
作者:荆磊
背景
ELK (Elasticsearch、Logstash、Kibana) 是当下开源领域主流的日志解决方案,在可观测场景下有比较广泛的应用。
随着数字化进程加速,机器数据日志增加,自建 ELK 在面临大规模数据、查询性能等方面有较多问题和挑战。如何解决可观测数据的低成本、高可用是一个新的话题。
SLS 是由阿里云推出的云上可观测 Serverless 产品,在功能层面对标 ELK,并且提供了高可用、高性能、低成本的方案。现在 SLS 推出了开源兼容(Elasticsearch、Kafka 等)能力,可帮助自建 ELK 场景平滑切换到 SLS 上来,在保留开源使用习惯的同时,享受到云上日志的便捷和低成本。
SLS 与 Elasticsearch 的前世今生

Elasticsearch 是从 2010 年开始写下第一行代码,整体使用 Java 语言,在 2012 年开始正式成立公司运作。它的底层是 Lucene 全文索引引擎,早期 ES 的主要场景是做企业搜索(比如文档搜素、商品搜索等)。近几年可观测场景数据日益增加,Elasticsearch 正式进入可观测领域。
SLS 自 2012 年开始就面向可观测场景,从阿里云内部开始孵化,依托于阿里云飞天的底座构建,使用的是 C++ 语言,以其高性能、高可靠等特性赢得了大量内部客户认可。于 2017 年开始在阿里云上正式对外提供服务。
可以看到,Elasticsearch 和 SLS 的产品历程都超过 10 年。其中,SLS 一直在可观测领域深耕,通过底层优化持续在可观测领域提供高质量服务。
阿里云 SLS 核心功能架构
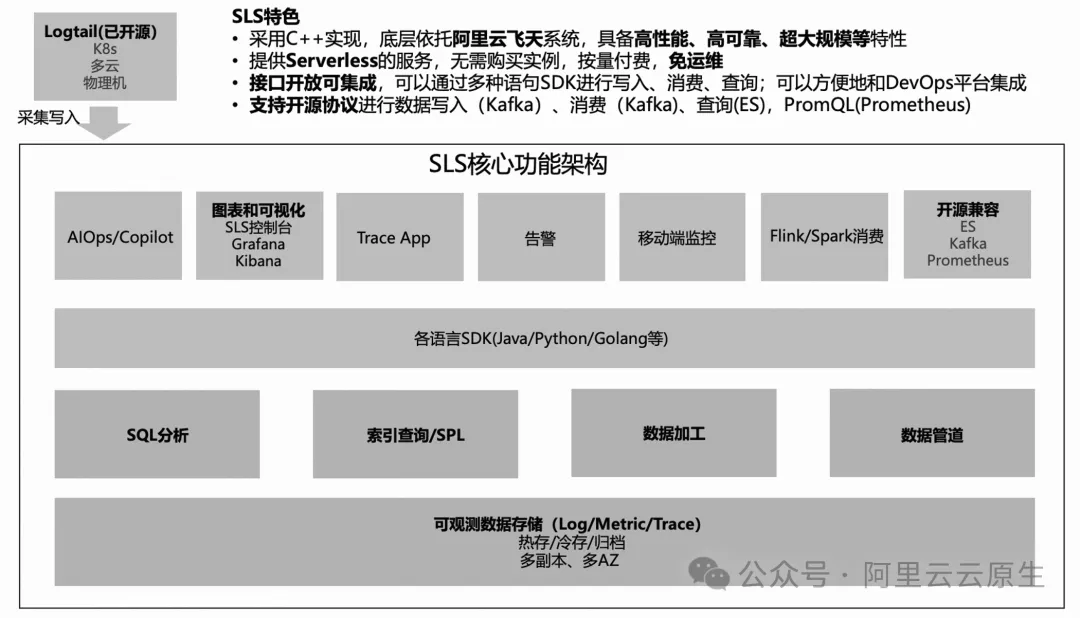
SLS 底层使用阿里云飞天盘古分布文件系统存储,支持各类可观测数据(Log/Metric/Trace)的存储格式,默认使用多副本备份确保高可用,同时也支持多种存储规格(热存、冷存、归档)。在存储层之上提供各类查询和计算的能力,包括:
- SQL 分析标准 SQL92 支持
- 索引查询和 SPL,索引查询提供和 Lucene 类似的查询能力
- 数据加工 方便对上报后的日志进行二次加工
- 数据管道 提供类似 Kafka 的消费、写入能力
在基础的存储、计算能力之前也提供了各类语言 SDK,方便业务集成。同时 SLS 也提供了垂直场景开箱即用的功能,包括 AIOps(异常检测、根因分析)、Copilot(支持用自然语言的方式查询数据)、告警、移动端监控、Flink、Spark 的消费 lib 等。另外,SLS 提供开源兼容的能力,可以很方便地和现有的开源生态进行集成,包括 Elasticsearch、Kafka 等,通过使用 SLS 兼容能力,可以很方便地将自建系统迁移到 SLS 上来。
SLS 与 Elasticsearch 功能对比
| 对比项 | SLS | 开源自建 ELK |
|---|---|---|
| 采集能力 | iLogtail(C++ 实现、高性能、开源) | Beats 系列、Logstash(性能较低) |
| 存储能力 | 单 Logstore 支持 PB 级 | 单 Index 百 GB 级 数据量大需要拆分 Index |
| 查询能力 | 支持 | 支持 |
| 无索引查询 | 支持 SPL 方式做无索引查询 | 不支持 |
| SQL 分析 | 支持标准 SQL 92 语法 | 不完整的 SQL 支持 |
| 流式消费 | 支持(支持 Kafka 协议、SLS 原生协议) Flink/Spark 消费 | 不支持 |
| 告警 | 原生支持告警 | 需要 XPack 启用 Kibana Watch 或者第三方(Grafana 告警、ElasticAlert 等) |
| 可视化 | SLS 原生控制台/Grafana/Kibana | Kibana、Grafana |
| DevOps 平台集成 | SLS 控制台页面可直接嵌入到 DevOps 平台 | Kibana 有限的嵌入能力,主要依赖 SDK API 做二次开发 |
| AIOps | SLS 原生支持 AIOps | 需 XPack 启用 |
SLS 原生提供了丰富的功能,基于 Serverless 的特性,这些在云上可以做到一键启用。
SLS 与 Elasticsearch 的可运维性对比
| 对比项 | SLS | 开源自建 ELK |
|---|---|---|
| 容量规划 | Serverless 无需关注 | 需关注容量•如果磁盘满将直接影响可用性•ES 写入性能差,需要为高峰预留足够多的资源 |
| 机器运维 | Serverless 无需关注 | 需要关注机器可用性,如果批量宕机将影响可用性 |
| 性能调优 | 只需扩 Logstore Shard 即可 | 需要专业的 Elasticsearch 领域支持,可能需要社区支持 |
| 版本升级 | Serverless 无需关注(SLS 后台持续迭代,提升性能) | 开源 ELK 不保证版本兼容性,可能因为升级导致不可用 |
| 数据可靠性 | 底层使用业界领先的飞天盘古存储,默认 3 副本存储 | 按需设置副本数;如果是单副本,遇意外数据损坏,可恢复概率低 |
| 服务 SLA | SLS 保证 | 专人或专门团队保证,可能因为大的 Query 导致集群不可用 |
由于 SLS 是云上 Serverless 服务,无需购买实例即可使用,免除了运维层面的烦恼。而自建 ELK 需要关注诸多运维层面的问题。 对于使用量较大的场景,比如数据量到 10TB 以上,往往需要专业的人来做 Elasticsearch 的维护和调优。
SLS 与 Elasticsearch 的性能对比

这里在实验室环境中做了一下简单的查询分析能力的测试。在 10 亿级别的数据量中做查询和分析,SLS 响应时间在秒级,而 Elasticsearch 随着并发增大,响应时间有明显上升,并且在整体延时上比 SLS 高。这里还需要提到 Elasticsearch 的写入性能问题,测下来单核能力在 2MB/s 左右,而 SLS 单 Shard 写入能可以支持到 10MB/s ,通过扩大 Logstore 的 Shard 数可以轻松地提升写入性能。
SLS 与 Elasticsearch 的成本对比

上面是一张成本对比图,Elasticsearch 的机器数基本上是由峰值的写入量决定的。对于 Elasticsearch 而言,写入是最大的瓶颈;Elasticsearch 存储空间需要考虑索引膨胀率和一定的空间预留。不然可能因为磁盘满导致服务不可用。
对于 SLS 而言,作为 Serverless 服务,它提供按写入量计费的方式,按照目前 0.4 元/GB 的写入费用估算,在 10TB 每天的场景下,30、90、180 天下的成本相对 Elasticsearch 有明显优势。其中,SLS 费用预估时按照下面的方式测算:
- SLS 按流量计费 0.4 元/GB(送 30 天存储)
- 90 天存储按照 30 天热 + 60 天低频
- 180 天存储按照 30 天热 + 60 天低频 + 90 天归档
那么是不是只有数据量大的情况下 SLS 才换算呢?答案是否定的,考虑一个场景,如果每天数据量是 10GB,需要保留 30 天,那么每天的费用是 4 元,即每个月 120 元。需要一台 ECS 至少 2core 4g 磁盘空间 400GB(300/0.75 空间预留), 每月持有费用是大于 200 的。
SLS 开源兼容能力
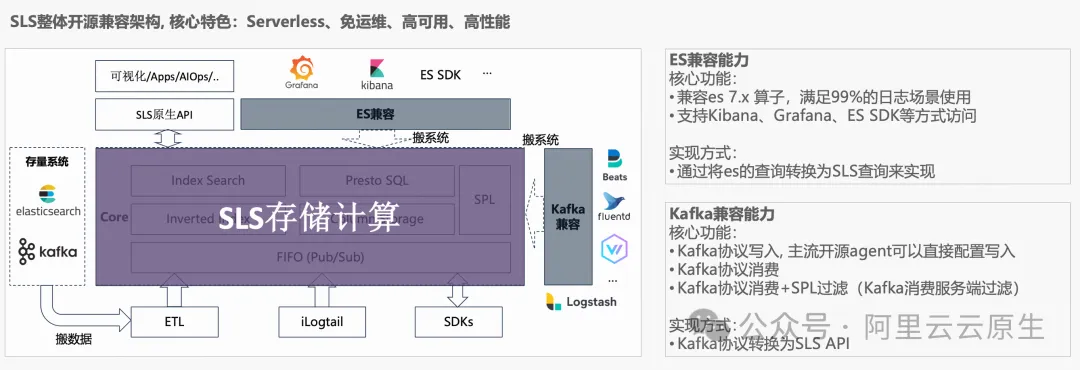
SLS 的 Elasticsearch 兼容、Kafka 兼容能力是基于 SLS 底层存储计算能力构建的。本质上是将 Elasticsearch、Kafka 的请求转换为 SLS 的协议进行请求,因此一份数据不管用什么方式写入 SLS,都可以用 Elasticsearch 兼容的方式来查询,也可以用 Kafka 兼容的方式来消费。
以前,对于 Kafka+ELK 的架构,往往需要较多机器做数据同步(LogStash、HangOut 等);现在使用一个 SLS 完全不需要数据同步,就可以用不同的协议来访问。简单来说就是一份数据提供了多种协议方式。 通过 Kafka 协议写入的数据可以用 ES 协议来立马查询;同样通过 Elasticsearch 协议写入的数据,可以用 Kafka 立马消费。使用 SLS 的开源兼容能力,相当于同时拥有一个 Serverless 的 Kafka 和 Elasticsearch,并且是按量付费,无需购买实例。
使用 Kibana 访问 SLS
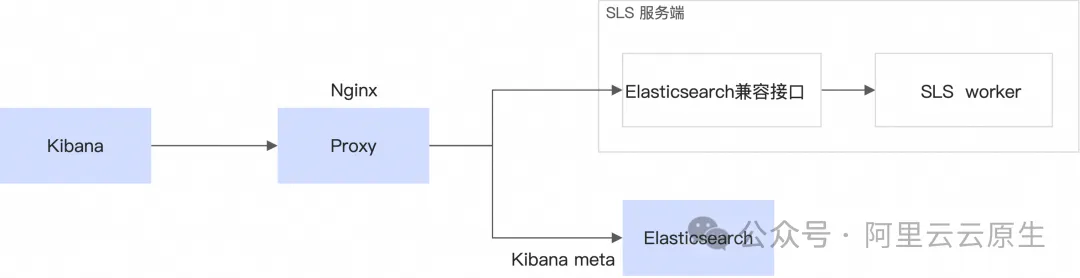
用 Kibana 访问 SLS 需要 3 个组件:
- Kibana
- Proxy 用于区分 Kibana 的元数据请求和日志数据请求
- Elasticsearch 只用于存 Kibana 的 meta 数据,资源占用比较小,用一台小规格 ECS 即可满足
Kibana 将元数据存在 Elasticsearch 中,会有 meta 更新的操作。 当前 SLS 提供的是不可修改的存储,因此 meta 类的数据还需要一个小的 Elasticsearch 来承载。这个 Elasticsearch 只处理 meta 请求,因此负载和数据存储量非常低,用小规格 ECS 可以满足。
使用 Kibana 访问 SLS 具体可以参考对接 Kibana [ 1] 。
使用 Grafana Elasticsearch 插件访问 SLS

除了 Kibana 的方式来做日志可视化,也可以用 Grafana 的 Elasticsearch 插件来访问 SLS。使用 Grafana Elasticsearch 插件访问 SLS Elasticsearch 兼容接口,有2个好处:
- 不需要写 SQL 语句,通过界面操作即可完成图表可视化
- 不需要在 Grafana 额外安装插件
用 Grafana 自带的 Elasticsearch 插件访问 SLS 具体可以参考使用 Grafana ES 插件访问 SLS [ 2] 。
使用 Kafka SDK 写入/消费 SLS

使用 Kafka 官方的 SDK 可以对接 SLS 的 Kafka 兼容接口。支持 Kafka 写入和消费两种能力。
推荐使用 Kafka 官方 SDK 消费,具体可以参考 Kafka SDK 消费 SLS [ 3] 、各类 Agent 写 SLS Kafka 兼容接口 [ 4] 。
开源 ELK 的平滑迁移方案
使用双采方案进行迁移

在原先的机器上部署 SLS 的 iLogtail 采集 Agent,将业务日志使用 iLogtail 采集到 SLS 上(一份日志可以被多个 Agent 采集,不会冲突),然后使用 Elasticsearch 兼容、Kafka 兼容的能力对接原有的使用程序。通过这个方案可以很方便地做性能、数据完整性验证。在充分验证后,移除掉机器上 filebeat 的 Agent,即可完成链路切换。
使用开源 Agent 直写迁移
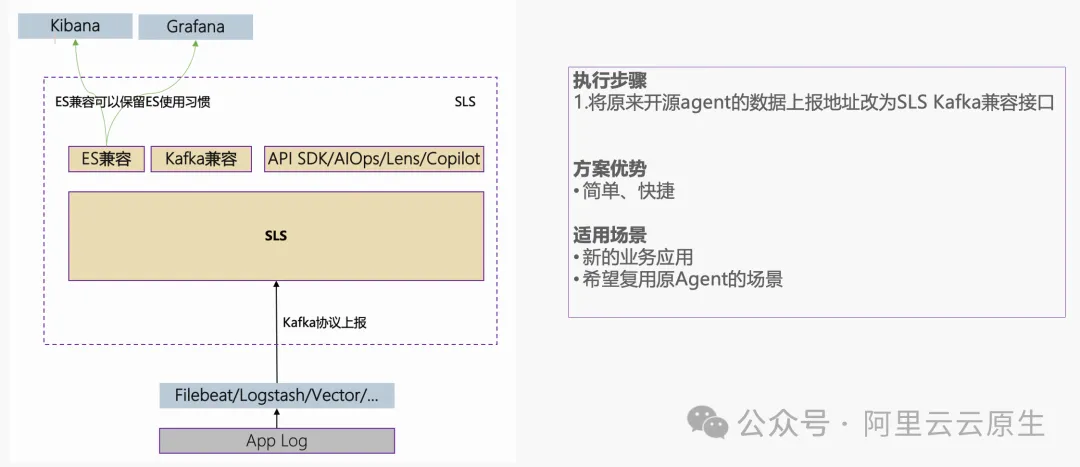
如果是新的业务或者 APP 想要尝试 SLS,没有历史包袱。但是又不想在机器上安装 iLogtail。那么可以复用原来的采集 Agent,将采集 Agent 的日志以 Kafka 协议的方式写入到 SLS。参考使用 Kafka 协议上传日志 [ 5] 。在日志写入 SLS 后,想保留开源使用习惯,可以使用 SLS 兼容接口对接 Kibana、Grafana 等可视化工具。
使用 Kafka 导入迁移
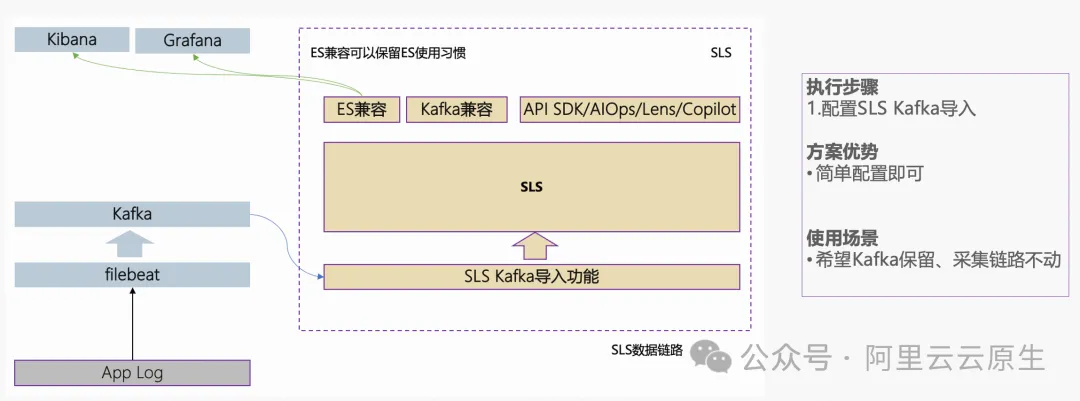
如果我们不希望动原来的采集链路,同时又要保留原 Kafka(通常是依赖 Kafka 的历史遗留程序较多,不好动),那么可以使用这个方案。使用 SLS 的 Kafka 导入功能,无需部署实例,在页面上配置即可完成 Kafka 数据导入到 SLS (支持持续导入),参考 SLS Kafka 导入 [ 6] 。将 Kafka 数据导入到 SLS 后,可以使用 SLS 开源兼容的能力保留开源使用的习惯。
使用 Elasticsearch 导入功能迁移存量数据
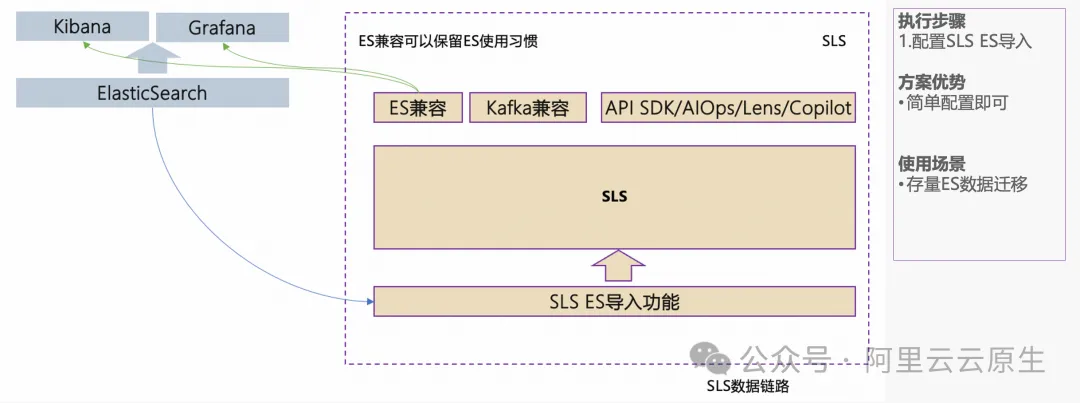
对于 Elasticsearch 中历史数据希望可以导入到 SLS 中做保留的场景,可以使用 SLS 的 Elasticsearch 导入功能,功能参考 ES 导入 [ 7] 。
总结
本文介绍了 SLS 基本能力,并和开源自建 ELK 做了对比,可以看到 SLS 相比开源 ELK 有较大优势。借助 SLS Serverless 服务能力帮助运维团队有效降低日志系统的运维压力与成本,提升日志使用的体验。现在 SLS 提供了丰富的开源兼容能力,在体验 SLS 诸多 Feature 同时,又可以保留开源使用习惯;在 ELK 日志系统切换方便又可以做到平滑迁移。综上,欢迎大家使用 SLS ,有任何问题可以通过客户群、工单来联系我们。
参考链接:
[1] 对接 Kibana
[2] 使用 Grafana ES 插件访问 SLS
[3] Kafka SDK 消费 SLS
https://help.aliyun.com/zh/sls/user-guide/overview-of-kafka-consumption?spm=a2c4g.11186623.0.i6
[4] 各类 Agent 写 SLS Kafka 兼容接口
[5] 使用 Kafka 协议上传日志
[6] SLS Kafka 导入
[7] ES 导入
相关链接:
-
SLS 服务介绍
-
SLS 的 ES 兼容使用文档
https://help.aliyun.com/zh/sls/user-guide/compatibility-between-log-service-and-elasticsearch
-
SLS 的 Kafka 兼容使用文档
https://help.aliyun.com/zh/sls/user-guide/overview-of-kafka-consumption