当我们在使用xgboost或者lightgbm等机器学习包时,这些包的输入数据默认都是全数值形式的矩阵,但是我们的原始数据中有可能出现分类变量等非数值型变量,那么如何使用R放入数据包进行one-hot编码是一件很重要的事情
我们使用ggplot2中的diamonds数据集和R自带的model.matrix函数。
观察diamonds数据集:
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 53940 obs. of 10 variables:
$ carat : num 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ...
$ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ...
$ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ...
$ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ...
$ depth : num 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ...
$ table : num 55 61 65 58 58 57 57 55 61 61 ...
$ price : int 326 326 327 334 335 336 336 337 337 338 ...
$ x : num 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ...
$ y : num 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ...
$ z : num 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...
其中cut,color,clarity都是因子型变量,接下来以cut为例演示如何进行one-hot编码:
model.matrix(~cut-1,diamonds) %>% as.data.frame()
函数格式为(~你想编码的列名-1,数据集名称),我们来观察一下返回数据结果:
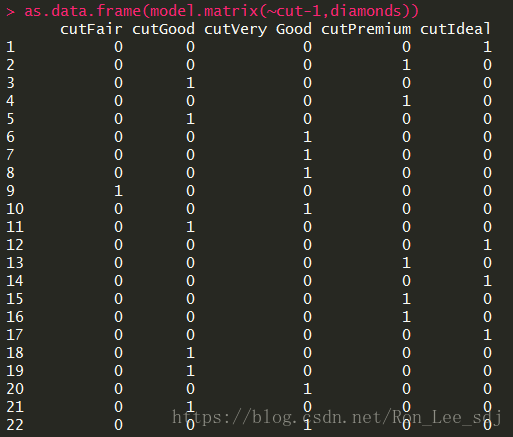
结果产生了新的数据,列的命名方式都是原始列名+因子类型,接下来将只包含有数值型的数据集和编码之后的数据集合并,就可以得到新的数据集
rbind(select_if(diamonds,is.numeric),as.data.frame(model.matrix(~cut-1,diamonds)))
这样经过one-hot编码的数据集就产生了,其余的变量以此类推即可
最后关联我做的diamonds数据集的数据科学tutorial,已发表在RPubs上,包含数据检查,数据可视化,数据操作,机器学习建模等数据科学大部分流程