1.从库I/O线程处于Connecting状态
从库的I/O线程处于Connection连接中的状态,一般都是连接不上主库导致:
- 可能由于网络不通,防火墙的干扰导致从库连不上主库,此时就会处于Connecting状态。
- 主库地址写错了,地址压根不是主库的地址。
- 复制用户不存在,导致从库无法通过复制用户连接主库。
- 主库的连接数上限,导致从库无法连接主库。
产生Connecting状态大多数情况下,都是复制用户不存在,或者密码不对,导致连不上主库,可以在从库服务器中使用mysql命令登录复制用户,观察是否能到登录成功,如果登录不上,就表示是复制用户的问题,导致I/O线程处于Connecting状态。
2.从库I/O线程处于No状态
从库的I/O线程处于No状态,可能是以下原因导致:
- 配置从库复制主库的参数时,指定的主库Binlog日志在不对,指定的Binlog在主库中并不存在,就会导致I/O线程处于No状态。
- 配置从库复制主库的参数时,指定的主库Binlog日志标识位号不对,也会导致I/O线程处于No状态。
- 主库的日志损坏,从库无法从指定的Binlog日志进行数据同步,例如主库突然执行了reset matser,导致主库的Binlog全部清空,而从库正在复制主库的某个Binlog,此时从库就无法在主库中找到这个Binlog,就会导致I/O线程处于No状态。
- Server_id如果重复也会导致I/O线程处于No状态。
下面模拟主库Binlog日志损坏,从库无法请求指定的Binlog,从而导致I/O线程处于No故障状态以及恢复处理过程。+
1)主库破坏Binlog日志
1.多刷新几次产生新的Binlog
mysql> flush logs;
mysql> flush logs;
mysql> flush logs;
当主库刷新Binlog日志后,从库也会跟着请求到最新的Binlog日志。
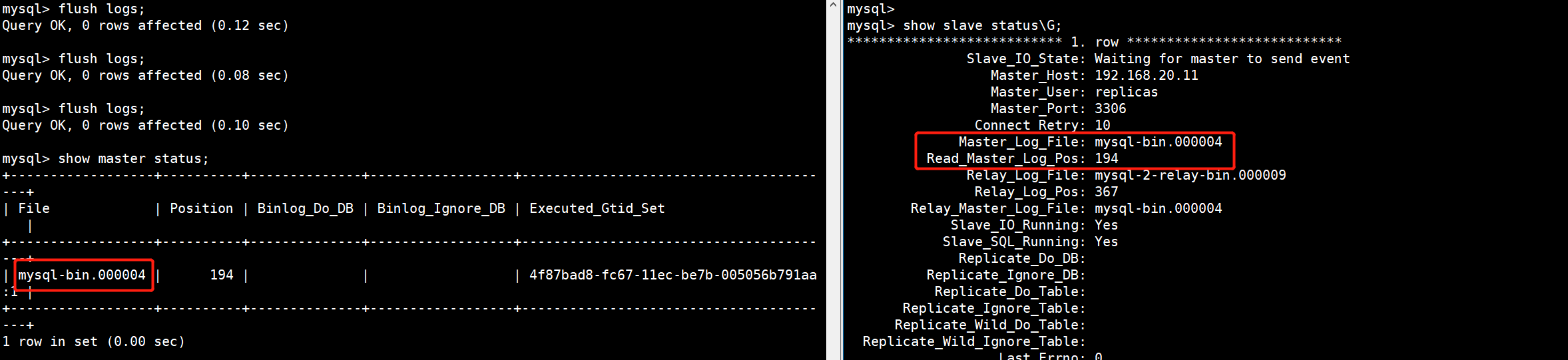
2.主库破坏Binlog
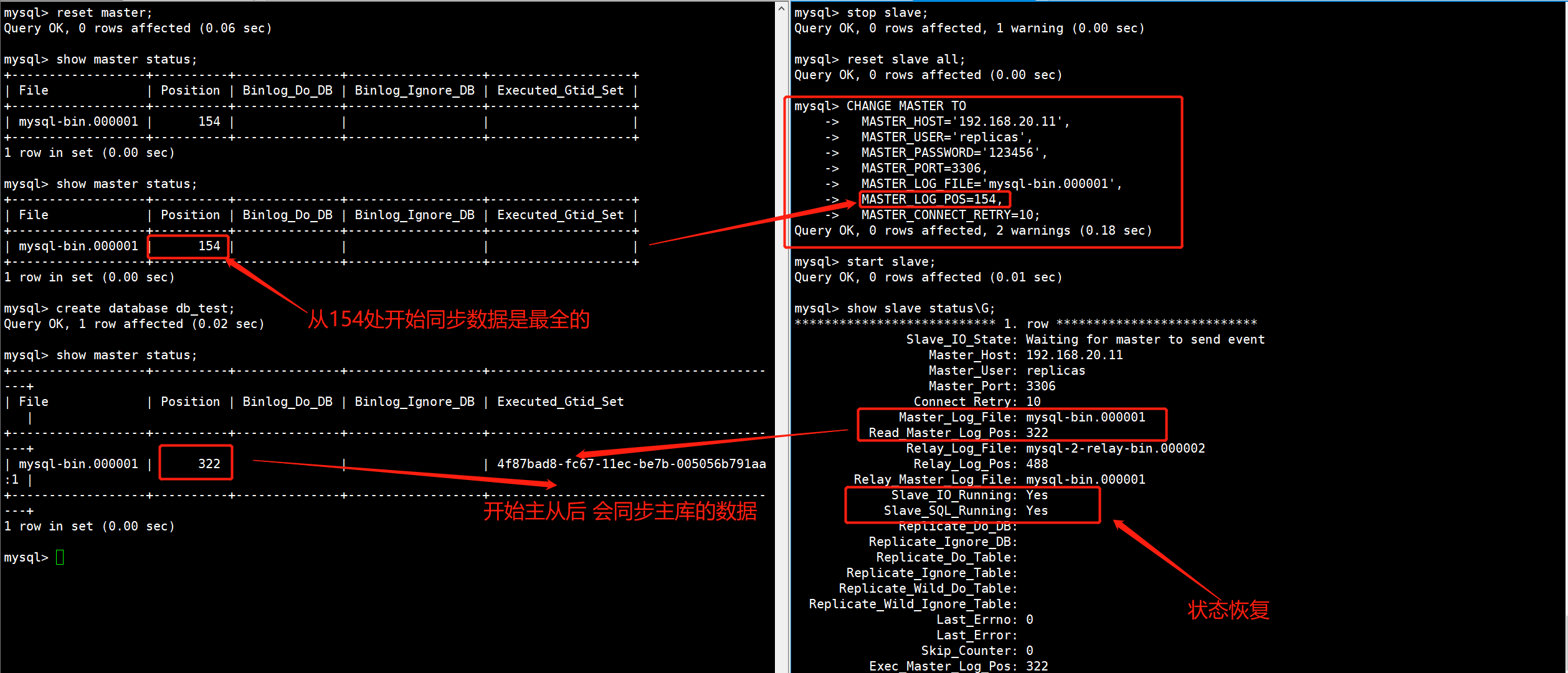
mysql> reset master;
2)从库的I/O线程处于No状态
从库的状态I/O线程立马变成No状态,从库要请求00004Binlog日志,但是主库的只有00001Binlog日志,没有从库要找的00004Binlog日志,此时就会处于No状态。

并且会报错说从库要请求mysql-bin.000004二进制日志,但是主库只有mysql-bin.000001二进制日志,没有从库要请求的日志,因此I/O会报错。
Got fatal error 1236 from master when reading data from binary log: 'could not find next log; the first event 'mysql-bin.000001' at 452, the last event read from './mysql-bin.000004' at 194, the last byte read from './mysql-bin.000004' at 194.'
3)此时主库又产生了新的操作
此时主库又发生了新的操作,创建了一个db_test库,而从库现在没法复制这些数据。
mysql> create database db_test;
4)处理方法
I/O状态目前处于No的状态,我们已经知道原因了,就是从库要请求主库的Binlog日志不对,我们调整一下请求的Binlog日志,然后指定Binlog标识位号为从库I/O线程故障时的标识位号,保证主从的数据同步。
mysql> stop slave;
mysql> reset slave all;
mysql> CHANGE MASTER TO
MASTER_HOST='192.168.20.11',
MASTER_USER='replicas',
MASTER_PASSWORD='123456',
MASTER_PORT=3306,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=154,
MASTER_CONNECT_RETRY=10;
mysql> start slave;
主库重新生成了新的Binlog日志,并且也产生了数据,我们不好确定从库故障时,主库的Binlog位置号,因此我们直接从154号开始同步,一定是最全的数据,重新配置主从同步信息,Binlog指对之后,从库的I/O状态正常。
3.从库SQL线程处于No状态
SQL线程主要是读取relay-log.info获取relay-log的位置号,然后执行relay-log中主库推送来的Binlog日志,然后再更新relay-log.info文件。
当SQL线程状态为No,主库发送来的Binlog日志,从库无法执行,从而导致数据不同步。
导致SQL线程处于No状态的原因:
- relay-log.info、rela-log文件损坏,就会导致SQL线程处于No状态,解决办法最好是重新构建主从。
- 如果主库发送来的Binlog日志在从库执行失败,就会导致SQL线程处于No状态,主库发送来的Binlog日志为什么会执行失败?
- 如果数据库版本差异较大,不建议配置成主从集群,很有可能主库发来的Binlog日志,在从库中不能执行,导致SQL线程异常。
- 主库和从库的配置参数不一致,也会导致SQL不能执行。
- 当主库要创建的表或者数据库,已经在从库中存在了,就会导致Binlog中创建对象的语句报错,从而使SQL线程出现故障,为什么主库要创建的对象在从库中存在了呢?很有可能有人误操作,连接上了主库,在主库中执行了创建对象的语句,建议将从库设置成只读模式,防止使用从库写入数据。
- 当主库要删除或者修改表、数据库时,这些对象在从库不存在,也会导致SQL执行失败,原因也看是误操作连上了从库进行了这些对象的处理。
如果真的有人在从库中写入了数据,SQL线程故障了,状态为No,并且写入的数据是无关紧要的,可以通过以下命令,跳过失败的SQL,使SQL线程恢复正常。
stop slave;
set global sql_slave_skip_counter = 1;
也可以修改配置文件,将可能在从库误操作导致SQL无法执行的几种错误号,配置在配置文件中,全部跳过,但是不合理。
vim /etc/my.cnf
slave-skip-errors = 1032,1062,1007
最合理的避免人员在从库误写入数据的方法,就是给从库设置为只读模式,或者配置读写分离,通过中间件,将写的操作写入到主库,读的操作写入到从库。