背景介绍
GPU 目前大量应用在了爱奇艺深度学习平台上。GPU 拥有成百上千个处理核心,能够并行的执行大量指令,非常适合用来做深度学习相关的计算。在 CV(计算机视觉),NLP(自然语言处理)的模型上,已经广泛的使用了 GPU,相比 CPU 通常能够更快、更经济的完成模型的训练和推理。
CTR (Click Trough Rate) 模型广泛使用在推荐、广告、搜索等场景中,用来估算用户点击某个广告、视频的概率。在 CTR 模型的训练场景中已经大量使用了 GPU,在提升训练速度的同时和降低了所需的服务器成本。
但在推理场景下,当我们直接把训练好的模型通过 Tensorflow-serving 部署在 GPU 之后,发现推理效果并不理想。表现在:
-
推理延迟高,CTR 类模型通常是面向终端用户的,对于推理延迟非常敏感。
-
原因分析
分析工具
-
Tensorflow Board,tensorflow 官方提供的工具,能够可视化的查看计算流图中各个阶段的耗时,并汇总算子的总耗时。
-
Nsight 是 NVIDIA 面向 CUDA 开发者提供的开发工具套件,能够对 CUDA 程序进行相对底层的跟踪、调试和性能分析。
分析结论
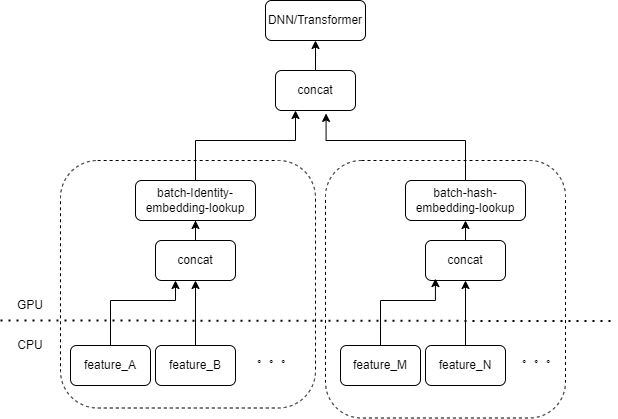
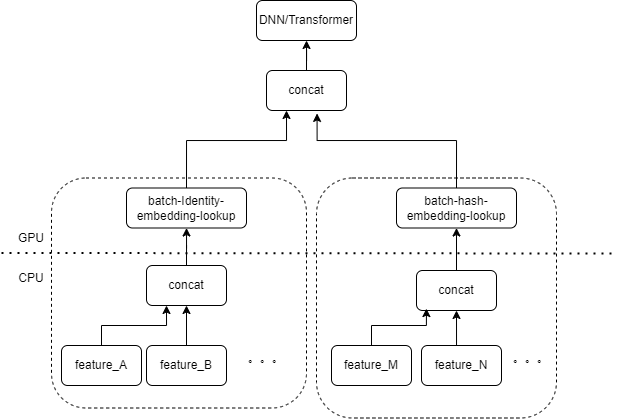
典型的 CTR 模型输入,包含大量的稀疏类特征(如设备 ID、最近浏览视频 ID 等)。Tensorflow 的 FeatureColumn 会对这些特征进行处理,首先进行 identity/hash 操作,得到 embedding table 的 index。再经 embedding lookup 和求均值等操作后,得到对应的 embedding tensor。多个特征对应的 embedding tensor 拼接后得到一个新的 tensor,再进入后续的 DNN/Transformer 等结构。
因此每个稀疏特征在模型的输入层,都会启动若干个算子。每个算子会对应着一次或者几次 GPU 计算,即 cuda kernel。每个 cuda kernel 包括两个阶段,launch cuda kernel(启动 kernel 所必需的 overhead) 和 kernel 执行(在 cuda 核心上真正执行矩阵计算)。稀疏特征 identity/hash/embedding lookup 对应的算子计算量较小,launch kernel 的耗时往往超过 kernel 执行的时间。一般来说 CTR 模型包含了几十到几百个稀疏特征,理论上就会有数百次 launch kernel,是当前主要的性能瓶颈。
在使用 GPU 训练 CTR 模型时,没有遇到这个问题。因为训练本身是一个离线任务,不关注延迟,所以训练时候的 batch size 都可以很大。虽然仍会进行多次 launch kernel,只要执行 kernel 时候计算的样本数量足够多,lauch kernel 的开销平均到每个样本上的时间就很小了。而对于在线推理的场景,如果要求 Tensorflow Serving 收到足够的推理请求并合并批次后再进行计算,那么推理延迟就会很高。
优化方案
我们的目标是在基本不改变训练代码,不改变服务框架的前提下,进行性能优化。我们很自然的想到两个方法,减少启动的 kernel 数量,提高 kernel 启动的速度。
算子融合
基本操作就是将多个连续的操作或算子合并成一个单一的算子,一方面可以减少 cuda kernel 启动的次数,另一方面可以把计算过程中一些中间结果存在寄存器或者共享内存,只在算子的最后把计算结果写入全局的 cuda 内存。
-
-
自动融合
我们尝试了多种深度学习编译器,如 TVM/TensorRT/XLA,实测可以实现 DNN 部分少量算子的融合,如连续的 MatrixMat/ADD/Relu。由于 TVM/TensorRT 需要导出 onnx 等中间格式,需要修改原有模型的上线流程。所以我们通过 tf.ConfigProto() 开启 tensorflow 内置的 XLA 来进行融合。
但自动融合对稀疏特征相关的算子并没有很好的融合效果。
手动算子融合
我们很自然的想到,如果有多个特征在输入层被相同类型的 FeatureColumn 组合所处理,那么我们可以实现一个算子,把多个特征的输入拼接成数组作为算子的输入。算子的输出是一个张量,这个张量的 shape 和原本多个特征分别计算后再拼接得到的张量 shape 一致。
以原有的 IdentityCategoricalColumn + EmbeddingColumn 组合为例,我们实现了 BatchIdentiyEmbeddingLookup 算子,达到相同的计算逻辑。
为了方便算法同学使用,我们封装了一个新的 FusedFeatureLayer,来代替原生的 FeatureLayer;除了包含融合算子,还实现了以下逻辑:
-
-
需要对特征进行排序,保证相同类型的特征可以排在一起。
-
由于每个特征的输入均为变长,在这里我们额外生成了一个索引数组,来标记输入数组的每个元素属于哪个特征。
对于业务来说,只需要替换原来的 FeatureLayer 即可达到融合的效果。
实测原本数百次的 launch kernel,经过手动融合后缩减到了 10 次以内。大大减少了启动 kernel 的开销。
MultiStream 提高 launch 效率
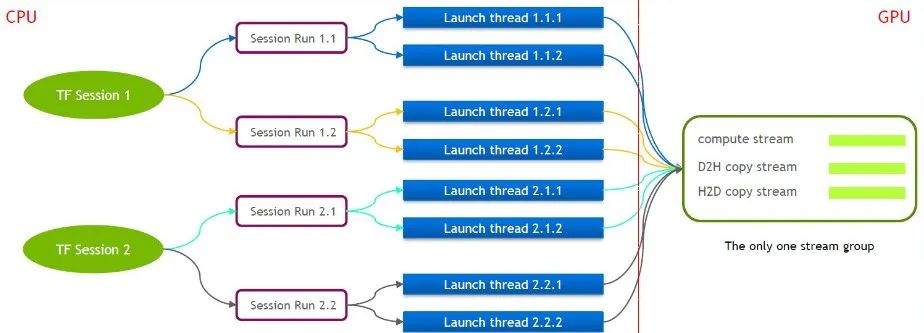
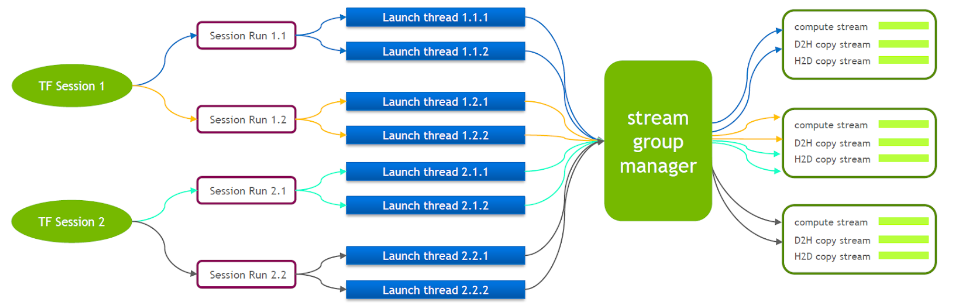
TensorFlow 本身是一个单流模型,只包含一个 Cuda Stream Group(由 Compute Stream、H2D Stream,D2H Stream 和 D2D Stream 组成)多个 kernel 只能在同一个 Compute Stream 上串行执行效率较低。即使通过多个 tensorflow 的 session 来 launch cuda kernel,在 GPU 侧仍然需要排队。
为此 NVIDIA 的技术团队维护了一个自己的 Tensorflow 分支,支持多个 Stream Group 同时执行。以此来提高 launch cuda kernel 的效率。我们将此特性移植到了我们的 Tensorflow Serving 里。
在 Tensorflow Serving 运行时候,需要开启 Nvidia MPS,减少多个 CUDA Context 间的相互干扰。
小数据拷贝优化
在前边优化基础上,我们针对小数据拷贝进一步做了优化。当 Tensorflow Serving 从请求中反序列化出中各个特征的值后,会多次调用 cudamemcpy,将数据从 host 拷贝到 device。调用次数取决于特征数量。
大部分 CTR 类业务,实测当 batchsize 较小时和,先将数据在 host 侧拼接,再一次性的调用 cudamemcpy 效率会更高一些。
合并批次
GPU 场景下需要开启批次合并。默认情况下 Tensorflow Serving 是不对请求进行合并的。为了更好的利用 GPU 的并行计算能力,让一次前向计算时候可以包含更多的样本。我们在运行时候打开了 Tensorflow Serving 的 enable_batching 选项,来对多个请求进行批次合并。同时需要提供一个 batch config 文件,重点配置以下参数,以下是我们总结的一些经验。
-
max_batch_size:一个批次允许的最大请求数量,可以稍微大一点。
-
batch_timeout_micros:合并一个批次等待的最长时间,即使该批次的数量未达到max_batch_size,也会立即进行计算(单位是微秒),理论上延迟要求越高,这儿设置的越小,最好设置在 5 毫秒以下。
-
num_batch_threads:最大推理并发线程,在开启了 MPS 之后,设置成 1 到 4 都可以,再多延迟会高。
在这里需要注意的是,CTR 类模型大部分输入的稀疏特征都为变长特征。如果客户端没有专门做约定,可能出现多个请求中在某个特征上的长度不一致。Tensorflow Serving 有一个默认的 padding 逻辑,给较短的请求在对应的特征上补 0。而对于变长特征使用 -1 来表示空,默认的补 0 会事实上改变原有的请求的含义。
比如用户 A 最近的观看视频 id 为 [3,5],用户 B 最近的观看视频 id 为 [7,9,10]。如果默认补齐,请求变成 [[3,5,0], [7,9,10]],在后续的处理中,模型会认为 A 最近观看了 id 为 3,5,0 的 3 个视频。
因此我们修改了 Tensorflow Serving 响应的补齐逻辑,遇到这种情况会补齐为 [[3,5,-1], [7,9,10]]。第一行的含义仍然是观看了视频 3,5。
最终效果
经过各种上述各种优化,在延迟和吞吐量满足了我们的需求,并落地在推荐个性化 Push、瀑布流业务上。业务效果如下:
-
吞吐量相比原生Tensorflow GPU 容器提升 6 倍以上
-
-
本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。