

mapConcurrent操作符的实现。

Java Stream 自从 Java 1.8 引入以来,迅速成为了各位开发者手中信手拈来的工具,大家日常在工作中谈论起来也是如数家珍。但由于 Java Stream 的操作符不足够的丰富,经常会遇到捉襟见肘的情况。对于此,大家可能会继而采用操作符更加丰富的库来作为替代。作为 Java 标准库的一部分,Oracle 的 Java 架构师们也一直以来都在探索如何更好的适应日益增长的用户需求和语言的可维护性,随着 Stream Gather API 的到来,这个情况得到了极大的改善,下面让我结合自身经验,和大家分享 Java Stream Gather API。

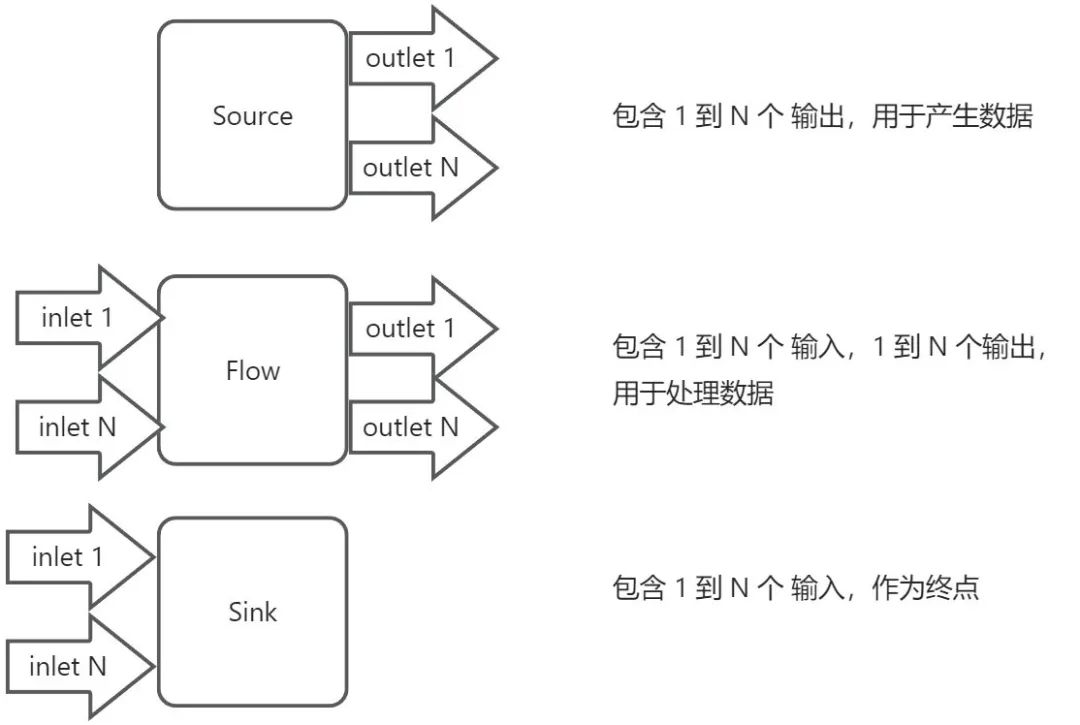
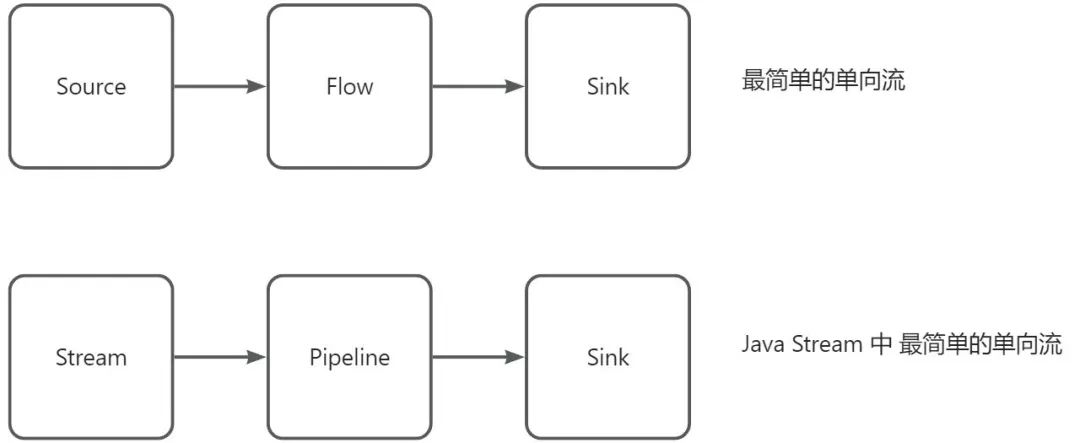
现在我们应该对什么 是 “流”有了一个清晰的认识了。通常我们如果不需要自己开发 Java Stream 的操作符,因此几乎接触不到 AbstractPipeline和 Sink这两个类,当然截止 Java 22, Java Stream 也没有足够的扩展点。

各种库有什么不一样
在目前日常工作中,作为 Java 开发者,我们可能会用到多种面向 “流”的工具包,简单对比如下:
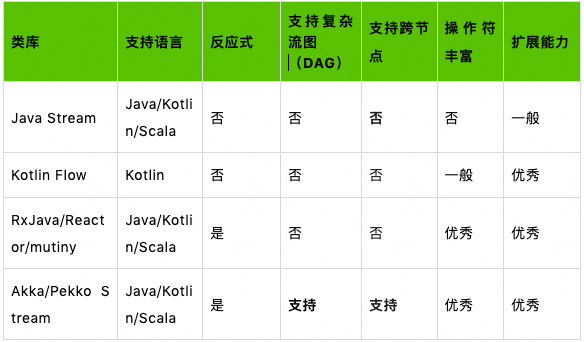
题外话:Viktor Klang 之前是 Akka 的开发团队的一员。

▐ 问题空间
-
支持多种类型的数据转换: 1 :1, 如 map 操作符 1 :N, 如 filter ,flatmap N :1, 如 buffer N:M, 如 intersperse -
支持 “有限流” 和 “无限流” -
支持 “有状态” 和 “无状态”操作 -
支持“提前终止”和 “全量消费” -
支持 “单线程顺序处理”和 “多线程并行处理” -
支持感知 “结束”,如实现一个 fold 操作符
▐ Stream Collector & Gather
Collector <T, A, R>
, 其包含下面几个部分:
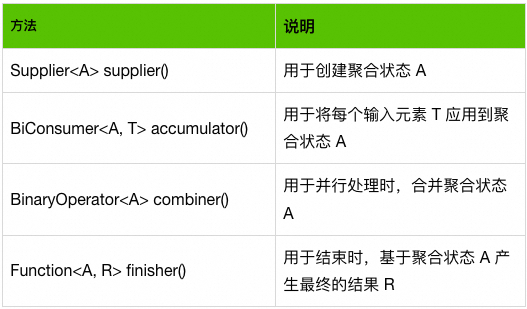
基于上面的说明,在处理过程中我们只会用到 accumulator 返回的 BiConsumer和 finisher返回的 Function<A, R>, 所以只能最终产生 1个值 (N :1)。比如我们的 Collectors.toList()只会在流结束的时候产生一个 List,所以 并不能满足我们实现 map、filter、buffer、scan 、zipWithIndex等操作符的要求。
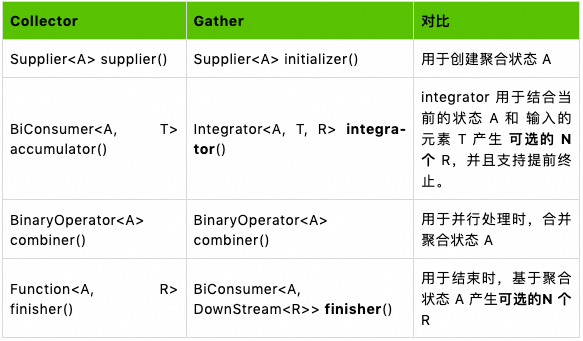
integrator和 finisher都可以产生 1 : N 地产生元素 R。这个可选的 0 ... N个 R 通过 DownStream<R>来传递给下游。如果直接在方法的返回值中返回,则仅可以表达 0 ... 1个 R 的情况。DownStream<R>的定义了两个核心方法,比较类似于 Reactor-core 的 Emitter。
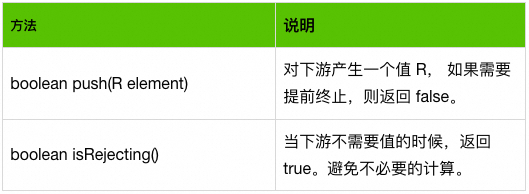
integrator 主要用于结合当前的状态 A 和 输入的元素 T,利用了 DownStream<R>的 能力来产生 可选的 N 个 R。核心的方法如下:

结合目前的信息,我们可以发现整个 Gather API 的设计其实还挺复杂的,因为引入了太多的中间接口名称,同时支持了单线程和多线程等情况,并且有一些隐藏的约束。下面让我们庖丁解牛,细细道来。

分析和对比
▐ Stream Gather API 拆解
结合上面的信息和其他类库中的经验,我们其实知道,“流”的任意中间处理过程都可以看做一个函数, 如下图所示:

Gather
API 其实是在这个基础上做的变体。具体来说:
-
supplier:产生最初的 State -
integrator + downstream:转换 和 传递值;
finisher
主要用于终止信号处理,
combiner
主要用于并行流。这样一看整个API 就简化很多了。在实现特定的 操作符的时候,我们可以只关心特定部分。比如下面分别实现
map
和
filter
操作符(无状态)。
-
map操作符无状态, 1 :1 地产生元素 -
filter操作符无状态, 1 : 0 ... 1 地产生元素
public static <T, R> Gatherer<T, ?, R> map(final Function<T, R> mapper) {return Gatherer.of((notused, element, downstream) -> downstream.push(mapper.apply(element)));}public static <T> Gatherer<T, ?, T> filter(final Predicate<T> predicate) {return Gatherer.of((notused, element, downstream) -> {if (predicate.test(element)) {return downstream.push(element);}return true;});}
▐ 和其他的类库对比
gather最相近是 statefulMap操作符, 该操作符在别的 函数式流 库中一般叫做 mapAccumulate. 具体的定义如下:
def statefulMap[S, T](create: function.Creator[S],f: function.Function2[S, Out, Pair[S, T]],onComplete: function.Function[S, Optional[T]]): javadsl.Flow[In, T, Mat]

用 statefulMap和 gather分别实现 zipWithIndex如下:
public static <T> Source<Pair<T, Integer>, NotUsed> zipWithIndex(final Source<T, NotUsed> source) {return source.statefulMap(() -> 0,(state, element) -> Pair.create(state + 1, Pair.create(element, state)),notused -> Optional.empty());}public static <T> Stream<Pair<T, Integer>> zipWithIndex(final Stream<T> stream) {class State {int index;}return stream.gather(Gatherer.ofSequential(State::new,(state, element, downstream) -> downstream.push(Pair.create(element, state.index++))));}
Gather
API 的设计中, 由
initializer
返回的 状态
A
在整个生命周期中使用,如果我们的操作符是带状态的,那么需要将状态放在一个 可变类 中,如上面实现中的
class State
。这个和函数式的(返回新的不可变状态)的方式不太一样。这样做的一个优势就是避免生产小对象
Pair(State, Ouput)
. 缺点则是会有很多这样的局部类。其他的重要的约束还有:不要将
State
对象传递给多个线程并发修改、传递给
integrator
的
State
需要是
initializer
返回的
State
等。至于并行化的支持这里不再展开,简单来说就是 Java Stream 是通过
combiner
合并聚合状态来完成的。无独有偶,在有个
statefulMapAsync
的PR 中也有类似的思考。
▐ 自带的 gathers 分析
Gather实现,比如 fold、scan、windowFixed和 mapConcurrent, 其中 fold比较简单,也有 Collectors.reduce作为对偶实现。最有有意思的是 mapConcurrent,其可以用于指定最大并行度地执行异步转换,类似于 Pekko-Stream 的 mapAsync。其中需要注意的是,在这个实现中,利用到了 虚拟线程、信号量,并且没有用到
CompletableFuture
。更加简单的实现了相同的功能。
mapConcurrent
public static <T, R> Gatherer<T,?,R> mapConcurrent(final int maxConcurrency, //限制:最大并行度final Function<? super T, ? extends R> mapper) //虚拟线程中执行的转换
整个实现非常的简单:
public static <T, R> Gatherer<T,?,R> mapConcurrent(final int maxConcurrency,final Function<? super T, ? extends R> mapper) {class State {final ArrayDeque<Future<R>> window =new ArrayDeque<>(Math.min(maxConcurrency, 16));//使用信号量,不需要复杂的判断逻辑final Semaphore windowLock = new Semaphore(maxConcurrency);final boolean integrate(T element,Downstream<? super R> downstream) {if (!downstream.isRejecting())createTaskFor(element);return flush(0, downstream);}final void createTaskFor(T element) {//阻塞等待permit,这里不是虚拟线程windowLock.acquireUninterruptibly();var task = new FutureTask<R>(() -> {try {return mapper.apply(element);} finally {//处理完成后释放信号量permitwindowLock.release();}});var wasAddedToWindow = window.add(task);//使用虚拟线程来执行具体的任务Thread.startVirtualThread(task);}final boolean flush(long atLeastN,Downstream<? super R> downstream) {//....省略很多代码,将结果值推送给下一个处理节点downstream.push(current.get());}}return Gatherer.ofSequential(State::new,Integrator.<State, T, R>ofGreedy(State::integrate),(state, downstream) -> state.flush(Long.MAX_VALUE, downstream));}
mapper
, 并结合 信号量来实现
maxConcurrency
的限制。整个实现非常简单,感兴趣的同学可以对比下 Reactor-core 中
flatmap
和 Pekko-Stream 中
mapAsync
的实现。
fold
相比之下,Gather 的 fold 实现就比较简单,如下所示:
public static <T, R> Gatherer<T, ?, R> fold(Supplier<R> initial,BiFunction<? super R, ? super T, ? extends R> folder) {class State {R value = initial.get(); //初始状态,记录聚合结果值State() {}}return Gatherer.ofSequential(State::new,Integrator.ofGreedy((state, element, downstream) -> {state.value = folder.apply(state.value, element);return true;}),//流处理结束,返回结果值给流的下一个处理节点(state, downstream) -> downstream.push(state.value));}
同样将状态保持在了 局部的 State类中,并且在结束时,调用了 finisher返回的方法,将最终的值推送给了流的下一个处理节点。因为是 fold方法不一定满足 结合律,所以上面使用的是 Gatherer.ofSequential, 来保证串行执行。同时,Stream Gather API 也支持多个 gather 之间组合,相当于其他库中的 fuse ,继而提高性能。

zipWithIndex
、
zipWithNext
、
mapConcat
、
throttle
等。稍有遗憾的是由于 Java 目前不支持类似 Kotlin 的扩展方法,所以在 Stream API DSL 的最终呈现上还不能是
Stream.zipWithIndex
而是
Stream.gather(MyGathers.zipWithIndex)
。希望在 下一个LTS来临之前 Java 能够补齐扩展方法这个短板,方便我们更优雅的设计 DSL 扩展。
mapConcurrent
操作符的实现。希望抛砖引玉和大家分享新的特性,共同进步。同时也希望大家都可以升级到新版本的 JDK,更好的赋能业务。

-
在底层技术上,我们具备深厚的Android和iOS底层技术积累,拥有丰富的编译器、链接器、解释器技术应用实践。 -
在研发模式上,我们负责原生研发模式DX演进,服务数千开发者、承载数百亿日PV,深耕系统原生渲染技术,致力于建立下一代终端研发模式。 -
在网络技术上,我们在终端网络、传输和超大规模网关有深厚技术积累,负责开源方案XQUIC/Tengine,承载亿级长连和千万级QPS;在国际IETF标准、顶会SIGCOMM均有建树。 -
在终端技术上,我们打造领先行业的移动技术产品,涵盖多端架构、性能体验、组件框架、用户增长等关键领域,致力于移动端系统及厂商特性前沿探索。 -
在后端技术上,我们负责移动基础设施,有百万级QPS API网关、消息/推送、Serverless平台、自适应流控等柔性高可用解决方案。打造覆盖移动App全生命周期工程技术平台。 -
在跨端技术上,我们负责Weex2.0和核心Web容器,研究领域涉及W3C标准、WebKit内核、脚本引擎和自绘渲染引擎,面向Web标准提供一流跨端能力。通过卡片级小部件和小游戏技术,丰富创意供给,提供差异化的购物体验。 在前端技术上,我们在前端框架、工程、低代码领域长期深耕,支撑大促营销ProCode、LowCode、NoCode跨端页面研发;配套前沿的页面托管;负责ICE、微前端等开源方案,致力于提供简单友好的研发体系。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。