文章目录
1. 使用Alexnet进行数据特征提取,并使用SVM进行分类(含有交互页面)
1.1 数据集
我的数据集比较少,一个文件夹才20个左右的数据,都是我自己抠的,用了一上午。
如果你想用一些图像分类的网络进行图像分类,最好是成千的数据,否则会很低的,因为我使用了别的网络,才30%,跟没有分一样。
其中ripe的文件夹:

数据来源
数据集我是在飞桨里面找的,这里我用图来展示
网址:https://aistudio.baidu.com/aistudio/index

这里的数据肯定是不能直接用的,有点乱,反正用的不多,干脆我自己抠点算了。
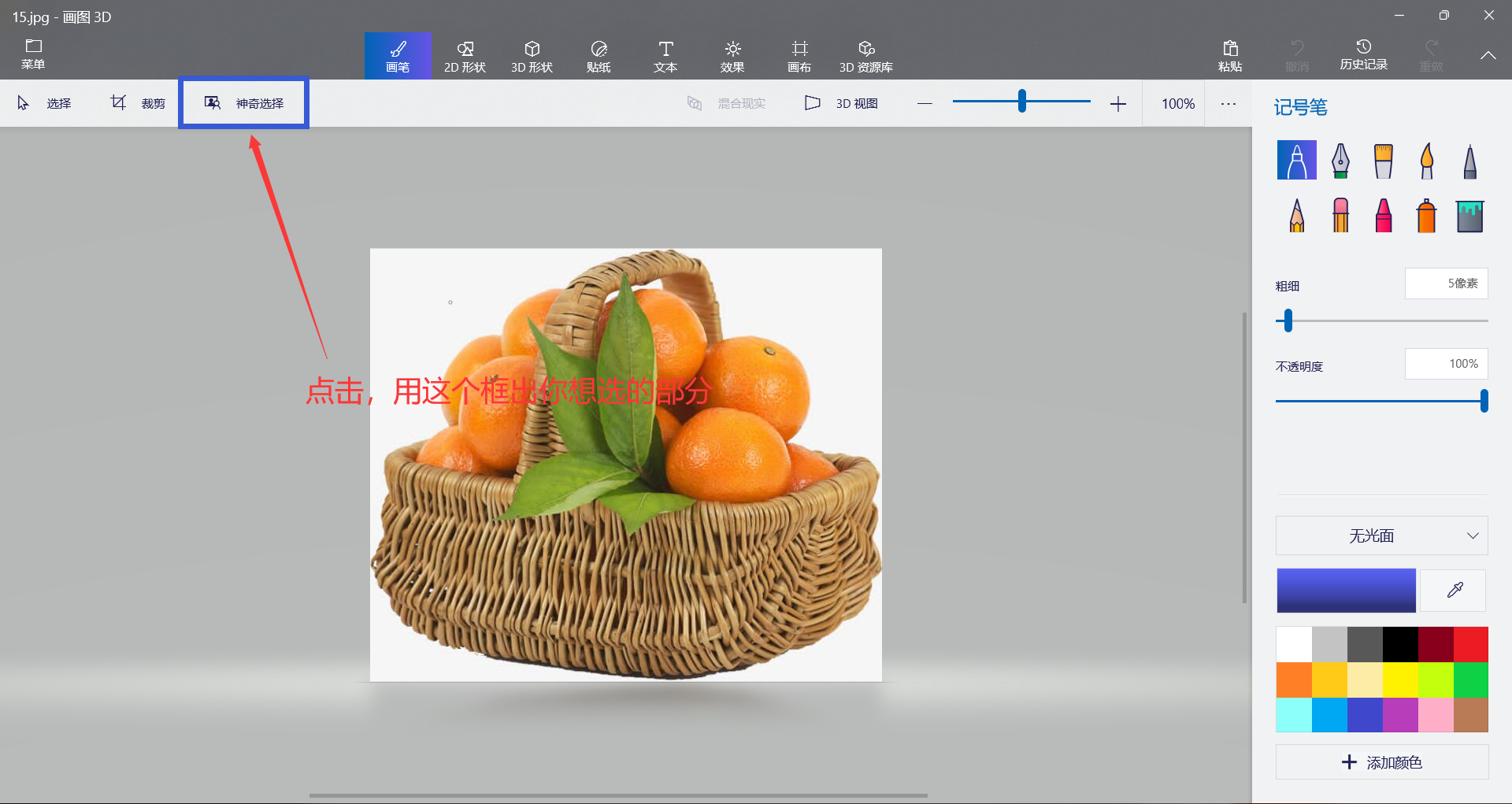
在Microsoft Store下载画图3D(免费的),方便大家抠图

对于一个图片,右击->打开方式->画图3D,



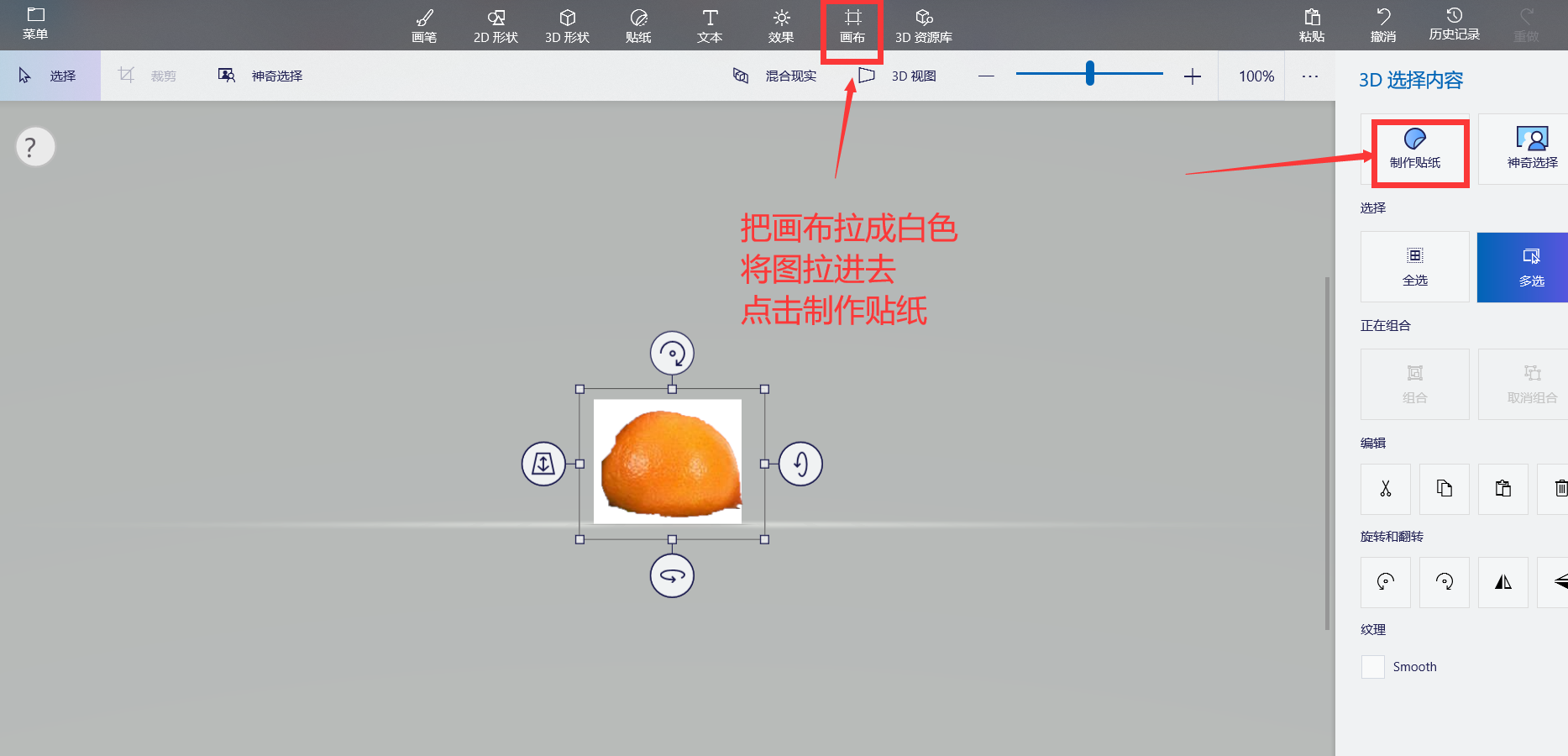
保存下来,把它分到对应的文件夹里,这里看你怎么分了,最好区别要明显。
最后每个文件夹里有20多的数据,当然,越多越好,越明显越好。。
这里我把我的数据集放到CSDN里,(建议不要下载,数据比较少,最好是自己少)
1. 2 数据预处理,并提取特征
导入包
所有的包都在这里了
import torch
import torchvision.models as models
import torchvision.transforms as transforms
import numpy as np
from PIL import Image
import cv2
import os
import torch.nn as nn
from sklearn import svm
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
import pickle
sklearn是一个基于Python的机器学习库,它提供了一系列常见的机器学习算法和数据处理工具,包括分类、回归、聚类、降维、模型选择和预处理等。sklearn建立在NumPy、SciPy和matplotlib之上,使用简单且非常灵活,是许多数据科学家和机器学习工程师的首选工具之一。
sklearn提供的算法包括线性模型、决策树、支持向量机、随机森林、神经网络等,同时还提供了各种评估指标、交叉验证和模型选择方法,以帮助用户选择最佳的模型。
导入alexnet模型
alexnet = models.alexnet(pretrained=False) # 加载没有预训练的AlexNet模型
预处理提取特征的方法
def get_texture_features(image):
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image = transform(image)
# 增加一个维度,变成[1, 3, 224, 224]
image = image.unsqueeze(0)
# 提取特征
with torch.no_grad():
features = alexnet.features(image)
# features = vgg(image) # 1000
# features = resnet(image) # 1000
features = torch.flatten(features)
return np.array(features)
1.3 对数据集进行遍历并提取特征
os.walk()参数是你的数据集的位置
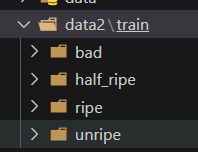
我的文件夹是:
所以我的输入时(相对路径):./data2/train
主要用到os这个库
# 读取数据集
X = []
y = []
for root, dirs, files in os.walk('./data2/train'):
for file in files:
if file.endswith('.jpg'):
img = Image.open(os.path.join(root, file))
# img = cv2.imread(os.path.join(root, file))
X.append(get_texture_features(img))
if 'unripe' in root:
y.append(0)
elif 'half_ripe' in root:
y.append(1)
elif 'ripe' in root:
y.append(2)
elif 'bad' in root:
y.append(3)
X = np.array(X)
# print(X.shape)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
1.4 进行训练
# 训练SVM模型
clf = svm.SVC(kernel='linear', C=1, gamma='auto')
clf.fit(X_train, y_train)
# 保存模型
with open('svm_model.pkl', 'wb') as f:
pickle.dump(clf, f)
# 预测测试集数据
y_pred = clf.predict(X_test)
# 输出分类报告
target_names = ['未成熟', '半成熟', '成熟', '坏橘子']
print(classification_report(y_test, y_pred, target_names=target_names))
最后的输出:
precision recall f1-score support
未成熟 0.33 0.67 0.44 3
半成熟 0.50 0.33 0.40 9
成熟 0.56 0.56 0.56 9
坏橘子 1.00 1.00 1.00 7
avg / total 0.62 0.61 0.60 28
注:第一行是:正确率 召回率 f1 支持率
1.5 进行交互页面
用PS大致的做了一下页面,主要使用 tkinter库
代码:
from tkinter import *
from PIL import Image, ImageTk
from tkinter import filedialog
from tkinter import ttk
root = Tk()
root.geometry("400x600")
root.resizable(False, False)
textLabel = ttk.Label(root, text="水果分级",font=("Impact Bold", 20),anchor="center",padding=(30,40))
textLabel.pack()
# 打开图片并转换为 PhotoImage 对象
image = Image.open("women.jpg")
# 调整图片大小
# image = image.resize((300, 300), Image.ANTIALIAS)
# image = image.crop((0,0,299, 299))
thumbnail_size = (300, 300) # 缩略图大小
image.thumbnail(thumbnail_size)
photo = ImageTk.PhotoImage(image)
# 创建 imagetk 并设置图片
imagetk = ttk.Label(root, image=photo)
imagetk.place(x=50, y=100, width=300, height=300)
# 定义按钮点击时执行的函数
def selectClick(event):
fileName = filedialog.askopenfilename()
# print(fileName)
image = Image.open(fileName)
image = image.resize((300, 300), Image.ANTIALIAS)
photo = ImageTk.PhotoImage(image)
# 更新图片内容
imagetk.config(image=photo)
imagetk.image = photo
# print("修改成功")
text_var.set(fileName)
text_var = StringVar()
text_var.set("原始字符串")
# 点击确定,输出这个橘子的种类
def sureChick(event):
# print(text_var.get())
img = Image.open(text_var.get())
featureOne = get_texture_features(img)
y_pred = clf.predict([featureOne])
target_names = ['未成熟', '半成熟', '成熟', '坏橘子']
textLabel3.config(text=target_names[y_pred[0]])
# 创建按钮对象,并设置文本和点击事件
selectbutton = ttk.Button(root, text="选择图片")
selectbutton.bind("<Button-1>",selectClick)
# 将按钮添加到窗口 并设置位置
selectbutton.place(x=50, y=420, width=140, height=70)
# 设置确定按钮
sureButton = ttk.Button(root, text="确定")
sureButton.bind("<Button-1>", sureChick)
# 将按钮添加到窗口 并设置位置
sureButton.place(x=210, y=420, width=140, height=70)
textLabel2 = ttk.Label(root, text="等级:",font=("Impact Bold", 20),padding=25)
# 将文本添加到窗口 并设置位置
textLabel2.place(x=50, y=500)
# 设置文本
textLabel3 = ttk.Label(root, text="暂无",font=("Impact Bold", 20),padding=25)
# 将文本添加到窗口 并设置位置
textLabel3.place(x=210, y=500)
root.mainloop()
最后的结果:
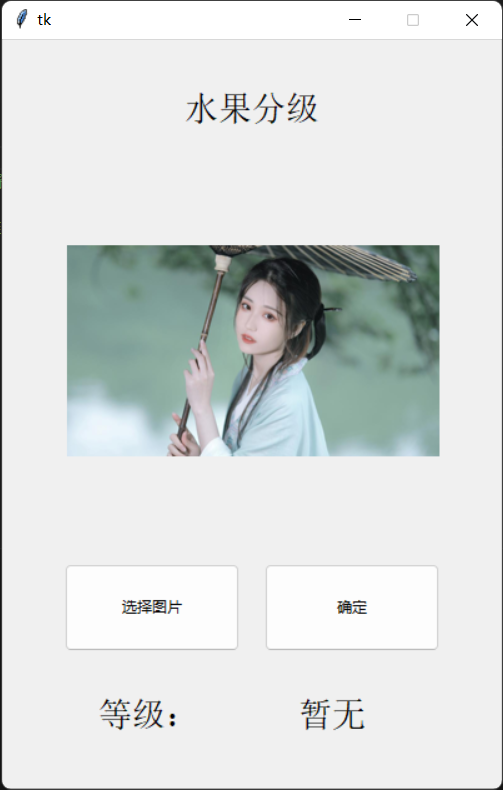
点击选择图片,进行选择
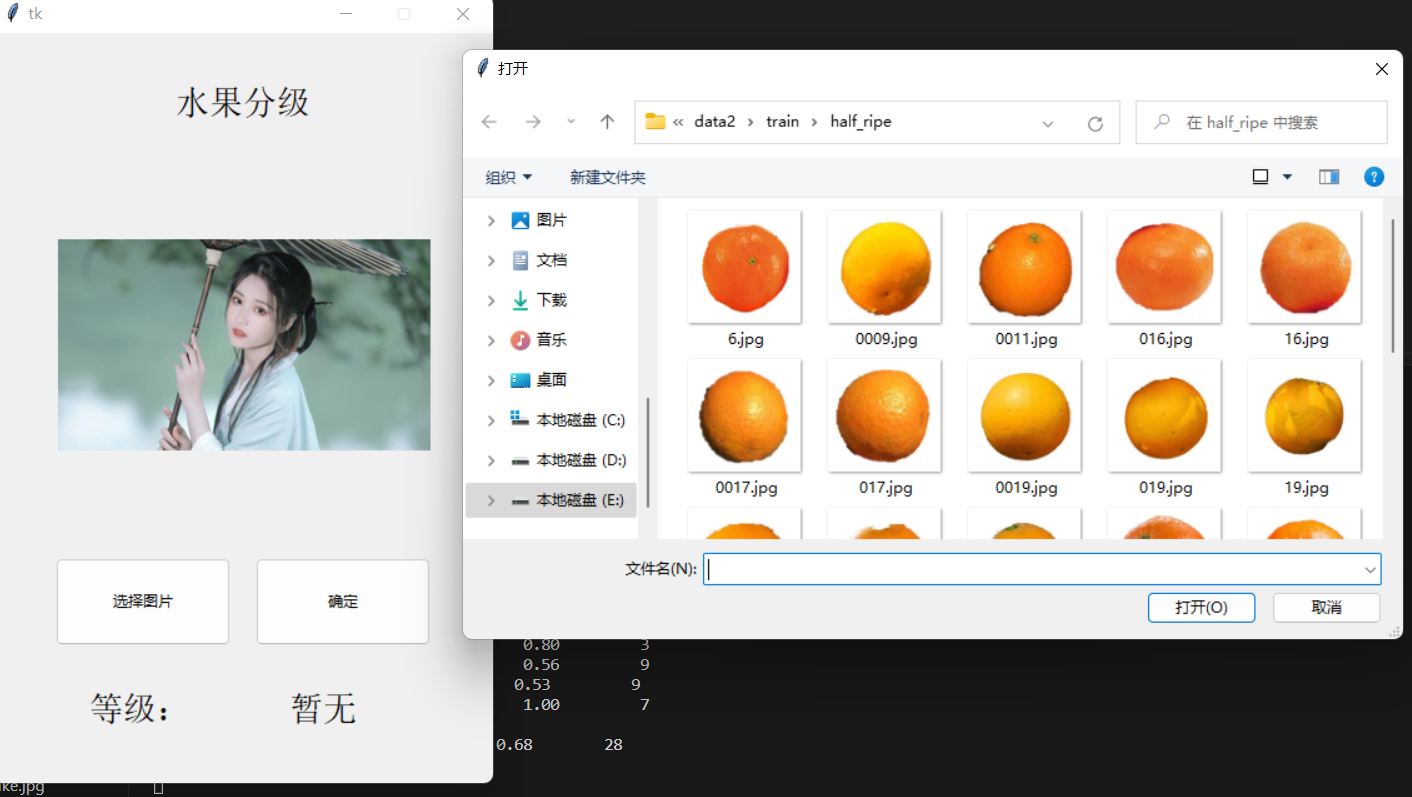
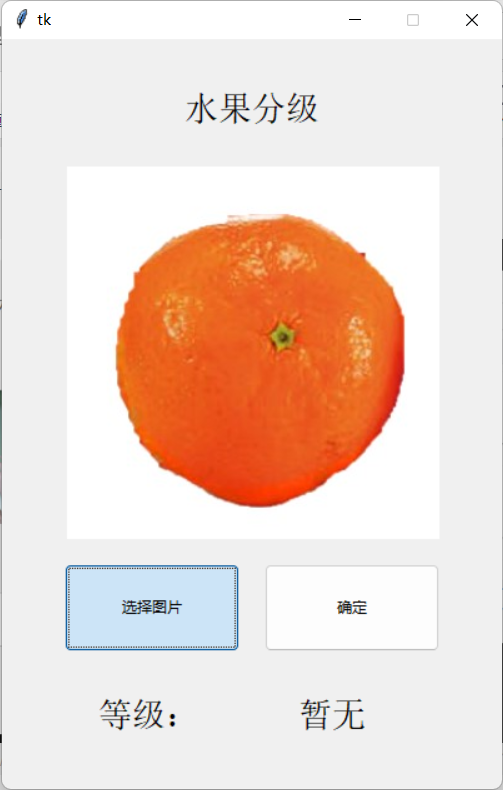
选择好后这个展示图片就变了
点击确定
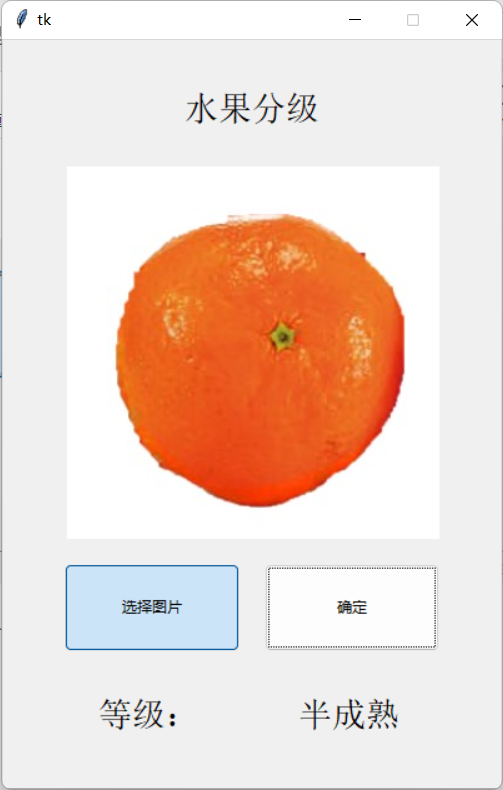
这里的文字就变了
当然我的数据集比较小,所以正确率比较低
2. 直接用skimage库进行图像特征提取,并使用SVM进行分类
2.1数据预处理,并提取特征
导入包
import os
import cv2
import numpy as np
from sklearn import svm
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from skimage.feature import greycomatrix, greycoprops
import pickle
skimage是一个基于Python的图像处理库,它提供了一系列用于图像处理、计算机视觉和机器学习的函数和算法。skimage基于SciPy库,使用NumPy进行数组操作,同时还支持matplotlib用于可视化和交互式探索。
skimage提供了多种图像处理功能,包括图像滤波、边缘检测、图像变换、图像分割、形态学操作、颜色空间转换等。此外,它还提供了一些特征提取和图像分类算法,如SIFT、HOG、LBP、PCA、SVM等。
提取特征的方法
# 定义函数提取图像纹理特征
def get_texture_features(img):
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_blur = cv2.GaussianBlur(img_gray, (5, 5), 0)
glcm = greycomatrix(img_blur, [5], [0], 256, symmetric=True, normed=True)
contrast = greycoprops(glcm, 'contrast')[0][0]
dissimilarity = greycoprops(glcm, 'dissimilarity')[0][0]
homogeneity = greycoprops(glcm, 'homogeneity')[0][0]
energy = greycoprops(glcm, 'energy')[0][0]
correlation = greycoprops(glcm, 'correlation')[0][0]
return np.array([contrast, dissimilarity, homogeneity, energy, correlation])
greycomatrix是sklearn库中的一个函数,用于计算灰度共生矩阵(Grey Level Co-occurrence Matrix,GLCM)。GLCM是一种描述图像中相邻像素之间灰度值关系的矩阵,可以用于计算纹理特征。
greycomatrix函数的参数包括图像数组、灰度级数、距离、角度等,返回的是一个灰度共生矩阵。
greycoprops是sklearn库中的一个函数,用于计算灰度共生矩阵的各种特征值。它的参数包括灰度共生矩阵和要计算的特征值名称,返回的是一个数组。
greycoprops函数支持的特征值名称有contrast、dissimilarity、homogeneity、ASM、energy、correlation和dissimilarity_angle等。
2.2 对数据集进行遍历并提取特征
主要使用os库
# 读取数据集
X = []
y = []
for root, dirs, files in os.walk('./data2/train'):
for file in files:
if file.endswith('.jpg'):
img = cv2.imread(os.path.join(root, file))
X.append(get_texture_features(img))
if 'unripe' in root:
y.append(0)
elif 'half_ripe' in root:
y.append(1)
elif 'ripe' in root:
y.append(2)
elif 'bad' in root:
y.append(3)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
2.3 SVM分类,并进行预测
# 训练SVM模型
clf = svm.SVC(kernel='linear', C=1, gamma='auto')
clf.fit(X_train, y_train)
# 保存模型
with open('svm_model.pkl', 'wb') as f:
pickle.dump(clf, f)
# 预测测试集数据
y_pred = clf.predict(X_test)
# 输出分类报告
target_names = ['未成熟', '半成熟', '成熟', '坏橘子']
print(classification_report(y_test, y_pred, target_names=target_names))
2.4 对单个图片进行预测
img = cv2.imread("./data2/train/ripe/0001.jpg")
featureOne = get_texture_features(img)
y_pred = clf.predict([featureOne])
print("预测是",target_names[y_pred[0]])
运行结果:
precision recall f1-score support
未成熟 0.30 1.00 0.46 3
半成熟 0.67 0.22 0.33 9
成熟 0.43 0.33 0.38 9
坏橘子 0.88 1.00 0.93 7
avg / total 0.60 0.54 0.51 28
预测是 成熟
这个可以用交互页面,就不展示了
其他:
保存模型:
# 保存模型
with open('svm_model.pkl', 'wb') as f:
pickle.dump(clf, f)
导入模型:
# 加载模型
with open('svm_model.pkl', 'rb') as f:
clf = pickle.load(f)
3. 总代码
3.1Alexnet模型与SVM模型
'''
Descripttion: 使用Alexnet提取数据集特征,并增加界面交互
version: 版本
Author: YueXuanZi
Date: 2023-06-12 08:56:30
LastEditors: YueXuanZi
LastEditTime: 2023-06-12 15:15:02
Experience: 心得体会
'''
import torch
import torchvision.models as models
import torchvision.transforms as transforms
import numpy as np
from PIL import Image
import cv2
import os
import torch.nn as nn
from sklearn import svm
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
import pickle
alexnet = models.alexnet(pretrained=False) # 加载预训练的AlexNet模型
# resnet = models.resnet50(pretrained=False)
# vgg = models.vgg16(pretrained=False)
def get_texture_features(image):
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image = transform(image)
# 增加一个维度,变成[1, 3, 224, 224]
image = image.unsqueeze(0)
# 提取特征
with torch.no_grad():
features = alexnet.features(image)
# features = vgg(image) # 1000
# features = resnet(image) # 1000
features = torch.flatten(features)
return np.array(features)
# 读取数据集
X = []
y = []
for root, dirs, files in os.walk('./data2/train'):
for file in files:
if file.endswith('.jpg'):
img = Image.open(os.path.join(root, file))
# img = cv2.imread(os.path.join(root, file))
X.append(get_texture_features(img))
if 'unripe' in root:
y.append(0)
elif 'half_ripe' in root:
y.append(1)
elif 'ripe' in root:
y.append(2)
elif 'bad' in root:
y.append(3)
X = np.array(X)
# print(X.shape)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练SVM模型
clf = svm.SVC(kernel='linear', C=1, gamma='auto')
clf.fit(X_train, y_train)
# 保存模型
with open('svm_model.pkl', 'wb') as f:
pickle.dump(clf, f)
# 预测测试集数据
y_pred = clf.predict(X_test)
# 输出分类报告
target_names = ['未成熟', '半成熟', '成熟', '坏橘子']
print(classification_report(y_test, y_pred, target_names=target_names))
# img = Image.open("./data2/train/ripe/0001.jpg")
# featureOne = get_texture_features(img)
# y_pred = clf.predict([featureOne])
# print("预测是",target_names[y_pred[0]])
from tkinter import *
from PIL import Image, ImageTk
from tkinter import filedialog
from tkinter import ttk
root = Tk()
root.geometry("400x600")
root.resizable(False, False)
textLabel = ttk.Label(root, text="水果分级",font=("Impact Bold", 20),anchor="center",padding=(30,40))
textLabel.pack()
# 打开图片并转换为 PhotoImage 对象
image = Image.open("./picture/women.jpg")
# 调整图片大小
# image = image.resize((300, 300), Image.ANTIALIAS)
# image = image.crop((0,0,299, 299))
thumbnail_size = (300, 300) # 缩略图大小
image.thumbnail(thumbnail_size)
photo = ImageTk.PhotoImage(image)
# 创建 Label 并设置图片
imagetk = ttk.Label(root, image=photo)
imagetk.place(x=50, y=100, width=300, height=300)
# 定义按钮点击时执行的函数
def selectClick(event):
fileName = filedialog.askopenfilename()
# print(fileName)
image = Image.open(fileName)
image = image.resize((300, 300), Image.ANTIALIAS)
photo = ImageTk.PhotoImage(image)
# 更新图片内容
imagetk.config(image=photo)
imagetk.image = photo
# print("修改成功")
text_var.set(fileName)
# 字符串
text_var = StringVar()
text_var.set("原始字符串")
# 点击确定,输出这个图片的种类
def sureChick(event):
# print(text_var.get())
img = Image.open(text_var.get())
featureOne = get_texture_features(img)
y_pred = clf.predict([featureOne])
target_names = ['未成熟', '半成熟', '成熟', '坏橘子']
textLabel3.config(text=target_names[y_pred[0]])
# 创建按钮对象,并设置文本和点击事件
selectbutton = ttk.Button(root, text="选择图片")
selectbutton.bind("<Button-1>",selectClick)
# 将按钮添加到窗口 并设置位置
selectbutton.place(x=50, y=420, width=140, height=70)
# 设置确定按钮
sureButton = ttk.Button(root, text="确定")
sureButton.bind("<Button-1>", sureChick)
# 将按钮添加到窗口 并设置位置
sureButton.place(x=210, y=420, width=140, height=70)
# 设置文本
textLabel2 = ttk.Label(root, text="等级:",font=("Impact Bold", 20),padding=25)
# 将文本添加到窗口 并设置位置
textLabel2.place(x=50, y=500)
# 设置文本
textLabel3 = ttk.Label(root, text="暂无",font=("Impact Bold", 20),padding=25)
# 将文本添加到窗口 并设置位置
textLabel3.place(x=210, y=500)
root.mainloop()
3.2 使用skimage库与SVM模型
'''
Descripttion: 橘子分类,skimage库,用SVM分类
version: 版本
Author: YueXuanZi
Date: 2023-06-11 10:39:52
LastEditors: YueXuanZi
LastEditTime: 2023-06-12 16:29:20
Experience: 心得体会
'''
import os
import cv2
import numpy as np
from sklearn import svm
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from skimage.feature import greycomatrix, greycoprops
import pickle
# 定义函数提取图像纹理特征
def get_texture_features(img):
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_blur = cv2.GaussianBlur(img_gray, (5, 5), 0)
glcm = greycomatrix(img_blur, [5], [0], 256, symmetric=True, normed=True)
contrast = greycoprops(glcm, 'contrast')[0][0]
dissimilarity = greycoprops(glcm, 'dissimilarity')[0][0]
homogeneity = greycoprops(glcm, 'homogeneity')[0][0]
energy = greycoprops(glcm, 'energy')[0][0]
correlation = greycoprops(glcm, 'correlation')[0][0]
return np.array([contrast, dissimilarity, homogeneity, energy, correlation])
# 读取数据集
X = []
y = []
for root, dirs, files in os.walk('./data2/train'):
for file in files:
if file.endswith('.jpg'):
img = cv2.imread(os.path.join(root, file))
X.append(get_texture_features(img))
if 'unripe' in root:
y.append(0)
elif 'half_ripe' in root:
y.append(1)
elif 'ripe' in root:
y.append(2)
elif 'bad' in root:
y.append(3)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练SVM模型
clf = svm.SVC(kernel='linear', C=1, gamma='auto')
clf.fit(X_train, y_train)
# 保存模型
with open('svm_model.pkl', 'wb') as f:
pickle.dump(clf, f)
# 预测测试集数据
y_pred = clf.predict(X_test)
# 输出分类报告
target_names = ['未成熟', '半成熟', '成熟', '坏橘子']
print(classification_report(y_test, y_pred, target_names=target_names))
img = cv2.imread("./data2/train/ripe/0001.jpg")
featureOne = get_texture_features(img)
y_pred = clf.predict([featureOne])
print("预测是",target_names[y_pred[0]])
4. 其他(可以忽略,与主要内容无关)
这是我之前做的时候,写的一些代码,算不上一点也没用吧。
- 分离图层
import cv2
print("欢迎使用test.py")
print(cv2.getVersionString())
image = cv2.imread("women.jpg")
cv2.imshow("image",image)
cv2.imshow("red",image[:,:,0])
cv2.imshow("blue",image[:,:,1])
cv2.imshow("green",image[:,:,2])
cv2.waitKey()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("gray",gray)
cv2.waitKey()
print(image.shape)
- 获取文件夹下所有文件的名字
import os
import cv2
def getFileList(dir,Filelist, ext=None):
"""
获取文件夹及其子文件夹中文件列表
输入 dir:文件夹根目录
输入 ext: 扩展名
返回: 文件路径列表
"""
newDir = dir
if os.path.isfile(dir):
if ext is None:
Filelist.append(dir)
else:
if ext in dir[-3:]:
Filelist.append(dir)
elif os.path.isdir(dir):
for s in os.listdir(dir):
newDir=os.path.join(dir,s)
getFileList(newDir, Filelist, ext)
return Filelist
org_img_folder='./picture'
# 检索文件
imglist = getFileList(org_img_folder, [], 'jpg')
print('本次执行检索到 '+str(len(imglist))+' 张图像\n')
# 依次展示图片
for imgpath in imglist:
imgname= os.path.splitext(os.path.basename(imgpath))[0]
img = cv2.imread(imgpath, cv2.IMREAD_COLOR)
# 对每幅图像执行相关操作
# cv2.namedWindow("001",cv2.WINDOW_NORMAL)
cv2.imshow("001",img)
cv2.waitKey()
- 定义鼠标下的事件cv2,我这个事件是点击后,输出点的数值
def getpos(event,x,y,flags,param):
if event==cv2.EVENT_LBUTTONDOWN: #定义一个鼠标左键按下去的事件
print(param[y,x])
# 转为HSV
img =cv2.imread("women.jpg")
imageHSV= cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
cv2.imshow("imageHSV",img)
cv2.setMouseCallback("imageHSV",getpos,img_hsv) # 通过点击获取图像中hsv的值
img_hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
lower_yellow = np.array([0, 50, 160]) # 设定红色的阈值,图像中低于这个值的,图像变为0
upper_yellow = np.array([30, 255, 255]) # 设定红色的阈值,图像中高于这个值的,图像变为0
mask = cv2.inRange(img_hsv, lower_yellow, upper_yellow) # 掩膜
cv2.imshow('mask', mask)
cv2.waitKey()
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(7,7))
img_ret1 = cv2.erode(mask,kernel,iterations=1) # 膨胀
cv2.imshow('mask', img_ret1)
cv2.waitKey()
- 获取该路径下的所有图片
# 获取该路径下的所有图片
def getPhoto(path_photo):
# path_photo = './data2/train/break_orange/' # 所有photo所在的文件夹目录
files_list = os.listdir(path_photo) # 得到文件夹下的所有文件名称,存在字符串列表中
# print(type(files_list))
# print(files_list) # 打印path_photo文件夹下的所有文件
imgs = []
for i in range(10):
path = path_photo+str(files_list[i])
# print(path)
img = cv2.imread(path)
imgs.append(img)
# cv2.imshow("img",imgs[1])
# cv2.waitKey()
return imgs
- 边缘检测和锐化处理
import cv2
import numpy as np
img = cv2.imread("./picture/dog.jpg",cv2.COLOR_BGR2RGB)
height,width = img.shape[:2]
# img = cv2.resize(img,(width//2,height//2),interpolation=cv2.INTER_CUBIC)
img = cv2.resize(img,None,fx=2,fy=2,interpolation=cv2.INTER_CUBIC)
# print(img.shape)
# (a,b,c) = img.shape
r1=cv2.Canny(img,128,200)
r2=cv2.Canny(img,32,128)
cv2.imshow("original",img)
cv2.imshow("result1",r1)
cv2.imshow("result2",r2)
kernel = np.array([
[-1, -1, -1],
[-1, 9, -1],
[-1, -1, -1]])
# 任意线性滤波器 把图像和卷积核进行卷积 参数2为卷积深度 -1和原图像一样
dst = cv2.filter2D(img, -1, kernel)
cv2.imshow("sharpness filter", dst)
cv2.waitKey(0)
cv2.destroyAllWindows()
- alexnet网络训练
'''
Descripttion: 一alexnet网络
version: 版本
Author: YueXuanZi
Date: 2023-06-10 12:21:46
LastEditors: YueXuanZi
LastEditTime: 2023-06-10 17:06:00
Experience: 心得体会
'''
import cv2
import numpy as np
import torch
import torchvision
from torchvision import transforms,datasets,utils
import torch.nn as nn
from torch.utils.data import DataLoader,Dataset
import matplotlib.pyplot as plt
from PIL import Image
from torch import nn
from torch import optim
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import accuracy_score #用于计算正确率
from torch.utils.tensorboard import SummaryWriter
# 读取数据集,预处理
def dataload(trainData,testData):
# 训练数据
train_data = torchvision.datasets.ImageFolder(trainData,transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Resize(300),
transforms.CenterCrop(300)]))
# train_data = torchvision.datasets.ImageFolder(trainData)
train_loader = DataLoader(train_data, batch_size=5, shuffle=True)
test_data = torchvision.datasets.ImageFolder(testData,transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Resize(300),
transforms.CenterCrop(300)]))
test_loader = DataLoader(test_data, batch_size=1, shuffle=True)
# 进行挑选
return train_data, test_data, train_loader, test_loader
if __name__=="__main__":
train_path = r"./data2/train"
test_path = r"./data2/test"
train_data, test_data, train_loader, test_loader = dataload(train_path,test_path)
# print(type(train_data))
# print(type(test_data))
# print(type(train_loader))
# print(type(test_loader))
# 接下来喂网络,进行训练
classes=("break_orange","good1","good2","good3")
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 一个不需要预训练的网络
VGG_false = torchvision.models.alexnet(pretrained=False)
# VGG_false = torch.load("tudui_20.pth")
VGG_false.to(device)
# 损失函数与优化器
loss=nn.CrossEntropyLoss()
optimizer=optim.SGD(VGG_false.parameters(),lr=0.001)
# 记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
# 添加tensorboard
writer=SummaryWriter("./logs_train")
for epoch in range(20):
print("——————第 {} 轮训练开始——————".format(epoch+1))
#训练开始
VGG_false.train()
for imgs,targets in train_loader:
imgs = imgs.to(device)
targets = targets.to(device)
output=VGG_false(imgs)
Loss=loss(output,targets)
# 优化器优化模型
optimizer.zero_grad()
Loss.backward()
optimizer.step()
_, pred = output.max(1)
num_correct = (pred == targets).sum().item()
acc = num_correct / (64)
total_train_step = total_train_step + 1
if total_train_step%100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step,Loss.item()))
writer.add_scalar("train_loss", Loss.item(), total_train_step)
writer.add_scalar("train_acc", acc, total_train_step)
# 测试步骤开始
VGG_false.eval()
eval_loss = 0
eval_losses = 0
eval_acc = 0
eval_acces = 0
with torch.no_grad():
for imgs,targets in test_loader:
imgs=imgs.to(device)
targets=targets.to(device)
output=VGG_false(imgs)
Loss=loss(output,targets)
_, pred = output.max(1)
num_correct = (pred == targets).sum().item()
eval_loss += Loss
acc = num_correct / imgs.shape[0]
eval_acc += acc
eval_losses = eval_loss/(len(test_loader))
eval_acces = eval_acc/(len(test_loader))
print("整体测试集上的Loss: {}".format(eval_losses))
print("整体测试集上的正确率: {}".format(eval_acces))
writer.add_scalar("test_loss", eval_losses, total_test_step)
writer.add_scalar("test_accuracy", eval_acces, total_test_step)
total_test_step = total_test_step + 1
if epoch==19:
epoch = epoch+1
torch.save(VGG_false, "tudui_{}.pth".format(epoch))
print("模型已保存")
- 对单个图片进行处理,进行分级(放弃的方法,主要是测算面积)
'''
Descripttion: 对单个图片进行处理,进行分级
version: 版本
Author: YueXuanZi
Date: 2023-06-07 14:54:49
LastEditors: YueXuanZi
LastEditTime: 2023-06-09 23:34:38
Experience: 心得体会
'''
import cv2
import torch
import os
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import sys
from JQ2 import Judge
from torchvision import transforms
# 获取该路径下的所有图片
def getPhoto(path_photo):
# path_photo = './data2/train/break_orange/' # 所有photo所在的文件夹目录
files_list = os.listdir(path_photo) # 得到文件夹下的所有文件名称,存在字符串列表中
# print(type(files_list))
# print(files_list) # 打印path_photo文件夹下的所有文件
imgs = []
for i in files_list:
path = path_photo+str(i)
# print(path)
img = cv2.imread(path)
imgs.append(img)
# cv2.imshow("img",imgs[1])
# cv2.waitKey()
return imgs,files_list
# 鼠标点击后,获取图片该点的信息
def getpos(event,x,y,flags,param):
if event==cv2.EVENT_LBUTTONDOWN: #定义一个鼠标左键按下去的事件
print(param[y,x])
# 去除小面积区域
def optimize(img_orange,area_in=20000):
# 寻找轮廓
contours, hierarchy = cv2.findContours(img_orange, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for i in range(len(contours)):
area = cv2.contourArea(contours[i])
if area < area_in:
cv2.drawContours(img_orange, [contours[i]], 0, 0, -1) # 去除小面积连通域
return img_orange
# 二值图增加原图后的效果
def mask_img_ground(img, img_mask):
area = np.sum(img_mask)
for i in range(len(img_mask)):
for j in range(len(img_mask[0])):
if img_mask[i][j]==0:
for k in range(3):
img[i][j][k]=0
return img,area
# 阈值分割函数
def threshold(img_cx, thresh_range,out_ran=128,in_ran=44):
'''对每个像素进行处理'''
img_cx_length = img_cx.shape[0]
img_cx_width = img_cx.shape[1]
range_min = thresh_range[0]
range_max = thresh_range[1]
for i in range(0,img_cx_length):
for j in range(0,img_cx_width):
if img_cx[i,j]<=range_min:
img_cx[i,j]=out_ran
elif img_cx[i,j]>=range_max:
img_cx[i,j]=out_ran
else:
img_cx[i,j]=in_ran
return img_cx
# 抠图,返回掩膜(二值图),面积,图片
def get_picture1(img):
img_ycbcr = cv2.cvtColor(img,cv2.COLOR_RGB2YCrCb)
# cv2.imshow("img",img_ycbcr) # 查看原图
# cv2.setMouseCallback("img",getpos,img_ycbcr) # 查看图中,点的值
lower_color = (30, 20, 140)
upper_color = (240, 120, 255)
# 掩膜处理
mask_img = cv2.inRange(img_ycbcr, lower_color, upper_color)
# cv2.imshow("mask_img",mask_img) # 查看橙色的抠图
# 获取绿色叶子
# lower_color = (40, 60, 100)
# upper_color = (200, 120, 150)
# # 掩膜处理
# mask_img2 = cv2.inRange(img_ycbcr, lower_color, upper_color)
# cv2.imshow("mask_img2",mask_img2) # 查看绿色抠图
# img_orange = mask_img + mask_img2
# cv2.imshow("img_orange",img_orange) # 查看抠完图的二值图
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(5,5)) #ksize=5,5
img_orange = cv2.dilate(mask_img,kernel,iterations=1)
img_orange = cv2.erode(img_orange,kernel,iterations=1)
img_orange = optimize(img_orange)
img_orange = cv2.dilate(img_orange,kernel,iterations=1)
img_orange = cv2.erode(img_orange,kernel,iterations=1)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(7,7)) #ksize=5,5
img_orange = cv2.dilate(img_orange,kernel,iterations=1)
mask = cv2.erode(img_orange,kernel,iterations=1)
# cv2.imshow('img_orange', img_orange)
img_orange2,area = mask_img_ground(img,mask)
cv2.imshow("imgo",img_orange2) # 查看图片
# cv2.setMouseCallback("imgo",getpos,img_orange2)
cv2.waitKey()
return img_orange,area,img_orange2
# 抠图,返回掩膜(二值图),面积,图片
def get_picture2(path):
img = cv2.imread(path)
img_ycbcr = cv2.cvtColor(img,cv2.COLOR_RGB2YCrCb)
# cv2.imshow("img",img_ycbcr) # 查看原图
# cv2.setMouseCallback("img",getpos,img_ycbcr) # 查看图中,点的值
lower_color = (30, 20, 140)
upper_color = (240, 120, 255)
# 掩膜处理
mask_img = cv2.inRange(img_ycbcr, lower_color, upper_color)
# cv2.imshow("mask_img",mask_img) # 查看橙色的抠图
# 获取绿色叶子
lower_color = (40, 60, 100)
upper_color = (200, 120, 150)
# 掩膜处理
mask_img2 = cv2.inRange(img_ycbcr, lower_color, upper_color)
# cv2.imshow("mask_img2",mask_img2) # 查看绿色抠图
img_orange = mask_img + mask_img2
# cv2.imshow("img_orange",img_orange) # 查看抠完图的二值图
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(5,5)) #ksize=5,5
img_orange = cv2.dilate(img_orange,kernel,iterations=1)
img_orange = cv2.erode(img_orange,kernel,iterations=1)
img_orange = optimize(img_orange)
img_orange = cv2.dilate(img_orange,kernel,iterations=1)
img_orange = cv2.erode(img_orange,kernel,iterations=1)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(7,7)) #ksize=5,5
img_orange = cv2.dilate(img_orange,kernel,iterations=1)
img_orange = cv2.erode(img_orange,kernel,iterations=1)
img_orange = cv2.dilate(img_orange,kernel,iterations=1)
mask = cv2.erode(img_orange,kernel,iterations=1)
# cv2.imshow('img_orange', img_orange)
img_orange2,area = mask_img_ground(img,mask)
cv2.imshow("imgo",img_orange2) # 查看图片
cv2.setMouseCallback("imgo",getpos,img_orange2)
cv2.waitKey()
return img_orange,area,img_orange2
# 设计一个阶级掩, 返回掩膜(二值图),面积,处理后的图片
def get_grading(img,grad):
img_ycbcr = cv2.cvtColor(img,cv2.COLOR_RGB2YCrCb)
lower_color = grad[0]
upper_color = grad[1]
# print(lower_color,upper_color)
mask_img = cv2.inRange(img_ycbcr, lower_color, upper_color)
# cv2.imshow("img",img)
# cv2.imshow("mask_img",mask_img) # 查看橙色的抠图
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(5,5)) #ksize=5,5
img_orange = cv2.dilate(mask_img,kernel,iterations=1)
img_orange = cv2.erode(img_orange,kernel,iterations=1)
img_orange = optimize(img_orange)
img_orange = cv2.dilate(img_orange,kernel,iterations=1)
img_orange = cv2.erode(img_orange,kernel,iterations=1)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(7,7)) #ksize=5,5
img_orange = cv2.dilate(img_orange,kernel,iterations=1)
img_orange = cv2.erode(img_orange,kernel,iterations=1)
img_orange = cv2.dilate(img_orange,kernel,iterations=1)
mask_img = cv2.erode(img_orange,kernel,iterations=1)
img_orange2,area = mask_img_ground(img,mask_img)
# cv2.imshow("imgo",img_orange2) # 查看图片
# cv2.waitKey()
return mask_img,area,img_orange2
# 对图片进行分级
# 读取路径,逐个处理图片
def grading_orange(path):
imgs,files_list = getPhoto(path) # 获取该文件夹里面的所有图片
# 进行分级,面积占比
train = [[],[],[]] # 三个级别
grad = np.array([[(30, 20, 140),(240, 120, 255)],[(0, 120, 215),(60, 170, 255)],[(0, 0, 160),(60, 120, 215)]])
print(2)
# 遍历每一个果子
i = 0
for img in imgs:
# img_mask,area,img_orange = get_picture1(img) # 获取掩膜,面积,橘子
# print(3)
img2 = np.copy(img)
mask_img,area,img2 = get_grading(img2,grad[0])
print(3)
mask_img,area2,img_orange3 = get_grading(img2,grad[1])
img2 = np.copy(img)
mask_img,area3,img_orange3 = get_grading(img2,grad[2])
print(4)
if (area2+area3)*100/area > 80:
train[0].append(img)
elif (area2+area3)*100/area > 50:
train[1].append(img)
else:
train[2].append(img)
print("已经完成第{i}张了")
i = i+1
return train
# 设计一个界面
def jieMian():
pass
if __name__=="__main__":
# path = r"./data2/train/good_orange/" # 108,93号橘子
# train = grading_orange(path)
# print(train.shape)
# 抠图,获取了橘子的抠图和抠图的面积
path = r"./data2/train/good_orange/93.jpg" # 108,93号橘子
mask,area,img = get_picture2(path)
# grad = np.array([[(30, 20, 140),(240, 120, 255)],[(0, 120, 215),(60, 170, 255)],[(0, 0, 160),(60, 120, 215)]])
# 利用Alexnet进行训练,判断是不是好橘子
# img = cv2.imread(path)
# get_picture1(img)
# img_ycbcr = cv2.cvtColor(img,cv2.COLOR_RGB2YCrCb)
# get_grading(img_ycbcr,grad[0])
####
indices = Judge(path)
# 颜色分级
# 是个坏果子,自动扔掉
if indices==0:
sys.exit()
# 其实就是用面积占比
# cv2.imshow("imgo",img)
# cv2.setMouseCallback("imgo",getpos,img)
# cv2.waitKey()
# grad = np.array([[(0, 120, 215),(60, 170, 255)],[(0, 0, 160),(60, 120, 215)]])
# img2 = np.copy(img)
# get_grading(img2,grad[0])
# img2 = np.copy(img)
# get_grading(img,grad[1])
# 计算好橘子的三个面的平均值
# 面积 area
5. 总结
说实话,这个我做了一星期,其实前六天跟没有做一样,方法错了,而且对于网络的使用没有那么好,算是一种复习吧。最后一天算是熟悉了网络,在网上查资料,开始写。刚开始我是用VGG来训练的,才25%,真的很低,后来才知道,原来是数据集太少了,所以就放弃它了。
刚开始的时候,我写了好多方法和代码,自己写的提取特征函数,还有网络,枯燥乏味。后面才真的的会用。而且代码其实也不用那么多。
不仅仅搜集资料的能力要好,而且,方向和方式也很重要,主要看你的选择,哈哈哈哈。
做的差不多后,我觉得还可以改进,就开始做交互页面,也算是一个亮点吧。
先把大框架做出来,最后再优化和改进,这很重要。
——————————————————————————————————————
交互页面的小姐姐,嘻嘻!!!
