,实现不同。为什么需要特征对象呢?
1.主要是为了编程方便,逻辑性和代码可读性好。举个例子,如果我们想要实现一个UI组件,有不同的元素(按钮,文本框等等,这些组件都有draw方法)。都存在一个表里vec,需要使用同一个方法逐一渲染在屏幕上!如果用泛型特征约束的话,那么列表中必须都是同一种类型。为了解决上面的所有问题,Rust 引入了一个概念 —— 特征对象。Box实现。任何实现了 Draw 特征的类型,都可以存放在vec中。
trait对象可以让代码变的简洁,因为实现的时候就不要带着泛型参数了。
2.第二就是在一些需要泛型返回值的时候。Rust 目前还不支持在 trait 里使用 impl trait 做返回值。那怎么办?很简单,我们可以返回 trait object。比如返回迭代器时,把所有不同的实现 Iterator 的类型都统一到一个相同的 trait object 下。
总结一下就是:
当系统需要使用多态来解决复杂多变的需求,让同一个接口可以展现不同的行为时,我们要决定究竟是编译时的静态分发更好(泛型参数),还是运行时的动态分发更好(特征对象)。
动态分发会有运行时开销,但是会使代码更加简洁,特别是当需要对不同具体类型做一个抽象,比如把不同组件形成UI组件集合,就需要特征对象,因为数组只能放相同类型的元素,可以考虑元组?以及返回值含有泛型时必须用特征对象,因为rust暂不支持impl trait作为返回值。
静态分发零成本抽象,但是设计成本是有的,简单的可以用,如果太复杂了,涉及多个trait,联系很复杂,就可以不考虑。
tips:
我们知道& dyn draw, Box, , Arc都是可以做特征对象的。但是动态分发额外开销对于静态分发到底多多少?
如果是& dyn draw(分配在栈上的ptr和vptr),其实就是多一次vtable的内存访问而已,影响并不大。而 Box, , Arc因为会多一次堆内存的分配,这个影响很大,导致速度慢几十倍。
所以,大部分情况,我们在撰写代码的时候,不必太在意 trait object 的性能问题。如果你实在在意关键路径上 trait object 的性能,那么先尝试看能不能不要做额外的堆内存分配。
(对于作为返回值(栈对象会在函数结束销毁),以及线程间传递(必须要实现send trait),必须要用Box, , Arc)
如何围绕trait来设计和架构系统?
其实不光是 Rust 中的 trait,任何一门语言,和接口处理相关的概念,都是那门语言在使用过程中最重要的概念。软件开发的整个行为,基本上可以说是不断创建和迭代接口,然后在这些接口上进行实现的过程。
构建一个简单的KV server-高级trait技巧
我们已经完成了 KV store 的基本功能,但留了两个小尾巴:
Storage trait 的 get_iter() 方法没有实现;
Service 的 execute() 方法里面还有一些 TODO,需要处理事件的通知。
完成持久化存储
impl Storage for MemTable {
...
fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> {
// 使用 clone() 来获取 table 的 snapshot
let table = self.get_or_create_table(table).clone();
let iter = table
.iter()
.map(|v| Kvpair::new(v.key(), v.value().clone()));
Ok(Box::new(iter)) // <-- 编译出错
}
}
table.iter() 使用了 table 的引用,我们返回 iter,但 iter 引用了作为局部变量的 table,所以无法编译通过。此刻,我们需要有一个能够完全占有 table 的迭代器,我们可以用 table.into_iter() 把 table 的所有权转移给 iter:let iter = table.into_iter().map(|data| data.into());
(String, Value) 需要转换成 Kvpair,我们依旧用 into() 来完成这件事。
我们还是有必要思考一下,如果以后想为更多的 data store 实现 Storage trait,都会怎样处理 get_iter() 方法?
我们会:
拿到一个关于某个 table 下的拥有所有权的 Iterator
对 Iterator 做 map
将 map 出来的每个 item 转换成 Kvpair
这里的第 2 步对于每个 Storage trait 的 get_iter() 方法的实现来说,都是相同的。有没有可能把它封装起来呢,也就是实现一个storeiterator trait里面包含了map操作,这样每当其他存储类型要实现get_iter,第二步就可以省略。的确,在这个 KV server 的例子里,这样的抽象收益不大。但是,如果刚才那个步骤不是 3 步,而是 5 步 /10 步,其中大量的步骤都是相同的,也就是说,我们每实现一个新的 store,就要撰写相同的代码逻辑,那么,这个抽象就非常有必要了。
支持事件通知
pub fn execute(&self, cmd: CommandRequest) -> CommandResponse {
debug!("Got request: {:?}", cmd);
// TODO: 发送 on_received 事件
let res = dispatch(cmd, &self.inner.store);
debug!("Executed response: {:?}", res);
// TODO: 发送 on_executed 事件
res
}
为了解决这些 TODO,我们需要提供事件通知的机制:在创建 Service 时,注册相应的事件处理函数;在 execute() 方法执行时,做相应的事件通知,使得注册的事件处理函数可以得到执行。
先看事件处理函数如何注册。
如果想要能够注册,那么倒推也就是,Service/ServiceInner 数据结构就需要有地方能够承载事件注册函数。可以尝试着把它加在 ServiceInner 结构里:
/// Service 内部数据结构
pub struct ServiceInner<Store> {
store: Store,
on_received: Vec<fn(&CommandRequest)>,
on_executed: Vec<fn(&CommandResponse)>,
on_before_send: Vec<fn(&mut CommandResponse)>,
on_after_send: Vec<fn()>,
}
在撰写事件注册的代码之前,还是先写个测试,从使用者的角度,考虑如何进行注册
#[test]
fn event_registration_should_work() {
fn b(cmd: &CommandRequest) {
info!("Got {:?}", cmd);
}
fn c(res: &CommandResponse) {
info!("{:?}", res);
}
fn d(res: &mut CommandResponse) {
res.status = StatusCode::CREATED.as_u16() as _;
}
fn e() {
info!("Data is sent");
}
let service: Service = ServiceInner::new(MemTable::default())
.fn_received(|_: &CommandRequest| {
})
.fn_received(b)
.fn_executed(c)
.fn_before_send(d)
.fn_after_send(e)
.into();
let res = service.execute(CommandRequest::new_hset("t1", "k1", "v1".into()));
assert_eq!(res.status, StatusCode::CREATED.as_u16() as _);
assert_eq!(res.message, "");
assert_eq!(res.values, vec![Value::default()]);
}
从测试代码中可以看到,我们希望通过 ServiceInner 结构,不断调用 fn_xxx 方法,为 ServiceInner 注册相应的事件处理函数;添加完毕后,通过 into() 方法,我们再把 ServiceInner 转换成 Service。这是一个经典的构造者模式(Builder Pattern),在很多 Rust 代码中,都能看到它的身影。(构造复杂对象,只需要把参数传进去,给构造类,具体怎么构造不用管。使用private修饰构造方法,外界无法直接创建对象,只能通过内部Builder类的build方法;隐藏了构建对象的过程;暴露出给外部调用的方法,用于构造组件。)
impl<Store: Storage> ServiceInner<Store> {
pub fn new(store: Store) -> Self {
Self {
store,
on_received: Vec::new(),
on_executed: Vec::new(),
on_before_send: Vec::new(),
on_after_send: Vec::new(),
}
}
pub fn fn_received(mut self, f: fn(&CommandRequest)) -> Self {
self.on_received.push(f);
self
}
pub fn fn_executed(mut self, f: fn(&CommandResponse)) -> Self {
self.on_executed.push(f);
self
}
pub fn fn_before_send(mut self, f: fn(&mut CommandResponse)) -> Self {
self.on_before_send.push(f);
self
}
pub fn fn_after_send(mut self, f: fn()) -> Self {
self.on_after_send.push(f);
self
}
}
我们虽然完成了事件处理函数的注册,但现在还没有发事件通知。另外因为我们的事件包括不可变事件(比如 on_received)和可变事件(比如 on_before_send),所以事件通知需要把二者分开。来定义两个 trait:Notify 和 NotifyMut:
/// 事件通知(不可变事件)
pub trait Notify<Arg> {
fn notify(&self, arg: &Arg);
}
/// 事件通知(可变事件)
pub trait NotifyMut<Arg> {
fn notify(&self, arg: &mut Arg);
}
impl<Arg> Notify<Arg> for Vec<fn(&Arg)> {
#[inline]
fn notify(&self, arg: &Arg) {
for f in self {
f(arg)
}
}
}
impl<Arg> NotifyMut<Arg> for Vec<fn(&mut Arg)> {
#[inline]
fn notify(&self, arg: &mut Arg) {
for f in self {
f(arg)
}
}
}
其中的 Arg 参数,对应事件注册函数里的 arg,比如:fn(&CommandRequest);
Notify / NotifyMut trait 实现好之后,我们就可以修改 execute() 方法了:
impl<Store: Storage> Service<Store> {
pub fn execute(&self, cmd: CommandRequest) -> CommandResponse {
debug!("Got request: {:?}", cmd);
self.inner.on_received.notify(&cmd);
let mut res = dispatch(cmd, &self.inner.store);
debug!("Executed response: {:?}", res);
self.inner.on_executed.notify(&res);
self.inner.on_before_send.notify(&mut res);
if !self.inner.on_before_send.is_empty() {
debug!("Modified response: {:?}", res);
}
res
}
}
现在,相应的事件就可以被通知到相应的处理函数中了。这个通知机制目前还是同步的函数调用,未来如果需要,我们可以将其改成消息传递,进行异步处理。
只能、整体过程就是在service结构中加入响应事件的数组,数组元素是要执行的函数,因为是数组,所以在构造service可以利用构造者模式,不断调用 fn_xxx 方法,这个方法就是把要执行的函数加入相应的响应事件的数组。然后执行到某个地方notify一下,执行数组里面的函数,进行通知。
注意,这里为什么采用为某个触发点采用数组的形式,也是为了满足开闭原则,因为比如收到请求后,要做的事或者说通知随着需求是在变化的,可能增加或者减少,如果只采用一个函数的形式,直接fn_xxx里面执行对应实现,面对变化就要修改代码,不满足开闭原则。
现在想想我们整个项目满足开闭原则地方有哪些:
1、使用了泛型trait,实现了C++中类似多态的效果,以后新增存储类型不需要修改代码,只要为新增的类型实现trait即可。并且泛型是静态分发,零成本抽象;
2、对于get_iter方法,返回参数使用的是 特征对象,不在乎具体类型,只要满足实现了iterator trait就可以,也是实现类似于多态的效果,是动态分发;另外,我们分析不同类型的迭代器第二步都是对 Iterator 做 map,所以我们把这一步封装,实现了
store iterator,这样当有新的存储类型,就不用重复写第二步了,特别是当这种共同的操作有很多步时,意义更大。
3.这里的事件通知机制,不是单独一个处理事件的函数,因为处理过程可能变化,所以设置了处理数组,构造时可以利用构造者模式不断调用fn_xxx往处理数组中添加函数,需要通知的时候notify顺序执行数组中的函数。
4、测试store部分的测试代码也符合开闭原则,接口是稳定的,用泛型trait作为接口参数,当有新增存储类型测试时,不需要修改代码了。
其他的可以不说,主要说一下事件通知机制(**构造者模式**):不是单独一个处理事件的函数,因为处理过程可能变化,所以设置了处理数组,构造时可以利用构造者模式不断调用fn_xxx往处理数组中添加函数,需要通知的时候notify顺序执行数组中的函数。
总结:到这里其实要了解就两点,一个是三部分整体流程以及service串联,然后是trait的使用以及事件通知机制构造者模式的实现;(联系一下设计模式)
下面还需要知道网络处理部分以及网络安全部分的实现; 以及异步编程的实现。
为持久化数据库实现 Storage trait
到目前为止,我们的 KV store 还都是一个在内存中的 KV store。一旦终止应用程序,用户存储的所有 key / value 都会消失。我们希望存储能够持久化。
一个方案是为 MemTable 添加 WAL 和 disk snapshot 支持,让用户发送的所有涉及更新的命令都按顺序存储在磁盘上,同时定期做 snapshot,便于数据的快速恢复;
另一个方案是使用已有的 KV store,比如 RocksDB,或者 sled。RocksDB 是 Facebook 在 Google 的 levelDB 基础上开发的嵌入式 KV store,用 C++ 编写,而 sled 是 Rust 社区里涌现的优秀的 KV store,对标 RocksDB。二者功能很类似,从演示的角度,sled 使用起来更简单,更加适合今天的内容,如果在生产环境中使用,RocksDB 更加合适,因为它在各种复杂的生产环境中经历了千锤百炼。所以,我们今天就尝试为 sled 实现 Storage trait,让它能够适配我们的 KV server。
首先在 Cargo.toml 里引入 sled:sled = “0.34” # sled db
然后创建 src/storage/sleddb.rs,并添加如下代码:
use sled::{
Db, IVec};
use std::{
convert::TryInto, path::Path, str};
use crate::{
KvError, Kvpair, Storage, StorageIter, Value};
#[derive(Debug)]
pub struct SledDb(Db);
impl SledDb {
pub fn new(path: impl AsRef<Path>) -> Self {
Self(sled::open(path).unwrap())
}
// 在 sleddb 里,因为它可以 scan_prefix,我们用 prefix
// 来模拟一个 table。当然,还可以用其它方案。
fn get_full_key(table: &str, key: &str) -> String {
format!("{}:{}", table, key)
}
// 遍历 table 的 key 时,我们直接把 prefix: 当成 table
fn get_table_prefix(table: &str) -> String {
format!("{}:", table)
}
}
/// 把 Option<Result<T, E>> flip 成 Result<Option<T>, E>
/// 从这个函数里,你可以看到函数式编程的优雅
fn flip<T, E>(x: Option<Result<T, E>>) -> Result<Option<T>, E> {
x.map_or(Ok(None), |v| v.map(Some))
}
impl Storage for SledDb {
fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> {
let name = SledDb::get_full_key(table, key);
let result = self.0.get(name.as_bytes())?.map(|v| v.as_ref().try_into());
flip(result)
}
fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError> {
let name = SledDb::get_full_key(table, &key);
let data: Vec<u8> = value.try_into()?;
let result = self.0.insert(name, data)?.map(|v| v.as_ref().try_into());
flip(result)
}
fn contains(&self, table: &str, key: &str) -> Result<bool, KvError> {
let name = SledDb::get_full_key(table, &key);
Ok(self.0.contains_key(name)?)
}
fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> {
let name = SledDb::get_full_key(table, &key);
let result = self.0.remove(name)?.map(|v| v.as_ref().try_into());
flip(result)
}
fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError> {
let prefix = SledDb::get_table_prefix(table);
let result = self.0.scan_prefix(prefix).map(|v| v.into()).collect();
Ok(result)
}
fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> {
let prefix = SledDb::get_table_prefix(table);
let iter = StorageIter::new(self.0.scan_prefix(prefix));
Ok(Box::new(iter))
}
}
impl From<Result<(IVec, IVec), sled::Error>> for Kvpair {
fn from(v: Result<(IVec, IVec), sled::Error>) -> Self {
match v {
Ok((k, v)) => match v.as_ref().try_into() {
Ok(v) => Kvpair::new(ivec_to_key(k.as_ref()), v),
Err(_) => Kvpair::default(),
},
_ => Kvpair::default(),
}
}
}
fn ivec_to_key(ivec: &[u8]) -> &str {
let s = str::from_utf8(ivec).unwrap();
let mut iter = s.split(":");
iter.next();
iter.next().unwrap()
}
这段代码主要就是在实现 Storage trait。每个方法都很简单,就是在 sled 提供的功能上增加了一次封装。
而测试代码就可以复用之前的,这里也体现了测试代码的开闭原则,测试的接口稳定,实现可以变。
mod sleddb;
pub use sleddb::SledDb;
#[cfg(test)]
mod tests {
use tempfile::tempdir;
use super::*;
...
#[test]
fn sleddb_basic_interface_should_work() {
let dir = tempdir().unwrap();
let store = SledDb::new(dir);
test_basi_interface(store);
}
#[test]
fn sleddb_get_all_should_work() {
let dir = tempdir().unwrap();
let store = SledDb::new(dir);
test_get_all(store);
}
#[test]
fn sleddb_iter_should_work() {
let dir = tempdir().unwrap();
let store = SledDb::new(dir);
test_get_iter(store);
}
}
最后实际运行的整体测试代码,可以看到,主函数几乎没怎么修改,就是在构造service修改了具体的存储类型,利用了构造者模式不断调用fn_xxx方法来把通知的函数push到事件数组中,执行的时候会调用notify函数执行。
并且,如果要新增通知事件,只需要构造时多调用一次fn_xxx函数即可,不用修改代码;如果要新增存储类型,也是为其实现store trait即可,不需要修改代码,execute会自动调用相应的函数去处理。(涉及到protobuf文件序列化反序列化,相应命令的执行函数也就是存储读取逻辑)
use anyhow::Result;
use async_prost::AsyncProstStream;
use futures::prelude::*;
use kv1::{
CommandRequest, CommandResponse, Service, ServiceInner, SledDb};
use tokio::net::TcpListener;
use tracing::info;
#[tokio::main]
async fn main() -> Result<()> {
tracing_subscriber::fmt::init();
let service: Service<SledDb> = ServiceInner::new(SledDb::new("/tmp/kvserver"))
.fn_before_send(|res| match res.message.as_ref() {
"" => res.message = "altered. Original message is empty.".into(),
s => res.message = format!("altered: {}", s),
})
.into();
let addr = "127.0.0.1:9527";
let listener = TcpListener::bind(addr).await?;
info!("Start listening on {}", addr);
loop {
let (stream, addr) = listener.accept().await?;
info!("Client {:?} connected", addr);
let svc = service.clone();
tokio::spawn(async move {
let mut stream =
AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async();
while let Some(Ok(cmd)) = stream.next().await {
info!("Got a new command: {:?}", cmd);
let res = svc.execute(cmd);
stream.send(res).await.unwrap();
}
info!("Client {:?} disconnected", addr);
});
}
}