

该图对于我的理解就是假设我们训练了一个数据量非常大的模型,然后从这个模型中采样一种分类的特征与少样本数据特征进行融合,等于我们再推理的时候,这种模型就可以推理少样本数据的类别,虽然少样本数据可能是鸭子,但是是跟狗的特征融合的,那么就可以把鸭子推理成狗。这里推理成狗是因为原模型的标签是狗,你也可以改成鸭子。
上图中的S是多分类数据样本(图中的support images)的特征,\(F_S\)是一个支持(support)特征编码器,其实就是一个神经网络的特征提取,一般的网络到这里就输出给softmax进行分类判断的;Q是少样本(图中的query image)的特征,\(F_Q\)是一个查询(query)特征编码器,意思跟\(F_S\)是一个意思。\(F_{enc}\)就是一个变分自编码器,它将多分类样本数据特征给编码成一个正态分布,这里会有一个KL散度的损失函数,意思就是使得\(F_{enc}\)生成的分布趋近于标准正态分布。
latent_loss = KL-Divergence(latent_variable, unit_gaussion)
latent_variable是 \(F_{enc}\)生成的分布,unit_gaussion是标准正态分布。
这样就将支持样本的特征转化为类别的分布,由于是标准正态分布,所以该类别特征分布不偏向于特定样本,因此从分布中采样的特征对样本的方差有较好的鲁棒性。此时会从正态分布中通过变分推理(variational inference)采样(sampling)出Z。最后通过解码器\(F_{dec}\)解码出与S相对应的重构的支持样本的特征S'。
这里的\(L_{rec}\)是一个均方根损失,是生成的图像特征S'与原始的图像特征S进行比较
generation_loss = mean(square(generated_image - real_image))
这里除了这两种损失之外还有一种一致性损失\(L_{cons}\),它表示生成的S'的分布与原始S的分布保持一致。
\(L_{cons}=L_{CE}(F_{cls}^{S'}(S'),c)\)
这里的\(L_{CE}\)是交叉熵损失函数,\(F_{cls}^{S'}\)是生成的图像特征S'的类别分布,它的主要作用就是以特征分布为依据,来进行类别分布的转化;c是原始图像特征S的类别分布(打过标签的分布)。
这里我们来解释一下什么是特征分布,特征分布是区别于样本分布的,样本分布就是你的数据集中各个种类占总数的占比,如某一数据集中有三种鸢尾花,它们的比例是1:1:1,那么这就是一种均匀分布。

特征分布有两种,第一种指的是某个特征在整个数据集上的分布情况。

假设我们需要识别的是猫这个种类(无论是英短,波斯,金渐层,银渐层),首先卷积神经网络会提取它们的特征,如毛发、眼睛、胡子、尾巴,耳朵......(神经网络提取出来的特征不一定是我们人类能理解的,这里只是打个比方),假设有一个特征是毛发长度(该数据集并不只包含猫,还有其他的种类),它在整个数据集中满足以下分布

那么该特征的总体分布(整个数据集中)就是一个正态分布的。整个数据集上的特征分布有助于我们理解特征的总体特性,例如它的变异性、是否存在偏斜等。
第二种就是不同类别的特征分布,这个则更为重要,它是模型区分不同类别的重要标志,如上面的例子,单以猫的毛发长度的分布可能就是另外一种分布,而狗的毛发长度的分布又是一种不同的分布,虽然它们可能都是正态分布。如果一个特征在不同的类别上有明显不同的分布,那么这个特征对于分类任务来说是有用的。相反,如果一个特征在所有类别上的分布都是相似的,那么它对于分类任务的帮助就很有限。
神经网络学习的本质就是学习数据的分布(此处可以参考AI的数学理论基础 极大似然估计法),这个分布指的就是特征分布,深度学习模型通过多层非线性变换来学习数据的高级表示。如果不同类别的数据在特征空间中有明显的分布差异,模型就更容易区分它们。
对于少样本数据来说,它的查询特征Q会进行变分特征聚合(Variational Feature Aggregation)到A,A是一个通道融合的过程,它是将Q与变分特征Z进行融合。具体来说就是,将给定查询类(少样本类)i的查询特征\(Q_i\)和支持类j的支持特征\(S_j\),首先估计\(S_j\)的正态分布\(N(μ_j,σ_j)\),并采样变分特征
\(Z_j=μ_j+σ_j\)
然后通过以下公式将\(Q_i\)与\(Z_j\)进行融合
\(Q_{ij}=A(Q_i,Z_j)=Q_i\)![]() \(sig(Z_j)\)
\(sig(Z_j)\)
其中![]() 表示通道乘法,sig是sigmoid。在训练阶段,会随机选择一个支持类的特征\(S_j\) 进行聚合;在测试阶段,会将所有支持类的特征取平均值
表示通道乘法,sig是sigmoid。在训练阶段,会随机选择一个支持类的特征\(S_j\) 进行聚合;在测试阶段,会将所有支持类的特征取平均值![]() ,并估计其正态分布\(N(μ_j,σ_j)\),即
,并估计其正态分布\(N(μ_j,σ_j)\),即![]() 。
。
\(F_D\)为对该融合特征进行检测的检测头,最后会有一个分类损失\(L_{cls}\),这也是一个交叉熵损失。
\(L_{cls}=L_{CE}(F_{cls}^{Q_{ij}}(Q_{ij}),c)\)
这里\(F_{cls}^{Q_{ij}}(Q_{ij})\)是融合特征\(Q_{ij}\)的类别分布,c是原始图像特征S的类别分布。
\(F_D\)的检测头包含一个共享特征提取器\(F_{share}\)和两个独立的子网络——分类子网络\(F_{cls}\)和回归子网络\(F_{reg}\),聚合后的特征\(Q_{ij}\)被输入到检测子网络中进行目标分类和边界框回归,分类任务需要平移不变特征,回归任务需要平移协变特征,由于支持特征表示的是类别的中心,具有平移不变性,因此聚合后的特征会损害回归任务。故这里的两个任务不会都采用聚合特征\(Q_{ij}\),则有
- \(p=F_{cls}(F_{share}^{cls}(Q_{ij}))\)
- \(b=F_{reg}(F_{share}^{reg}(Q))\)
这里p表示分类分数,b为预测边界框。
VAE
这里需要说明的是VAE本身就是一种生成式网络结构。

假设我们需要生成一大堆的类似于上图的手写数字图片(同分布),那么我们需要该图的特征,如果是人工来定义的话,我们可能会定义:数字、粗细、倾斜度....;当然我们不可能用人工的方式来定义,而是使用神经网络来提取该图的特征。我们假设提取的特征的特征向量为S,因为我们要生成大量类似的图片,而不是将原图给还原出来,所以单一的特征向量肯定是不行的,我们需要根据这个特征向量来生成一种分布,而标准正态分布N(0,1)一般被验证是最好的。
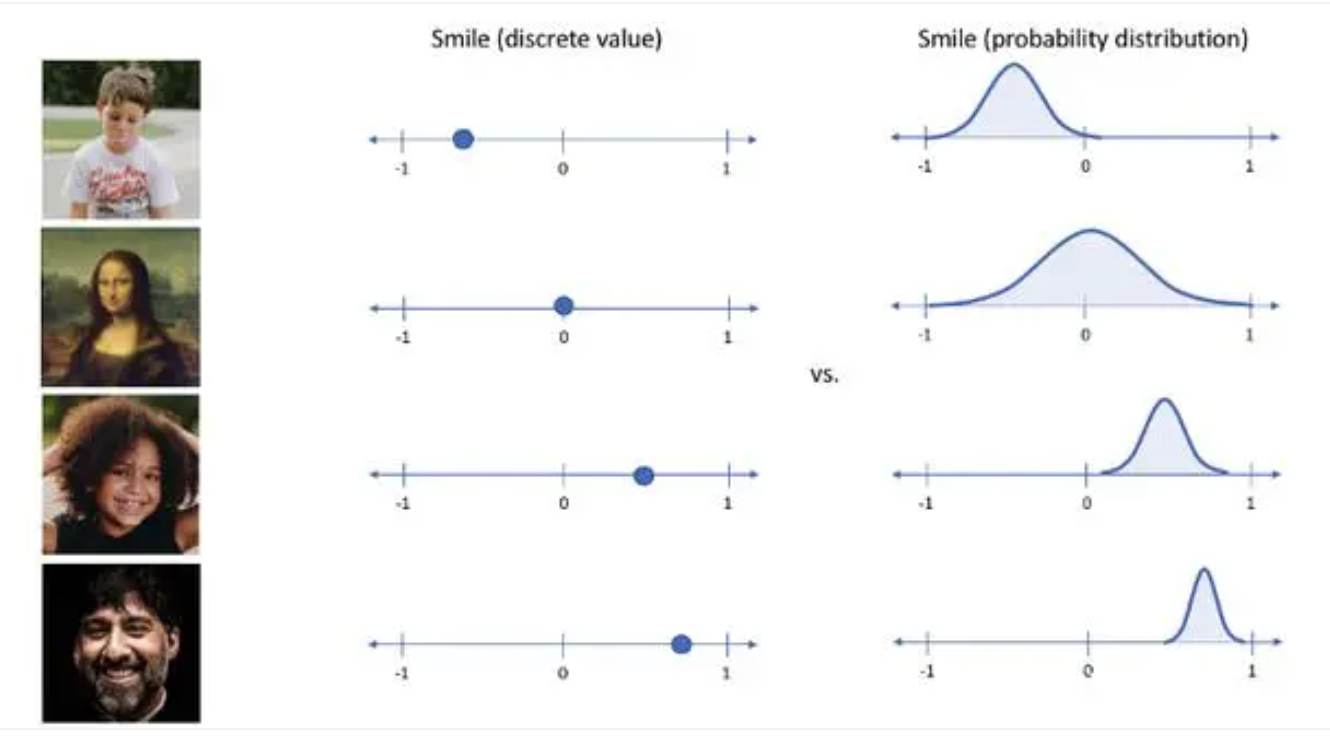
如上图中,同样是微笑,自编码器提取的是一个特征向量,而VAE提取的是一个特征分布。
用数学语言来描述就是
\(P_θ(X)=\int{P_θ(X|S)P(S)dS}={1\over m}\sum_{i=1}^mP_θ(X|S_i)\)
这是一个全概率公式(有关全概率公式的内容可以参考概率论整理 中的全概率公式),这里的\(P(S)\)~N(0,1),它表示数据集中所有的图像特征都满足正态分布,X是一个随机变量,\(S\)是数据集中所有图片的特征向量,θ是提取该特征向量的神经网络参数。\(P_θ(X)\)是X从随机变量生成类似于手写数字图片的概率分布。
代码分析
VAE
class VAE(nn.Module): def __init__(self, in_channels: int, latent_dim: int, hidden_dim: int) -> None: super(VAE, self).__init__() self.latent_dim = latent_dim # 隐空间的维度 self.encoder = nn.Sequential( # 编码器 nn.Linear(in_channels, hidden_dim), nn.BatchNorm1d(hidden_dim), nn.LeakyReLU() ) self.fc_mu = nn.Linear(hidden_dim, latent_dim) # 均值μ self.fc_var = nn.Linear(hidden_dim, latent_dim) # 变分参数 self.decoder_input = nn.Linear(latent_dim, hidden_dim) # 解码器输入层 self.decoder = nn.Sequential( # 解码器 nn.Linear(hidden_dim, in_channels), nn.BatchNorm1d(in_channels), nn.Sigmoid() ) def encode(self, input: Tensor) -> List[Tensor]: # 编码 result = self.encoder(input) # 通过编码器提取特征 mu = self.fc_mu(result) # 将特征转化为均值μ log_var = self.fc_var(result) # 将特征转化为变分参数 return [mu, log_var] def decode(self, z: Tensor) -> Tensor: # 解码 z = self.decoder_input(z) # 将变分特征z转化为解码的可输入格式 z_out = self.decoder(z) # 对该输入进行解码 return z_out def reparameterize(self, mu: Tensor, logvar: Tensor) -> Tensor: # 重置参数 std = torch.exp(0.5 * logvar) # 将变分参数转化为标准差 eps = torch.randn_like(std) return eps * std + mu, std + mu def forward(self, input: Tensor, **kwargs) -> List[Tensor]: mu, log_var = self.encode(input) z, z_inv = self.reparameterize(mu, log_var) z_out = self.decode(z) return [z_out, z_inv, input, mu, log_var] def loss_function(self, input, rec, mu, log_var, kld_weight=0.00025) -> dict: recons_loss = F.mse_loss(rec, input) kld_loss = torch.mean(-0.5 * torch.sum(1 + log_var - mu ** 2 - log_var.exp(), dim=1), dim=0) loss = recons_loss + kld_weight * kld_loss return {'loss_vae': loss}