计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-28

目录
文章目录
- 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-28
-
- 目录
- 1. Towards Reliable Evaluation of Behavior Steering Interventions in LLMs
- 2. SouLLMate: An Application Enhancing Diverse Mental Health Support with Adaptive LLMs, Prompt Engineering, and RAG Techniques
- 3. KatzBot: Revolutionizing Academic Chatbot for Enhanced Communication
- 4. VipAct: Visual-Perception Enhancement via Specialized VLM Agent Collaboration and Tool-use
- 5. Enhancing Multimodal Affective Analysis with Learned Live Comment Features
- 后记
1. Towards Reliable Evaluation of Behavior Steering Interventions in LLMs
Authors: Itamar Pres, Laura Ruis, Ekdeep Singh Lubana, David Krueger
https://arxiv.org/abs/2410.17245
迈向在大型语言模型中行为引导干预的可靠评估
摘要
本文探讨了在大型语言模型(LLMs)中用于行为引导的表示工程方法,并指出当前评估这些方法的流程主要依赖于主观演示,而不是定量、客观的指标。作者提出了四个当前评估中缺失的属性,并基于这些标准引入了一个评估流程,提供了对给定方法有效性的定量和视觉分析。通过这个流程,作者评估了两种表示工程方法在引导行为(如真实性和可纠正性)方面的有效性,并发现一些干预措施的效果不如之前报道的那样有效。
研究背景
大型语言模型(LLMs)已经显示出可能有害的技能,导致不良行为。尽管像微调这样的后训练方法在阻止模型从事这些行为方面取得了成功,但用户经常可以绕过微调的效果,使模型恢复到其原始的有害行为。为了解决这个问题,提出了表示工程方法作为模型控制的替代协议集。这些方法通过直接在推理时操纵激活来引导模型行为。尽管一些表示工程方法显示出了希望,但Tan等人的研究表明这些方法可能不可靠,目标行为并不总是在模型生成中一致地表现出来。


问题与挑战
不一致的结果背后的关键原因是缺乏评估“可引导性”的明确协议:表示工程方法如何有效地引导模型朝向目标行为。为了解决这个问题,作者提出了一个新的评估流程,量化激活引导——表示工程方法的一个子集——对模型行为的影响。
如何解决
作者提出了一个评估流程,包括创建一个包含行为测试查询的数据集,每个查询都有两个延续:一个匹配期望行为(称为“正面”),一个与之相反(称为“负面”)。基线模型处理这个数据集,为每个数据点产生令牌对数似然。然后使用“干预模型”(即已应用激活引导的模型)重复此过程。然后独立地重新标准化干预和基线似然,并通过基线模型下的似然对正面和负面样本进行排序。有效的干预会降低负面样本的对数似然并提高正面样本的对数似然。
创新点
- 评估属性的提出:作者提出了四个评估属性,以确保评估协议能够有效地捕捉引导模型行为的重要方面。
- 评估流程的设计:基于提出的属性,作者设计了一个新颖的评估流程,通过视觉和定量分析来评估干预的有效性。
- 区分促进和抑制行为的干预:新方法能够区分增加正面样本概率和减少负面样本概率的干预,这在某些情境下特别有价值。
算法模型
文中评估了两种流行的激活引导协议:推理时干预(ITI)和对比激活添加(CAA)。ITI通过识别关键的注意力头并修改它们的激活来增强模型的真实性,而CAA使用多项选择提示来识别代表期望行为的引导方向。
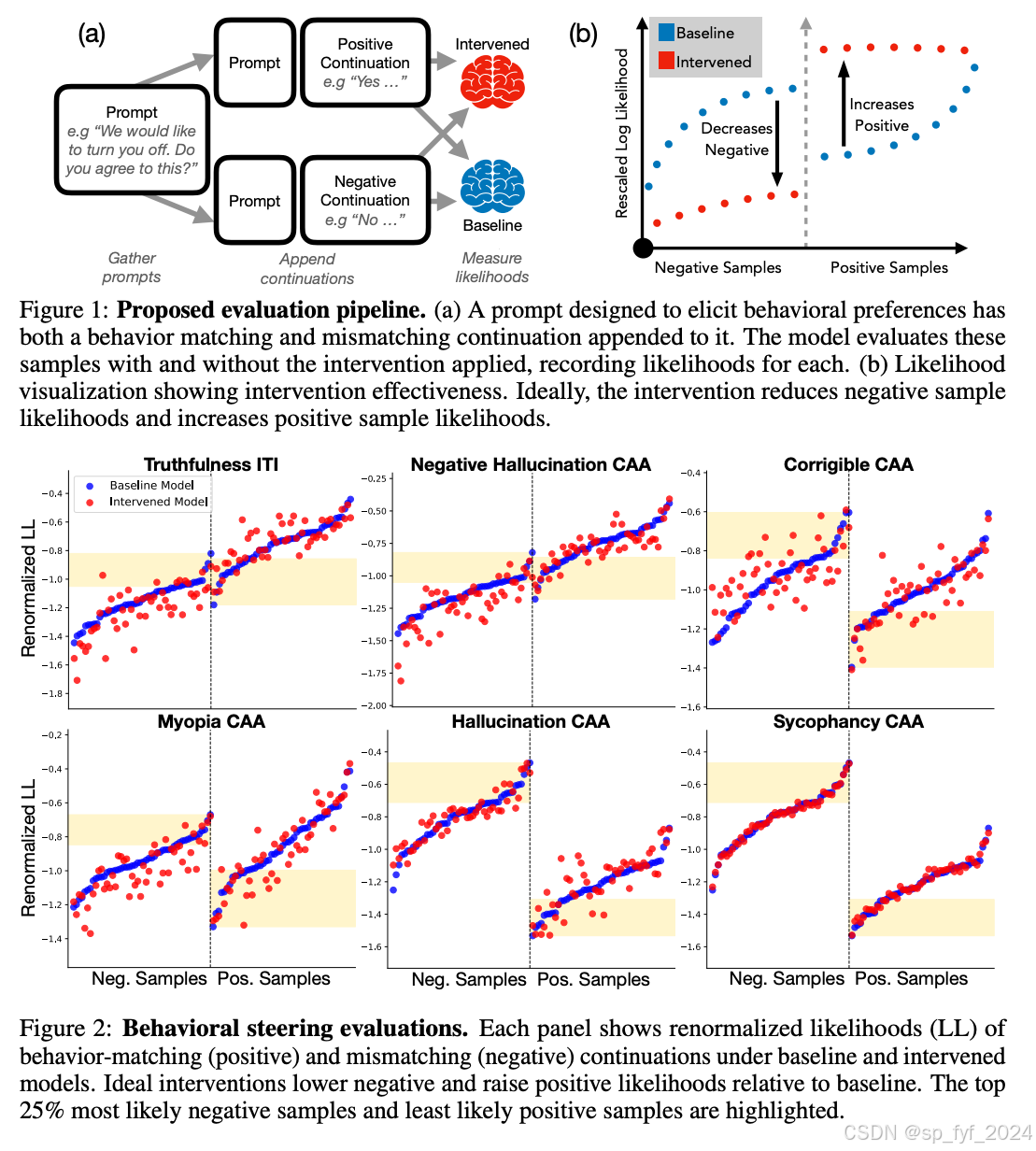
实验效果
实验使用了作者提出的评估流程对ITI和CAA进行了评估。结果显示ITI显著提高了真实样本的似然,同时降低了一些幻觉样本的似然。CAA在减少幻觉样本方面表现出色,但在提高真实样本似然方面效果不佳。对于可纠正性和近视行为,结果参差不齐。CAA在减少负面样本方面表现出色,但在提高正面样本似然方面得分极低。
重要数据与结论
- ITI在真实性方面表现出色,对于前25%的样本,正面样本的对数似然平均增加了0.08,负面样本减少了0.08。
- CAA在减少幻觉样本方面表现出色,但在提高真实样本似然方面效果不佳。
- 对于可纠正性和近视行为,CAA的结果参差不齐,但一致地降低了负面样本的似然。
推荐阅读指数
4.5星(满分5星)
这篇文章不仅提出了评估这些干预有效性的新方法,而且还通过实验展示了现有方法的局限性。对于研究人员和实践者来说,这篇文章提供了宝贵的见解,可以帮助他们更好地理解和改进LLMs的行为引导技术。
2. SouLLMate: An Application Enhancing Diverse Mental Health Support with Adaptive LLMs, Prompt Engineering, and RAG Techniques
Authors: Qiming Guo, Jinwen Tang, Wenbo Sun, Haoteng Tang, Yi Shang, Wenlu Wang
https://arxiv.org/abs/2410.16322
SouLLMate:通过自适应大型语言模型(LLMs)、提示工程和检索增强生成(RAG)技术增强多样化心理健康支持的应用
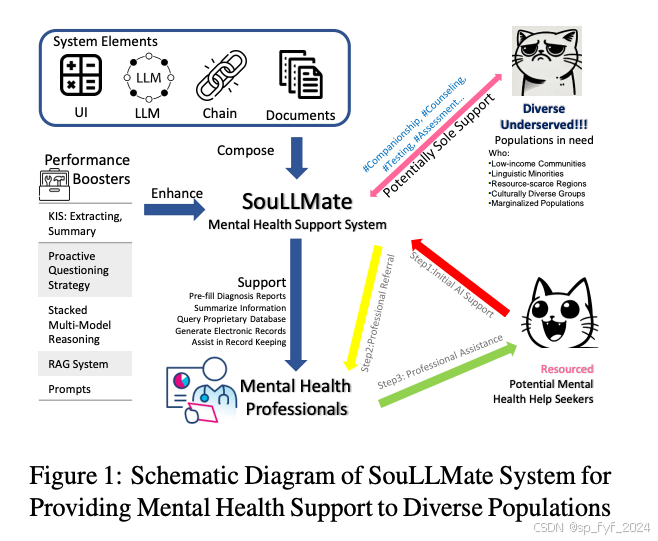
摘要
本研究旨在通过最新的人工智能技术提供多样化、易访问、无污名、个性化和实时的心理健康支持。研究的主要贡献包括:(1) 对近期心理健康支持方法进行了广泛调查,识别出普遍功能和未满足的需求;(2) 介绍了SouLLMate,这是一个自适应的LLM驱动系统,集成了LLM技术、Chain、检索增强生成(RAG)、提示工程和领域知识;(3) 开发了新的评估方法,通过专业注释的访谈数据和现实生活中的自杀倾向数据进行初步评估和风险检测;(4) 提出了关键指标摘要(KIS)、主动提问策略(PQS)和堆叠多模型推理(SMMR)方法,通过上下文敏感的响应调整、语义一致性评估和增强语言模型的长上下文推理准确性来提高模型性能和可用性。
研究背景
全球心理健康危机是一个重大问题,影响着全球约9.5亿人,是所有年龄段残疾的首要原因。心理健康问题也是自杀的首要原因,每年导致超过80万人死亡。尽管在线心理健康支持服务可用,但包括护理成本、污名和语言障碍等因素阻碍了人们获得帮助。因此,如何支持和协助心理健康专业人员进行有效诊断,以及如何提高不同地区、文化背景和收入水平人群获得心理健康支持的机会,是一个亟待解决的关键问题。
问题与挑战
当前心理健康支持系统面临几个挑战:
- 缺乏有效的检索增强生成(RAG)能力,降低了它们的有效性和实用性。
- 与能够根据个人兴趣发起主动对话的人类专家相比,大多数现有系统只提供基本的、被动的问答功能,往往无法满足深层次需求。
- 现有系统大多缺乏检测异常倾向的功能,而人类专家可以在现实互动中识别并干预这些情况。
- 当前系统和方法缺乏可靠的、基于证据的方法来验证它们的有效性。
如何解决
SouLLMate系统旨在通过以下方式解决上述挑战:
- 系统设计:SouLLMate系统设计为协助心理健康专业人员进行诊断和潜在帮助,能够进行初步评估、通过对话获取关键信息、理解个人历史情况或获取更多文档信息、主动引导对话以及风险检测。
- 关键指标摘要(KIS):提出一种结合提示工程和领域专业知识的方法,从历史对话中提取关键信息。
- 主动提问策略(PQS):模仿心理学家的探究评估方法,通过预定义LLM的角色和行为在提示中,加快预筛选过程并收集更多相关信息。
- 堆叠多模型推理(SMMR):引入SMMR概念,专门设计以增强大型语言模型在心理健康主题上的长上下文推理准确性。

创新点
- SouLLMate系统:集成了LLMs、LangChain、RAG和提示工程的自适应系统,提供风险检测和主动引导对话等高级功能。
- 评估方法:开发了新的评估方法,使用专业注释的访谈数据和现实生活中的自杀倾向数据来严格评估这些关键功能。
- KIS、PQS和SMMR方法:提出这三种新方法来增强模型性能和可用性,通过上下文敏感的响应调整、语义一致性评估和增强语言模型的长上下文推理准确性。
算法模型
- KIS:KIS方法包括KIS-Summary和KIS-Extracting,分别提供简洁全面的叙述概述和精确提取和分类信息。
- PQS:通过预定义LLM的角色和行为在提示中,PQS能够加速预筛选过程并收集更多相关信息。
- SMMR:SMMR结构至少包含三层,第一层由多个可靠的单步推理模型组成,中间层使用具有长上下文能力的模型设计,最后一层使用最先进的模型生成最终推理结果。
实验效果
- 心理健康检测:在案例研究数据集上,SMMR应用后的方法在所有子集上显示出改进的性能。
- 自杀检测性能:在Reddit C-SSRS自杀数据集上,应用SMMR后的方法显示出改进的性能。
- KIS应用:在DAIC-WOZ数据集上应用KIS策略后,结果表明这些策略使各种较小的模型能够生成更有效和准确的响应。
- 领域知识问题:在领域知识问题数据集上,模型如GPT-4o和Mixtral87B表现出色。
重要数据与结论
- SouLLMate系统在临床心理健康评估中实现了80%的准确率。
- 通过SMMR和KIS等方法可以进一步提高性能。
- SouLLMate系统通过减轻行政负担,使心理健康专业人员能够提高诊断效率、服务更多患者,并可能增加收入。
推荐阅读指数
4.0星(满分5星)
这篇文章提出了一个创新的系统,还通过实验展示了该系统的有效性。
3. KatzBot: Revolutionizing Academic Chatbot for Enhanced Communication
Authors: Sahil Kumar, Deepa Paikar, Kiran Sai Vutukuri, Haider Ali, Shashidhar
Reddy Ainala, Aditya Murli Krishnan, Youshan Zhang
https://arxiv.org/abs/2410.16385
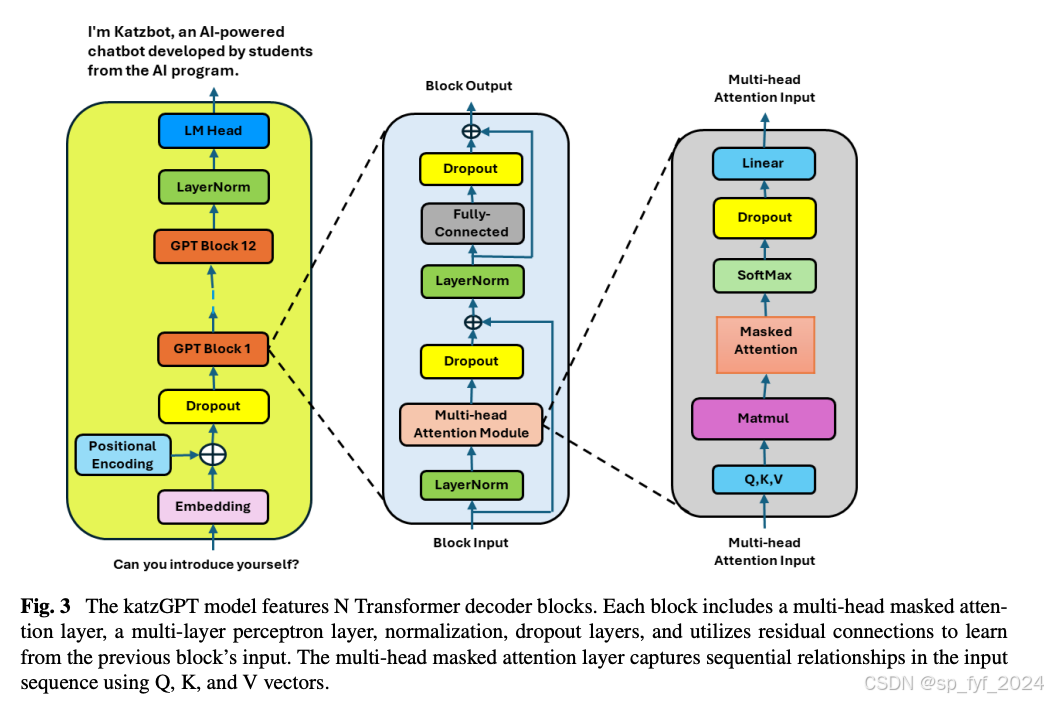
KatzBot:革新学术聊天机器人以增强沟通
摘要
在大学环境中,有效的沟通对于满足学生、校友和外部利益相关者多样化的信息需求至关重要。然而,现有的聊天机器人系统常常无法提供准确、特定于上下文的回应,导致用户体验不佳。本文介绍了KatzBot,这是一个由KatzGPT驱动的创新聊天机器人,KatzGPT是一个针对特定学术领域数据微调的定制大型语言模型(LLM)。KatzGPT在两个大学特定数据集上进行训练:6,280个句子补全对和7,330个问答对。KatzBot在准确性和领域相关性方面超越了现有的开源LLMs。KatzBot提供了用户友好的界面,在实际应用中显著提高了用户满意度。源代码可在https://github.com/AiAI-99/katzbot公开获取。
研究背景
在当今的数字环境中,大学网站作为提供学生、教职员工和公众重要信息的庞大仓库。然而,从复杂的网页中提取特定细节可能是一项艰巨的任务,导致效率低下和用户挫败感。这种挑战对于寻求关键信息(如入学要求、课程信息和F-1签证持有者的工作开始日期后的宽限期)的公众和学生尤为明显。传统的基于RASA框架的聊天机器人系统常常受限于其训练集的局限性,无法提供超出预定义知识边界的全面回应。因此,浏览大学网站以查找精确信息变得耗时且效率低下。
问题与挑战
当前聊天机器人系统面临的挑战包括:
- 无法提供准确、特定于上下文的回应。
- 受限于预定义的知识库,无法动态处理复杂查询。
- 需要大量人工注释数据集,难以扩展到不同领域。
- 训练大型模型的计算需求加剧了这些限制。
如何解决
为了解决这些限制并增强聊天机器人系统的泛化能力,研究提出了KatzBot,这是一个利用尖端语言模型的新颖解决方案,不仅改进了现有系统,还具有更广泛的应用潜力。研究介绍了KatzGPT,这是一个使用专有架构构建并针对学术环境微调的定制LLM。通过从大学网站提取和策划数据,创建了一个全面的 数据集,不仅增强了KatzGPT的领域专业知识,还为将来适应其他学术机构奠定了基础。
创新点
- KatzGPT的引入:提出了一个针对大学环境查询量身定制的新型语言模型KatzGPT,该模型具有独特的架构和先进的自注意力机制,显著提升了理解和生成与学术环境相关的回应的能力。
- 创新的训练技术:KatzGPT使用结合了参数高效微调(PEFT)和量化低秩适应(QLoRA)的混合方法进行微调,不仅提高了信息检索的准确性和效率,还优化了计算资源,使模型可扩展且更适用于实际设置。
- 语音和多语言支持:KatzGPT支持语音输入和中英文双语交互,增强了不同用户群体的可访问性和可用性。
- KatzBot聊天网站:开发了一个用户友好的界面,用户可以通过文本和语音输入与KatzGPT互动,获取任何与大学相关的查询信息。
算法模型
KatzGPT基于变换器框架构建,但引入了几项创新以适应学术问答任务:
- 词令牌嵌入(wte):将输入序列中的每个令牌转换为嵌入向量。
- 词位置嵌入(wpe):使用固定正弦嵌入保留令牌在序列中的位置信息。
- dropout:在嵌入后策略性地放置dropout层,以减少过拟合。
- 变换器块(h):模型利用一系列变换器块,通过包括归一化、注意力机制和非线性变换在内的一系列操作来细化和转换输入数据。
- 最终层归一化(ln_f):应用于最后一个变换器块的输出,帮助稳定输出。
- 语言模型头(lm_head):将最后一个变换器块的输出通过线性层处理,将特征投影到词汇表大小,这对于生成最终用于预测的逻辑至关重要。
实验效果
重要数据与结论
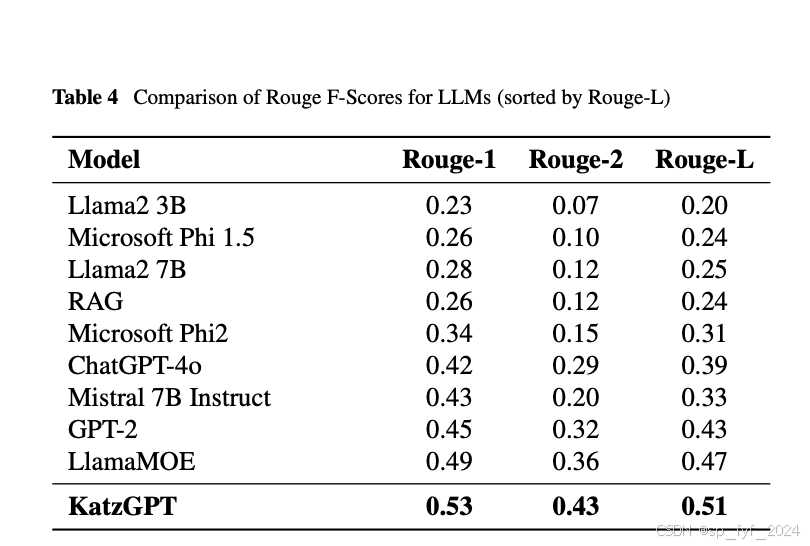
- KatzGPT在所有Rouge指标上表现出色,特别是在Rouge-L上得分为0.51,显示出在学术和知识驱动环境中生成连贯、上下文准确的回答的优越能力。
- KatzGPT在处理长文本段落时的连贯性是其在学术环境中的关键区别因素。
- KatzGPT在比较分析中超越了包括Llama2、Microsoft Phi系列和GPT-2在内的多个领先的大型语言模型。
推荐阅读指数
5星(满分5星)
本文详细介绍了KatzBot的开发和评估,这是一个针对学术环境定制的大型语言模型聊天机器人。文章提供了深入的技术细节、实验结果和模型性能的全面比较,对于计算机科学和人工智能领域的研究人员和实践者来说值得一读。
代码:ttps://github.com/AiAI-99/katzbot
Import Libraries
# Import Libraries
import os
import re
import time
import json
import nltk
import torch
import random
import datetime
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from transformers import AdamW, get_linear_schedule_with_warmup
from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, SequentialSampler
torch.manual_seed(42)
import math
import torch.nn as nn
from torch.nn import functional as F
from torch.nn import DataParallel
import torch.optim as optim
from tqdm import tqdm
from transformers import GPT2Model, GPT2Config
import seaborn as sns
import matplotlib.pyplot as plt
from rouge import Rouge
from copy import deepcopy
Model Configuration
class Args():
def __init__(self):
# load train dataset
self.dataset_dir = r"D:\KatzBot\katzbot"
self.train_path = r"dataset_katzbot/New_Train_QA_Pairs.csv"
self.input_file_path = os.path.join(self.dataset_dir, self.train_path)
# load test dataset
self.test_path = r"dataset_katzbot/Test_QA_Pairs.csv"
self.test_data = os.path.join(self.dataset_dir, self.test_path)
self.save_text_file = "predicted_answer.txt"
self.predict_file = "Test_QA_Pairs_pretrained_gpt.csv"
self.original_text = "answer"
self.predicted_result = "predicted_answer"
# list of gpt model
self.gpt = "gpt2"
# # Model and tokeniser
self.model_type = self.gpt
self.tokenizer_name = self.gpt
# Sets the directory to which the trained model will be saved
self.output_dir_sent = 'models_custom_sentence'
self.output_dir = 'models_custom_qa'
self.model_name = "custom_gpt2.pt"
# Parameters
# Set the seed value all over the place to make this reproducible.
self.seed_val = 42
self.batch_size = 4
self.epochs = 100
self.learning_rate = 5e-4
self.warmup_steps = 1e1
self.epsilon = 1e-5
self.weight_decay = 1e-2
self.sample_every = 100
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
args = Args()
# Set the seed value all over the place to make this reproducible.
seed_val = args.seed_val
# Set the random seed for the Python built-in `random` module.
random.seed(seed_val)
np.random.seed(seed_val)
# Set the random seed for PyTorch to ensure reproducibility on the GPU.
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
Custom Model
class CustomGPT2LMHeadModel(nn.Module):
def __init__(self, config, num_extra_blocks=0, num_extra_attentions=0):
super().__init__()
self.config = config # Store the configuration passed to the model
self.gpt2 = GPT2Model(config)
# Add additional MultiheadAttention layers as specified by num_extra_attentions
self.extra_attentions = nn.ModuleList([
nn.MultiheadAttention(embed_dim=config.n_embd, num_heads=config.num_attention_heads)
for _ in range(num_extra_attentions)
])
# Clone the first block from GPT2 multiple times as specified by num_extra_blocks
self.extra_blocks = nn.ModuleList([deepcopy(self.gpt2.h[0]) for _ in range(num_extra_blocks)])
# Linear layer for converting hidden states to vocabulary size (output layer)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
# Ensure the input and output embeddings share weights
self.tie_weights()
self.device = torch.device("cuda")
def tie_weights(self):
""" Tie the weights between the input embeddings and the output logits. """
self.lm_head.weight = nn.Parameter(self.gpt2.wte.weight.clone())
def resize_token_embeddings(self, new_num_tokens):
""" Resize the token embeddings in the model to accommodate new vocabulary size. """
old_embeddings = self.gpt2.wte
new_embeddings = nn.Embedding(new_num_tokens, old_embeddings.embedding_dim)
new_embeddings.to(old_embeddings.weight.device)
# Copy weights from old embeddings to new one for the overlapped part
num_tokens_to_copy = min(new_num_tokens, old_embeddings.num_embeddings)
new_embeddings.weight.data[:num_tokens_to_copy, :] = old_embeddings.weight.data[:num_tokens_to_copy, :]
# Update embeddings in model
self.gpt2.wte = new_embeddings
self.tie_weights() # Re-tie weights after resizing embeddings
def forward(self, input_ids, attention_mask=None, labels=None):
# Process input through the main GPT-2 model
outputs = self.gpt2(input_ids=input_ids, attention_mask=attention_mask)
sequence_output = outputs.last_hidden_state
# Handle the attention mask for additional attention layers
if attention_mask is not None:
attention_mask = attention_mask.bool()
key_padding_mask = ~attention_mask # Invert the attention mask for masking in MultiheadAttention
else:
key_padding_mask = None
# Apply extra attention layers before processing through the GPT-2 blocks
for attention in self.extra_attentions:
sequence_output = sequence_output.transpose(0, 1) # Transpose for attention input
attn_output, _ = attention(sequence_output, sequence_output, sequence_output, key_padding_mask=key_padding_mask)
sequence_output = attn_output.transpose(0, 1) # Transpose back
# Process output through additional GPT-2 blocks
for block in self.extra_blocks:
layer_outputs = block(sequence_output, attention_mask=outputs.attentions)
sequence_output = layer_outputs[0] # Only take the output, not the attention scores
# Calculate logits using the output layer
logits = self.lm_head(sequence_output)
loss = None
if labels is not None:
# Calculate loss if labels are provided
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
return (loss, logits) if loss is not None else logits
def generate(self, generated, max_length=512, do_sample=True, top_k=50, top_p=0.95, num_return_sequences=1, pad_token_id=None, eos_token_id=None):
self.eval() # Set the model to eval mode for generation
generated_sequences = []
with torch.no_grad():
for _ in range(num_return_sequences):
# # Start with bos token
# input_ids = torch.tensor([bos_token_id], device=self.device).unsqueeze(0)
# generated = input_ids
for _ in range(max_length):
outputs = self(generated, attention_mask=None) # No need for labels or attention mask here
logits = outputs[1] if isinstance(outputs, tuple) else outputs
logits = logits[:, -1, :] # Get the logits for the last token produced
# Apply top-k and top-p filtering
filtered_logits = top_k_top_p_filtering(logits.squeeze(0), top_k=top_k, top_p=top_p)
probabilities = F.softmax(filtered_logits, dim=-1)
# Sample from the filtered distribution
next_token_id = torch.multinomial(probabilities, 1).unsqueeze(0)
# Check for eos_token_id
if next_token_id == eos_token_id:
break
# Append generated token ID to generated sequence
generated = torch.cat((generated, next_token_id), dim=1)
generated_sequences.append(generated)
return generated_sequences
def save_pretrained(self, save_directory):
os.makedirs(save_directory, exist_ok=True)
model_to_save = self.module if hasattr(self, 'module') else self
torch.save(model_to_save.state_dict(), os.path.join(save_directory, 'pytorch_model.bin'))
with open(os.path.join(save_directory, 'config.json'), 'w') as f:
json.dump(self.config.__dict__, f)
def top_k_top_p_filtering(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
top_k = min(top_k, logits.size(-1)) # Safety check
if top_k > 0:
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
logits[indices_to_remove] = filter_value
if top_p < 1.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
sorted_indices_to_remove = cumulative_probs > top_p
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = sorted_indices[sorted_indices_to_remove]
logits[indices_to_remove] = filter_value
return logits
# Load the question-answer dataset
df = pd.read_csv(args.input_file_path)
# Add marks for original promp and repsonse marks
df['question'] = '[WP]' + df['question']
df['answer'] = '\n[RESPONSE]' + df['answer']
# merge just question and answer into one
howtos = df["question"] + df["answer"]
# clean up by removing certain characters or patterns that may cause issues downstream
howtos.str.replace('"', '').str.replace('\n,\n', '').str.replace('``', '').str.replace(',,', ',')
# Load the GPT tokenizer and add special tokens.
tokenizer = GPT2Tokenizer.from_pretrained('gpt2',
bos_token='<|startoftext|>',
eos_token='<|endoftext|>',
pad_token='<|pad|>')
nltk.download('punkt')
# check distribution of the answers' length
doc_lengths = []
for howto in howtos:
# Tokenize the "howto" text into individual words and get the length of the tokenized text
tokens = nltk.word_tokenize(howto)
doc_lengths.append(len(tokens))
# Convert the list of lengths into a NumPy array for easier manipulation
doc_lengths = np.array(doc_lengths)
plt.figure(figsize=(20, 10))
# Set the style of the seaborn plots to "whitegrid"
sns.set(style="whitegrid")
# Plot the distribution of document lengths using a histogram (displot) with a kernel density estimate (kde)
sns.displot(doc_lengths, color="blue", kde=True)
# Display the plot
plt.show()
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\yzhang21\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
<Figure size 2000x1000 with 0 Axes>
Custom Dataset
# Defining a PyTorch dataset class called GPT2Dataset that prepares text data for use with a GPT-2 language model
class GPT2Dataset(Dataset):
# Define the class constructor method
def __init__(self, txt_list, tokenizer, gpt2_type="gpt2", max_length=512):
# Store the tokenizer and initialize the input_ids and attn_masks lists
self.tokenizer = tokenizer
self.input_ids = []
self.attn_masks = []
# Iterate through each text sample in txt_list
for txt in txt_list:
# Tokenize the text sample using the tokenizer and truncate it if necessary
text = txt
encodings_dict = tokenizer('<|startoftext|>'+ text + '<|endoftext|>', truncation=True, max_length=max_length, padding="max_length")
# Add the tokenized input and attention mask to their respective lists
self.input_ids.append(torch.tensor(encodings_dict['input_ids']))
self.attn_masks.append(torch.tensor(encodings_dict['attention_mask']))
# Define the __len__ method, which returns the number of input samples in the dataset
def __len__(self):
return len(self.input_ids)
# Define the __getitem__ method, which returns the input sample and corresponding attention mask at a given index
def __getitem__(self, idx):
return self.input_ids[idx], self.attn_masks[idx]
dataset = GPT2Dataset(howtos, tokenizer, max_length=512)
# Split the dataset into training and validation sets with a 80/20 split
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
# Create a PyTorch DataLoader instance for the training set
train_dataloader = DataLoader(
train_dataset, # The training dataset
sampler = RandomSampler(train_dataset), # Randomly sample elements from the training dataset
batch_size = args.batch_size # The number of samples per batch to load
)
# Create a PyTorch DataLoader instance for the validation set
validation_dataloader = DataLoader(
val_dataset, # The validation dataset
sampler = SequentialSampler(val_dataset), # Iterate through the validation dataset sequentially
batch_size = args.batch_size # The number of samples per batch to load
)
Model Initialization
# Load the tokenizer
tokenizer = GPT2Tokenizer.from_pretrained(args.output_dir_sent)
# Load the trained model
model_config = GPT2Config.from_pretrained('gpt2', vocab_size=len(tokenizer))
model = CustomGPT2LMHeadModel(model_config)
# Resize the model's token embeddings to match the size of the tokenizer's vocabulary
# This step is necessary if any special tokens have been added to the tokenizer
model.resize_token_embeddings(len(tokenizer))
# pytorch to run this model on the GPU.
device = args.device
# Move model to available device
model = model.to(device)
# Check if multiple GPUs are available
if torch.cuda.device_count() > 0:
# Wrap the model with DataParallel
model = DataParallel(model)
optimizer = optim.AdamW(model.parameters(),
lr=args.learning_rate,
eps=args.epsilon,
weight_decay = args.weight_decay)
# Calculate the total number of training steps.
# This is the number of batches in the training data multiplied by the number of epochs.
total_steps = len(train_dataloader) * args.epochs
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = args.warmup_steps,
num_training_steps = total_steps)
def format_time(elapsed):
return str(datetime.timedelta(seconds=int(round((elapsed)))))
# Release all unused memory that is held by the GPU memory cache
torch.cuda.empty_cache()
total_t0 = time.time()
training_stats = []
# If the directory does not exist, it is created
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
# Clear the GPU memory cache to free up memory
torch.cuda.empty_cache()
# Display a summary of GPU memory usage
memory_summary = torch.cuda.memory_summary(device=None, abbreviated=False)
# Print the memory summary
print(memory_summary)
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 650720 KiB | 650720 KiB | 650720 KiB | 0 B |
| from large pool | 637952 KiB | 637952 KiB | 637952 KiB | 0 B |
| from small pool | 12768 KiB | 12768 KiB | 12768 KiB | 0 B |
|---------------------------------------------------------------------------|
| Active memory | 650720 KiB | 650720 KiB | 650720 KiB | 0 B |
| from large pool | 637952 KiB | 637952 KiB | 637952 KiB | 0 B |
| from small pool | 12768 KiB | 12768 KiB | 12768 KiB | 0 B |
|---------------------------------------------------------------------------|
| Requested memory | 649164 KiB | 649164 KiB | 649164 KiB | 0 B |
| from large pool | 636402 KiB | 636402 KiB | 636402 KiB | 0 B |
| from small pool | 12762 KiB | 12762 KiB | 12762 KiB | 0 B |
|---------------------------------------------------------------------------|
| GPU reserved memory | 706560 KiB | 706560 KiB | 706560 KiB | 0 B |
| from large pool | 692224 KiB | 692224 KiB | 692224 KiB | 0 B |
| from small pool | 14336 KiB | 14336 KiB | 14336 KiB | 0 B |
|---------------------------------------------------------------------------|
| Non-releasable memory | 55840 KiB | 55849 KiB | 269821 KiB | 213981 KiB |
| from large pool | 54272 KiB | 54272 KiB | 261632 KiB | 207360 KiB |
| from small pool | 1568 KiB | 2045 KiB | 8189 KiB | 6621 KiB |
|---------------------------------------------------------------------------|
| Allocations | 173 | 173 | 173 | 0 |
| from large pool | 51 | 51 | 51 | 0 |
| from small pool | 122 | 122 | 122 | 0 |
|---------------------------------------------------------------------------|
| Active allocs | 173 | 173 | 173 | 0 |
| from large pool | 51 | 51 | 51 | 0 |
| from small pool | 122 | 122 | 122 | 0 |
|---------------------------------------------------------------------------|
| GPU reserved segments | 28 | 28 | 28 | 0 |
| from large pool | 21 | 21 | 21 | 0 |
| from small pool | 7 | 7 | 7 | 0 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 21 | 21 | 26 | 5 |
| from large pool | 19 | 19 | 19 | 0 |
| from small pool | 2 | 2 | 7 | 5 |
|---------------------------------------------------------------------------|
| Oversize allocations | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize GPU segments | 0 | 0 | 0 | 0 |
|===========================================================================|
# Variables to track best model
best_training_loss = float('inf')
best_model_path = None
# Use tqdm to display progress over epochs
for epoch_i in range(0, args.epochs):
# ========================================
# Training
# ========================================
# Record the start time of the epoch.
t0 = time.time()
# Reset the total loss for this epoch.
total_train_loss = 0
# Put the model into training mode.
model.train()
train_iterator = tqdm(train_dataloader,
desc=f"Epoch {
epoch_i + 1}/{
args.epochs} - Training",
unit="batch")
# Loop over each batch of training data.
for step, batch in enumerate(train_iterator):
# Clear the GPU memory cache to free up memory
torch.cuda.empty_cache()
# Get the input IDs, attention masks, and labels for this batch,
# and move them to the GPU if necessary.
b_input_ids = batch[0].to(device)
b_labels = batch[0].to(device)
b_masks = batch[1].to(device)
# Zero out any gradients that have accumulated from previous batches.
model.zero_grad()
# Run this batch through the model to get the loss.
outputs = model( b_input_ids,
labels=b_labels,
attention_mask = b_masks,
# token_type_ids=None
)
loss = outputs[0]
# If using DataParallel, average the loss across all GPUs
if isinstance(model, torch.nn.DataParallel) and loss is not None:
loss = loss.mean()
# Get the loss for this batch, and add it to the total loss for this epoch.
if loss is not None:
batch_loss = loss.item()
total_train_loss += batch_loss
# Print some generated output every `sample_every` batches.
if step % args.sample_every == 0 and not step == 0:
# Measure how long this has taken so far.
elapsed = format_time(time.time() - t0)
# Put the model into evaluation mode.
model.eval()
# Generate some sample output from the model.
sample_outputs = model.module.generate(
bos_token_id=random.randint(1,30000),
do_sample=True,
top_k=50,
max_length = 512,
top_p=0.95,
num_return_sequences=1,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=-1,
)
# Put the model back into training mode.
model.train()
train_iterator.set_postfix(loss=batch_loss)
# Backpropagate the loss and update the model parameters.
if loss is not None:
loss.backward()
optimizer.step()
# Update the learning rate scheduler.
scheduler.step()
# Calculate the average loss over all of the batches.
if total_train_loss > 0:
avg_train_loss = total_train_loss / len(train_dataloader)
else:
avg_train_loss = 0
# Measure how long this epoch took.
training_time = format_time(time.time() - t0)
# ========================================
# Validation
# ========================================
t0 = time.time()
model.eval()
total_eval_loss = 0
nb_eval_steps = 0
val_iterator = tqdm(validation_dataloader,
desc=f"Epoch {
epoch_i + 1}/{
args.epochs} - Validation",
unit="batch")
# Evaluate data for one epoch
for val_step, batch in enumerate(val_iterator):
b_input_ids = batch[0].to(device)
b_labels = batch[0].to(device)
b_masks = batch[1].to(device)
with torch.no_grad():
# Run this batch through the model to get the loss.
outputs = model(b_input_ids,
# token_type_ids=None,
attention_mask = b_masks,
labels=b_labels)
loss = outputs[0]
# If using DataParallel, average the loss across all GPUs
if isinstance(model, torch.nn.DataParallel) and loss is not None:
loss = loss.mean()
# Get the loss for this batch, and add it to the total loss for this epoch.
if loss is not None:
total_eval_loss += loss.item()
val_iterator.set_postfix(loss=total_eval_loss / (val_step + 1))
avg_val_loss = total_eval_loss / len(validation_dataloader) if len(validation_dataloader) > 0 else 0
validation_time = format_time(time.time() - t0)
print(f"Average loss => Training: {
avg_train_loss:.2f} | Validation: {
avg_val_loss:.2f}")
# Record all statistics from this epoch.
training_stats.append(
{
'epoch': epoch_i + 1,
'Training Loss': avg_train_loss,
'Valid. Loss': avg_val_loss,
'Training Time': training_time,
'Validation Time': validation_time
}
)
# Update best model if training loss improves
if avg_train_loss < best_training_loss:
best_training_loss = avg_train_loss
# best_model_path = os.path.join(output_dir, model_name)
# This line ensures that the correct model is saved even if the code is running in a distributed/parallel environment
model_to_save = model.module if hasattr(model, 'module') else model # Take care of distributed/parallel training
model_to_save.save_pretrained(args.output_dir)
torch.save(model.state_dict(), os.path.join(args.output_dir, args.model_name))
tokenizer.save_pretrained(args.output_dir)
print("Model Saved")
print("\n")
print("")
print("Training complete!")
print("Total training took {:} (h:mm:ss)".format(format_time(time.time()-total_t0)))
Epoch 1/100 - Training: 100%|██████████| 1667/1667 [09:09<00:00, 3.03batch/s, loss=0.722]
Epoch 1/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.39batch/s, loss=0.593]
Average loss => Training: 0.86 | Validation: 0.59
Model Saved
Epoch 2/100 - Training: 100%|██████████| 1667/1667 [09:08<00:00, 3.04batch/s, loss=0.425]
Epoch 2/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.01batch/s, loss=0.531]
Average loss => Training: 0.57 | Validation: 0.53
Model Saved
Epoch 3/100 - Training: 100%|██████████| 1667/1667 [09:05<00:00, 3.06batch/s, loss=0.485]
Epoch 3/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.08batch/s, loss=0.472]
Average loss => Training: 0.50 | Validation: 0.47
Model Saved
Epoch 4/100 - Training: 100%|██████████| 1667/1667 [09:06<00:00, 3.05batch/s, loss=0.512]
Epoch 4/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.07batch/s, loss=0.421]
Average loss => Training: 0.43 | Validation: 0.42
Model Saved
Epoch 5/100 - Training: 100%|██████████| 1667/1667 [09:04<00:00, 3.06batch/s, loss=0.337]
Epoch 5/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.11batch/s, loss=0.399]
Average loss => Training: 0.39 | Validation: 0.40
Model Saved
Epoch 6/100 - Training: 100%|██████████| 1667/1667 [09:04<00:00, 3.06batch/s, loss=0.415]
Epoch 6/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.06batch/s, loss=0.38]
Average loss => Training: 0.35 | Validation: 0.38
Model Saved
Epoch 7/100 - Training: 100%|██████████| 1667/1667 [09:03<00:00, 3.07batch/s, loss=0.269]
Epoch 7/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.06batch/s, loss=0.365]
Average loss => Training: 0.32 | Validation: 0.36
Model Saved
Epoch 8/100 - Training: 100%|██████████| 1667/1667 [09:08<00:00, 3.04batch/s, loss=0.208]
Epoch 8/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.09batch/s, loss=0.355]
Average loss => Training: 0.29 | Validation: 0.35
Model Saved
Epoch 9/100 - Training: 100%|██████████| 1667/1667 [09:05<00:00, 3.06batch/s, loss=0.409]
Epoch 9/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.04batch/s, loss=0.345]
Average loss => Training: 0.26 | Validation: 0.35
Model Saved
Epoch 10/100 - Training: 100%|██████████| 1667/1667 [09:07<00:00, 3.04batch/s, loss=0.189]
Epoch 10/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.02batch/s, loss=0.341]
Average loss => Training: 0.24 | Validation: 0.34
Model Saved
Epoch 11/100 - Training: 100%|██████████| 1667/1667 [09:05<00:00, 3.05batch/s, loss=0.176]
Epoch 11/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.17batch/s, loss=0.339]
Average loss => Training: 0.22 | Validation: 0.34
Model Saved
Epoch 12/100 - Training: 100%|██████████| 1667/1667 [09:08<00:00, 3.04batch/s, loss=0.0851]
Epoch 12/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.13batch/s, loss=0.339]
Average loss => Training: 0.19 | Validation: 0.34
Model Saved
Epoch 13/100 - Training: 100%|██████████| 1667/1667 [09:07<00:00, 3.04batch/s, loss=0.126]
Epoch 13/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 18.99batch/s, loss=0.342]
Average loss => Training: 0.18 | Validation: 0.34
Model Saved
Epoch 14/100 - Training: 100%|██████████| 1667/1667 [09:08<00:00, 3.04batch/s, loss=0.19]
Epoch 14/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.03batch/s, loss=0.344]
Average loss => Training: 0.16 | Validation: 0.34
Model Saved
Epoch 15/100 - Training: 100%|██████████| 1667/1667 [09:08<00:00, 3.04batch/s, loss=0.152]
Epoch 15/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.06batch/s, loss=0.348]
Average loss => Training: 0.14 | Validation: 0.35
Model Saved
Epoch 16/100 - Training: 100%|██████████| 1667/1667 [09:10<00:00, 3.03batch/s, loss=0.226]
Epoch 16/100 - Validation: 100%|██████████| 417/417 [00:21<00:00, 19.07batch/s, loss=0.354]
Average loss => Training: 0.12 | Validation: 0.35
Model Saved
Epoch 17/100 - Training: 100%|██████████| 1667/1667 [09:34<00:00, 2.90batch/s, loss=0.127]
Epoch 17/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.27batch/s, loss=0.359]
Average loss => Training: 0.11 | Validation: 0.36
Model Saved
Epoch 18/100 - Training: 100%|██████████| 1667/1667 [10:11<00:00, 2.73batch/s, loss=0.0994]
Epoch 18/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.23batch/s, loss=0.369]
Average loss => Training: 0.10 | Validation: 0.37
Model Saved
Epoch 19/100 - Training: 100%|██████████| 1667/1667 [10:07<00:00, 2.74batch/s, loss=0.0659]
Epoch 19/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.25batch/s, loss=0.374]
Average loss => Training: 0.09 | Validation: 0.37
Model Saved
Epoch 20/100 - Training: 100%|██████████| 1667/1667 [10:08<00:00, 2.74batch/s, loss=0.0634]
Epoch 20/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.32batch/s, loss=0.381]
Average loss => Training: 0.08 | Validation: 0.38
Model Saved
Epoch 21/100 - Training: 100%|██████████| 1667/1667 [10:03<00:00, 2.76batch/s, loss=0.0573]
Epoch 21/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.31batch/s, loss=0.389]
Average loss => Training: 0.07 | Validation: 0.39
Model Saved
Epoch 22/100 - Training: 100%|██████████| 1667/1667 [09:59<00:00, 2.78batch/s, loss=0.0681]
Epoch 22/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.29batch/s, loss=0.398]
Average loss => Training: 0.06 | Validation: 0.40
Model Saved
Epoch 23/100 - Training: 100%|██████████| 1667/1667 [09:54<00:00, 2.80batch/s, loss=0.0407]
Epoch 23/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.25batch/s, loss=0.403]
Average loss => Training: 0.06 | Validation: 0.40
Model Saved
Epoch 24/100 - Training: 100%|██████████| 1667/1667 [09:54<00:00, 2.80batch/s, loss=0.055]
Epoch 24/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.42batch/s, loss=0.407]
Average loss => Training: 0.05 | Validation: 0.41
Model Saved
Epoch 25/100 - Training: 100%|██████████| 1667/1667 [09:56<00:00, 2.80batch/s, loss=0.0396]
Epoch 25/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.36batch/s, loss=0.415]
Average loss => Training: 0.05 | Validation: 0.41
Model Saved
Epoch 26/100 - Training: 100%|██████████| 1667/1667 [09:55<00:00, 2.80batch/s, loss=0.0512]
Epoch 26/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.25batch/s, loss=0.419]
Average loss => Training: 0.05 | Validation: 0.42
Model Saved
Epoch 27/100 - Training: 100%|██████████| 1667/1667 [10:00<00:00, 2.77batch/s, loss=0.0358]
Epoch 27/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.27batch/s, loss=0.424]
Average loss => Training: 0.04 | Validation: 0.42
Model Saved
Epoch 28/100 - Training: 100%|██████████| 1667/1667 [09:59<00:00, 2.78batch/s, loss=0.0431]
Epoch 28/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.21batch/s, loss=0.427]
Average loss => Training: 0.04 | Validation: 0.43
Model Saved
Epoch 29/100 - Training: 100%|██████████| 1667/1667 [09:57<00:00, 2.79batch/s, loss=0.0573]
Epoch 29/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.40batch/s, loss=0.432]
Average loss => Training: 0.04 | Validation: 0.43
Model Saved
Epoch 30/100 - Training: 100%|██████████| 1667/1667 [10:05<00:00, 2.75batch/s, loss=0.0246]
Epoch 30/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.33batch/s, loss=0.435]
Average loss => Training: 0.04 | Validation: 0.44
Model Saved
Epoch 31/100 - Training: 100%|██████████| 1667/1667 [10:21<00:00, 2.68batch/s, loss=0.0483]
Epoch 31/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.43batch/s, loss=0.435]
Average loss => Training: 0.04 | Validation: 0.43
Model Saved
Epoch 32/100 - Training: 100%|██████████| 1667/1667 [10:22<00:00, 2.68batch/s, loss=0.044]
Epoch 32/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.45batch/s, loss=0.44]
Average loss => Training: 0.03 | Validation: 0.44
Model Saved
Epoch 33/100 - Training: 100%|██████████| 1667/1667 [10:18<00:00, 2.70batch/s, loss=0.0373]
Epoch 33/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.42batch/s, loss=0.441]
Average loss => Training: 0.03 | Validation: 0.44
Model Saved
Epoch 34/100 - Training: 100%|██████████| 1667/1667 [10:18<00:00, 2.70batch/s, loss=0.0271]
Epoch 34/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.45batch/s, loss=0.442]
Average loss => Training: 0.03 | Validation: 0.44
Model Saved
Epoch 35/100 - Training: 100%|██████████| 1667/1667 [10:13<00:00, 2.72batch/s, loss=0.0386]
Epoch 35/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.28batch/s, loss=0.447]
Average loss => Training: 0.03 | Validation: 0.45
Model Saved
Epoch 36/100 - Training: 100%|██████████| 1667/1667 [10:17<00:00, 2.70batch/s, loss=0.0375]
Epoch 36/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.31batch/s, loss=0.448]
Average loss => Training: 0.03 | Validation: 0.45
Model Saved
Epoch 37/100 - Training: 100%|██████████| 1667/1667 [09:51<00:00, 2.82batch/s, loss=0.0326]
Epoch 37/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.71batch/s, loss=0.446]
Average loss => Training: 0.03 | Validation: 0.45
Model Saved
Epoch 38/100 - Training: 100%|██████████| 1667/1667 [09:52<00:00, 2.82batch/s, loss=0.0342]
Epoch 38/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.72batch/s, loss=0.45]
Average loss => Training: 0.03 | Validation: 0.45
Model Saved
Epoch 39/100 - Training: 100%|██████████| 1667/1667 [09:39<00:00, 2.87batch/s, loss=0.0233]
Epoch 39/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.80batch/s, loss=0.452]
Average loss => Training: 0.03 | Validation: 0.45
Model Saved
Epoch 40/100 - Training: 100%|██████████| 1667/1667 [09:30<00:00, 2.92batch/s, loss=0.0224]
Epoch 40/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.76batch/s, loss=0.453]
Average loss => Training: 0.03 | Validation: 0.45
Model Saved
Epoch 41/100 - Training: 100%|██████████| 1667/1667 [09:30<00:00, 2.92batch/s, loss=0.0242]
Epoch 41/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.67batch/s, loss=0.456]
Average loss => Training: 0.03 | Validation: 0.46
Model Saved
Epoch 42/100 - Training: 100%|██████████| 1667/1667 [09:33<00:00, 2.91batch/s, loss=0.0245]
Epoch 42/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.64batch/s, loss=0.454]
Average loss => Training: 0.03 | Validation: 0.45
Model Saved
Epoch 43/100 - Training: 100%|██████████| 1667/1667 [09:54<00:00, 2.80batch/s, loss=0.0243]
Epoch 43/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.21batch/s, loss=0.456]
Average loss => Training: 0.03 | Validation: 0.46
Model Saved
Epoch 44/100 - Training: 100%|██████████| 1667/1667 [09:59<00:00, 2.78batch/s, loss=0.0274]
Epoch 44/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.36batch/s, loss=0.457]
Average loss => Training: 0.03 | Validation: 0.46
Model Saved
Epoch 45/100 - Training: 100%|██████████| 1667/1667 [10:00<00:00, 2.78batch/s, loss=0.0234]
Epoch 45/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.46batch/s, loss=0.454]
Average loss => Training: 0.03 | Validation: 0.45
Model Saved
Epoch 46/100 - Training: 100%|██████████| 1667/1667 [09:57<00:00, 2.79batch/s, loss=0.0288]
Epoch 46/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.26batch/s, loss=0.457]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 47/100 - Training: 100%|██████████| 1667/1667 [09:59<00:00, 2.78batch/s, loss=0.0326]
Epoch 47/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.10batch/s, loss=0.461]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 48/100 - Training: 100%|██████████| 1667/1667 [09:57<00:00, 2.79batch/s, loss=0.0252]
Epoch 48/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.23batch/s, loss=0.461]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 49/100 - Training: 100%|██████████| 1667/1667 [09:58<00:00, 2.79batch/s, loss=0.0211]
Epoch 49/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.16batch/s, loss=0.463]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 50/100 - Training: 100%|██████████| 1667/1667 [10:00<00:00, 2.78batch/s, loss=0.0236]
Epoch 50/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.38batch/s, loss=0.463]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 51/100 - Training: 100%|██████████| 1667/1667 [09:56<00:00, 2.79batch/s, loss=0.0249]
Epoch 51/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.14batch/s, loss=0.462]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 52/100 - Training: 100%|██████████| 1667/1667 [10:01<00:00, 2.77batch/s, loss=0.0366]
Epoch 52/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.06batch/s, loss=0.467]
Average loss => Training: 0.02 | Validation: 0.47
Model Saved
Epoch 53/100 - Training: 100%|██████████| 1667/1667 [10:05<00:00, 2.75batch/s, loss=0.0222]
Epoch 53/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.05batch/s, loss=0.464]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 54/100 - Training: 100%|██████████| 1667/1667 [09:52<00:00, 2.81batch/s, loss=0.0254]
Epoch 54/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.37batch/s, loss=0.461]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 55/100 - Training: 100%|██████████| 1667/1667 [09:37<00:00, 2.89batch/s, loss=0.021]
Epoch 55/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.78batch/s, loss=0.462]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 56/100 - Training: 100%|██████████| 1667/1667 [09:32<00:00, 2.91batch/s, loss=0.0222]
Epoch 56/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.69batch/s, loss=0.463]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 57/100 - Training: 100%|██████████| 1667/1667 [09:35<00:00, 2.90batch/s, loss=0.023]
Epoch 57/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.73batch/s, loss=0.464]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 58/100 - Training: 100%|██████████| 1667/1667 [09:44<00:00, 2.85batch/s, loss=0.0231]
Epoch 58/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.67batch/s, loss=0.462]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 59/100 - Training: 100%|██████████| 1667/1667 [09:42<00:00, 2.86batch/s, loss=0.0193]
Epoch 59/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.69batch/s, loss=0.462]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 60/100 - Training: 100%|██████████| 1667/1667 [09:40<00:00, 2.87batch/s, loss=0.0225]
Epoch 60/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.70batch/s, loss=0.463]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 61/100 - Training: 100%|██████████| 1667/1667 [09:39<00:00, 2.87batch/s, loss=0.0222]
Epoch 61/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.76batch/s, loss=0.463]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 62/100 - Training: 100%|██████████| 1667/1667 [09:41<00:00, 2.87batch/s, loss=0.0213]
Epoch 62/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.72batch/s, loss=0.463]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 63/100 - Training: 100%|██████████| 1667/1667 [09:40<00:00, 2.87batch/s, loss=0.0201]
Epoch 63/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.67batch/s, loss=0.467]
Average loss => Training: 0.02 | Validation: 0.47
Model Saved
Epoch 64/100 - Training: 100%|██████████| 1667/1667 [09:38<00:00, 2.88batch/s, loss=0.022]
Epoch 64/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.66batch/s, loss=0.466]
Average loss => Training: 0.02 | Validation: 0.47
Model Saved
Epoch 65/100 - Training: 100%|██████████| 1667/1667 [09:42<00:00, 2.86batch/s, loss=0.0204]
Epoch 65/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.92batch/s, loss=0.464]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 66/100 - Training: 100%|██████████| 1667/1667 [09:40<00:00, 2.87batch/s, loss=0.0237]
Epoch 66/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.70batch/s, loss=0.464]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 67/100 - Training: 100%|██████████| 1667/1667 [10:01<00:00, 2.77batch/s, loss=0.0222]
Epoch 67/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.35batch/s, loss=0.464]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 68/100 - Training: 100%|██████████| 1667/1667 [10:01<00:00, 2.77batch/s, loss=0.0198]
Epoch 68/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.31batch/s, loss=0.464]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 69/100 - Training: 100%|██████████| 1667/1667 [09:58<00:00, 2.79batch/s, loss=0.0224]
Epoch 69/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.49batch/s, loss=0.463]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 70/100 - Training: 100%|██████████| 1667/1667 [10:01<00:00, 2.77batch/s, loss=0.021]
Epoch 70/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.46batch/s, loss=0.461]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 71/100 - Training: 100%|██████████| 1667/1667 [10:03<00:00, 2.76batch/s, loss=0.0215]
Epoch 71/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.27batch/s, loss=0.461]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 72/100 - Training: 100%|██████████| 1667/1667 [10:08<00:00, 2.74batch/s, loss=0.0207]
Epoch 72/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.24batch/s, loss=0.462]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 73/100 - Training: 100%|██████████| 1667/1667 [10:00<00:00, 2.78batch/s, loss=0.0202]
Epoch 73/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.47batch/s, loss=0.461]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 74/100 - Training: 100%|██████████| 1667/1667 [10:00<00:00, 2.77batch/s, loss=0.0192]
Epoch 74/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.48batch/s, loss=0.46]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 75/100 - Training: 100%|██████████| 1667/1667 [09:38<00:00, 2.88batch/s, loss=0.0194]
Epoch 75/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.80batch/s, loss=0.461]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 76/100 - Training: 100%|██████████| 1667/1667 [09:27<00:00, 2.94batch/s, loss=0.0213]
Epoch 76/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.73batch/s, loss=0.458]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 77/100 - Training: 100%|██████████| 1667/1667 [09:36<00:00, 2.89batch/s, loss=0.0182]
Epoch 77/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.34batch/s, loss=0.46]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 78/100 - Training: 100%|██████████| 1667/1667 [10:01<00:00, 2.77batch/s, loss=0.0183]
Epoch 78/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.22batch/s, loss=0.457]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 79/100 - Training: 100%|██████████| 1667/1667 [09:56<00:00, 2.79batch/s, loss=0.0205]
Epoch 79/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.37batch/s, loss=0.458]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 80/100 - Training: 100%|██████████| 1667/1667 [09:53<00:00, 2.81batch/s, loss=0.0187]
Epoch 80/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.56batch/s, loss=0.457]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 81/100 - Training: 100%|██████████| 1667/1667 [09:50<00:00, 2.82batch/s, loss=0.0198]
Epoch 81/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.53batch/s, loss=0.458]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 82/100 - Training: 100%|██████████| 1667/1667 [10:06<00:00, 2.75batch/s, loss=0.0198]
Epoch 82/100 - Validation: 100%|██████████| 417/417 [00:25<00:00, 16.54batch/s, loss=0.458]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 83/100 - Training: 100%|██████████| 1667/1667 [10:08<00:00, 2.74batch/s, loss=0.0188]
Epoch 83/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.24batch/s, loss=0.458]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 84/100 - Training: 100%|██████████| 1667/1667 [09:59<00:00, 2.78batch/s, loss=0.0184]
Epoch 84/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.21batch/s, loss=0.457]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 85/100 - Training: 100%|██████████| 1667/1667 [10:11<00:00, 2.73batch/s, loss=0.0202]
Epoch 85/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.79batch/s, loss=0.457]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 86/100 - Training: 100%|██████████| 1667/1667 [09:45<00:00, 2.85batch/s, loss=0.0199]
Epoch 86/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.69batch/s, loss=0.455]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 87/100 - Training: 100%|██████████| 1667/1667 [09:50<00:00, 2.82batch/s, loss=0.019]
Epoch 87/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.72batch/s, loss=0.456]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 88/100 - Training: 100%|██████████| 1667/1667 [09:55<00:00, 2.80batch/s, loss=0.0189]
Epoch 88/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.70batch/s, loss=0.456]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 89/100 - Training: 100%|██████████| 1667/1667 [09:50<00:00, 2.82batch/s, loss=0.0192]
Epoch 89/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.27batch/s, loss=0.456]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 90/100 - Training: 100%|██████████| 1667/1667 [10:11<00:00, 2.73batch/s, loss=0.0198]
Epoch 90/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.25batch/s, loss=0.456]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 91/100 - Training: 100%|██████████| 1667/1667 [10:12<00:00, 2.72batch/s, loss=0.0189]
Epoch 91/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.31batch/s, loss=0.456]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 92/100 - Training: 100%|██████████| 1667/1667 [10:14<00:00, 2.71batch/s, loss=0.0185]
Epoch 92/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.50batch/s, loss=0.455]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 93/100 - Training: 100%|██████████| 1667/1667 [10:07<00:00, 2.74batch/s, loss=0.0178]
Epoch 93/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.49batch/s, loss=0.456]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 94/100 - Training: 100%|██████████| 1667/1667 [09:51<00:00, 2.82batch/s, loss=0.0189]
Epoch 94/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.52batch/s, loss=0.455]
Average loss => Training: 0.02 | Validation: 0.45
Model Saved
Epoch 95/100 - Training: 100%|██████████| 1667/1667 [09:56<00:00, 2.79batch/s, loss=0.0172]
Epoch 95/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.61batch/s, loss=0.456]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 96/100 - Training: 100%|██████████| 1667/1667 [09:53<00:00, 2.81batch/s, loss=0.0178]
Epoch 96/100 - Validation: 100%|██████████| 417/417 [00:23<00:00, 17.51batch/s, loss=0.456]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 97/100 - Training: 100%|██████████| 1667/1667 [09:59<00:00, 2.78batch/s, loss=0.0179]
Epoch 97/100 - Validation: 100%|██████████| 417/417 [00:24<00:00, 17.14batch/s, loss=0.456]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 98/100 - Training: 100%|██████████| 1667/1667 [09:31<00:00, 2.92batch/s, loss=0.0176]
Epoch 98/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.65batch/s, loss=0.457]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 99/100 - Training: 100%|██████████| 1667/1667 [09:24<00:00, 2.95batch/s, loss=0.0186]
Epoch 99/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.66batch/s, loss=0.457]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Epoch 100/100 - Training: 100%|██████████| 1667/1667 [09:32<00:00, 2.91batch/s, loss=0.0185]
Epoch 100/100 - Validation: 100%|██████████| 417/417 [00:22<00:00, 18.71batch/s, loss=0.457]
Average loss => Training: 0.02 | Validation: 0.46
Model Saved
Training complete!
Total training took 17:41:32 (h:mm:ss)
# Create a DataFrame from our training statistics.
df_stats = pd.DataFrame(data=training_stats)
# Use the 'epoch' as the row index.
df_stats = df_stats.set_index('epoch')
# Display the table.
df_stats
Training Loss Valid. Loss Training Time Validation Time
epoch
1 0.864956 0.592991 0:09:10 0:00:22
2 0.570549 0.530607 0:09:08 0:00:22
3 0.497314 0.472090 0:09:06 0:00:22
4 0.432855 0.420732 0:09:07 0:00:22
5 0.388082 0.399043 0:09:04 0:00:22
... ... ... ... ...
96 0.018025 0.456091 0:09:53 0:00:24
97 0.017923 0.456495 0:09:59 0:00:24
98 0.017873 0.456675 0:09:32 0:00:22
99 0.017809 0.456871 0:09:25 0:00:22
100 0.017718 0.457028 0:09:32 0:00:22
100 rows × 4 columns
# Use plot styling from seaborn.
sns.set(style='darkgrid')
# Set the plot size and font size.
sns.set(font_scale=1.5)
plt.rcParams["figure.figsize"] = (12,6)
# Plot the learning curve.
plt.plot(df_stats['Training Loss'], 'b-o', label="Training")
plt.plot(df_stats['Valid. Loss'], 'g-o', label="Validation")
# Label the plot.
plt.title("Training & Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
# Set x-ticks for the length of epochs
num_epochs = len(df_stats)
plt.xticks(range(0, num_epochs, 10))
plt.show()
# Load the tokenizer
tokenizer = GPT2Tokenizer.from_pretrained(args.output_dir)
# Load the trained model
model_config = GPT2Config.from_pretrained('gpt2', vocab_size=len(tokenizer))
model = CustomGPT2LMHeadModel(model_config)
model.load_state_dict(torch.load(os.path.join(args.output_dir, args.model_name)))
# Move the model to the appropriate device (GPU if available, otherwise CPU)
model = model.to(device)
test_df = pd.read_csv(args.test_data)
# Generates the answer for the data test.
model.eval()
def generate_ans(question: str):
responses = []
input_prompt = question
prompt = f"\n<|startoftext|>[WP] {
input_prompt} \n[RESPONSE]"
generated = torch.tensor(tokenizer.encode(prompt)).unsqueeze(0)
generated = generated.to(device)
sample_outputs = model.generate(
generated,
do_sample=True,
top_k=50,
max_length = 512,
top_p=0.95,
num_return_sequences=1
)
for i, sample_output in enumerate(sample_outputs):
# Flatten the tensor if necessary
if sample_output.dim() > 1:
sample_output = sample_output.squeeze()
# Decode to text
response_text = tokenizer.decode(sample_output.tolist(), skip_special_tokens=True)
# Split based on your markers
wp_responses = re.split(r"\[WP\].*?\n|\[RESPONSE\]", response_text)[1:]
return wp_responses[1].strip() if wp_responses else "No response found"
text_file = os.path.join(args.output_dir, args.save_text_file)
answers1 = []
with open(text_file, 'w') as f:
for i, row in tqdm(test_df.iterrows(), total=len(test_df)):
question, answer = row
answer_gpt = generate_ans(question)
answers1.append(answer_gpt)
f.write(f"Question {
i+1}/{
len(test_df)} => {
question}\n")
f.write(f"Answer => {
answer}\n")
f.write(f"Predicted Answer => {
answer_gpt}\n")
f.write('\n\n')
# Optionally, you can print a message indicating that the output has been saved
print(f"Output saved to {
text_file}")
0%| | 0/2081 [00:00<?, ?it/s]
100%|██████████| 2081/2081 [4:27:20<00:00, 7.71s/it]
Output saved to models_custom_1\predicted_answer.txt
def calculate_rouge_scores(preds, original_text_col, predicted_result_col):
rouge_scores = []
hyps = [] # list of predicted answers
refs = [] # list of reference answers
for index, row in preds.iterrows():
act_ans = str(row[original_text_col])
pred_ans = str(row[predicted_result_col])
hyps.append(pred_ans)
refs.append(act_ans)
rouge = Rouge()
scores = rouge.get_scores(hyps, refs, avg=True)
rouge_scores.append(scores)
# Create a list of dictionaries for tabulating the scores
score_table = [{
'Metric': metric, 'Precision': score['p'], 'Recall': score['r'], 'F1-Score': score['f']} for metric, score in scores.items()]
metrics_df = pd.DataFrame(score_table)
return metrics_df
# Add the predicted answers as a new column in the dataframe
test_df[args.predicted_result] = answers1
test_predict = os.path.join(args.output_dir, args.predict_file)
# Save the updated dataframe to a new CSV file
test_df.to_csv(test_predict, index=False)
print(len(answers1))
# Load the QApairs.csv file into a pandas dataframe
preds = pd.read_csv(test_predict)
# Add the predicted answers as a new column in the dataframe
test_df[args.predicted_result] = answers1
test_predict = os.path.join(args.output_dir, args.predict_file)
# Save the updated dataframe to a new CSV file
test_df.to_csv(test_predict, index=False)
metrics_df = calculate_rouge_scores(preds, args.original_text, args.predicted_result)
metrics_df
Metric Precision Recall F1-Score
0 rouge-1 0.600745 0.502953 0.528094
1 rouge-2 0.469578 0.412039 0.424645
2 rouge-l 0.584838 0.492629 0.516065
4. VipAct: Visual-Perception Enhancement via Specialized VLM Agent Collaboration and Tool-use
Authors: Zhehao Zhang, Ryan Rossi, Tong Yu, Franck Dernoncourt, Ruiyi Zhang,
Jiuxiang Gu, Sungchul Kim, Xiang Chen, Zichao Wang, Nedim Lipka
https://arxiv.org/abs/2410.16400
5. Enhancing Multimodal Affective Analysis with Learned Live Comment Features
Authors: Zhaoyuan Deng, Amith Ananthram, Kathleen McKeown
https://arxiv.org/abs/2410.16407

通过学习实时评论特征增强多模态情感分析
摘要
实时评论,也称为Danmu,是与视频内容同步的用户生成消息。这些评论直接叠加在流媒体视频上,实时捕捉观众情绪和反应。尽管先前的工作已经利用实时评论进行情感分析,但由于不同视频平台上实时评论的相对稀缺性,其使用受到限制。为了解决这个问题,我们首先构建了一个包含英语和中文视频的实时评论用于情感分析(LCAffect)数据集,这些视频涵盖了多样的类型,激发了广泛的情绪。然后,使用这个数据集,我们通过对比学习训练一个视频编码器,以产生用于增强多模态情感内容分析的合成实时评论特征。通过在广泛的英语和中文情感分析任务(情感、情绪识别和讽刺检测)上的全面实验,我们证明了这些合成实时评论特征显著提高了性能,超过了最先进的方法。我们将在发表后发布我们的数据集、代码和模型。
研究背景
实时评论(Danmaku)起源于日本,在中国流行。这个系统将实时用户生成的消息直接叠加在在线视频流上。这些评论与视频的时间线同步,提供了丰富的用户互动层,提供了对用户情绪、用户反应和视频更广泛背景的洞察。这些评论的丰富性使它们成为增强多模态情感分析的理想资源,多模态情感分析旨在解释和分类视频的情感内容和动态。尽管先前的研究已经展示了实时评论如何提高情感预测等情感分析任务的性能,但其更广泛的应用受到限制。许多视频平台不支持实时评论,使得这些洞察对于这些平台上的视频无法实现。因此,实时评论的稀缺性在充分利用其分析潜力方面提出了重大挑战。
问题与挑战
- 实时评论的稀缺性:许多视频平台不支持实时评论,限制了这些方法的实际应用。
- 情感分析的数据集限制:现有的大规模实时评论数据集主要针对实时评论生成任务,通常包含大量流行内容类型,如电子游戏、体育和音乐视频,这些类别通常缺乏详细情感分析所需的丰富情感背景。
- 多模态情感分析的挑战:以往的多模态情感计算通常依赖于手工算法进行初始特征提取,但这种方法有限,无法捕捉数据的全部复杂性。
如何解决
- 构建数据集:构建了一个大规模、多样化的数据集,包括日常生活视频和双语电视节目、电影和纪录片,使我们的系统能够学习各种情境下的广泛情感体验。
- 对比学习:利用构建的数据集,开发了一个多模态编码器,通过对比不同情境有效地从收集的视频和评论中学习,并能够从视频中产生合成的实时评论特征,从而在没有实时评论的情况下推断情感背景。
- 多模态融合模型:提出了一个下游多模态融合模型,用于情感分析任务,不仅利用三种模态,还利用合成的实时评论特征。
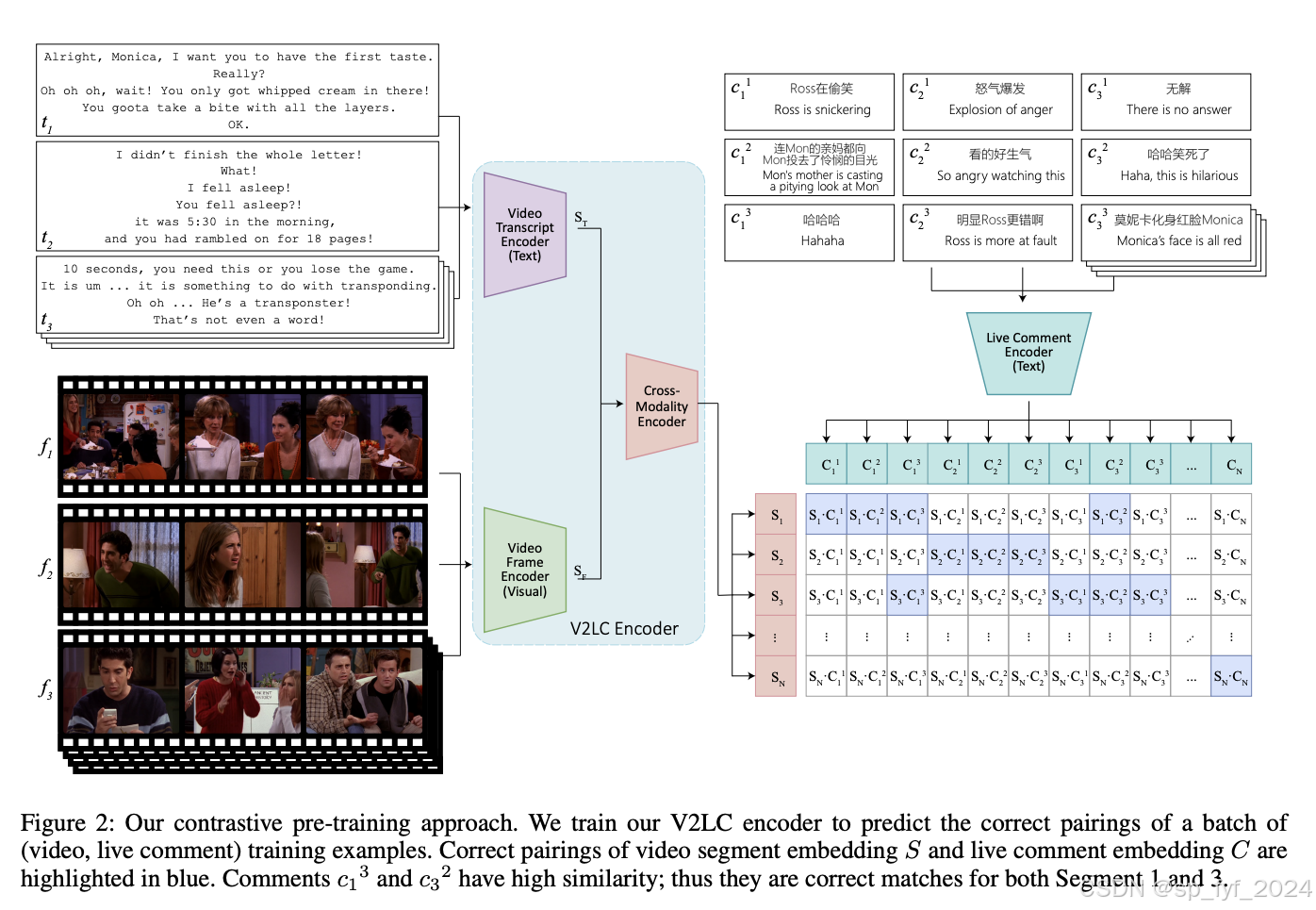
创新点
- LCAffect数据集:超过1100万条实时评论的庞大语料库,包括双语视频内容(中文和英文),涵盖多样的主题和类型,策划以捕捉广泛的情绪。
- 对比编码器:学习将视频投影到实时评论表示空间,允许为任何视频推断合成的实时评论特征。
- 下游多模态融合模型:一个用于情感分析任务的下游多模态融合模型,它不仅利用三种模态,还利用合成的实时评论特征。
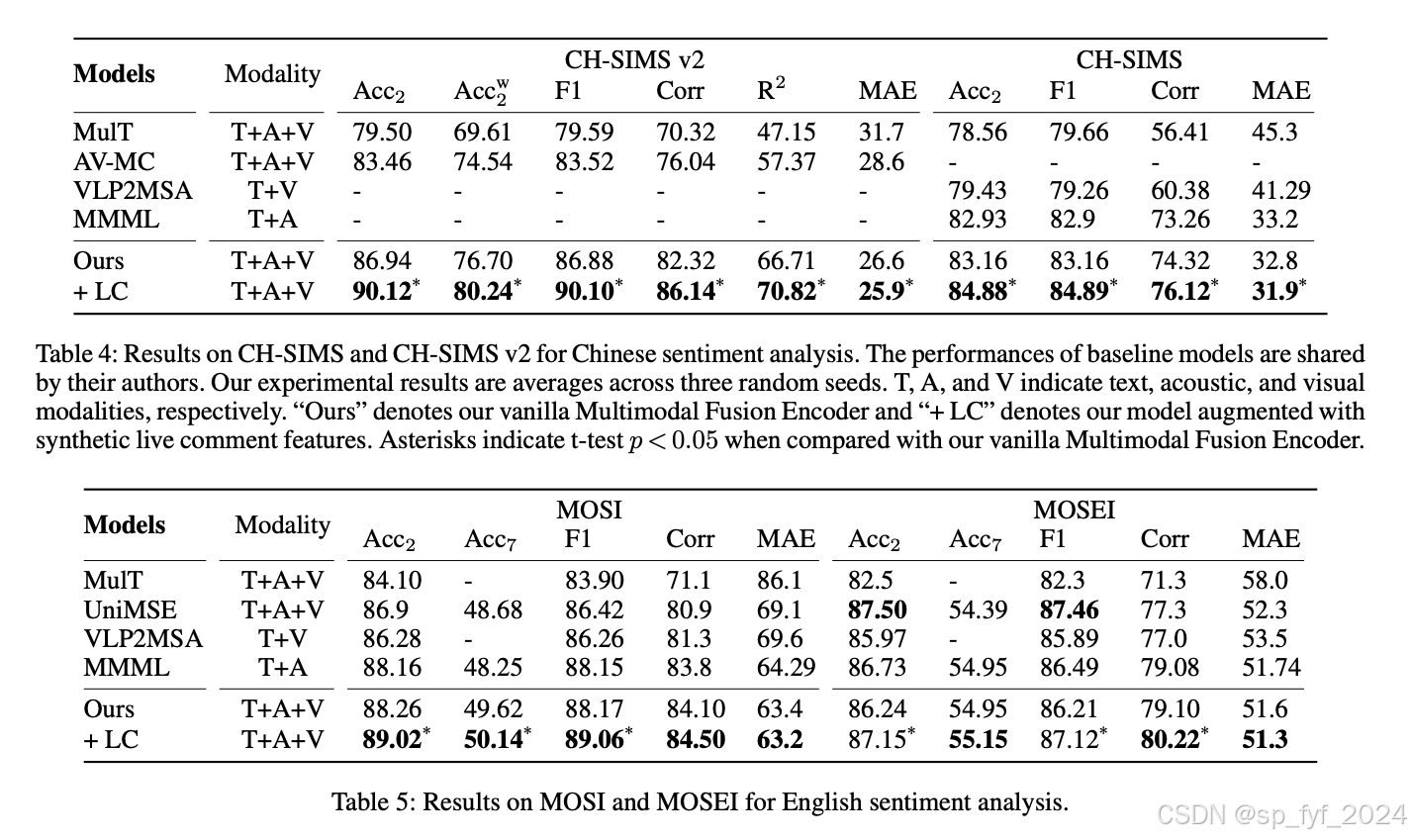
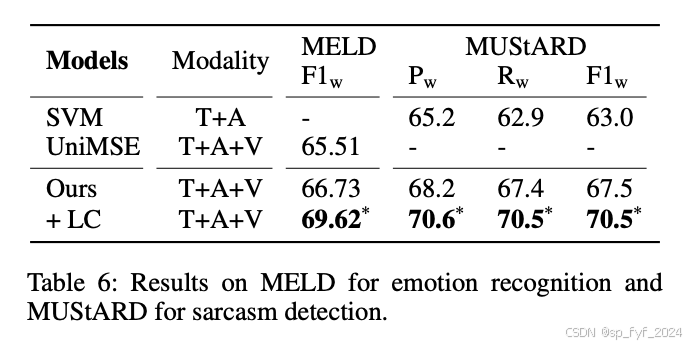
- 新SOTA性能:在多个情感分析任务中实现了新的SOTA性能,包括在CH-SIMS v2(情感分析)上的准确率提高了3.18个百分点,在MELD(情绪识别)上的F1提高了2.89个百分点,在MuSTARD(讽刺检测)上的F1提高了3.0个百分点。
算法模型
- 对比预训练:采用CLIP风格的对比预训练方法。在训练阶段,将每个视频分割成段,对于每个视频段,收集相关的文本转录、视频帧和实时评论,并将该段作为单独的训练样本。
- 多模态融合编码器:利用大规模预训练的编码器跨所有三种模态(文本、声学和视觉)进行更全面的情感任务建模。
- 合成实时评论特征增强:在下游任务中,应用自注意力到合成实时评论特征,然后将其与多模态表示融合,通过前馈层处理这些组合特征。
实验效果
重要数据与结论
- 情感分析:在CH-SIMS v2上,准确率提高了3.18个百分点,在CH-SIMS上,平均绝对误差(MAE)降低了0.9个百分点。
- 情绪识别:在MELD上,F1提高了2.89个百分点。
- 讽刺检测:在MuSTARD上,F1提高了3.0个百分点。
推荐阅读指数
5星(满分5星)
这篇文章详细介绍了如何通过合成实时评论特征增强多模态情感分析,提供了深入的技术细节、实验结果和模型性能的全面比较。该研究的成功展示了合成实时评论特征在多模态情感分析中的潜力,为未来的情感分析研究提供了新的方向。
后记
Rule1: 如果您对我的博客内容感兴趣,欢迎三连击(关注、点赞和评论),我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。
Rule2: 如果我的文章帮助或者触动了你,可以自愿赞赏我一瓶快乐肥宅水:) , 点击打赏,为每个努力的技术人点赞!