Datawhale干货
大模型:Gemini、编辑:量子位
传闻中的谷歌杀手锏Gemini,来了!
就在刚刚,谷歌CEO皮猜和哈萨比斯在谷歌官网联名发文,宣布推出这一万众瞩目的多模态大模型。

标题明晃晃写着“最大”、“最强”,主打的就是一个干爆GPT-4。
具体来说,此次谷歌一共带来了Gemini的三个版本:
Gemini Ultra:谷歌最大、最强模型,适用于高度复杂的任务
Gemini Pro:可扩展至各种任务的Gemini模型
Gemini Nano:适用于端侧设备的高效Gemini版本(1.8B/3.25B)
其中Gemini Ultra一上来就在32个基准测试中拿下30个SOTA,并且第一个在MMLU基准上达到人类专家水平。
而Gemini Pro从今天起,就会在Bard中实装上线。

同时,谷歌Gemini团队还公布了一份60页的详细技术报告。

消息一出,社交媒体瞬间炸了锅。
英伟达AI科学家Jim Fan就第一时间转发评论:
这是OpenAI王座的有力竞争者。
话不多说,一起来看更多细节。
谷歌史上最强大模型Gemini
在LLM中的表现,也正如我们刚才所述,32个基准测试中拿下30个SOTA。
其中,通用、推理、数学和编程等大方向的成绩如下表所示:
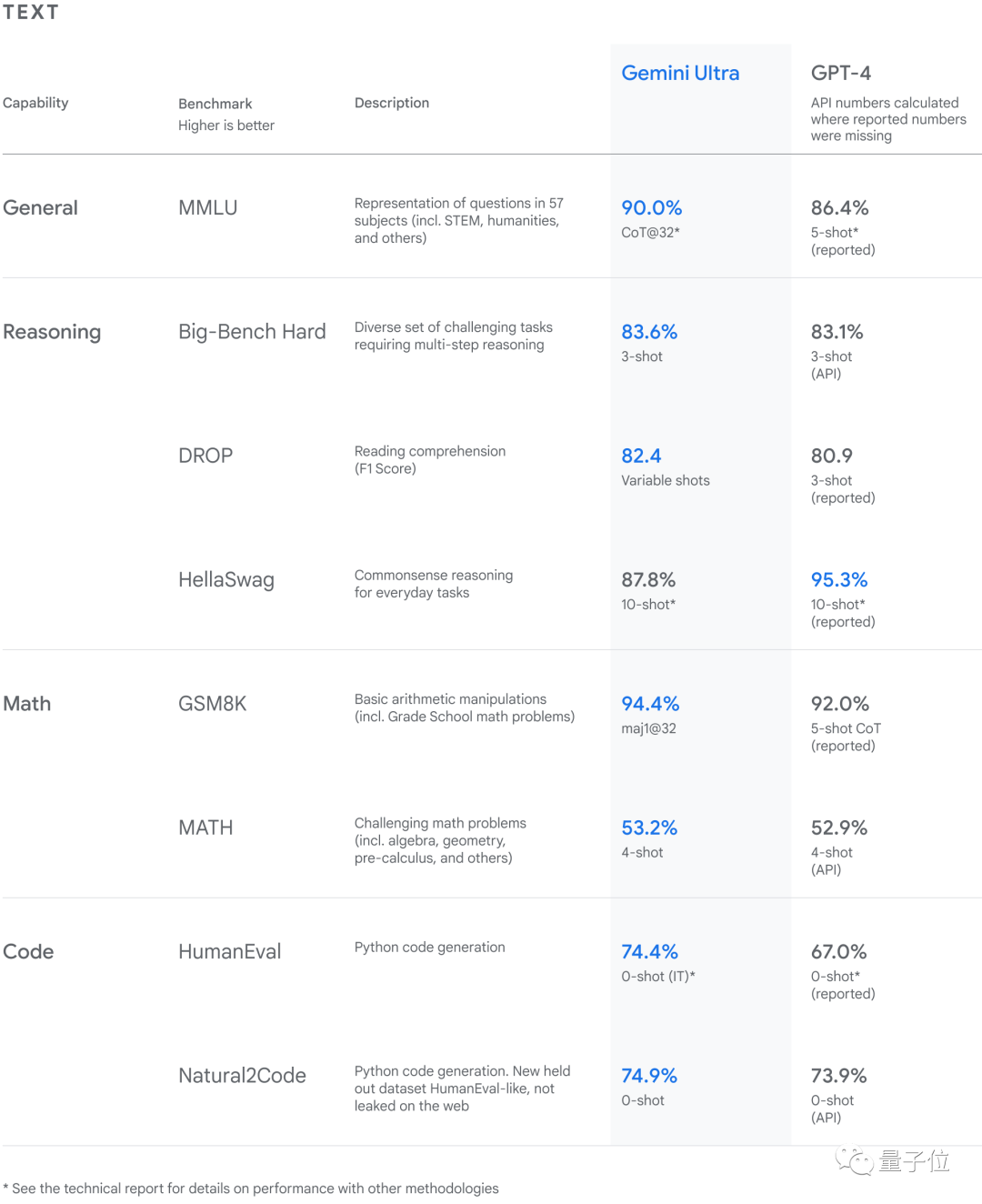
△Gemini 在包括文本和编码在内的一系列基准测试中达到SOTA
在多模态方面,Gemini Ultra在新的MMMU基准测试中也获得了59.4%的SOTA分数。
这项基准测试是由跨不同领域的多模式任务组成,需要大模型进行一个深思熟虑的推理过程。
根据谷歌给出的图像基准测试结果来看,Gemini Ultra在没有OCR系统的帮助下,表现优于之前最先进的模型。
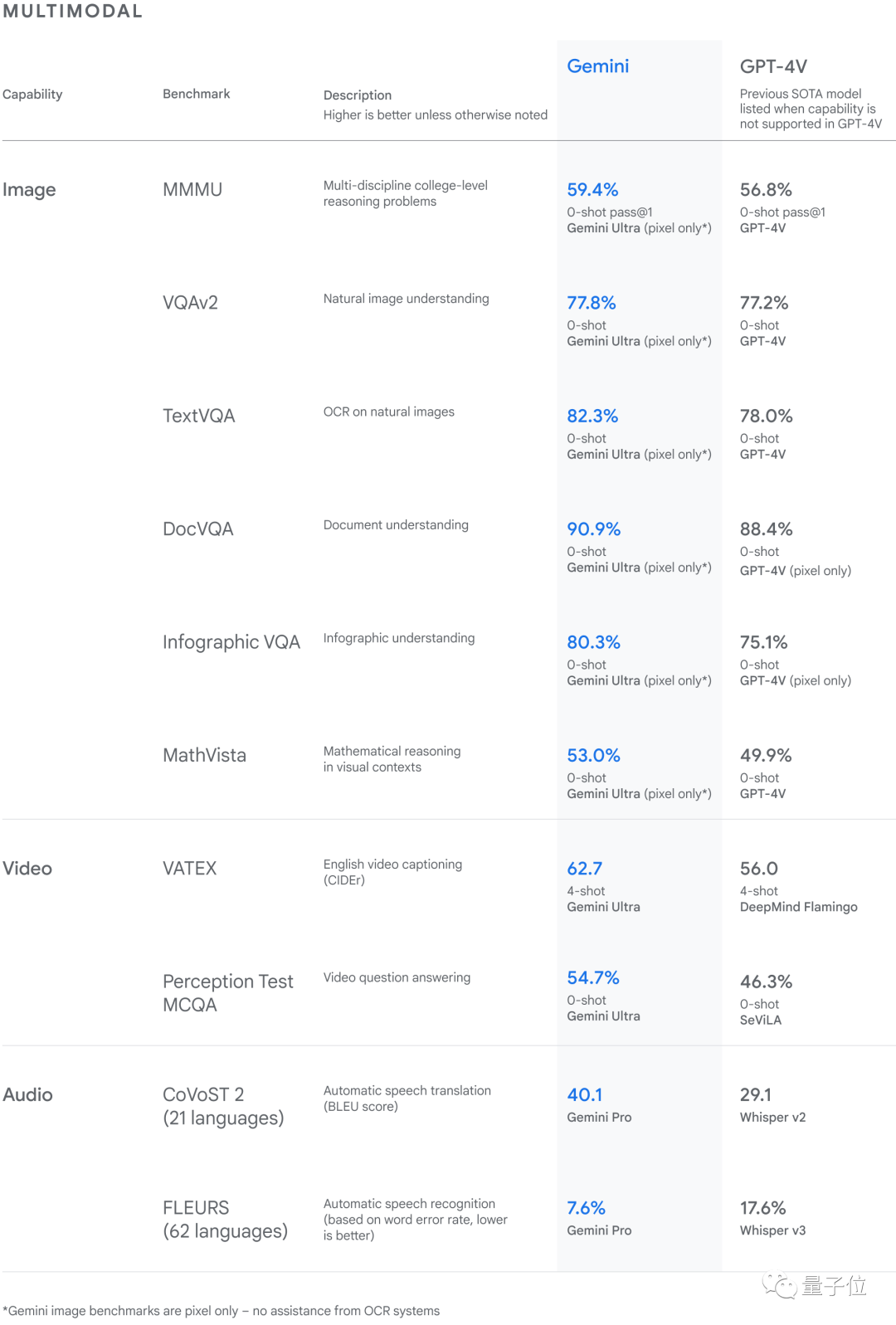
△Gemini 在一系列多模态基准测试中达到SOTA
接下来,我们以具体的案例来看一下Gemini的能力。
例如科学家们经常要面对从成千上万的文献中提取数据的难题,像下面这篇研究,作者就通过手动的方法从上万篇遗传学论文中创建了数据集。

像这样的数据集是需得随着时间流逝而进行更新的,但现实的情况是,自2021年以来,这个领域便已有超过200000篇新增的论文……
再像以往手动的方式显然是不可行的,不过现在有了Gemini,一切就变得简单了起来。
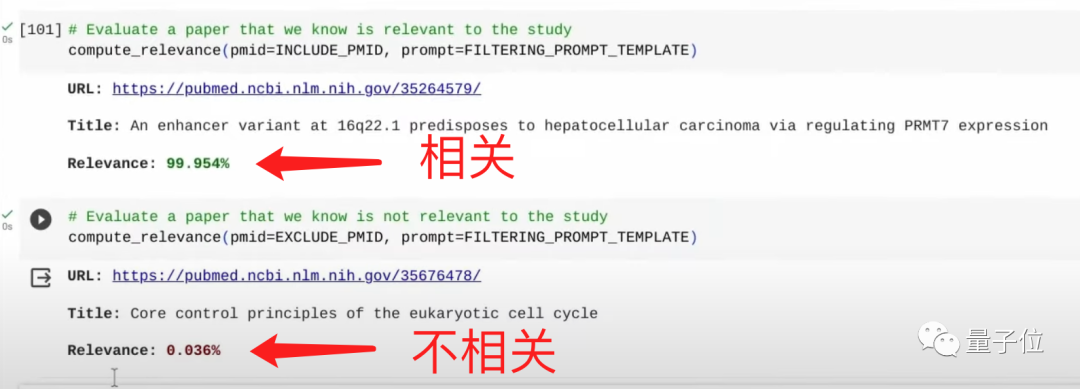
首先,通过自然语言的Prompt,告诉Gemini去过滤相关的科学论文:
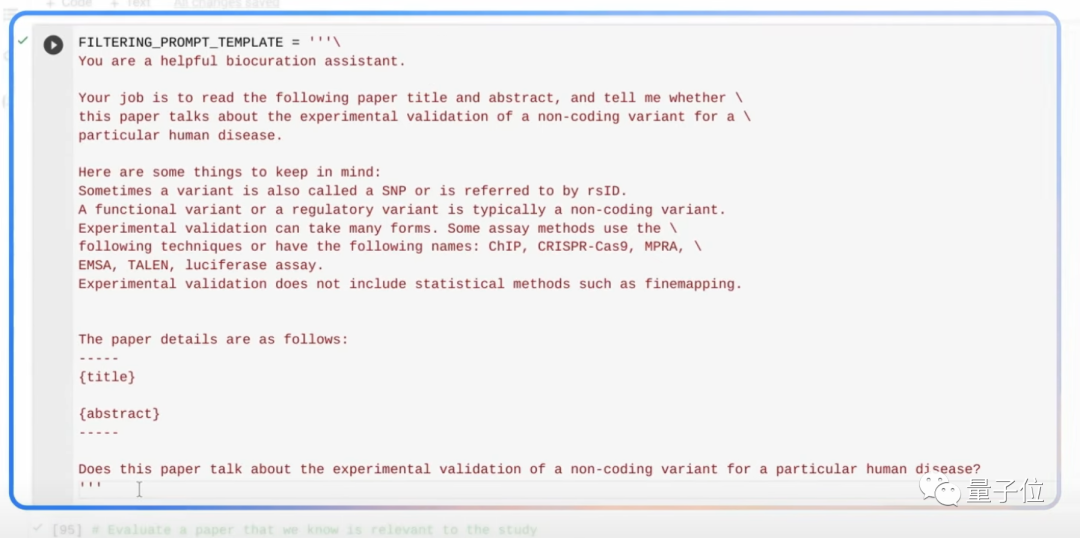
只需片刻时间,Gemini就能找到相关论文和非相关的论文。
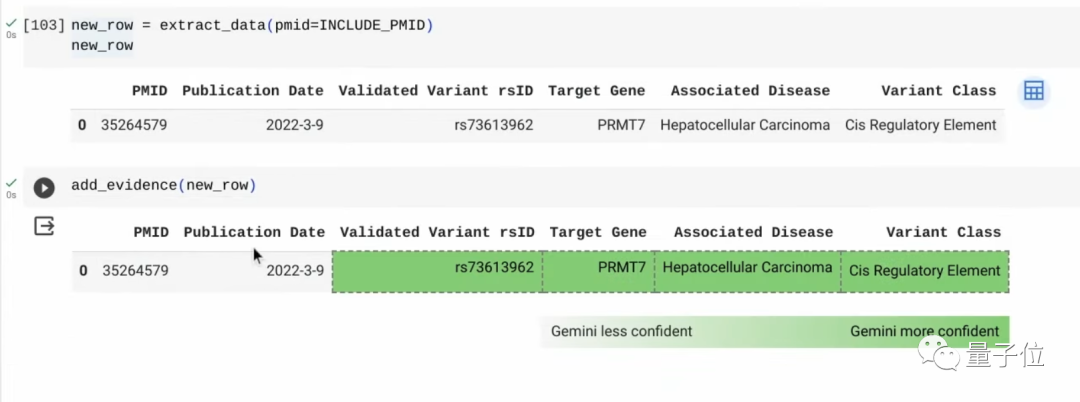
而后,继续用Prompt告诉Gemini去阅读相关论文,并提取关键数据,甚至是可以要求它添加注释的那种。
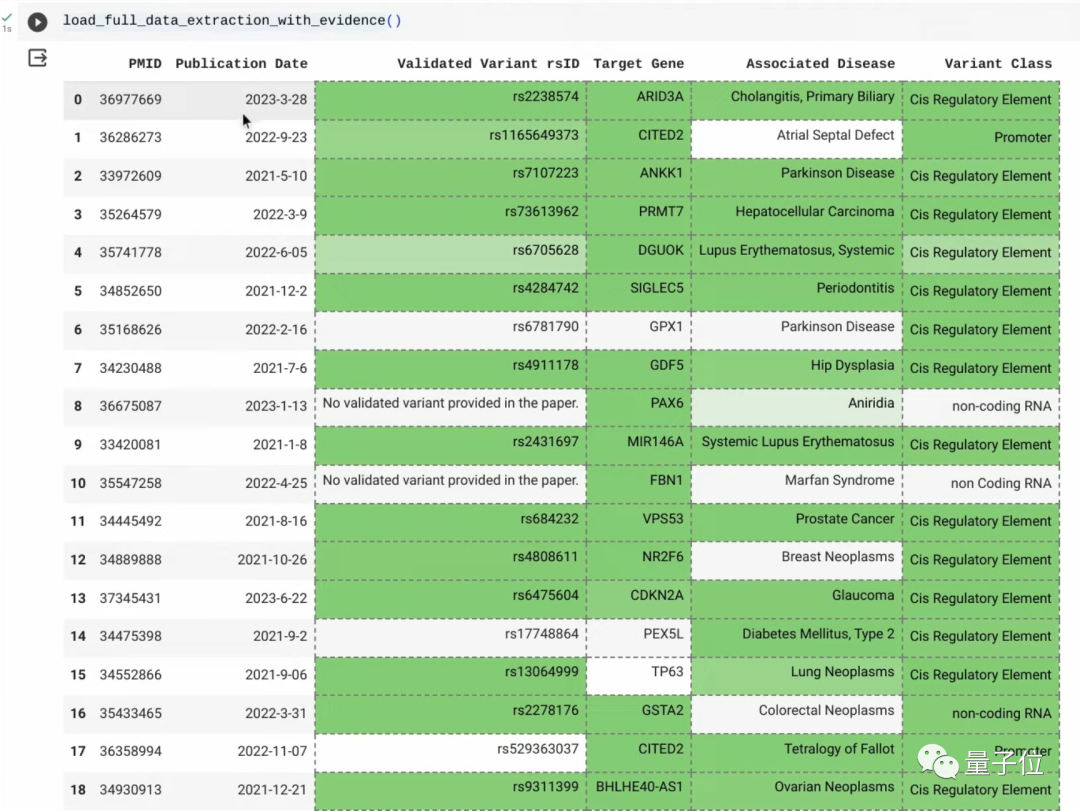
如果你给Gemini一个午休的时间长度,它就能阅读200000篇论文,从中筛选出250篇并提取数据!
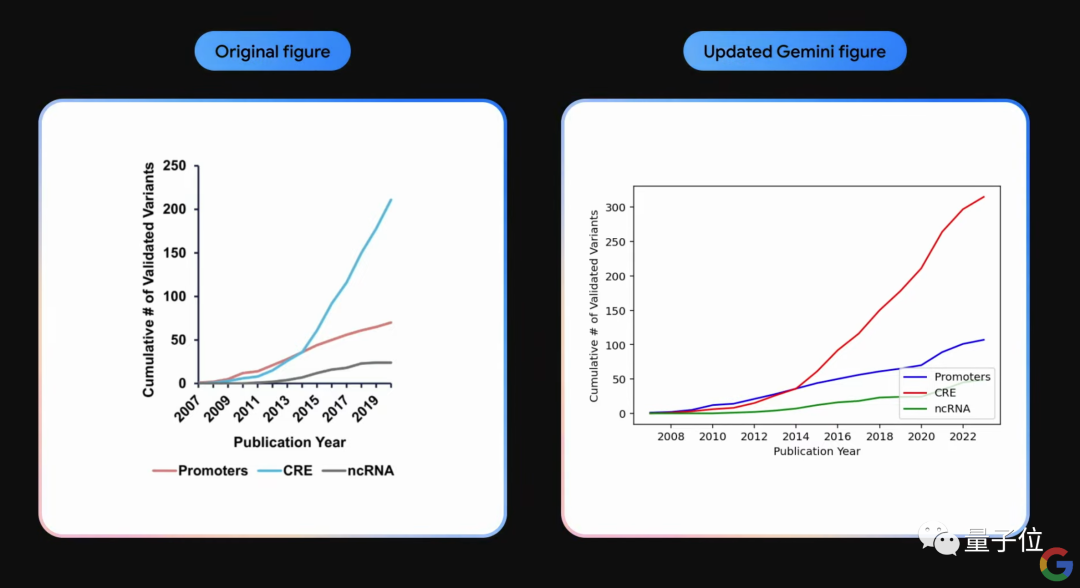
并且由于Gemini是多模态的,我们还可以让它对上面的数据表格做进一步的深入操作,例如更新图表:
对于学生党来说,Gemini现在也可以成为非常得力的学习助手。
例如“喂”给Gemini一张手写物理题,它不仅能看懂,而且还可以辨别手写答案的对错。
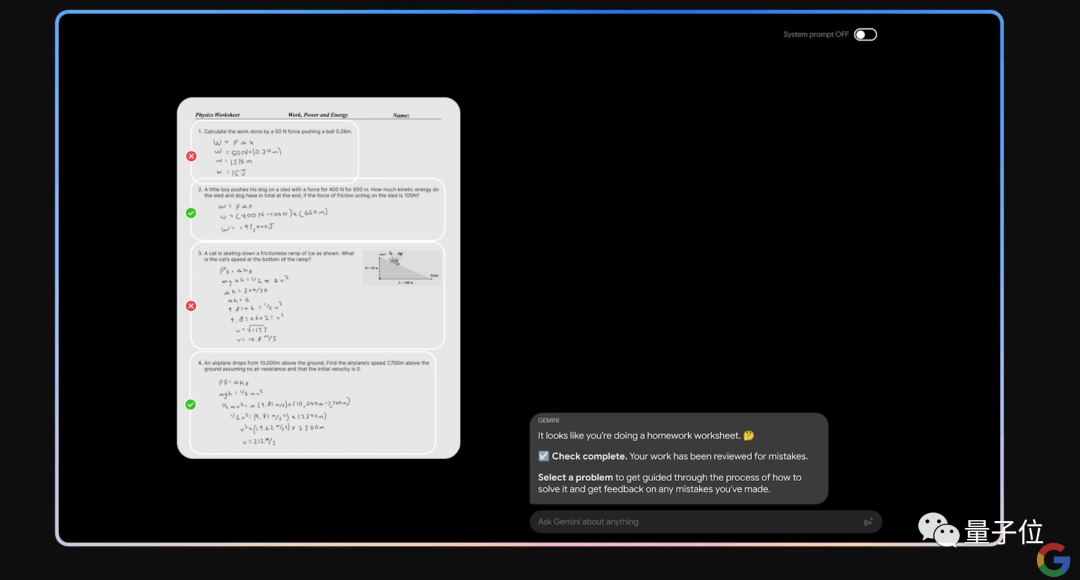
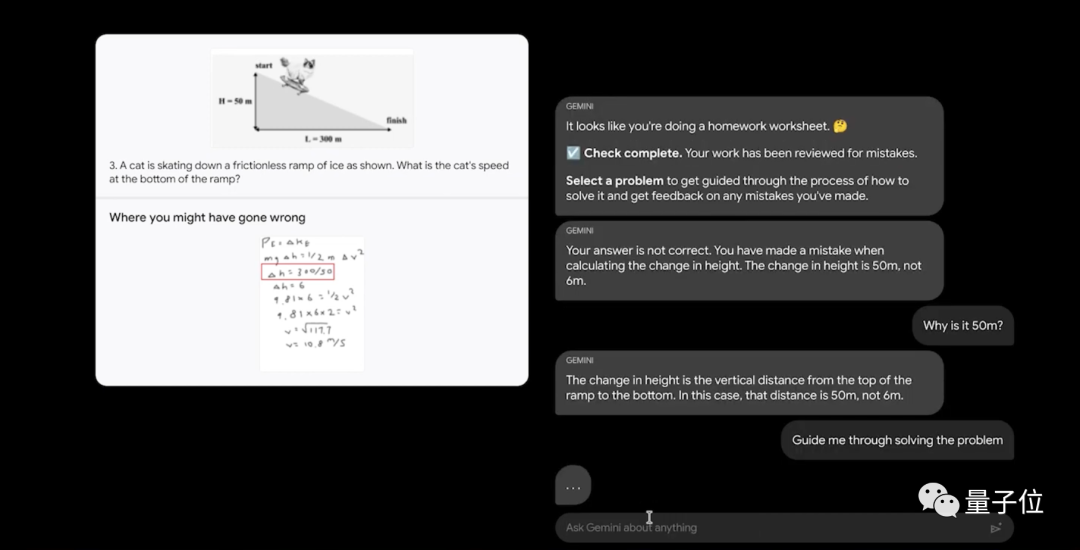
在此基础上,若是选择一个错误的题目,我们还可以跟Gemini通过自然语言沟通,让它对每一个细节步骤进行详解。
在看图像做理解和推理方面,谷歌还亮出了更多有意思的案例。
例如替换图片素材的组合方式,Gemini就能像人一样精准猜中所指的电影名字:
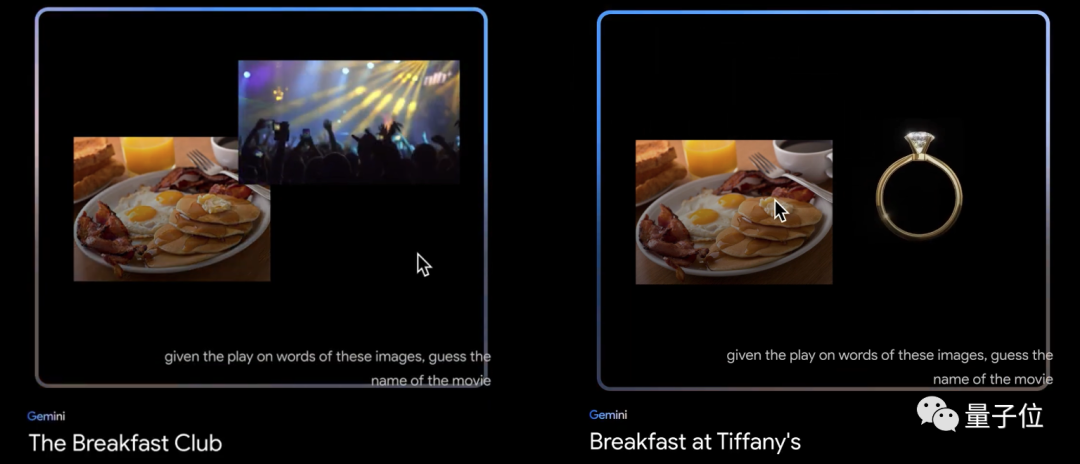
就连下面这种高难度的也能hold住:

再如寻找两张图片的相似之处:

更有意思的是,谷歌还特意用中文做了个demo,来展示Gemini对多张图片的组合理解能力:

那么接下来的问题就是:Gemini是如何做到的?
60页报告透露技术细节
谷歌Gemini背后技术的杀手锏,便是原生多模态(natively multimodal)。
因为以往创建多模态大模型的方法,通常是为不同的模态训练单独的组件,然后将它们拼接在一起,大致模拟其中的一些功能。
这样训练出来的模型虽然有时可以很好地执行某些任务(比如描述图像),但在面对更具概念性和复杂推理的情况下,就会出现表现不佳的结果。
而谷歌Gemini所强调的原生多模态,是指从一开始就对不同的模态进行预训练,然后用额外的多模态数据对其进行微调,以此来进一步完善大模型的有效性。
谷歌对此表示:
这样的训练方法,有助于Gemini从头开始无缝地理解和推理各种输入,远远优于现有的多模态模型;而且它的功能在几乎每个领域都是最先进的。
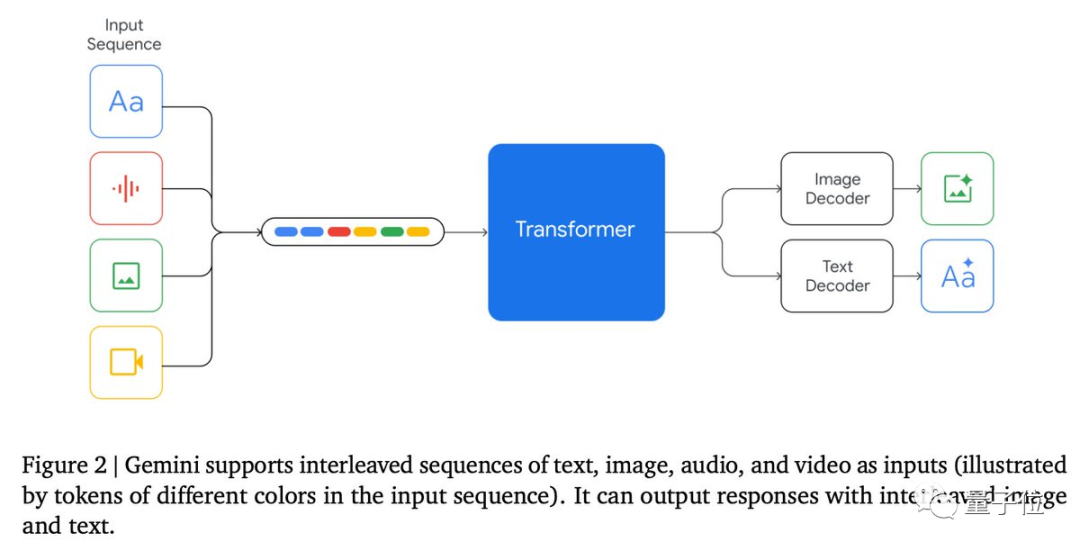
具体到模型架构方面,Gemini基于增强的Transformer decoder打造,采用了高效attention机制(如multi-query attention),支持32k上下文长度。

尽管没有透露Ultra和Pro版本的具体参数规模,但技术报告中提到,谷歌使用TPUv5e和TPUv4来训练Gemini。
训练Gemini Ultra使用了跨多个数据中心的大量TPUv4。这意味着与谷歌此前的主力大模型PaLM-2相比,Gemini在规模上显著增大。
此前,PaLM-2被曝参数规模为3400亿。
Gemini Pro实装上线
竞争对手那边,OpenAI的GPTs惊艳全世界,微软的Copilot更是先一步渗透进全线产品。
因此Gemini一出,谷歌也当即强调:Gemini将通过谷歌产品推向数十亿用户。
率先上线的是Gemini Pro。从今天起,谷歌的聊天机器人Bard将由Gemini Pro微调版本驱动。谷歌表示:
这是Bard自推出以来的最大升级。
谷歌还打算把Gemini引入手机:Pixel 8 Pro将是第一款运行Gemini Nano的智能手机。

另外,谷歌计划在接下来几个月中,将Gemini全面推向搜索、广告、Chrome和Duet AI等产品线。
根据官方数据,Gemini能使用户的搜索生成体验(SGE)速度更快、质量更高,比如在美国使用英语搜索延迟能减少40%。
值得关注还有,就在Gemini正式亮相的同时,谷歌还推出了专为大模型而设计的新一代TPU——Cloud TPU v5p。

那么,你觉得这一波,谷歌能赶上OpenAI的脚步吗?
参考链接:
[1]https://blog.google/technology/ai/google-gemini-ai
[2]https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
[3]https://youtu.be/jV1vkHv4zq8?si=jjAw0uV0dkpP3eVT

最新技术,点赞在看↓