
背景
知识图谱系统的建设需要工程和算法的紧密配合,在工程层面,去年蚂蚁集团联合OpenKG开放知识图谱社区,共同发布了工业级知识图谱语义标准OpenSPG并开源;算法层面,蚂蚁从知识融合,知识推理,图谱应用等维度不断推进。
OpenSPG GitHub,欢迎大家Star关注~:https://github.com/OpenSPG/openspg
本文将梳理知识图谱常用的推理算法,并讨论各个算法之间的差异、联系、应用范围和优缺点,为建设知识图谱的图谱计算和推理能力理清思路,为希望了解或者工作中需要用到知识图谱推理算法的同学提供概述和引导。
在知识图谱推理算法综述(上):基于距离和图传播的模型,我们了解到“基于距离的翻译模型”,“基于图传播的模型”的详细知识图谱算法梳理。本文为下篇,重点从基于语义的匹配模型:张量分解模型与神经网络类型进行介绍。
知识图谱算法汇总
本章将对常用的图谱推理算法做一个概括的梳理。业界算法很多,一篇文章难以做到全面覆盖,因此我们这里挑选了与图谱推理强相关的算法进行讲解,部分类似的算法挑选了其典型代表进行讨论,算法能力范围尽量覆盖:
-
知识融合,包括:实体对齐、属性融合、关系发掘、相似性属性补全;
-
知识推理,包括:链接预测、属性值预测、事件分析、连通性分析、相似性分析。
首先,通过一张思维导图对这些图推理算法进行汇总:
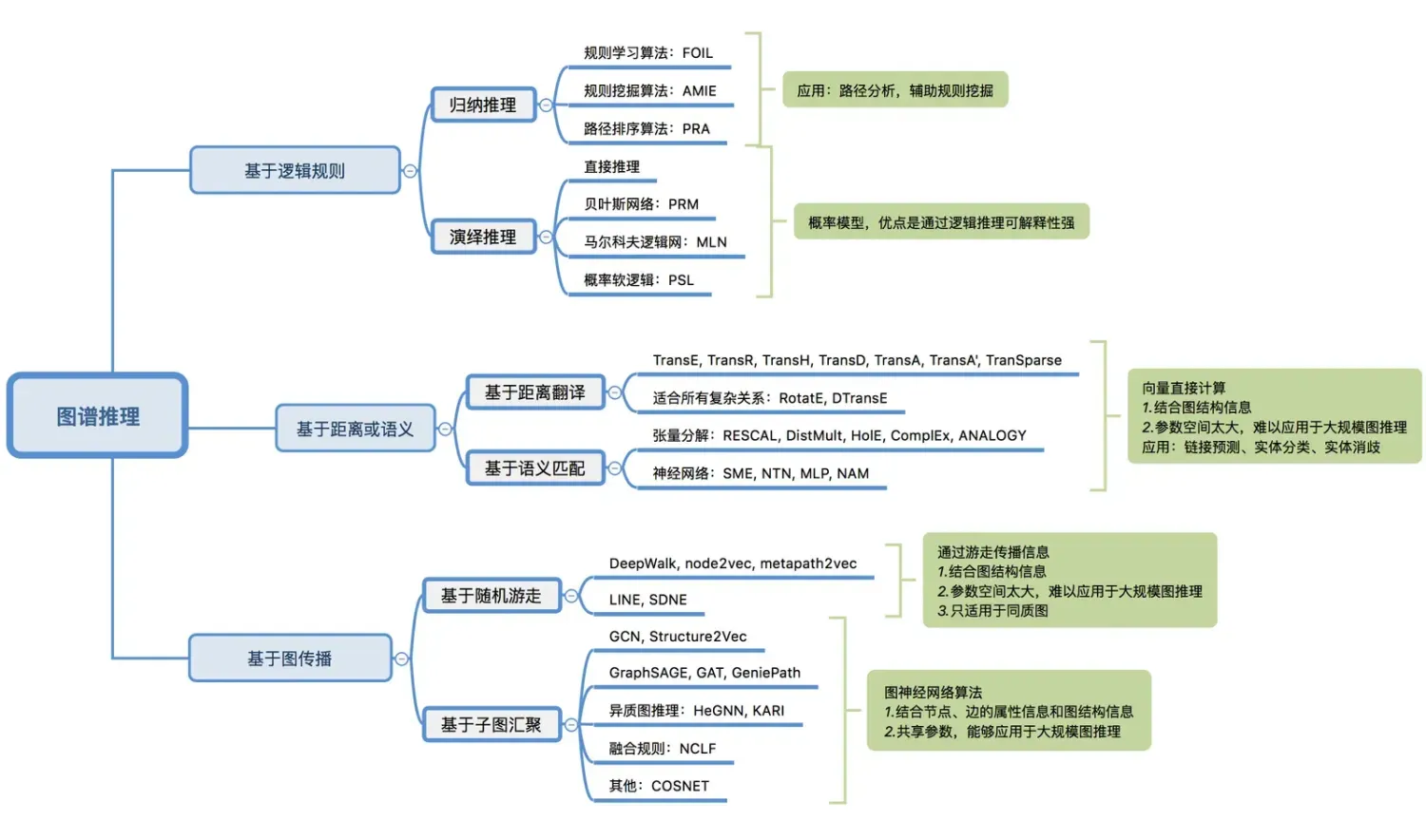
符号推理:基于逻辑规则的推理
- 归纳推理算法,用于规则挖掘
- 归纳程序:FOIL规则学习算法[1],根据增加例子的正、反例数目,计算Foil_Gain因子,选其最大的作为新增规则。
- 关联规则挖掘:AMIE规则挖掘算法[2]。目标是生成边关系规则,事先依据边类型生成所有可能的规则,再在图谱中找出支持该规则的事实,置信度达到阈值则认为该规则成立。缺点:数据稀疏时很难实用。
- 路径排序算法:PRA路径排序算法 (Path Ranking Algorithm)[3]。该算法将每条不同路径的概率作为特征,其中路径概率等于该路径上每步游走的联合概率。然后用逻辑回归分类器做训练和预测,其训练语料为两点之间的各条路径的概率。模型的预测结果包含分类结果以及各条路径的权重,后者可以用作结果解释以及辅助规则挖掘。缺点:这种基于关系的同现统计的方法,都面临数据稀疏时难以实用的问题。PRA的后续改进算法有带采样策略的SFE,多任务耦合的CPRA,效果均有提升。
- 演绎推理算法,用于规则挖掘、事件推理
- 基于规则的直接推理。只适用于确定性推理,不能进行不确定性推理。比如 marryTo(A,B) -> marryTo(B,A)。
- 基于贝叶斯网络的概率关系模型(Probabilistic Relational Models),用条件概率表示因果关系,形成图结构。
- 马尔可夫逻辑网(Markov Logic Network)[4]是将概率图模型与一阶谓词逻辑相结合的一种统计关系学习模型,其核心思想是通过为规则绑定权重的方式将一阶谓词逻辑规则中的硬性约束进行软化。即以前的一阶谓词规则是不能违反的,现在采用了概率来描述。其中,权重反映其约束强度。规则的权重越大,其约束能力越强,当规则的权重设置为无穷大时,其退化为硬性规则。该模型的事实的真值取值0或者1,模型可以学习规则(结构学习),学习权重,利用规则和权重推断未知事实成立的概率。
-
概率软逻辑(Probabilistic Soft Logic)[5]。是马尔可夫逻辑网的升级版本,最大的不同是事实的真值可以在[0,1]区间任意取值。进一步增强了马尔可夫逻辑网的不确定性处理能力,能够同时建模不确定性的规则和事实。并且连续真值的引入使得推理从原本的离散优化问题简化为连续优化问题,大大提升了推理效率。因为是连续值,所以其“与、或、非”规则专门定义了一套公式。
数值推理:基于图表示学习(Knowledge Graph Embedding)的推理
图表示学习(Knowledge Graph Embedding)是知识图谱中的实体和关系通过学习得到一个低维向量,同时保持图中原有的结构或语义信息。所以一组好的实体向量可以充分、完全地表示实体之间的相互关系,因为绝大部分机器学习算法都可以很方便地处理低维向量输入,可以应用于链接预测、分类任务、属性值计算、相似度计算等大多数常见任务。其包含基于距离的翻译模型,基于图传播的模型,基于语义的匹配模型等板块。本文围绕基于语义的匹配模型展开讨论。
基于语义的匹配模型
这类模型使用基于相似度的评分函数评估三元组的概率,将实体和关系映射到隐语义空间中进行相似度度量。这类方法分为两种:一类是简单匹配模型:RESCAL张量分解模型及其变种。二类是深度神经网络SME、NTN(Neural Tensor Networks)神经张量模型、MLP、NAM等等。
算法详细梳理
基于语义的匹配模型--张量分解模型
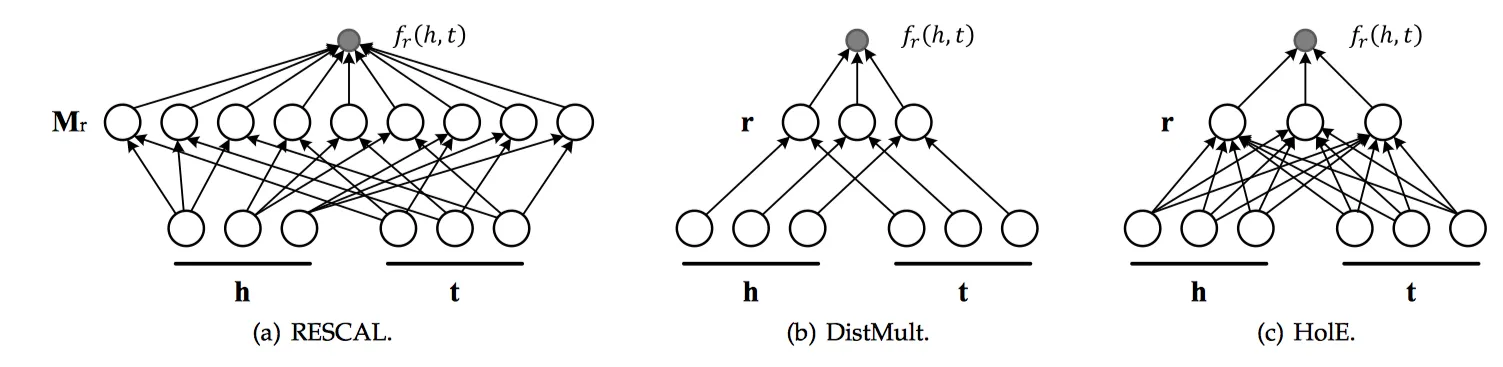
RESCAL
Trans系列算法是利用求和来表达关系
 对头结点
对头结点 的影响,而RESCAL[14]是利用旋转、拉伸来表达关系
的影响,而RESCAL[14]是利用旋转、拉伸来表达关系 对头结点
对头结点 的影响。旋转、拉伸操作在数学上就是乘以矩阵Mr。RESCAL张量分解算法是将整个知识图谱看作一个大的张量,通过张量分解技术分解为多个小的张量片,即将高维的知识图谱进行降维处理,大幅减少计算时的数据规模。张量构建的基本方法是,如果实体i和实体j存在关系k,则
的影响。旋转、拉伸操作在数学上就是乘以矩阵Mr。RESCAL张量分解算法是将整个知识图谱看作一个大的张量,通过张量分解技术分解为多个小的张量片,即将高维的知识图谱进行降维处理,大幅减少计算时的数据规模。张量构建的基本方法是,如果实体i和实体j存在关系k,则 否则为0。
否则为0。其目标函数如下(一种向量内积):

DistMult
DistMult[15]是为了减少RESCAL的参数空间,而采用了一个对角矩阵diag(r)来代替矩阵Mr。这一点与TransH和TransE之间的关系有异曲同工之妙。其目标函数如下:

需要留意的是,因为采用了对角矩阵diag(r),而h、t互换后是相等的,见下式,导致DistMult只能处理对称关系。比如"A-同学-B",而不能处理非对称关系,比如"A-父亲-B"。

HolE
HolE[16]是为了在缩小RESCAL的参数空间前提下,依然能够处理非对称关系而开发的。方法就是每次先利用快速傅里叶变换对头向量和尾向量做一个shift i 位,然后再做内积运算。因为头向量和尾向量shift的位数不一样,就打破了对称性,就可以处理非对称关系了。其目标函数如下:


ComplEx
ComplEx[17]和HolE目的相同,为了能够缩小RESCAL的参数空间,同时依然能够处理非对称关系。ComplEx采用了复数的方式,扩充到实部和虚部以增加自由度的方式来解决非对称关系。其目标函数如下:

ANALOGY
ANALOGY[18]融合了DistMult、HolE、ComplEx这三类模型,以期待得到更好的效果。
基于语义的匹配模型--神经网络类型
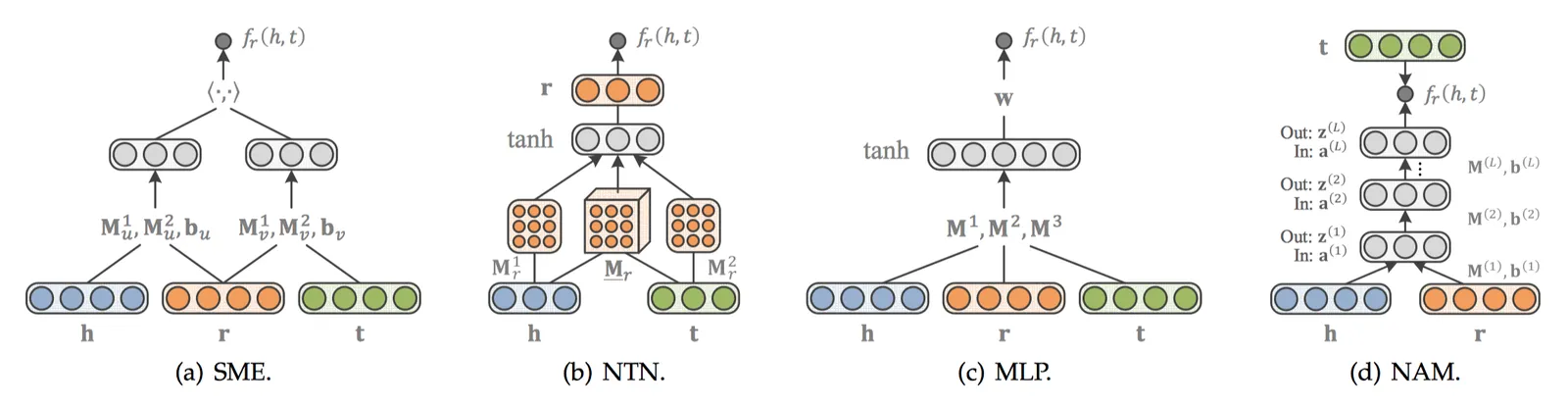
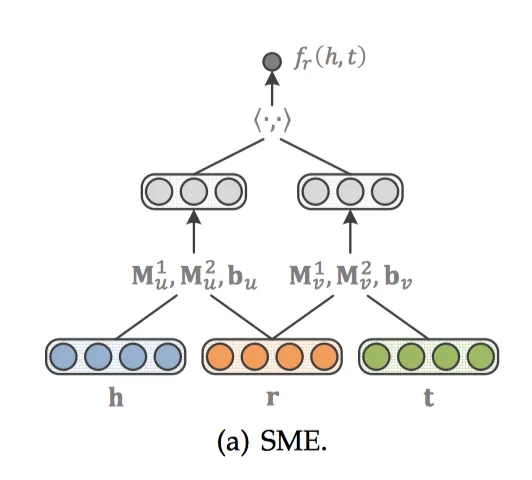
SME
SME[19]利用深度神经网络构造一个二分类模型,将h、r和t输入到网络中。先经过隐藏层gu和gv分别将h、r以及t、r结合,然后将这两个结果在输出层做内积作为得分。如果(h,r,t)在知识图谱中真实存在,则应该得到接近1的概率,如果不存在,应该得到接近0的概率。得分函数如下:

隐藏层gu和gv分别将h、r以及t、r结合。有两个版本,其中一个是线性版本:


另外一个是双线性版本:


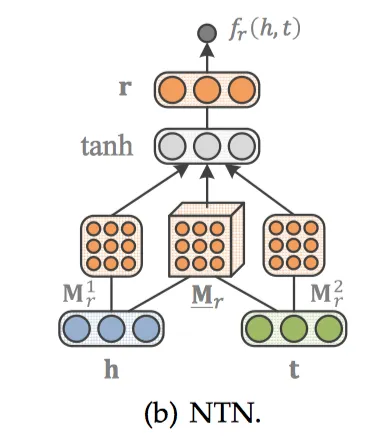
NTN
NTN[20]是另外一种神经网络结构。与SME打平的结构不同,NTN先用隐藏层将h、t结合起来,经过一个激活函数tanh以后,在输出层与关系向量r相结合。得分函数如下:

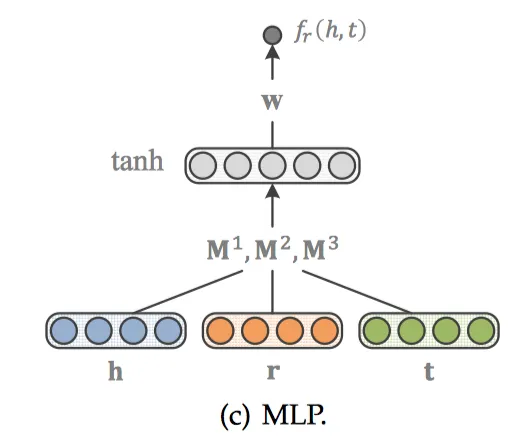
MLP
MLP[21]模型更简单一些,h、r、t经过输入层结合在一起,通过激活函数tanh后得到非线性的隐藏层,权重为M1、M2、M3,最后再经过一个线性的输出层,权重为w。得分函数如下:

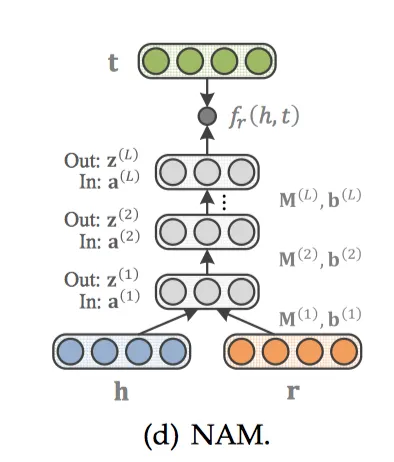
NAM
NAM[22]先将h和r经过输入层后结合在一起,然后使用多层DNN作为隐藏层,第
 层为z(
层为z( )。
)。

得分函数如下:

两种loss
- Logistic loss
Logistic loss适合RESCAL系列模型。是基于Close World假设,即将未观察到的三元组视为不成立。对正确的三元组进行奖励,对错误的三元组进行惩罚。

- pairwise ranking loss
Pairwise ranking loss更适合Trans系列模型。是基于Open World假设,将未观察到的三元组视为不一定成立。将事实三元组和未观测到三元组从距离上尽量分开。

这里
 是给定常数margin,用于将正、负三元组分开。
是给定常数margin,用于将正、负三元组分开。 是正样本的打分,
是正样本的打分, 是负样本的打分。
是负样本的打分。- 初始化
上面这些算法默认都是随机初始化的。初始化这里也有发挥的空间,比如可以利用外部知识源做一些预训练等。
应用
- 链接预测
给定三元组(h, r, t)中任意两个预测第三个。
评估指标有:
-
- MR(mean rank)预测排序的平均值
- MRR(mean reciprocal rank)排序倒数的平均值
- Hits@N 排序高于N的百分比
- AUC-PR 精度-召回曲线下方的面积
- 三元组分类
对给定三元组(h, r, t)判定成立还是不成立。
- 实体分类
这里用了一个技巧,即将实体分类转化为求 “Is A” 关系。
- 实体消歧
若两个实体的向量相等,就判定为同一个实体
Trans系列、RESCAL系列、SME系列这三类模型的参数数量与节点数量成正比,面对大规模图谱时往往捉襟见肘。为了克服这个困难,人们引入了图神经网络模型GNN,图神经网络后来发展成为了一个体系,本文后面会介绍到包括GCN、GAT、Structure2vec、GeniePath等等图神经网络算法。图神经网络算法通过共享参数的方式降低了参数空间,就能适用于大规模图推理了。
文献已经下表将上述各类算法做了一个汇总,将上述算法的实体、关系嵌入向量,打分函数,约束信息的表达式做了整理如下:


小结
从算法分类角度
无监督:Deepwalk、Node2Vec、Metapath2vec、LINE、Louvain
有监督:GCN(半监督)、GraphSAGE、SDNE(半监督)、GeniePath、GAT、Structure2Vec、HeGNN
从应用角度
链接预测:所有的embedding算法都支持链接预测。有一个区别是同质图模型支持一种关系预测,而异质图模型支持多种关系预测。(另外加上ALPS平台尚未包括的trans系列也可以做链接预测)。
实体归一(相似度计算):所有的embedding算法都支持相似度计算。相似度是由具体的任务目标来定义并体现在loss中,一般的任务目标有距离相似性(两个节点有几度相连)、结构相似性、节点类型相似性(label预测)。
属性值预测(label预测):GCN、GraphSAGE、GeniePath、GAT、Structure2Vec、HeGNN等。
-
支持异质图:HeGNN、metaPath2vec、KGNN
-
支持同质图:Deepwalk、Node2Vec、LINE、SDNE、GCN、GraphSAGE、GeniePath、GAT、Structure2Vec
关注我们
查看官网: spg.openkg.cn/
Github: github.com/OpenSPG/ope…
SPG 知识图谱 平台致力于分享 SPG 及 SPG + LLM 双驱架构及应用相关进展,欢迎大家扫码关注~
