
LLMPerf是一个开源项目,旨在帮助用户对语言模型进行基准测试,并使其性能具有可复现性。它能够帮助用户评估不同LLM的性能,并根据具体任务做出明智的决策。该项目选择了多个指标来衡量LLM的性能,包括吞吐量、时延、内存使用和成本等。本文介绍了如何使用LLMPerf进行基准测试,并提供了一些实用的技巧和建议。此外,本文还对当前最流行的LLM进行了基准测试,并提供了详细的结果和分析。
需要说明的是,LLMPerf测试可能仍需进一步完善。本文中他们对比了Fireworks给出的性能,不过Fireworks也发布博客进行了澄清,我们也将在后续文章中加以介绍。
(本文由OneFlow编译发布,转载请联系授权。原文:https://www.anyscale.com/blog/reproducible-performance-metrics-for-llm-inference)
来源 | Anyscale
OneFlow编译
翻译|宛子琳、杨婷
重点内容摘要:
-
我们见过许多关于LLM性能的声明,然而,这些声明通常难以复现。
-
我们发布了LLMPerf(https://github.com/ray-project/llmperf),这是一个用于对LLM进行基准测试,以复现这些声明的开源项目。本文将讨论我们选择的指标以及如何对其进行衡量。
-
有趣见解:100个输入词元与单个输出词元对时延的影响大致相当。若想提升速度,减少输出要比减少输入更有效。
-
我们还展示了这些基准测试在部分当前LLM产品上的结果,并确定了这些LLM产品各自的优势。其中重点关注的是Llama 2-70B。
-
对单个词元价格测算的结果总结:由于速率限制较低,Perplexity beta目前尚不适用于在生产环境中使用;Fireworks.ai和Anyscale Endpoints均可行,但在典型工作负载(550个输入词元,150个输出词元)的平均端到端时延上,Anyscale Endpoints便宜15%,快17%。Fireworks在高负载水平下的首词元时间(Time To First Token,TTFT)更短。
-
特别是在LLM中,由于性能特征变化迅速,每种用例都有不同的要求,因此“因人而异(Your mileage may vary)”的规则更为适用。
最近,许多人宣称他们的LLM推理表现出色。然而,这些声明通常是不可复现的,而且细节也存在缺失,例如,某篇帖子仅声明称其结果针对“不同输入大小”,并附上了一张人们看不懂的图表。
我们考虑过发布自己的基准测试结果,但意识到仅仅发布结果只会延续不可复现的问题。因此,除发布结果之外,我们还拿出了自己内部的基准测试工具,并将其开源。
在接下来的部分,我们将讨论衡量LLM的关键指标,以及各个供应商在相应指标上的表现。
1
LLM的定量性能指标
LLM的关键指标是什么?我们建议将重点放在以下指标:
通用指标
以下指标适用于共享公共端点以及专用实例。
每分钟完成的请求数
在几乎所有情况下,你都希望系统能够处理并发请求。这可能是因为你正在处理来自多个用户的输入,或者可能有一个批量推理工作负载。
在许多情况下,除非你与共享公共端点的供应商达成了某些额外协议,否则他们会将你的速率限制得非常低。我们发现,一些供应商将速率限制在90秒内不超过3个请求。
首词元时间(TTFT)
在流式应用中,TTFT指的是LLM返回第一个词元前所需的时间。我们不仅对平均TTFT感兴趣,还包括其分布:P50、P90、P95和P99。
词元间时延(ITL)
词元间时延指的是连续输出词元之间的平均时间。我们决定将TTFT纳入词元间时延的计算。我们发现有些系统在端到端时间中很晚才开始流式传输。
端到端时延
端到端时延应该大致等于词元的平均输出长度乘以词元间时延。
单个典型请求的成本
API供应商通常可以通过牺牲其中一个指标来降低成本。例如,你可以通过在更多GPU上运行相同的模型或使用更高端的GPU来降低时延。
2
专用实例的额外指标
如果你正在使用专用计算运行LLM,例如Anyscale Private Endpoints,那么就会有一些额外标准。请注意,很难比较通用LLM实例和专有LLM实例的性能:它们的约束条件不同,利用率成为一个更为重要的实际问题。
配置
同一模型通常由于配置不同,导致在时延、成本和吞吐量之间出现不同权衡。例如,在p4de实例上运行的CodeLlama-34B模型可以配置为8个副本,每个副本有1个GPU,也可以配置为4个副本,每个副本有2个GPU,或者配置为2个副本,每个副本有4个GPU,甚至还可以配置为1个副本,拥有全部8个GPU。你还可以为流水并行或张量并行配置多个GPU。
每种配置都有不同特性:每个副本有一个GPU的情况可能拥有最低的TTFT(因为有8个“队列”等待输入),而一个副本有8个GPU的情况可能具备最大的吞吐量(因为有更多的批处理内存,且实际上有8倍的内存带宽)。
每种配置都会导致不同的基准测试结果。
输出词元吞吐量
还有一个重要的额外标准:总生成词元吞吐量,这便于比较成本。
最大利用率下的每百万词元成本
为比较不同配置的成本(例如,你可以在1个A10G GPU、2个A10G GPU或1个A100-40GB GPU上提供Llama 2-7B模型等),考虑给定输出的部署总成本十分重要。为进行比较,我们将使用AWS的1年预留实例定价(https://aws.amazon.com/cn/ec2/instance-types/p4/)。
3
考虑到但没有包含的测量标准
当然,我们可以将其他衡量标准添加到该列表。
预加载时间(未包含)
由于预加载时间只能通过对输入大小的首词元的回归来间接测算,因此我们在这一轮基准测试中没有加入这一指标。我们计划在未来的版本中添加预加载时间。
根据我们对大多数当前技术的经验,并没有发现预加载时间(获取输入词元,将它们加载到GPU并计算注意力值)对时延的影响比输出词元更显著。
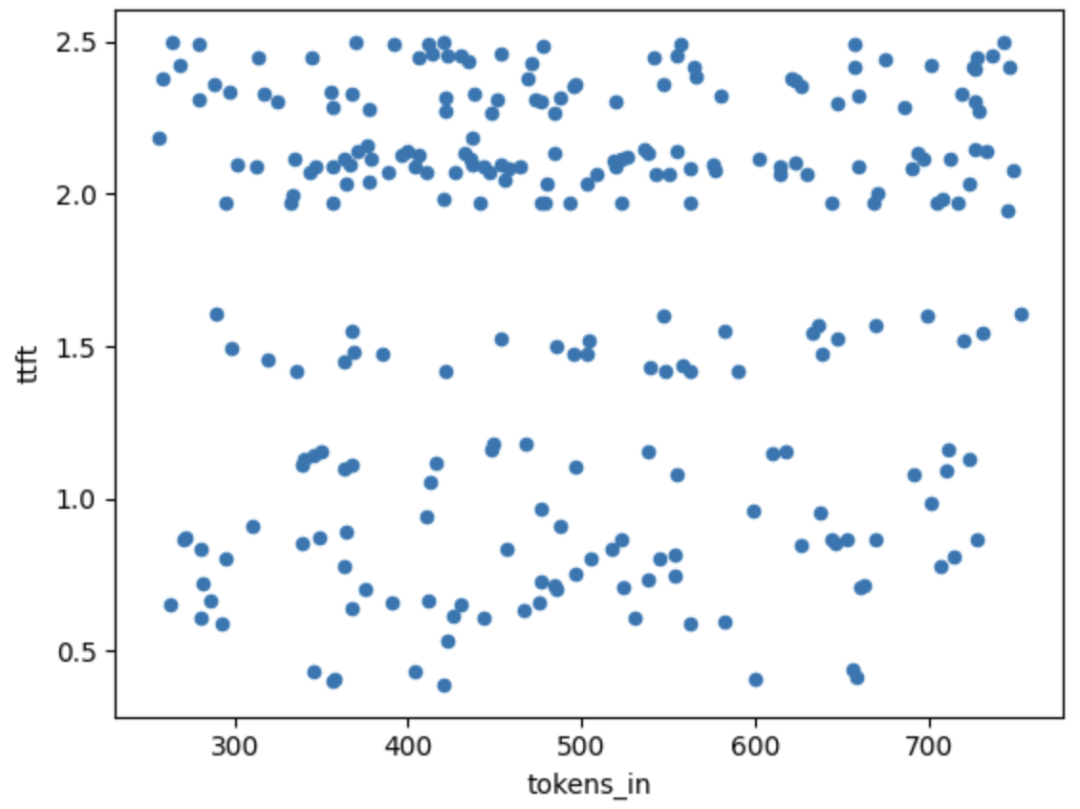
上图显示了在不同的输入大小时,首词元时间(TTFT)的变化。所有这些样本都来自单次运行(5个并发请求)。这些数据点都将取均值,从而得到下面图表中的单个样本点。
可以看到,在250个词元输入和800个词元输入之间,输入词元与TTFT之间似乎并不存在明显的关系,且因其他原因导致的TTFT的随机噪声“掩盖(swamped)”了这一关系。
实际上,我们尝试过使用回归分析来估计这一关系,通过比较550个输入词元和3500个输入词元的输出,并估算梯度,我们发现每增加一个输入词元会增加0.3-0.7毫秒的端到端时间,相比之下,每增加一个输出词元会增加30-60毫秒的端到端时间(适用于Anyscale Endpoints上的Llama 2-70b模型)。因此,输入词元对端到端时延的影响约为输出词元的1%。我们将在未来继续对此进行测量。
总吞吐量(包括输入和生成的词元)
考虑到无法测量预加载时间,并且所花时间更多地取决于生成的词元数量,而不是输入的词元数量,因此,我们认为将注意力集中在输出上是正确的选择。
4
输入选择
运行该基准测试时,我们需要选择用于测试的输入和速率。
有人使用随机词元来生成固定大小的输入,然后在最大词元上使用强制停止(hard stop)来控制输出大小。我们认为这一做法不够理想,原因有以下两点:
-
随机词元并不代表真实数据。因此,某些依赖于真实数据分布的性能优化算法(如投机采样)在随机数据上的表现可能不如真实数据。
-
固定大小并不代表真实数据。这意味着某些算法的优势无法得到体现,比如分页注意力(paged attention)和连续批处理(continuous batching)等,因为它们很大一部分的创新点在于处理输入和输出的大小变化。
因此,我们希望使用“真实(real)”数据。显然,“真实”的定义因具体应用而异,但我们希望至少有一个平均水平的数据作为初始基准。
输入大小
为确定一个“典型”的输入和输出大小,我们查看了Anyscale Endpoints的终端用户数据。基于这一数据,我们选择了以下数值:
-
平均输入长度:550个词元(标准差为150个词元)
-
平均输出长度:150个词元(标准差为20个词元)
为简化问题,我们假设输入和输出都服从正态分布。在未来的工作中,我们将考虑Poisson分布等更具代表性的分布,因为这类分布在建模词元分布方面性质更佳,例如Poisson分布在负值时为0。
在计算词元数量时,我们始终使用Llama 2快速分词器,以一种独立于系统的方式估计词元数量。在过去的研究中,我们注意到ChatGPT的分词器比Llama 2的分词器更“高效”(Llama 2是每词1.5个词元,而ChatGPT是每词1.33个词元)。因此我们认为,ChatGPT不应因为这一点而受到惩罚。
输入内容
为使基准测试更具代表性,我们决定让LLM执行两项任务。
第一项任务是将数字的单词表示转换为数字表示。这实际上是一个“校验和”任务,用于确保LLM的正常运行:我们有很高的概率期望返回的值与我们发送的值相同(根据经验,良好运行的LLM很少出现概率低于97%的情况)。
第二项任务是为了增加输入和输出的灵活性。我们在输入中包含了莎士比亚十四行诗的若干行,并要求LLM在输出中选择若干行。这使我们得到了一个真实的词元和大小分布。我们还可以利用这一任务来“理智地检验”LLM——我们期望输出行在一定程度上类似于我们提供的输入行。
并发请求
一个关键特征是同时发出的请求数量。显然,更多的并发请求会使固定资源集的输出速度变慢。在测试中,我们已经将5作为关键数字进行了标准化。
5
LLMPerf
LLMPerf实现了上述标准。它还进行了参数化(LLMPerf允许改变输入和输出大小以匹配应用程序,这样就可以为自己的工作运行服务供应商的基准测试)。
单个词元的LLM产品基准测试结果
如上所述,我们很难比较按词元计费的LLM产品和按分钟计费的产品,因为后者以时间单位支付产品费用。在这些实验中,我们关注的是已知的按词元计费的产品。因此,我们选择了Anyscale上的llama-2-70b-chat,Fireworks和Perplexity。对于Fireworks,我们使用了Developer PRO账户(将速率限制提高到每分钟100个请求)。
每分钟完成的请求数
我们利用这一方法,通过改变并发请求数,来测算每分钟可以完成的请求,并观察整体时间变化。然后,我们将完成的请求数量除以完成所有请求所需的时间(以分钟为单位)。
需要注意的是,这种方法可能稍显保守,因为我们以“轮次”而不是连续查询的方式完成了并发请求。举例来说,如果我们同时发起了5个请求,其中4个在5秒内完成,另一个在6秒内完成,那么就会有1秒钟的时间并没有完全达到5个并发请求。
结果如图所示。
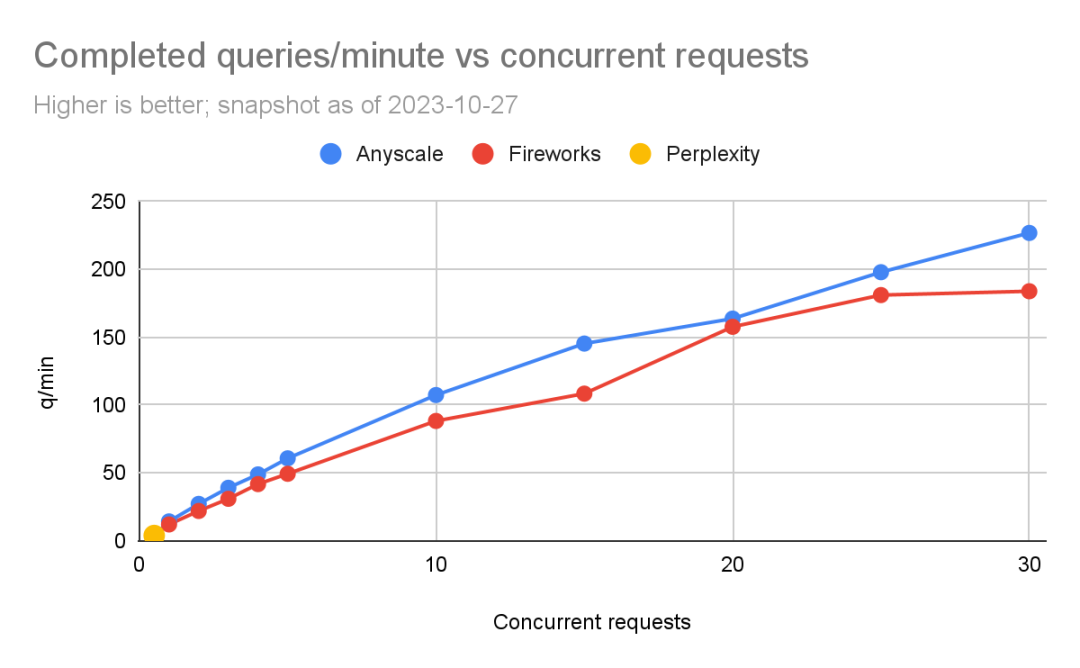
在处理过程中我们遇到了一个问题:即Perplexity的速率限制非常低。因此,我们只能在每轮之间暂停15秒来完成一个“一一对应”的比较。如果暂停时间少于这个值,就会开始从Perplexity那里出现异常。我们将这标记为每秒0.5个并发请求。我们一直运行实验,直到出现异常。
我们可以看到,Fireworks和Anyscale都可以扩展到每分钟完成数百个查询。Anyscale的扩展能力略高一些(最高达到每分钟227个查询,Fireworks最高为每分钟184个查询)。
首词元时间
我们比较了每个产品的TTFT。TTFT对于流媒体应用程序(如聊天机器人)尤为重要。
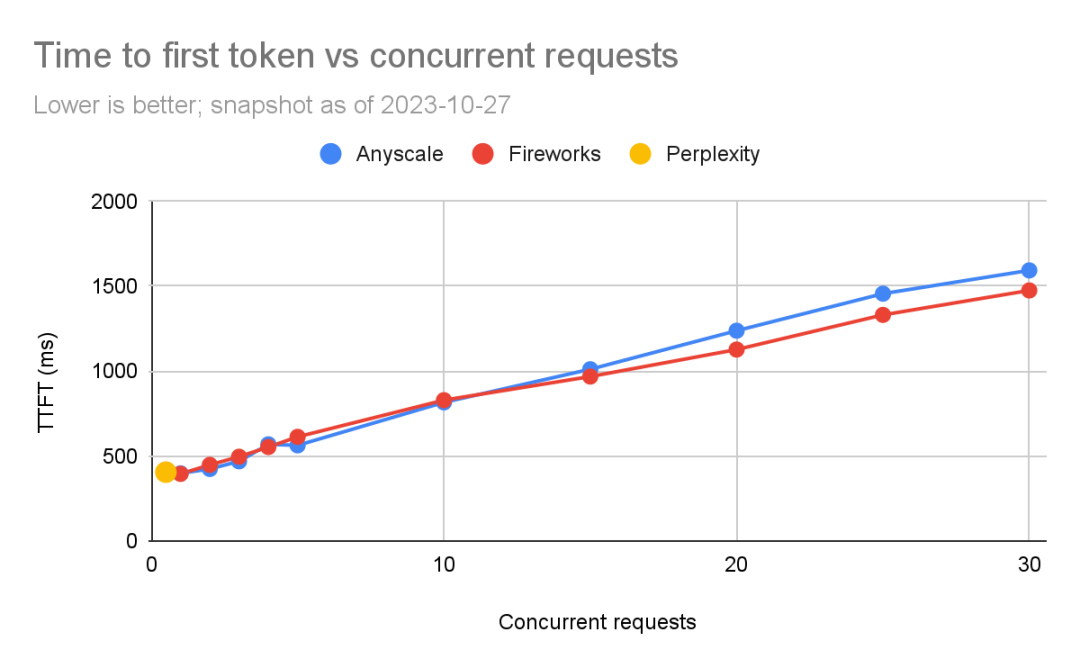
我们再次受到了Perplexity测试速度的限制。最初,在低负载情况下,Anyscale比Fireworks快,但随着并发请求的数量增加,Fireworks似乎略胜一筹。在进行5个并发查询时(这是我们关注的重点),时延差距通常在100毫秒以内(Fireworks为563毫秒,Anyscale为630毫秒)。需要注意的是,TTFT因网络条件存在很大差异(例如,服务部署在附近或远程地区)。
词元间时延
从上图可以看出,尽管两者的差异相对较小(约5%到20%),但Anyscale上的词元间时延始终优于Fireworks。
端到端时间
下图显示了完成查询所需的端到端时间。我们可以看到,就噪声而言,端到端请求时间是更敏感的衡量标准之一。
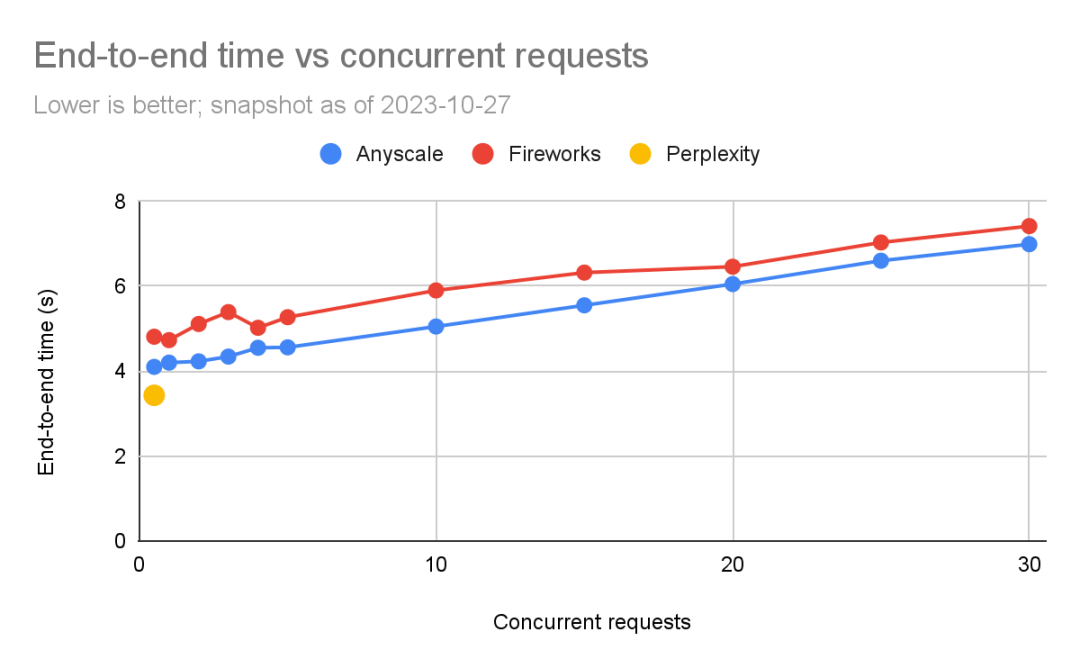
可以看到,Anyscale的端到端时间始终优于Fireworks,但随着负载水平增加,两者之间的差距变小(尤其是比例上的差距)。在运行5个并发查询时,Anyscale为4.6秒,而Fireworks为5.3秒(快15%),但运行30个并发查询时,两者的差距变小了(Anyscale快5%)。
每千次请求的成本
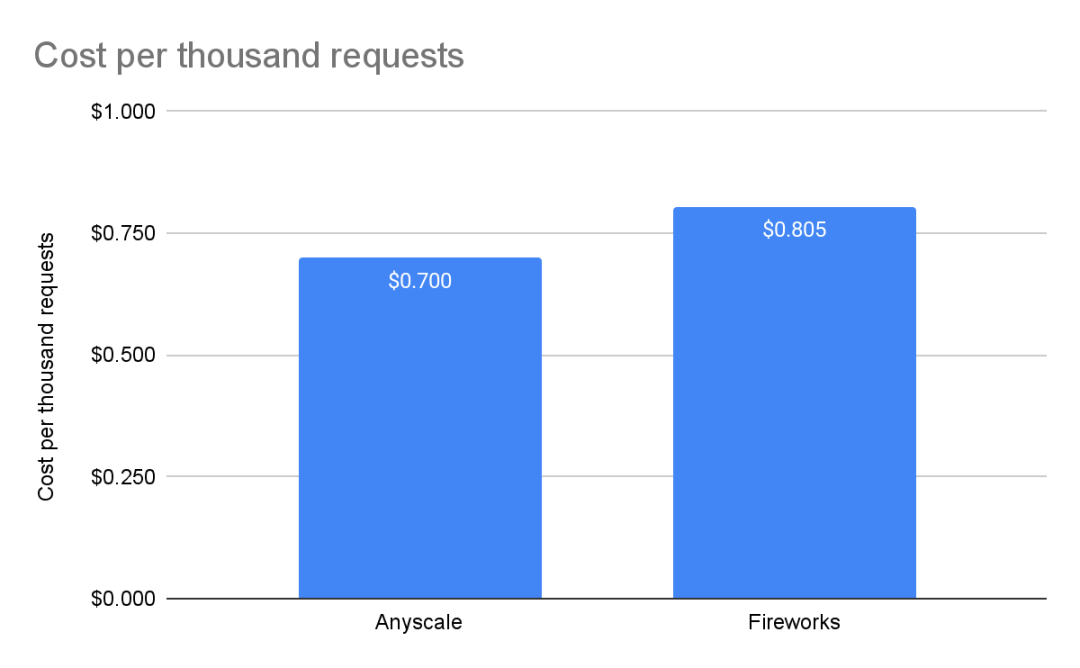
Perplexity目前处于公开测试阶段,因此没有价格可供比较。对于Fireworks,我们使用了其网站上列出的价格,即每百万输入词元收费0.7美元,每百万输出词元收费2.80美元。对于Anyscale Endpoints,根据其定价页所示,无论是输入还是输出,都是每百万个词元1美元。
6
结果分析
利用上述数据,我们可以计算出何时使用何种LLM产品:
-
对于低流量的交互式应用(比如聊天机器人),这三种方案都可行。ITL和TTFT都足够小,不会成为主要问题,因为人类每秒大约阅读5个词元,即便方案中最慢的速度也是人类的6倍之多,所以它们之间没有显著的差异。然而,在这种工作负载下,Anyscale是这三种方案中最便宜的,大约便宜15%。
-
如果你需要端到端的超低时延应用,且工作负载不是很大,那么一旦Perplexity推出公测版本,就值得考虑。然而,在Perplexity公布价格之前,很难知道这种低时延的“成本”是多少。
-
如果有大量工作负载,则可以考虑Anyscale和Fireworks。然而,对于特定的工作负载,Anyscale比其他服务便宜大约15%。同时,如果你的输入和输出比例很高,例如10个输入词元对应1个输出词元,那么Fireworks会更便宜(Fireworks为89美分,Anyscale为1美元),极端的文本摘要就属于这种情况。
7
总结
LLM的性能正飞速优化。我们希望LLMPerf这一基准测试工具能够帮助社区比较输出结果。我们将继续努力,改进LLMPerf(特别是使其更易于控制输入和输出的分布),以期提升透明度和可复现性。同时,我们也希望用户能够利用LLMPerf来对特定工作负载的成本和性能建模。
从这一点可以看出,LLMPerf基准测试并不适用于所有情况,尤其是在涉及LLM时,结果的适用性取决于特定的应用。
其他人都在看
试用OneFlow: github.com/Oneflow-Inc/oneflow/![]() http://github.com/Oneflow-Inc/oneflow/
http://github.com/Oneflow-Inc/oneflow/