
爱奇艺基于 Hive 构建了传统的离线数据仓库,支持了公司运营决策、用户增长、视频推荐、会员、广告等业务需求。近几年,随着业务对数据实时性的更高要求。我们引入了基于 Iceberg 的数据湖技术,大幅提升数据查询性能及整体流通效率。从性能和成本角度考虑,将现有的Hive表迁移到数据湖是必要的。然而多年来,大数据平台上已经积累了数百 PB 的 Hive 数据,如何将 Hive 迁移到数据湖,成为我们面临的一大挑战。本文介绍了爱奇艺从 Hive 平滑迁移到 Iceberg 数据湖的技术方案,帮助业务加速数据流程,提效增收。
01
Hive VS Iceberg
Hive 是一个基于 Hadoop 的数据仓库和分析平台,提供了类似 SQL 的语言,支持复杂的数据处理和分析。
Iceberg 是一个开源的数据表格式,旨在提供可扩展、稳定和高效的表格存储,以支持分析性工作负载。Iceberg 提供了类似传统数据库的事务性保证和数据一致性,并支持复杂的数据操作,如更新、删除等。
表 1-1 分别列出了 Hive 和 Iceberg 在时效性、查询性能等方面的比较情况:
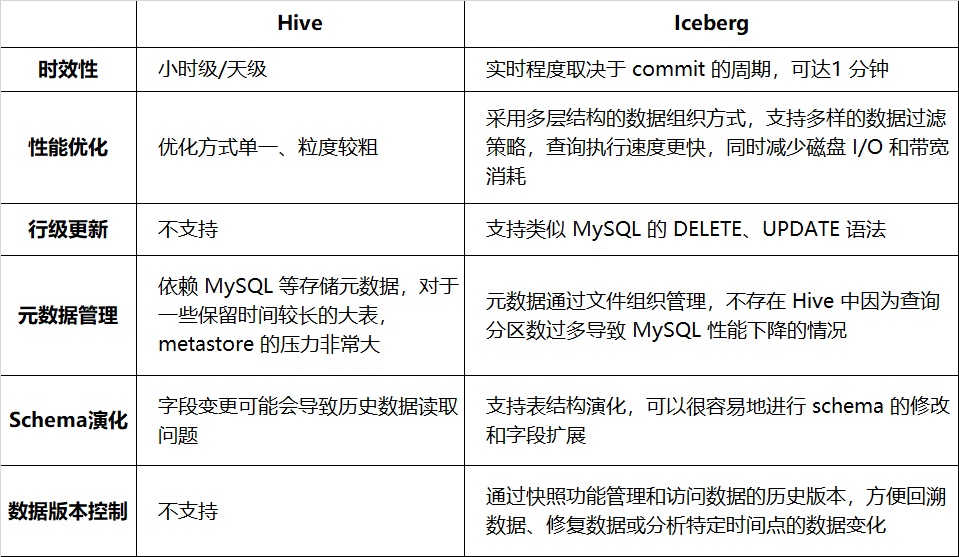
表 1-1 Hive 和 Iceberg 的对比
切换到 Iceberg 可以提高数据处理的效率和可靠性,为复杂的数据操作提供更好的支持,目前已接入广告、会员、Venus 日志、审核等十几个业务。关于爱奇艺 Iceberg 实践的更多细节,可阅读之前的系列文章(见文末引用)。
02
Hive 存量数据平滑切换 Iceberg
Iceberg 相比 Hive 有诸多优势,可是业务的数据已经运行在 Hive 环境中,业务不希望投入大量的人力修改存量的任务。我们调研了业界常用切换方法 [1],在数据湖平台上提供了自助式 Hive 平滑切换 Iceberg 的能力,本节将阐述具体实现方案。
1. 查询兼容性
在实际切换前,我们验证了 Spark 对 Hive 和 Iceberg 的兼容性。
Spark 对 Hive 和 Iceberg 表的查询、写入语法基本是相同的,对 Hive 表的查询 SQL 语句无需修改即可查询 Iceberg 表。
但 Iceberg 与 Hive 在 DDL 方面存在较大差异,主要表现在对表结构进行修改的处理方式上,详细信息如表 2-1 所述。实际 schema 与数据文件的 schema 需要一一对应,否则会影响数据的查询,因此对于 DDL 语句的处理应该更为谨慎,不建议将这类 DDL 语句与任务绑定在一起。
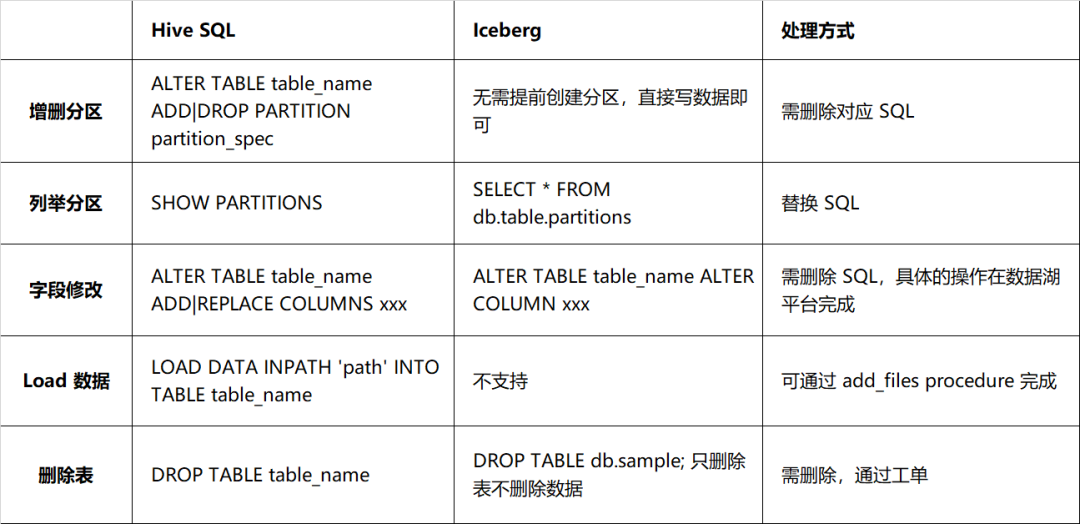
表 2-1 Hive 和 Iceberg 语法兼容性对比
2. 业界切换方案
2.1 业务双写切换
业务复制现有的pipeline,实现Hive、Iceberg双写。待新旧通路对数一致后,切换到 Iceberg 通路,并下线原有的通路。该方案需要业务投入人力进行开发、对数,耗时耗力。
2.2 原地切换,客户端停写
如果业务允许停写一段时间进行切换,则可以用如下一些方式:
-
Spark migrate procedure 是 Iceberg 官方提供的函数,可将一个 Hive 表原地切换为 Iceberg,示例如下:
CALL catalog_name.system.migrate('db.sample'); |
该程序不会修改原始数据,仅会扫描原表的数据然后构建 Iceberg 元信息,引用原始的文件。因而 migrate 程序执行速度非常快,但存量数据无法利用文件索引等特性加速查询。如希望存量数据也加速,可以使用 Spark 的rewrite_data_files 方法重写历史数据。
migrate 程序并不会将 Hive 表删除,而是将其重命名为 sample__BACKUP__,此处 __BACKUP__ 后缀是硬编码的,如果需要回滚可将新建的 Iceberg 表 Drop 掉,将 Hive 表 rename 回去。
-
使用 CTAS 语句,Spark 示例如下:
CREATE TABLE db.sample_iceberg USING Iceberg PARTITIONED BY dt LOCATION 'qbfs://....' TBLPROPERTIES('write.target-file-size-bytes' = '512m', ...) AS SELECT * FROM db.sample; |
在写入完成后进行对数,符合要求后,通过重命名完成切换。
ALTER TABLE db.sample RENAME TO db.sample_backup; ALTER TABLE db.sample_iceberg RENAME TO db.sample; |
CTAS 相比于 migrate 优势是存量数据重新写入,因而可以优化分区、列排序、文件格式和小文件等。缺点是如果存量数据较多,重写耗时耗资源。
以上两个方案,具有如下特性:
优点:
方案简单,执行已有的 SQL 即可
可回滚,原 Hive 表还在
缺点:
写入/读取程序未验证:切换到 Iceberg 表后,可能出现写入或查询异常
要求切换过程停写,对一些业务是不能接受的
3. 爱奇艺平滑迁移方案
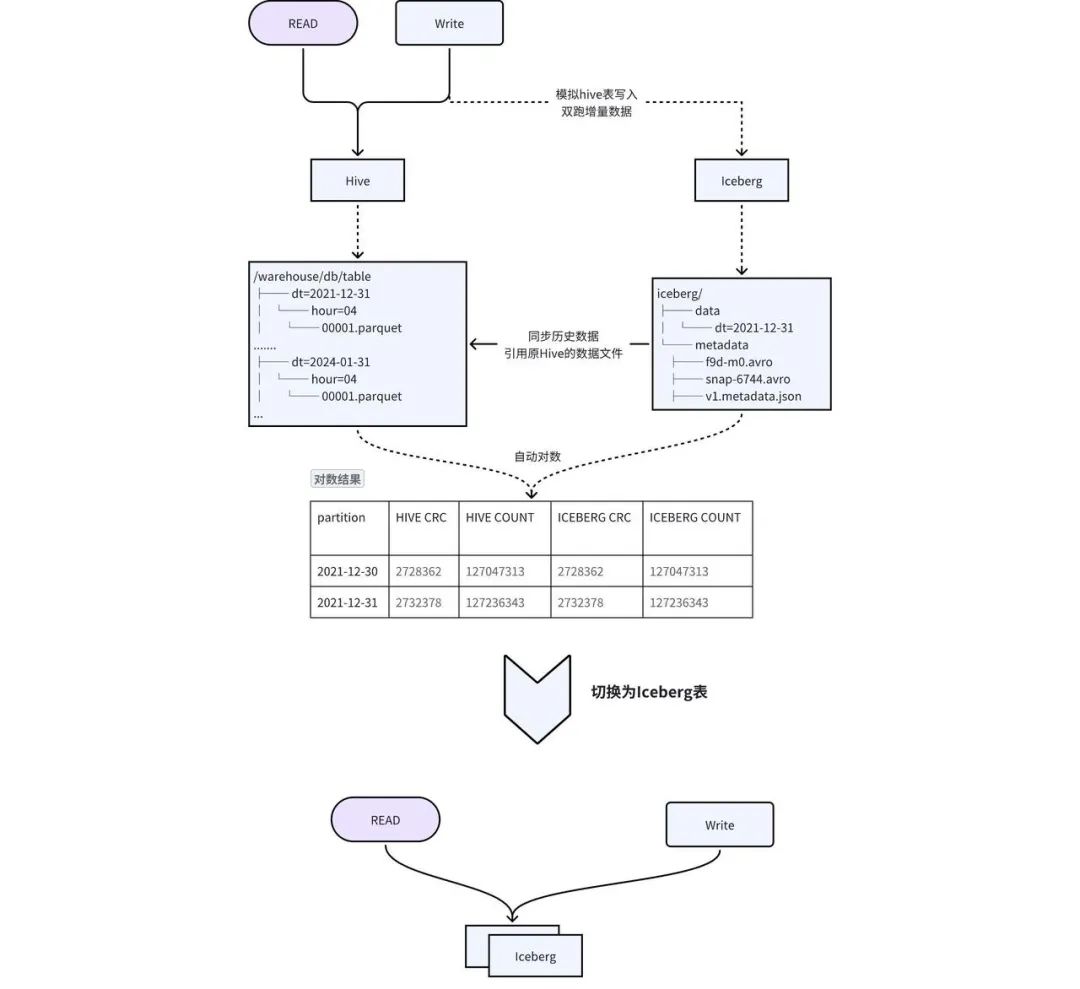
考虑到上述方案的缺点,我们设计了原地双写 + 透明切换的方案,实现平滑迁移,如图 2-1 所示:
-
建表:创建与 Hive 相同 schema 的 Iceberg 表,同步 Hive 表的 TTL、权限等元信息到 Iceberg 表。 -
历史数据迁移到 Iceberg : Hive 历史数据通过 add_file procedure 添加到 Iceberg 中,该操作会根据 Hive 数据构建出 Iceberg 的元数据,实际上 Iceberg 的元数据中指向的是 Hive 的数据文件,减少了数据冗余及历史数据同步时间。 -
增量数据双写 : 通过爱奇艺自研的 Pilot SQL 网关探测 Hive 表的写入任务,自动复制写入 SQL,并将输出替换成 Iceberg 表,实现双写。 -
数据一致性 校验: 当历史数据同步完成且增量双写到一定次数之后,后台会自动发起对数,校验 Hive 和 Iceberg 中的数据是否一致。对于历史数据与增量数据会选取一部分数据进行 count 以及字段 CRC 数值校验。 -
切换 : 数据一致性校验完成后,进行 Hive 和 Iceberg 的切换,用户不需要修改任务,直接使用原来的表名进行访问即可。正常切换过程耗时在几分钟之内。
03
核心收益 - 加速查询
1. Iceberg 查询加速技术
2. Iceberg 加速技巧
-
配置分区:使用分区剪裁的方式使查询只针对特定分区的数据执行,而不需要扫描整个数据集。 -
指定排序列:通过对数据分布进行合理的组织,最大限度的发挥文件级别的过滤效果,使得查询只集中在特定的文件。例如通过下面的方式使得写入 sample 表的数据按照 category, id 降序写入,注意由于多了一个排序的环节,这种方式会比非排序的写入耗时长。
|
|
-
高基数列应用布隆过滤器:在查询数据时,会自动应用布隆过滤器来快速验证查询数据是否存在于某个数据块,避免不必要的磁盘访问。
|
|
-
使用 Trino 代替 Spark:由于 Trino 自身 MPP 的架构,在查询上相较于 Spark 更有优势,并且 Trino 自身对 Iceberg 也有相应的优化,因此如果有秒级查询的需求,可将引擎由 Spark 切换到 Trino。 -
Alluxio 缓存:使用 Alluxio 作为数据缓存层,将数据缓存在内存中。在查询时可以直接从内存中获取数据,避免从磁盘读取数据的开销,可大大提高查询速度,也可防止 HDFS 抖动对任务的影响。 -
ORC 代替 Parquet:由于 Trino 对 ORC 格式有特定的优化,使得 ORC 的读取性能要优于 Parquet,可以将文件格式设置为 ORC 加速查询。 -
配置合并:写 Iceberg 的任务往往会出现写入文件较小但数量较多的情况,通过将小文件合并成一个或少量更大的文件,有利于减少读取的文件数,降低磁盘 I/O。
3. 性能评测
3.1 文件内过滤性能提升
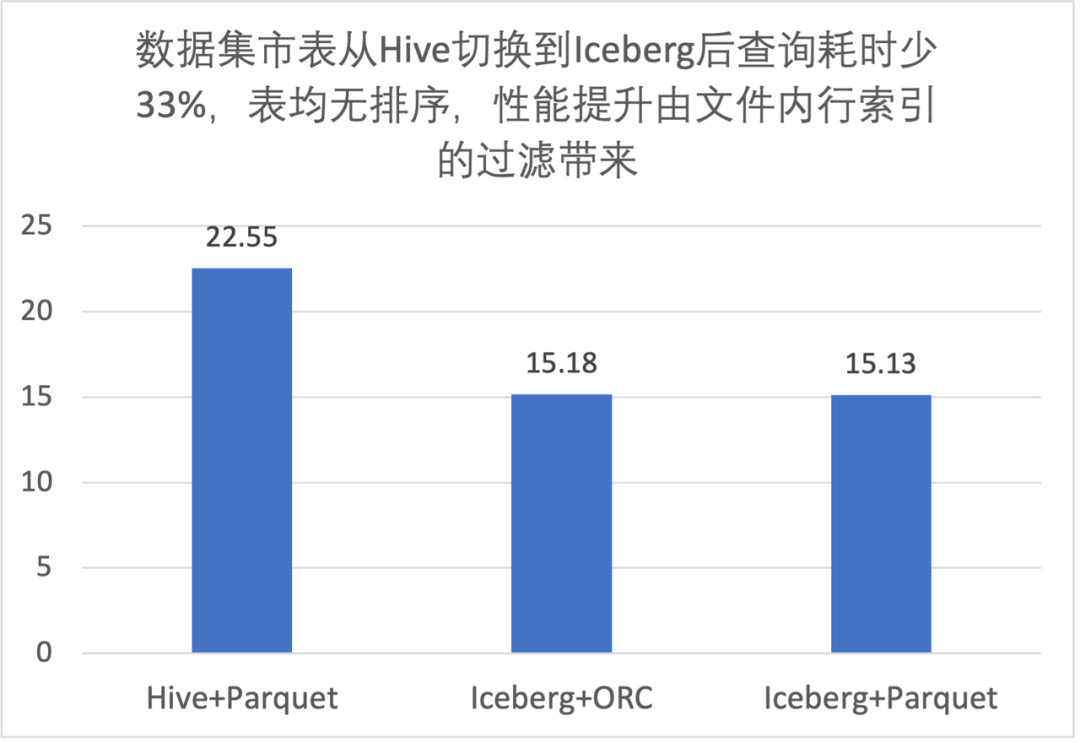
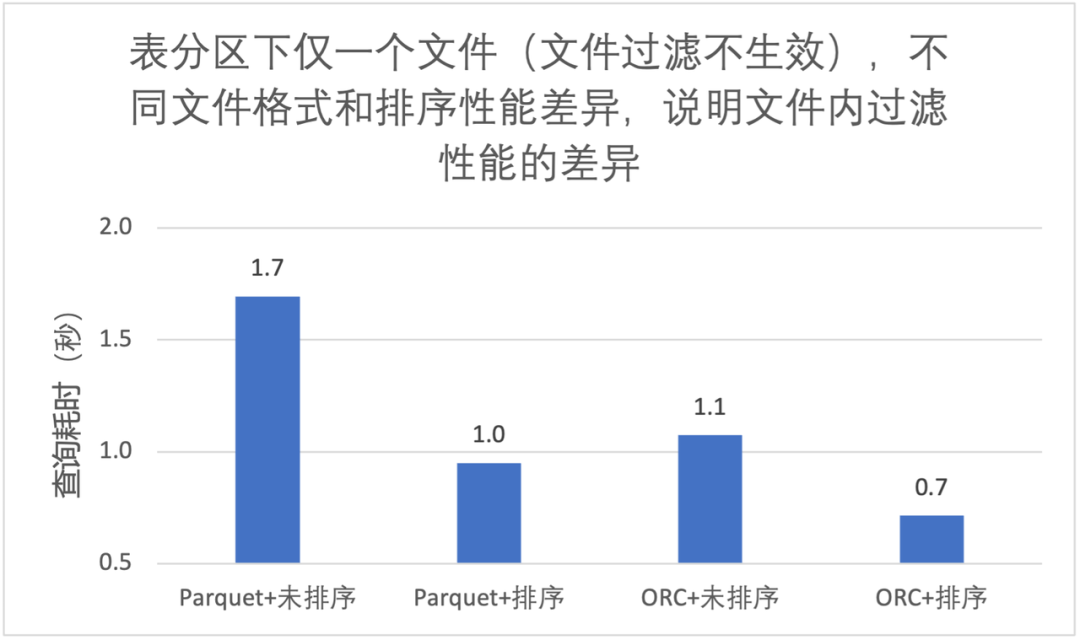
3.2 列排序对文件内过滤性能提升
-
同样的文件格式,排序后文件内过滤效果更好,大致能快 40%; -
ORC 查询性能优于 Parquet; -
使用 Trino 查询,我们推荐 Iceberg 表 + ORC 文件格式 + 列排序;
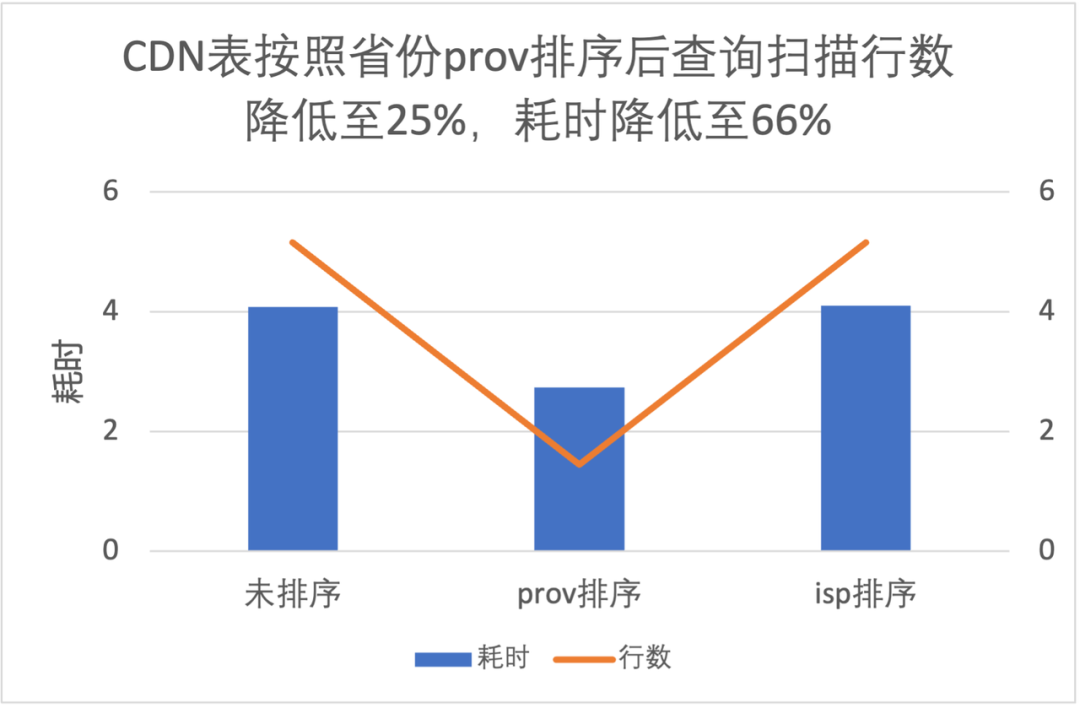
3.3 列排序对文件级过滤性能提升
|
|
-
按照 prov 排序查询读取数据量是不排序的 25%,耗时是 66%; -
按照 isp 排序提升不明显,这是因为 isp 数据量有明显的倾斜,条件中 isp 值占比高达 90%;
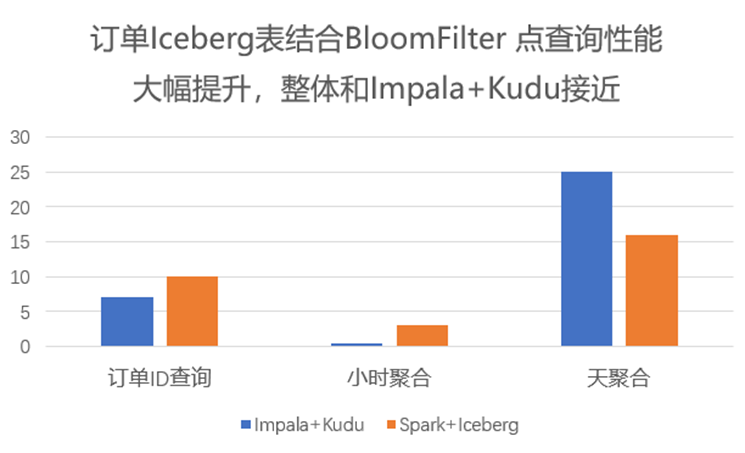
3.4 布隆过滤器的性能提升
3.5 Spark 和 Trino 性能比较
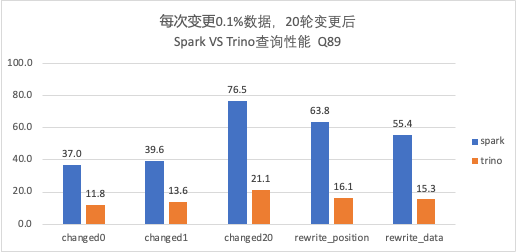
-
Trino 对于 V2 表查询结果与 Spark 一致,且在相同核数性能优于 Spark,耗时是 Spark 的 1/3 左右; -
随着变更轮次的增加(Data File 和 Postition Delete File 数量增加),Trino 查询性能也会逐渐变慢,需要定期进行合并。
04
核心收益 - 支持变更
1. 变更在业务使用场景
-
ETL 计算:如广告计费,通过接入 Iceberg 实现变更,简化业务逻辑,实现了更长时间范围的转化回收; -
数据修正:批量修正,如对某个数据的状态进行修改、批量删除等; -
隐私相关:如播放记录、搜索记录,用户需要删除历史条目等; -
CDC 同步:如订单业务,需要将 MySQL 中的数据进行大数据分析,通过 Flink CDC 技术很方便地将 MySQL 数据入湖,实时性可达到分钟级。
2. Hive 如何实现变更
-
分区覆写 例如修改某个 id 的相关内容,先筛选出要修改的目标行,更新后与历史数据进行合并,最后覆盖原表。这种方式对不需要修改的数据进行了重写,浪费计算资源;且覆写的粒度最小是分区级别,数据无法进一步细分,任务耗时相对较长。 -
标记删除 通常的做法是添加标志位,数据初始写入时标志位置 0,需要删除时,插入相同的数据,且标志位置 1,查询时过滤掉标志位为 1 的数据即可。这种方式在语义上未实现真正的删除,历史数据仍然保存在 Hive 中,浪费空间,而且查询语句较为复杂。
3. Iceberg 支持的变更类型
-
Delete:删除符合指定条件的数据,例如
|
|
-
Update:更新指定范围的数据,例如
|
|
-
MERGE:若数据已存在 UPDATE,不存在执行 INSERT,例如
|
|
4. Iceberg 变更策略
-
Copy on Write(写时合并):当进行删除或更新特定行时,包含这些行的数据文件将被重写。写入耗时取决于重写的数据文件数量,频繁变更会面临写放大问题。如果更新数据分布在大量不同的文件,那么更新的执行速度比较慢。这种方式由于结果文件数较少,读取的速度会比较快,适合频繁读取、低频批次更新的场景。 -
Merge on Read(读时合并):文件不会被重写,而是将更改写入新文件,当读取数据时,将新文件合并到原始数据文件得到最终结果。这使得写入速度更快,但读取数据时必须完成更多工作。写入新文件有两种方式,分别是记录删除某个文件对应的行(position delete)、记录删除的数据(equality detete)。 -
Position Delete:当前 Spark 的实现方式,记录变更对应的文件及行位置。这种方式不需要重写整个数据文件,只需找到对应数据的文件位置并记录,减少了写入的延迟,读取时合并的代价较小。 -
Equality Delete:当前 Flink 的实现方式,记录了删除数据行的主键。这种方式要求表必须有唯一的主键,写入过程无需查询数据文件,延迟最低;然而它的读取代价最大,这是由于读取时需要将 equality delete 记录和所有的原始文件进行 JOIN。
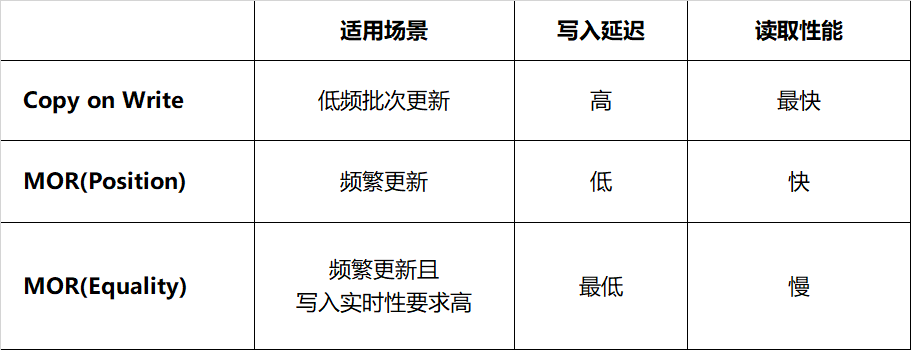 表 4-1 Iceberg 不同变更策略对比
表 4-1 Iceberg 不同变更策略对比
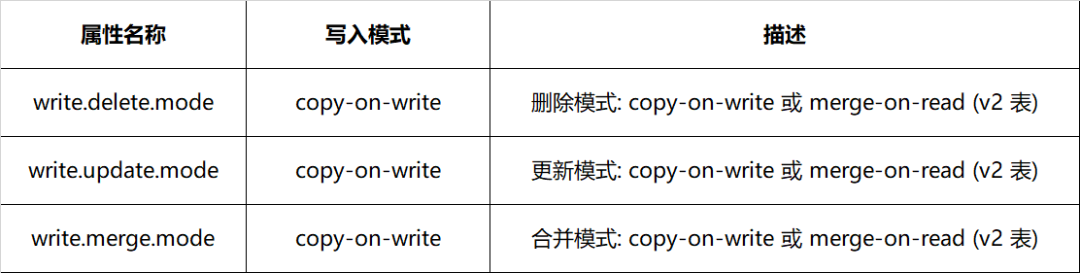 表 4-2 Iceberg 变更属性配置方式
表 4-2 Iceberg 变更属性配置方式
5. 业务接入
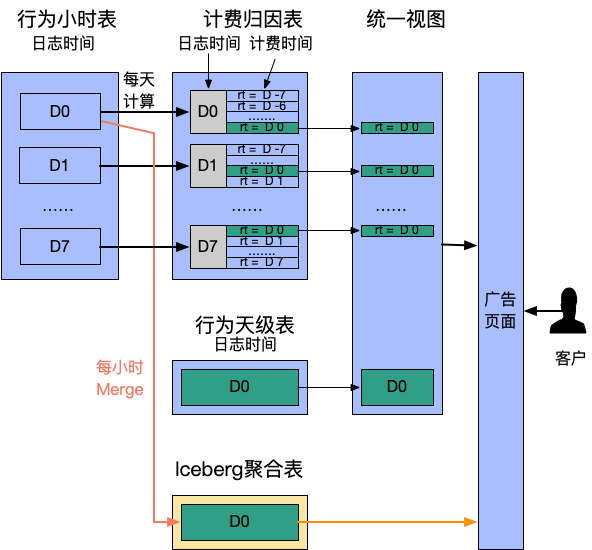
5.1 广告计费转换
-
每天触发一次计算,从行为表聚合出过去 7 天的“计费时间”数据。此处用 rt 字段代表计费时间 -
提供统一视图合并行为数据和计费时间数据,计费归因表 rt as dt 作为分区过滤查询条件,满足同时检索曝光和计费转化的需求
|
|
-
时效性提升:从天级缩短到小时级,客户更实时观察成本,有利于预算引入; -
计算更长周期数据:原先为计算效率仅提供 7 日内转换,而真实场景转换周期可能超过 1 个月; -
表语义清晰:多表联合变为单表查询。
5.2 数据修正
|
|
05
总结
06
引用
-
From Hive Tables to Iceberg Tables: Hassle-Free -
通过数据组织优化加速基于Apache Iceberg的大规模数据分析 -
Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg -
《爱奇艺数据湖实战 - 综述》 -
《爱奇艺数据湖实战 - 广告》 -
《爱奇艺数据湖实战 - 基于数据湖的日志平台架构演进》 -
《爱奇艺数据湖实战 - 数据湖技术在爱奇艺BI场景的应用》 -
《爱奇艺在Iceberg落地相关性能优化与实践》

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。