
01
背景与现状
1、广告领域数据特点
广告领域数据可以分成:连续值特征和离散值特征。不同于 AI 图像、视频、语音等领域,广告领域内的原始数据大多以 ID 形式呈现,比如用户 ID、广告 ID、与用户交互的广告 ID 序列等,而且 ID 规模较大,形成了广告领域数据高维稀疏的鲜明特点。
-
既 有静态的(比如用户的年龄),也有基于用户行为的动态特征(比如用户点击某行业广告的次数)。 -
优点是具备良好的泛化能力。 一个用户对行业的偏好可以泛化到对这个行业有相同统计特性的其他用户身上。 -
不足是缺乏记忆能力导致区分度不高。 比如两个相同统计特性的用户,可能行为上也会存在显著差别。 另外,连续值特征还需要大量的人工特征工程。
-
离散值特征是细粒度的特征。 有可枚举的(如用户性别、行业ID ),也有高维的(如用户ID 、广告ID )。 -
优点就是记忆性强、区分度高。 还可以对离散值特征进行特征组合,用于学习交叉、协同信息。 -
缺点是泛化能力相对较弱。
-
独热编码( One-hot Encoding ) -
特征嵌入( Embedding )
-
特征冲突: 若 vocabulary_size 设置过大,训练效率会急剧下降且会由于内存 OOM 导致训练失败。 因此即使对于亿级别的用户 ID 离散值特征,我们也仅会设置 10 万量级的 ID Hash 空间,Hash 冲突率较高,特征信息受损,离线评估无正向收益。 -
低效的 IO : 由于用户 ID 、广告 ID 等特征是高维稀疏的,即一段时间内训练更新的参数只占总量很少的一部分,在 TensorFlow 原有静态 Embedding 机制下,模型存取需要处理整个稠密 Tensor,这会带来极大的 IO 开销,无法支持稀疏大模型的训练。
02
广告稀疏大模型实践
-
TFRA API 兼容 Tensorflow 生态(复用原有优化器和初始化器,API 同名且行为一致),使 TensorFlow 能够以更原生的方式支持 ID 类稀疏大模型的训练和推理; 学习及使用成本低,不改变算法工程师建模习惯。 -
内存动态伸缩,训练更省资源; 有效避免Hash 冲突,保证特征信息无损。
-
静态 Embedding 升级到动态 Embedding : 下线对于离散值特征的人工 Hash 逻辑,使用 TFRA 动态Embedding 对参数进行存储、访问和更新,从而在算法框架上保证所有离散值特征的 Embedding 无冲突,保证所有离散值特征的无损学习。 -
高维稀疏 ID 特征的使用: 如上文所述,使用 TensorFlow 静态 Embedding 功能时,用户 ID 、广告 ID 特征由于 Hash 冲突,离线评估无收益。 算法框架升级后,重新引入用户 ID、广告 ID 特征,离线及线上均有正向收益。 -
高维稀疏组合 ID 特征的使用: 引入用户 ID 与广告粗粒度 ID 的组合离散值特征,比如用户 ID 分别与行业 ID 、App 包名的组合。 同时结合特征准入功能,引入使用更稀疏的用户 ID 与广告 ID 的组合离散特征。

2、模型更新
-
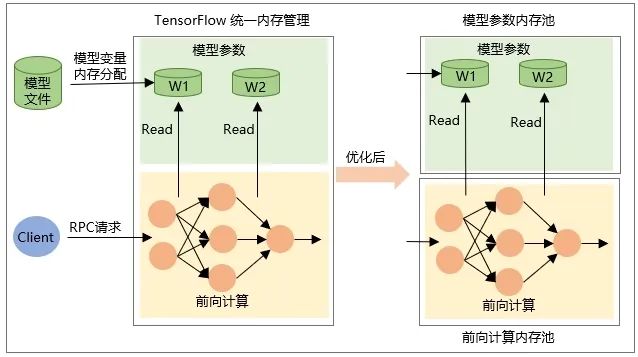
模型 Restore 时变量本身 Tensor 的分配,即加载模型时分配内存,卸载模型时释放内存。 -
RPC 请求时网络前向计算时中间输出 Tensor 的内存分配,在请求处理结束后被释放。
03
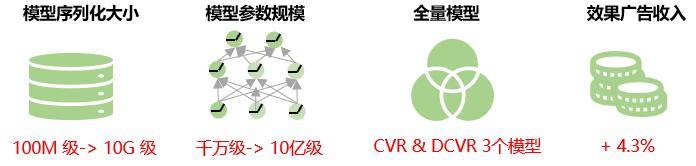
总体收益
04
未来展望
目前广告稀疏大模型中同一特征的所有特征值赋予了相同的 Embedding 维度。实际业务中,高维特征的数据分布极不均匀,极少量高频特征占比极高,长尾现象严重;所有特征值使用固定的 Embedding 维度会降低 Embedding 表示学习的能力。即对于低频特征,Embedding 维度过大,模型有过拟合的风险;对于高频特征,由于有丰富的信息需要表示学习,Embedding 维度过小,模型有欠拟合的风险。因此后续我们会探索自适应地学习特征 Embedding 维度的方法,进一步提升模型预估的精度。
同时我们会探索模型增量导出的方案,即仅将增量训练时产生变化的参数加载到 TensorFlow Serving,从而降低模型更新时的网络传输和加载耗时,实现稀疏大模型的分钟级更新,提高模型的实时性。

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
{{o.name}}
{{m.name}}