本文分享SMOKE最新的版本的环境搭建,以及模型训练;环境关键库版本:pytorch 1.12.0、CUDA 11.3、cudnn 8.3.2、python 3.7、DCNv2。
目录
1、docker 获取Nvidia 镜像
拉取镜像到本地:11.3.1-cudnn8-devel-ubuntu20.04
docker pull nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04拉取镜像完成后,用docker images命令查看镜像的情况:
docker images能看到nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04镜像在本地了,镜像大小是8.95G。
打开镜像(常规模式--支持使用GPU)
docker run -i -t --gpus all nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04 /bin/bash
打开镜像(增强模式--支持使用GPU、映射目录、设置内存)
docker run -i -t -v /home/liguopu/:/guopu:rw --gpus all --shm-size 16G nvidia/cuda:11.3.1-cudnn8-devel-ubuntu20.04 /bin/bash平常进入了docker环境,然后创建或产生的文件,在退出docker环境后会“自动销毁”;或者想运行本地主机的某个程序,发现在docker环境中找不到。
我们可以通过映射目录的方式,把本地主机的某个目录,映射到docker环境中,这样产生的文件会保留在本地主机中。
通过-v 把本地主机目录 /home/liguopu/ 映射到docker环境中的/guopu 目录;其权限是rw,即能读能写。
默认分配很小的内参,在训练模型时不够用,可以通过参数设置:比如,我电脑有32G内参,想放16G到docker中使用,设置为 --shm-size 16G。
参考我这篇博客:docker 获取Nvidia 镜像 | cuda |cudnn_cudnn镜像站_一颗小树x的博客-CSDN博客
2、安装Conda
默认的系统镜像可能没有conda也没有python,我们可以安装Anaconda,来搭建深度学习环境
这里有两个下载地址可以选择,分别是官方下载地址、清华大学开源软件镜像站。
官方下载地址:Free Download | Anaconda
如果觉得官方地址下载慢,可以尝试下清华大学的下载地址:
清华大学开源软件镜像站:Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
比如选择:Anaconda3-2023.07-2-Linux-x86_64.sh
安装Anaconda3
进入下载文件的位置,打开终端terminal在文件目录下,使用bash 执行安装就可以啦:
bash Anaconda3-2023.07-2-Linux-x86_64.sh
安装过程:
1)输入回车键确认安装;
2)阅读Anaconda最终用户许可协议,按下回车浏览完信息;
3)问我们是否接受该协议,只能接受了,输入yes;(Do you accept the license terms? [yes|no])
4)提示安装到以下位置,回车确认即可;(Anaconda3 will now be installed into this location:)
5)是否加入环境变量,通常是选择yes的;这个根据自己情况选择,如果经常用conda环境开发,建议选择yes(Do you wish the installer to initialize Anaconda3 in your /home/linuxidc/.bashrc ? [yes|no])
完成conda安装:

用另一个终端打开这个镜像创建的容器:
能看到能conda的初始环境了,说明conda安装成功啦。
3、创建SMOKE环境
用conda命令创建
conda create -n SMOKE python=3.7下载代码到本地
git clone https://github.com/lzccccc/SMOKE安装torch1.12
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch修改DCNv2版本,改为最新的torch1.11(亲测可用)
https://github.com/lbin/DCNv2/tree/pytorch_1.11
下载DCNv2文件,然后:
- 将SMOKE源码中的smoke/csrc中的文件全部替换为DCNv2/src中的文件
- 将smoke/layers/dcn_v2.py文件替换为DCNv2/dcn_v2.py文件
替换后修改smoke/layers/dcn_v2.py中代码,把 import _ext as _backend 改为:from smoke import _ext as _backend
4、编译SMOKE环境
cd SMOKE
python setup.py build develop编译成功信息
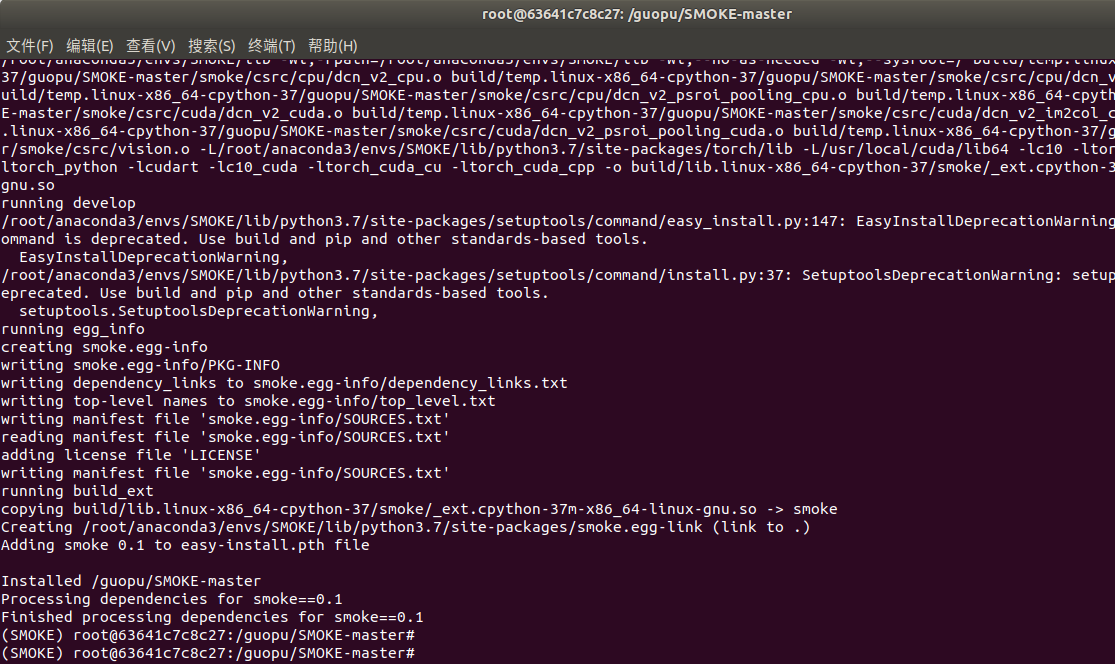
用coda list查看smoke库已经安装成功了
安装其他库
pip install yacs scikit-image tqdm -i https://mirrors.aliyun.com/pypi/simple/5、下载kitti 3D目标检测数据集
官网链接:The KITTI Vision Benchmark Suite
需要下载的文件:
- Download left color images of object data set (12 GB) 这是图片,包括训练集和测试集
- Download camera calibration matrices of object data set (16 MB) 这是相机的标定相关的文件
- Download training labels of object data set (5 MB) 这是图片训练集对应的标签
- Download object development kit (1 MB) 这是评价模型的代码,后面要用到,训练时用不到
这个些文件在官网下载需要注册账号,而且需要tizi才会速度快;我保存到了百度网盘,方便下载。
下载好文件是这样的:

6、处理数据集
首先解压文件,在datasets文件夹中,创建一个kitti文件夹,按照如下路径存放:
kitti
│──training
│ ├──calib
│ ├──label_2
│ ├──image_2
│ └──ImageSets
└──testing
├──calib
├──image_2
└──ImageSets
这里除了ImageSets文件夹,其他都有了;ImageSets主要是存放训练或测试时,所用到那些文件,指定文件的名称;
比如,在kitti/training/ImageSets/目录下,创建一个文件trainval.txt,内容如下:
000000
000001
000002
...
007479
007480
那么如何生成这个trainval.txt,写个python小程序即可,这个程序放在xxxx/SMOKE-master/datasets/kitti/training/下,执行即可
比如命名为:create_imagesets_trainval_sort.py
代码如下:
'''
文件路径:
xxxx/SMOKE-master/datasets/kitti/training/
'''
import os
# 获取文件夹下的所有文件名称,并排序
files = os.listdir("./image_2")
files.sort()
# 创建/打开一个txt文件
save_txt = open("./ImageSets/trainval.txt", 'w')
# 遍历列表,逐一获取文件名
for file in files:
print("file:", file)
file_name = file.split(".")[0]
save_txt.write(file_name)
save_txt.write("\n")比如,在kitti/training/ImageSets/目录下,创建一个文件test.txt,内容如下:
000000
000001
000002
...
007516
007517
那么如何生成这个test.txt,写个python小程序即可,,这个程序放在xxxx/SMOKE-master/datasets/kitti/testing/下,执行即可
'''
文件路径:
xxxx/SMOKE-master/datasets/kitti/testing/
'''
import os
# 获取文件夹下的所有文件名称,并排序
files = os.listdir("./image_2")
files.sort()
# 创建/打开一个txt文件
save_txt = open("./ImageSets/test.txt", 'w')
# 遍历列表,逐一获取文件名
for file in files:
print("file:", file)
file_name = file.split(".")[0]
save_txt.write(file_name)
save_txt.write("\n")
7、开始训练
首先看一个训练的配置文件,configs/smoke_gn_vector.yaml
MODEL:
WEIGHT: "catalog://ImageNetPretrained/DLA34"
INPUT:
FLIP_PROB_TRAIN: 0.5
SHIFT_SCALE_PROB_TRAIN: 0.3
DATASETS:
DETECT_CLASSES: ("Car", "Cyclist", "Pedestrian")
TRAIN: ("kitti_train",)
TEST: ("kitti_test",)
TRAIN_SPLIT: "trainval"
TEST_SPLIT: "test"
SOLVER:
BASE_LR: 2.5e-4
STEPS: (10000, 18000)
MAX_ITERATION: 25000
IMS_PER_BATCH: 32MAX_ITERATION,这里官网的训练轮数是25000次,挺夸张的,可以修改。
IMS_PER_BATCH,批量大小是32,显存没这么大,可以改小一些。
STEPS,是训练过程中,在多少轮时,保存模型的权重;默认是10000轮、18000轮,自行修改。
其它的根据任务情况,修改即可。
单GPU训练的命令如下:
python tools/plain_train_net.py --config-file "configs/smoke_gn_vector.yaml"模型开始训练打印信息
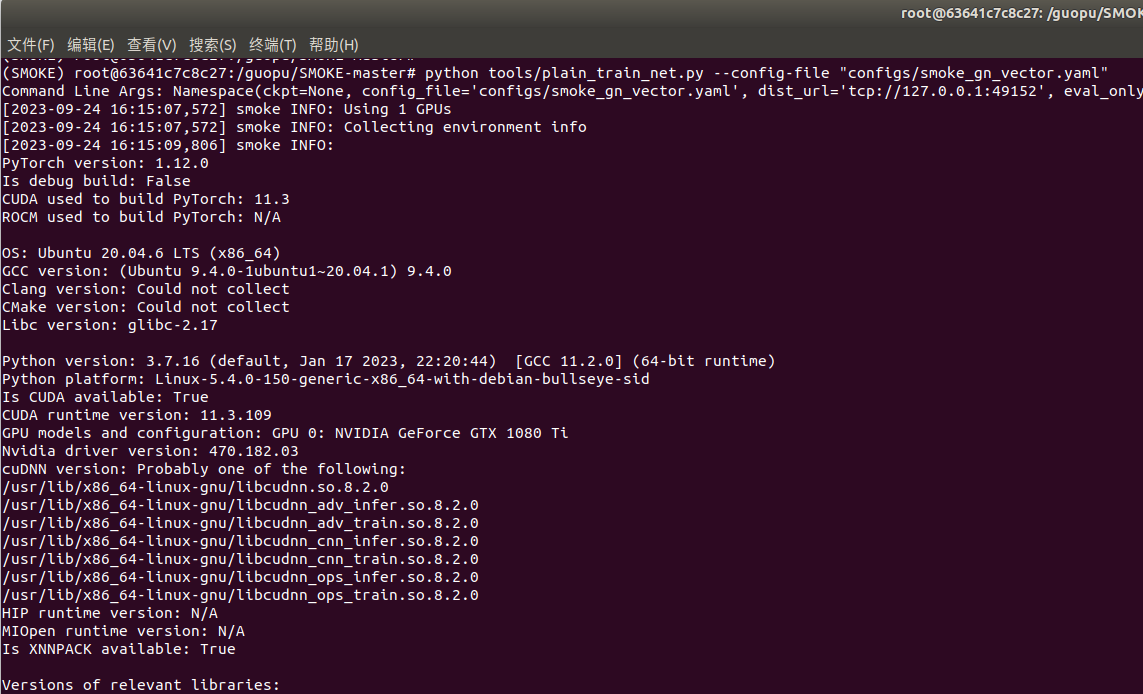
打印训练配置和模型结构

训练中,有提示信息,包括迭代轮数、损失、学习率变化等
[2023-09-24 16:15:11,299] smoke.data.datasets.kitti INFO: Initializing KITTI trainval set with 7481 files loaded
[2023-09-24 16:15:11,299] smoke.trainer INFO: Start training
[2023-09-24 16:15:16,859] smoke.trainer INFO: eta: 0:27:41 iter: 10 loss: 7.9971 (21.7083) hm_loss: 4.5385 (19.3146) reg_loss: 1.4058 (2.3936) time: 0.2013 (0.5557) data: 0.0078 (0.0284) lr: 0.00025000 max men: 4816
[2023-09-24 16:15:18,872] smoke.trainer INFO: eta: 0:18:48 iter: 20 loss: 6.0802 (13.6487) hm_loss: 4.1279 (11.7072) reg_loss: 1.4058 (1.9416) time: 0.2011 (0.3786) data: 0.0078 (0.0182) lr: 0.00025000 max men: 4816
[2023-09-24 16:15:20,889] smoke.trainer INFO: eta: 0:15:49 iter: 30 loss: 4.9480 (10.5877) hm_loss: 3.7482 (9.0827) reg_loss: 0.7232 (1.5050) time: 0.2012 (0.3196) data: 0.0079 (0.0148) lr: 0.00025000 max men: 4816
[2023-09-24 16:15:22,904] smoke.trainer INFO: eta: 0:14:18 iter: 40 loss: 4.8069 (9.3238) hm_loss: 3.5018 (7.6436) reg_loss: 0.8950 (1.6802) time: 0.2012 (0.2901) data: 0.0080 (0.0131) lr: 0.00025000 max men: 4816
[2023-09-24 16:15:24,921] smoke.trainer INFO: eta: 0:13:23 iter: 50 loss: 4.3501 (8.3160) hm_loss: 3.2921 (6.8062) reg_loss: 0.6793 (1.5098) time: 0.2011 (0.2724) data: 0.0080 (0.0121) lr: 0.00025000 max men: 4816
[2023-09-24 16:15:26,954] smoke.trainer INFO: eta: 0:12:47 iter: 60 loss: 4.1979 (7.6786) hm_loss: 3.2857 (6.2086) reg_loss: 0.5120 (1.4699) time: 0.2022 (0.2609) data: 0.0080 (0.0114) lr: 0.00025000 max men: 4816
[2023-09-24 16:15:28,982] smoke.trainer INFO: eta: 0:12:20 iter: 70 loss: 4.2102 (7.2046) hm_loss: 3.0555 (5.7704) reg_loss: 0.8590 (1.4341) time: 0.2027 (0.2526) data: 0.0080 (0.0109) lr: 0.00025000 max men: 4816
[2023-09-24 16:15:31,048] smoke.trainer INFO: eta: 0:12:00 iter: 80 loss: 4.5890 (6.9815) hm_loss: 2.9401 (5.4155) reg_loss: 1.4550 (1.5660) time: 0.2029 (0.2468) data: 0.0080
训练完成
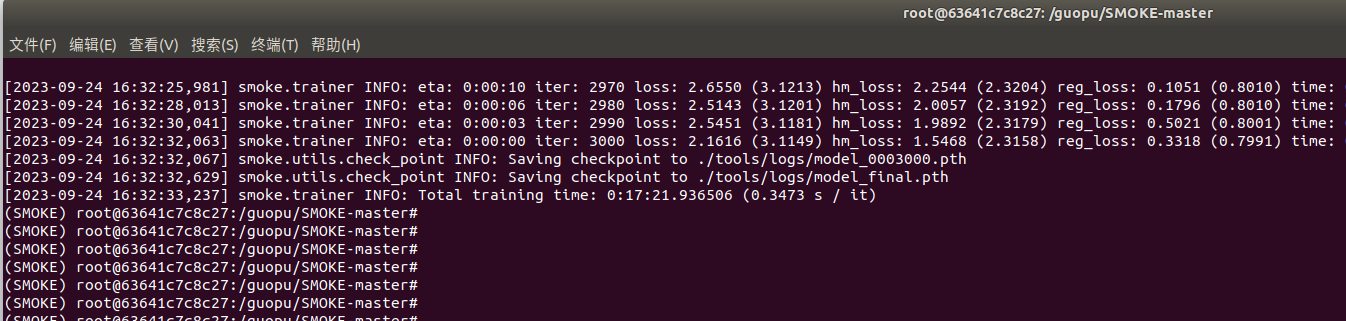
训练中,在tools\目录下生成一个logs目录,存放日志文件、模型权重等等:
模型一共训练3000轮,我把STEPS改为了(1000,2000,3000),所以在1000,2000,3000轮会保存权重。
模型效果:

分享完成~