混部作为一种提高资源利用率、降低成本的的方案,被业界普遍认可。爱奇艺在云原生化与降本增效的过程中,成功将大数据离线计算、音视频内容处理等工作负载与在线业务进行了混部,并且取得了阶段性收益。本文重点以大数据为例,介绍从 0 到 1 落地混部体系的实践过程。
背景
爱奇艺大数据支持了公司内运营决策、用户增长、广告分发、视频推荐、搜索、会员等重要场景,为业务提供数据驱动引擎。随着业务需求的增长,计算需要的资源量与日俱增,成本管控和资源供给面临着较大的压力。
爱奇艺大数据计算分为离线计算、实时计算两条数据处理链路,其中:
-
离线计算包括以 Spark 为主的数据处理、以 Hive 为主的小时级乃至天级别的数仓构建及对应的报表查询分析,这类计算多在每天凌晨开始启动计算前一天的数据,在上午结束。每天 0 - 8 点是计算资源需求的高峰期,集群总资源往往不足,任务经常排队、积压,而白天则出现较大空闲导致资源浪费。
-
实时计算包括 Kafka + Flink 为代表的实时数据流处理,具有比较稳定的资源需求。
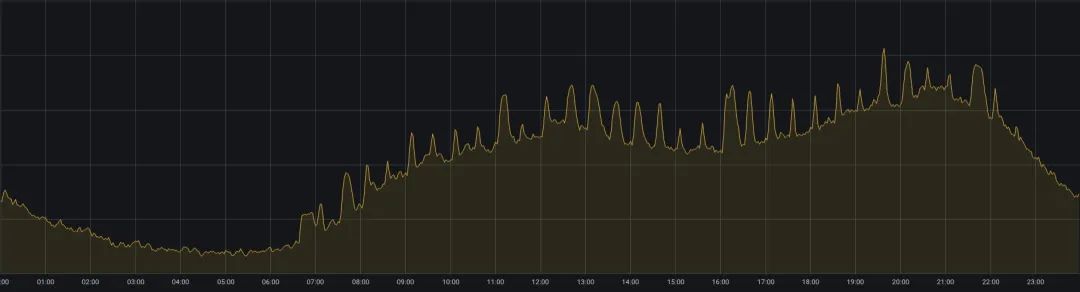
为了均衡大数据资源利用,我们将离线计算、实时计算进行混部,一定程度上缓解了白天资源空闲浪费情况,但仍无法有效地削峰填谷,大数据计算资源总体利用情况仍表现出“白天低谷、凌晨高峰”的潮汐现象,如图 1 所示。
图 1. 大数据计算集群一天内 CPU 使用变化情况
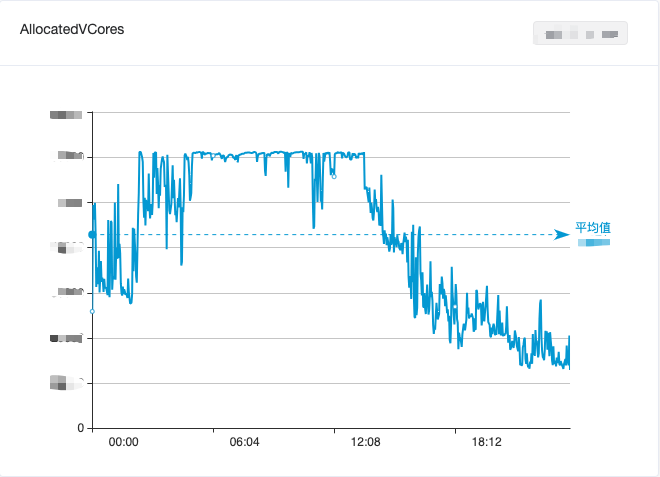
爱奇艺在线业务则面临另一个问题:服务质量与资源利用率之间的平衡。在线业务主要服务于爱奇艺视频播放等场景,午间和晚间观看视频的用户比较多,资源使用情况具备“白天高峰、凌晨低谷”的潮汐现象(如图 2 所示)。为保证高峰期间的服务质量,在线业务通常会预留较多资源,使得资源利用率非常不理想。
图 2. 在线业务集群一天内 CPU 使用变化情况
为提高利用率,爱奇艺自研的上一代容器平台采用了 CPU 静态超售策略,该方式虽然对提升利用率有明显效果,但是受限于内核能力等因素,无法避免单机上业务之间偶发的资源竞争问题,也导致了在线业务服务质量不稳定,这个问题始终无法得到妥善解决。
随着云原生化推进,爱奇艺容器平台逐渐转型到 Kubernetes(下文简称“K8s”) 技术栈。最近几年,K8s 社区陆续出现多个混部相关的开源项目,业界也有一些混部实践 [1]。在此背景下,计算平台团队将工作方向由“静态超售”调整到“动态超售 + 混部”。
大数据作为最典型的离线业务,是尝试落地混部的先行者。一方面,大数据有着较大体量,以及较稳定的计算资源需求;另一方面,大数据业务与在线业务在很多维度都能达到互补的效果,通过混部能充分提高资源利用率。
基于上述分析,爱奇艺计算平台团队与大数据团队开始了混部的探索。
混部方案设计
爱奇艺大数据体系基于开源的 Apache Hadoop 生态构建,采用了 YARN 作为计算资源调度系统,而在线业务构建在 K8s 上,如何打通两套不同的资源调度体系,是混部方案首先需要解决的。
-
方案一:直接将大数据作业(Spark、Flink 等,不支持 MapReduce)跑在 K8s 上,使用其原生的调度器
-
方案二:将 YARN 的 NodeManager(下文简称“NM”)运行在 K8s 上,大数据作业仍通过 YARN 来调度
经过慎重的考虑,我们选择了方案二,主要的原因有以下两点:
-
目前公司内绝大多数大数据计算作业的调度是基于 YARN 的,YARN 具有强大的调度功能(多租户多队列、机架感知)、优秀的调度性能(5k+ 容器/s)和完善的安全机制(Kerberos、Delegation Tokens),支持 MapReduce、Spark、Flink 等几乎所有大数据计算框架。爱奇艺大数据团队从 2014 年引入 YARN 开始,围绕其构建了一系列平台,用于开发、运维、计算治理等,为公司内部用户提供了便捷的大数据开发流程。因此与 YARN API 的兼容性是混部方案选型的重要考虑点之一
-
K8s 虽有批处理调度器,但还不够成熟,且调度性能存在瓶颈(<1k 容器/s),还不足以支撑大数据场景需求
K8s 层面,双方需要有一套标准的接口来管理和使用混部资源。社区中有很多优秀项目,如阿里巴巴开源的 Koordinator [2]、腾讯开源的 FinOps 项目 Crane [3]、字节跳动开源的项目 Katalyst [4] 等。其中,Koordinator 与龙蜥操作系统(爱奇艺正在尝试的 CentOS 替代者之一)拥有“天然”的适配能力,可以协作实现在线业务负载监测、空闲的资源超分、任务分级调度、在离线工作负载 QoS 保障等,契合爱奇艺需求。
基于上述技术选型,我们通过深度改造,将 YARN NM 容器化后运行在 K8s Pod 中,并可实时感知 Koordinator 动态变化的超分计算资源,从而实现自动的横向及纵向扩缩容,最大化利用混部资源。
混部调度策略演进
大数据和在线业务的混部经历了多个阶段的技术演进,下文我们将详细介绍。
阶段一:夜间分时复用
为了快速验证方案,我们首先完成了 NM on K8s Pod 的容器化改造(该阶段尚未采用 Koordinator),作为弹性节点扩容到已有的 Hadoop 集群。在大数据层面,这些 K8s NM 与其他物理机上的 NM 一起由 YARN 统一调度。这些弹性节点每天定时启停,只在 0 - 9 点之间运行。
在这个阶段,我们完成了 20 多项改造,下面列举 5 个主要的改造点:
改造点 1:固定 IP 池
传统 NM 部署在物理机上,机器的 IP 和域名固定,在 YARN ResourceManager(下文简称“RM”) 上配置节点白名单(slaves 文件)以允许该节点加入集群。同时 YARN 集群通过 Kerberos 来实现安全认证,在部署前需要在 Kerberos KDC 生成 keytab 文件,并分发到 NM 节点上。
为了适配 YARN 的白名单、安全认证机制,自建集群我们使用了自研的静态 IP 功能,每一个静态 IP 会有对应的 K8s StaticIP 资源,以记录 Pod 和 IP 的对应关系,同时基于公有云集群我们也会部署自研的 StaticIP CRD, 并针对每一个静态 IP 创建 StaticIP 资源,从而对 YARN 提供用法与自建集群一致的固定 IP 池。基于固定 IP 池内 IP 为其提前创建好 DNS 记录、keytab 文件,这样在 NM 启动时便可快速获取所需的配置。
改造点 2:Elastic YARN Operator
为了让用户对引入弹性节点无感知,我们将弹性 NM 加入到已有的 Hadoop YARN 集群。考虑到后期混部动态感知资源的复杂性,我们选择了自研 Elastic YARN Operator,用于更好地管理弹性 NM 的生命周期。
在这一阶段,Elastic YARN Operator 支持的策略有:
-
按需启动:应对离线任务的突发流量,包括寒暑假、节假日、重要活动等场景
-
周期性上下线:利用在线服务每天凌晨的资源利用率低谷期,运行大数据任务
改造点 3:Node Label - 弹性与固定资源隔离
由于 Flink 等大数据实时流计算任务是 7x24 小时不间断常驻运行的,对 NM 的稳定性的要求比批处理更高,弹性 NM 节点的缩容或资源量调整会使得流计算任务重启,导致实时数据波动。为此,我们引入了 YARN Node Label 特性 [5],将集群分为固定节点(物理机 NM)和弹性节点(K8s NM)。批处理任务可以使用任意节点,流任务则只能使用固定节点运行。
此外,批处理任务容错的基础在于 YARN Application Master 的稳定性。我们的解决方案是,给 YARN 新增了一个配置,用于设置 Application Master 默认使用的 label,确保 Application Master 不被分配到弹性 NM 节点上。这一功能已经合并到社区:
YARN-11084
、
YARN-11088
。
改造点 4:NM Graceful Decommission
我们采用了弹性节点固定时间上下线,来对在离线资源进行削峰填谷。弹性 NM 的上线由 YARN Operator 来启动,一旦启动完成,任务就可被调度上。弹性 NM 的下线则略微复杂些,因为任务仍然运行在上面,我们需要尽可能保证任务在下线的时间区间内已经结束。
例如我们周期性部署策略为:0 - 8 点弹性 NM 上线,8 - 9 点为下线时间区间,9 - 24 点为节点离线状态。通过使用 YARN graceful decommission [6] 的机制,将增量 container 请求避免分配到 decommissioning 的节点上,在下线时间区间内等待任务缓慢结束即可。
但是在我们集群中,批处理任务大部分是 Spark 3.1.1 版本,因为 Spark 申请的 YARN container 是作为 task 的 executor 来使用,在大部分情况下,1 个小时的下线区间往往是不够的。因此我们引入了 SPARK-20624 的一系列优化 [7],通过 executor 响应 YARN decommission 事件来将 executor 尽可能快速退出。
改造点 5:引入 Remote Shuffle Service - Uniffle
Shuffle 作为离线任务中的重要一环,我们采用 Spark ESS on NodeManager 的部署模式。但在引入弹性节点后,因为弹性 NM 生命周期短,无法保证在 YARN graceful decommmission 的时间区间内,任务所在节点的 shuffle 数据被消费完,导致作业整体失败。
基于这一点,我们引入了 Apache Uniffle (incubating) [8] 实现 remote shuffle service 来解耦 Spark shuffle 数据与 NM 的生命周期,NM 被转变为单纯的计算,不存储中间 shuffle 数据,从而实现 NM 快速平滑下线。
另外一方面,弹性 NM 挂载的云盘性能一般,无法承载高 IO 和高并发的随机读写,同时也会对在线服务产生影响。通过独立构建高性能 IO 的 Uniffle 集群,提供更快速的 shuffle 服务。
爱奇艺作为 Uniffle 的深度参与者,贡献了 100+ 改进和 30+ 特性,包括 Spark AQE 优化 [9] 、Kerberos 的支持 [10] 和超大分区优化 [11] 等。
阶段二:资源超分
在阶段一,我们仅使用 K8s 资源池剩余未分配资源实现了初步的混部。为了最大限度地利用空闲资源,我们引入 Koordinator 进行资源的超分配。
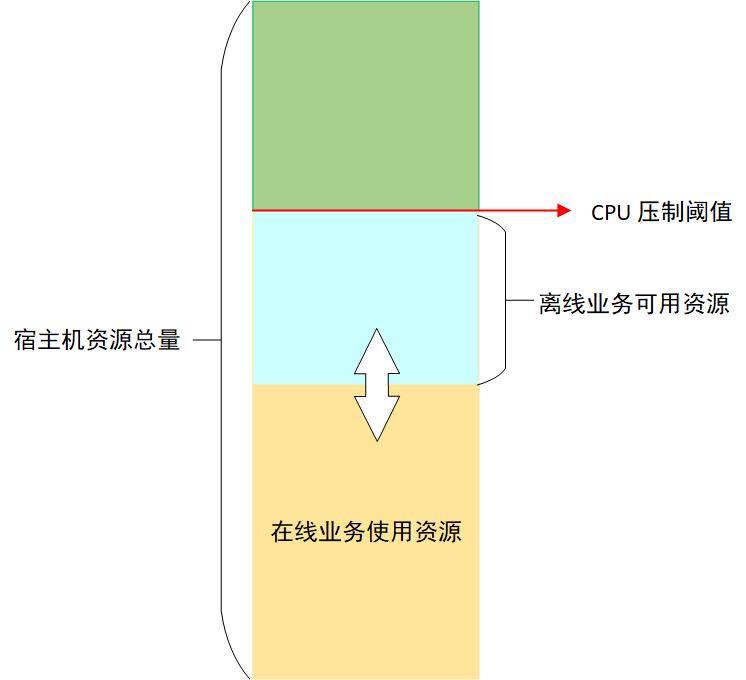
我们对弹性 NM 的资源容量采用了固定规格限制:10 核 batch-cpu、30 GB batch-memory(batch-cpu 和 batch-memory 是 Koordinator 超分出来的扩展资源),NM 保证离线任务使用的资源总量不会超过这些限制。
为了保证在线业务的稳定性,Koordinator 会对节点上离线任务能够使用的 CPU 进行压制 [12],压制结果由压制阈值和在线业务 CPU 实际用量(不是 request 请求)的差值决定,这个差值就是离线业务能够使用的最大 CPU 资源,由于在线业务 CPU 实际使用量不断变化,所以离线业务能够使用的 CPU 也在不断变化,如图 3 所示:
对离线任务的 CPU 压制保证了在线业务的稳定性,但是离线任务执行时间就会被拉长。如果某个节点上离线任务被压制程度比较严重,就可能会导致等待的发生,从而拖慢整体任务的运行速度。为了避免这种情况,Koordinator 提供了基于 CPU 满足度的驱逐功能 [13],当离线任务使用的 CPU 被压制到用户指定的满足度以下时,就会触发离线任务的驱逐。离线任务被驱逐后,可以调度到其他资源充足的机器上运行,避免等待。
在经过一段时间的测试验证后,我们发现在线业务运行稳定,集群 CPU 7 天平均利用率提升了 5%。但是节点上的 NM Pod 被驱逐的情况时有发生。NM 被驱逐之后,RM 不能及时感知到驱逐情况的发生,会导致失败的任务延迟重新调度。为了解决这个问题,我们开发了 NM 动态感知节点离线 CPU 资源的功能。
阶段三:从夜间分时复用到全天候实时弹性
与其触发 Koordinator 的驱逐操作,不如让 NM 主动感知节点上离线资源的变化,在离线资源充足时,调度较多任务,离线资源不足时,停止调度任务,甚至主动杀死一些离线 container 任务,避免 NM 被 Koordinator 驱逐。
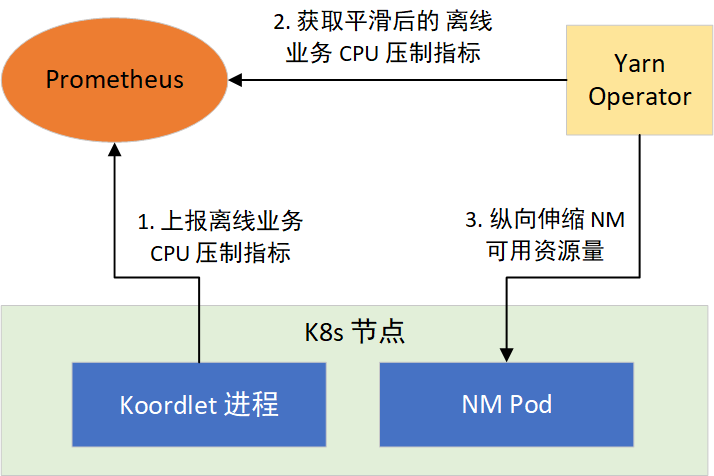
根据这个思路,我们通过 YARN Operator 动态感知节点所能利用的资源,来纵向伸缩 NM 可用资源量。分两步实现:1)提供离线任务 CPU 压制指标;2)让 NM 感知 CPU 压制指标,采取措施。如图 4 所示:
CPU 压制指标
Koordinator 的 Koordlet 组件,运行于 K8s 的节点上,负责执行离线任务 CPU 压制、Pod 驱逐等操作,它以 Prometheus 格式提供了 CPU 压制指标,经过采集后就可以通过 Prometheus 对外提供。CPU 压制指标默认每隔 1 秒更新 1 次,会随着在线业务负载的变化而变化,波动较大。而 Prometheus 的指标抓取周期一般都大于 1 秒,这会造成部分数据的丢失,为了平滑波动,我们对 Koordlet 进行了修改,提供了 1 min、5 min、10 min CPU 压制指标的均值、方差、最大值和最小值等指标供 NM 选择使用。
YARN Operator 动态感知和纵向伸缩
在 NM 常驻的部署模式下,YARN Operator 提供了新的策略。通过在 YARN Operator 接收到当前部署的节点 10 min 内可利用的资源指标,用来决策是否对所在宿主机上的 NM 进行纵向伸缩。
对于扩容,一旦超过 3 核,则向 RM 进行节点的资源更新。扩容过程如图 5 所示:
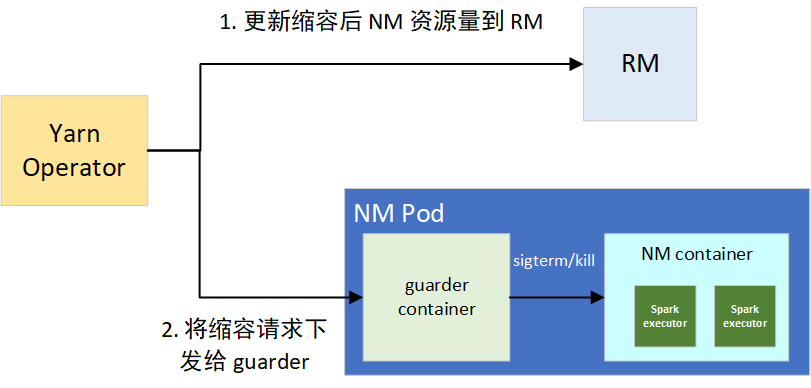
缩容的话,如果抑制率控制在 10% 以内的波动,我们默认忽略。一旦超过阈值,则会触发缩容操作,分为两个步骤:1)更新节点在 RM 上的可用资源,用来堵住增量的 container 分配需求;2)将缩容请求下发给 NM 的 guarder sidecar 容器,来对部分资源超用的 container 的平滑和强制下线,避免因占用过多 CPU 资源导致整个 NM 被驱逐。
guarder 在拿到目标可用资源后,会对当前所有的 YARN container 进程进行排序,包括框架类型、运行时长、资源使用量三者,决策拿到要 kill 的进程。在 kill 前,会进行 SIGPWR 信号的发送,用来平滑下线任务,Spark Executor 接收到此信号,会尽可能平滑退出。缩容过程如图 6 所示:
通常节点的资源量变动幅度不是很大,且 NM 可使用的资源量维持在较高的水平(平均有 20 core),部分 container 的存活周期为 10 秒级,因此很快就能降至目标可用资源量值。涉及到变动幅度频繁的节点,通过 guarder 的平滑下线和 kill 决策,container 失败数非常低,从线上来看,按天统计平均 force kill container 数目为 5 左右,guarder 发送的平滑下线信号有 500+,可以看到效果比较好。
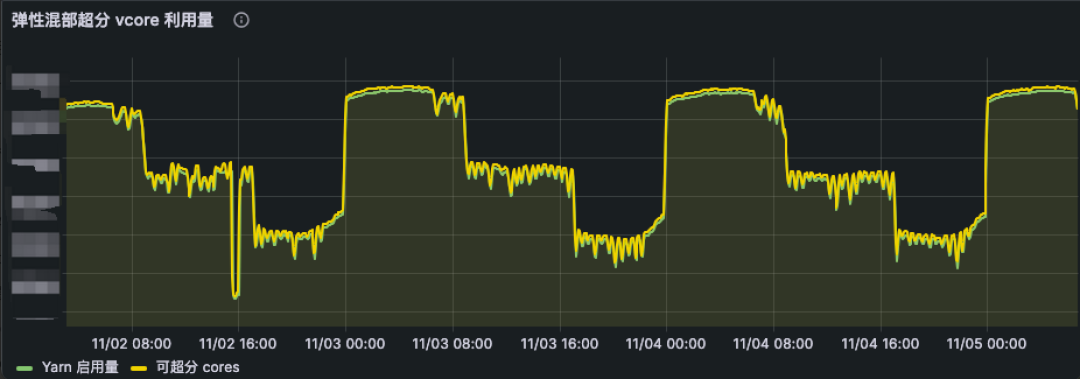
在离线 CPU 资源感知功能全面上线后,NM Pod 被驱逐的情况基本消失。因此,我们逐步将混部时间由凌晨的 0 点至 8 点,扩展到全天 24h 运行,并根据在线业务负载分布情况,在一天的不同时段采用不同的 CPU 资源超分比,从而实现全天候实时弹性调度策略。伴随着全天 24h 的稳定运行,集群 CPU 利用率再度提升了 10%。从线上混部 K8s 集群来看(如图 7 所示),弹性 NM 的 vcore 使用资源量(绿线)也是动态贴合可超分的资源(黄线)。
阶段四:提升资源超分率
为了提供更多的离线资源,我们开始逐步调高 CPU 资源的超分比,而 NM Pod 被驱逐的情况再次发生了,这一次的原因是内存驱逐。我们将物理机器的内存超分比设置为 90%,从集群总体情况看,物理机器上的内存资源比较充足,刚开始我们只关注了 CPU 资源,没有关注内存资源。而 NM 的 CPU 和内存按照 1:4 的比例来使用,随着 CPU 超分比的提高,YARN 任务需要的内存也在提升,最终当 K8s 节点内存使用量超过设定的阈值时,就会触发 Koordinator 的驱逐操作。
经过观察,我们发现内存驱逐在某些节点上发生的概率特别高,这些节点的内存比其他节点内存小,而 CPU 数量是相同的,因此这些节点在 CPU 超分比相同的情况下,更容易因为内存原因被驱逐,它们能提供的离线内存更少。因此,guarder 容器也需要感知节点的离线内存资源用量,并根据资源用量采取相应的措施,这个过程与 CPU 离线资源的感知一样的,不再赘述。
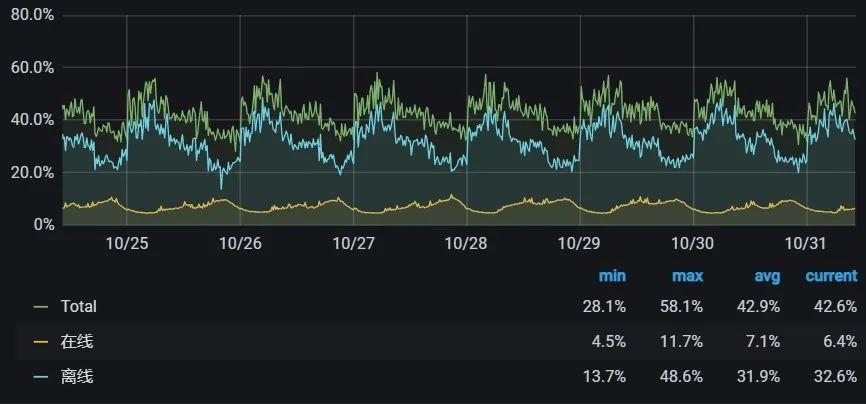
内存感知功能上线后,我们又逐步提升了 CPU 的超分比,当前在线业务集群的 CPU 利用率已经提升到全天平均 40%+、夜间 58% 左右。
效果
通过大数据离线计算与在线业务的混部,我们将在线业务集群 CPU 平均利用率从 9% 提升到 40%+,在不增加机器采购的同时满足了部分大数据弹性计算的资源需求,每年节省数千万元成本。
同时,我们也将这套框架应用到大数据 OLAP 分析场景,实现了 Impala/Trino on K8s 弹性架构,满足数据分析师日常动态查询需求,支持了寒暑假、春晚直播、广告 618 与双 11 等重要活动期间临时大批量资源扩容需求,保障了广告、BI、会员等数据分析场景的稳定、高效。
未来计划
当前,大数据离在线混部已稳定运行一年多,并取得阶段性成果,未来我们将基于这套框架进一步推进大数据云原生化:
-
完善离在线混部可观测性:建立精细化的 QoS 监控,保障在线服务、大数据弹性计算任务的稳定性。
-
加大离在线混部力度:K8s 层面,继续提高宿主机资源利用率,提供更多的弹性计算资源供大数据使用。大数据层面,进一步提升通过离在线混部框架调度的弹性计算资源占比,节省更多成本。
-
大数据混合云计算:目前我们主要使用爱奇艺内部的 K8s 进行混部,随着公司混合云战略的推进,我们计划将混部推广到公有云 K8s 集群中,实现大数据计算的多云调度。
-
探索云原生的混部模式:尽管复用 YARN 的调度器能让我们快速利用混部资源,但它也带来了额外的资源管理和调度开销。后续我们也将探索云原生的混部模式,尝试将大数据的计算任务直接使用 K8s 的离线调度器进行调度,进一步优化调度速度和资源利用率。
参考资料
[1] 一文看懂业界在离线混部技术. https://www.infoq.cn/article/knqswz6qrggwmv6axwqu
[2] Koordinator: QoS-based Scheduling for Colocating on Kubernetes. https://koordinator.sh/
[3] Crane: Cloud Resource Analytics and Economics in Kubernetes clusters. https://gocrane.io/
[4] Katalyst: a universal solution to help improve resource utilization and optimize the overall costs in the cloud. https://github.com/kubewharf/katalyst-core
[5] Apache Hadoop YARN - Node Labels. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
[6] Apache Hadoop YARN - Graceful Decommission of YARN Nodes. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html
[7] Apache Spark - Add better handling for node shutdown. https://issues.apache.org/jira/browse/SPARK-20624
[8] Apache Uniffle: Remote Shuffle Service. https://uniffle.apache.org/
[9] Apache Uniffle - Support getting memory data skip by upstream task ids. https://github.com/apache/incubator-uniffle/pull/358
[10] Apache Uniffle - Support storing shuffle data to secured dfs cluster. https://github.com/apache/incubator-uniffle/pull/53
[11] Apache Uniffle - Huge partition optimization. https://github.com/apache/incubator-uniffle/issues/378
[12] Koordinator - CPU Suppress. https://koordinator.sh/docs/user-manuals/cpu-suppress/
[13] Koordinator - Eviction Strategy based on CPU Satisfaction. https://koordinator.sh/docs/user-manuals/cpu-evict/

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。