一、About ZipKin
please google
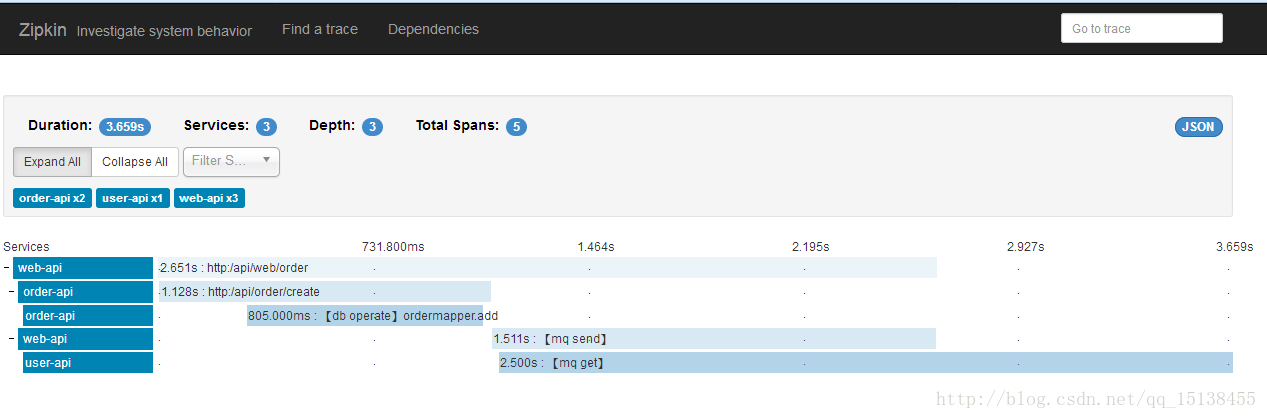
二、 Demo Scene
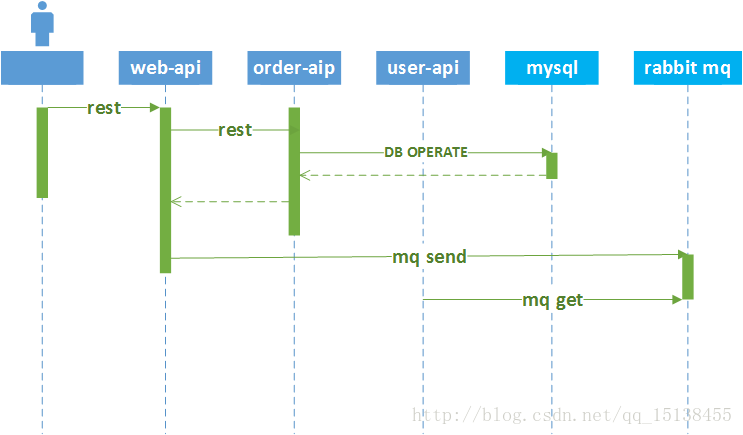
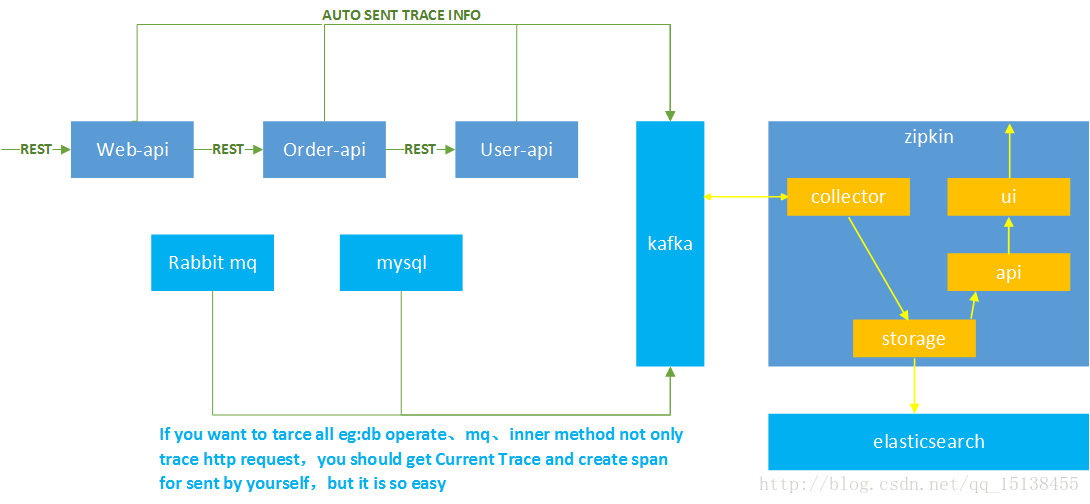
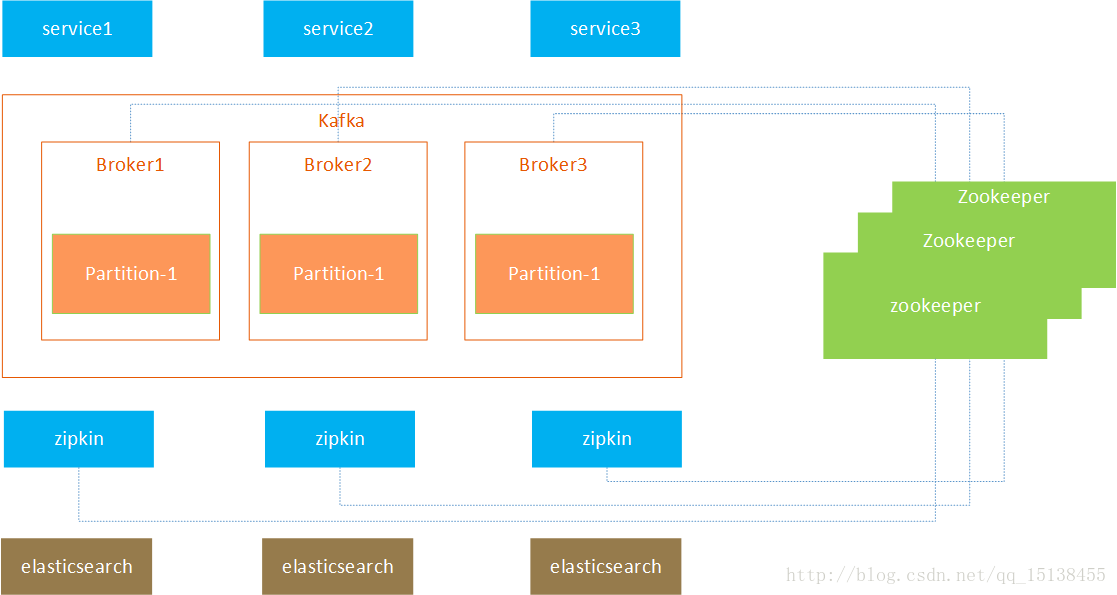
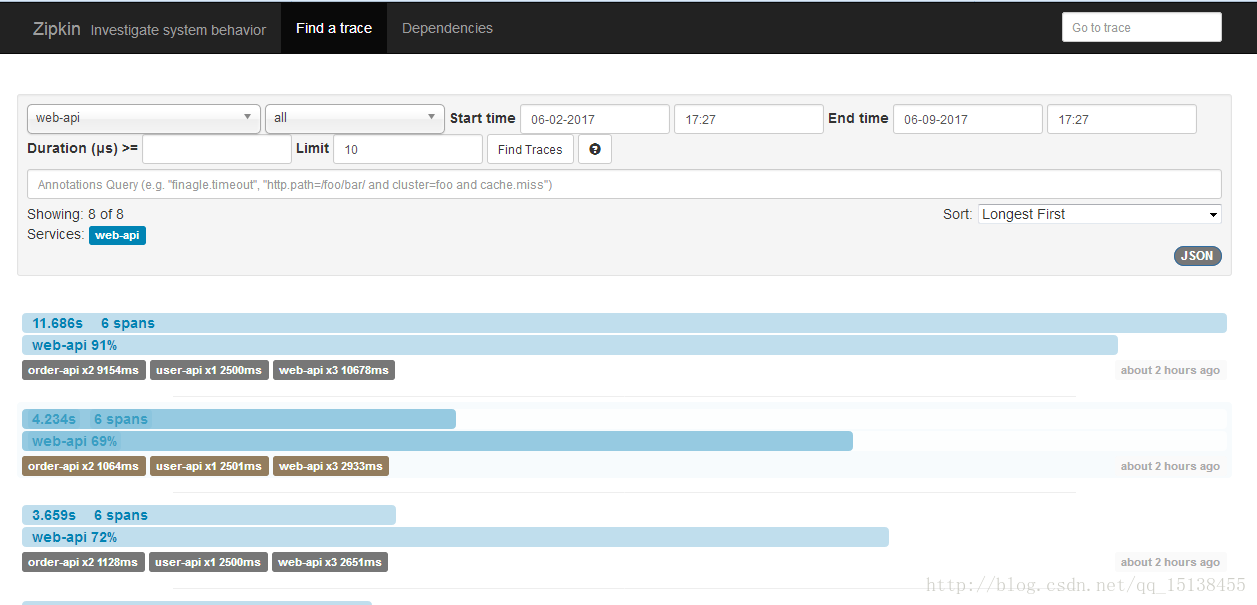
三、 Result Display
四、Prepare
1、soft version
zokeeper:3.4.10
elasticsearch:5.2.2
jdk:1.8
spring boot:1.5.3.RELEASE
sprign cloud:Dalston.RELEASE
rabbit mq:3.6.9
2、install
kafka+zookeeperelasticsearch
rabbit mq
mysql
3、create four spring cloud project
ps:
why i will create zipkin project use spring boot by myself not use zipkin.jar from http://zipkin.io/,actually,zipkin.jar is a spring boot project,check it's dependency lib you will find it din't use spring-cloud-sleuth-stream,but i will send trace info to kafka for zipkin server collector ,so i must use spring-cloud-sleuth-stream in my service
and the message send to kafka is a sleuth.span object and use kafka default serialized,but zipkin.jar only receive zipkin.span and json or thrift encode,so it‘s not matching,That's the reason i create zipkin server
but if you use rabbit mq,that's no problem.
4、configuration
4.1、the service web-api、user-api、order-api config part like:pom.xml
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-stream-kafka</artifactId>
- </dependency>
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-kafka</artifactId> </dependency>application.properties
- spring.sleuth.sampler.percentage=1.0
- spring.cloud.stream.kafka.binder.brokers=10.20.1.11:9092,10.20.1.12:9092
- spring.cloud.stream.kafka.binder.zkNodes=10.20.1.11:2181,10.20.1.12:2181
spring.sleuth.sampler.percentage=1.0 spring.cloud.stream.kafka.binder.brokers=10.20.1.11:9092,10.20.1.12:9092 spring.cloud.stream.kafka.binder.zkNodes=10.20.1.11:2181,10.20.1.12:21814.2、the zipkinconfig part like:
pom.xml
- <!-- the first one dependency below,In principle, there is no need,beause sleuth-zipkin-stream 1.5.3 will Introduce zipkin version1.19 Automaticly,but 1.19 only support elasticsearch version 2.X -->
- <dependency>
- <groupId>io.zipkin.java</groupId>
- <artifactId>zipkin</artifactId>
- <version>1.24.0</version>
- </dependency>
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-stream-kafka</artifactId>
- </dependency>
- <dependency>
- <groupId>io.zipkin.java</groupId>
- <artifactId>zipkin-autoconfigure-storage-elasticsearch-http</artifactId>
- <version>1.24.0</version>
- <optional>true</optional>
- </dependency>
<!-- the first one dependency below,In principle, there is no need,beause sleuth-zipkin-stream 1.5.3 will Introduce zipkin version1.19 Automaticly,but 1.19 only support elasticsearch version 2.X --> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin</artifactId> <version>1.24.0</version> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-kafka</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-storage-elasticsearch-http</artifactId> <version>1.24.0</version> <optional>true</optional> </dependency>application.properties
- #kafka config
- spring.sleuth.enabled=false
- spring.sleuth.sampler.percentage=1.0
- spring.cloud.stream.kafka.binder.brokers=10.20.1.11:9092,10.20.1.12:9092
- spring.cloud.stream.kafka.binder.zkNodes=10.20.1.11:2181,10.20.1.12:2181
- #elasticsearch config
- zipkin.storage.type=elasticsearch
- zipkin.storage.elasticsearch.hosts=10.20.1.11:9200,10.20.1.12:9200
- zipkin.storage.elasticsearch.cluster=elasticsearch
- zipkin.storage.elasticsearch.index=zipkin
- zipkin.storage.elasticsearch.index-shards=5
- zipkin.storage.elasticsearch.index-replicas=1
#kafka config spring.sleuth.enabled=false spring.sleuth.sampler.percentage=1.0 spring.cloud.stream.kafka.binder.brokers=10.20.1.11:9092,10.20.1.12:9092 spring.cloud.stream.kafka.binder.zkNodes=10.20.1.11:2181,10.20.1.12:2181 #elasticsearch config zipkin.storage.type=elasticsearch zipkin.storage.elasticsearch.hosts=10.20.1.11:9200,10.20.1.12:9200 zipkin.storage.elasticsearch.cluster=elasticsearch zipkin.storage.elasticsearch.index=zipkin zipkin.storage.elasticsearch.index-shards=5 zipkin.storage.elasticsearch.index-replicas=1ZipKin Server Startup class configuration
- <span style="font-size:14px;">@SpringBootApplication
- //@EnableZipkinServer //this is used by interface receive trace info
- @EnableZipkinStreamServer //can be used kafka,rabbit
- public class ZkingApplication {
- public static void main(String[] args) {
- SpringApplication.run(ZkingApplication.class, args);
- }
- }</span>
@SpringBootApplication
//@EnableZipkinServer //this is used by interface receive trace info
@EnableZipkinStreamServer //can be used kafka,rabbit
public class ZkingApplication {
public static void main(String[] args) {
SpringApplication.run(ZkingApplication.class, args);
}
}
五、Demo DownLoad
by the way,spring cloud is a pretty boy,i like its combination of terseness and elegance
六、补充
如果kafka没有启动,spring boot会启动失败,这个异常处理设计的真是缺德
/**
* 1、修改背景
* 因kafka节点没有启动 在spring boot启动时初始化outputBindingLifecycle、inputBindingLifecycle
* 两个bean时候连接kafka失败,向外抛出了异常直到EmbeddedWebApplicationContext类
* 捕获处理,处理方式为:stopAndReleaseEmbeddedServletContainer()导致整个应用停止启动
* 2、修改方案
* 干预上面两个bean的初始化,在连接kafka异常时,将异常处理掉,不向上层抛出
* 3、修改步骤
* 3.1、使用自定义MyBindingLifecycle的bean将BindingServiceConfiguration中的两个bean初始化替换掉
* 3.2、在自定bean中启动线程MyBindingThread来控制两个bean的初始化
* 4、解决启动问题之后,实际上kafka还是没有连接的,此时向kafka发送span时会失败,默认的处理方案是捕获到异常之后使用
* handleError处理,再次发送新的span,这就导致循环发送
* 参见:ErrorHandlingTaskExecutor中的execute方法
* catch (Throwable t)
* {
* ErrorHandlingTaskExecutor.this.errorHandler.handleError(t);
* }
* 5、解决方案
* 重写ErrorHandler的handleError方法
* 6、跟踪代码发现
* 跟踪发现ErrorHandler对线对象是在SourcePollingChannelAdapterFactoryBean初始化时候设置的
* spca.setErrorHandler(this.pollerMetadata.getErrorHandler());
* 进一步发现是在pollerMetadata对象中,所以需要在pollerMetadata对象初始化时候做修改
* 7、修改步骤
* 自定义MyPollerMetadata且需要@Configuration,重写handleError方法如下
* @author zhangdingxin、yangxi
*/