Qwen2.5
论文
无
模型结构
Qwen2.5与qwen2模型结构一致。就 Qwen2.5 语言模型而言,所有模型都在我们最新的大规模数据集上进行了预训练,该数据集包含多达 18T tokens。相较于 Qwen2,Qwen2.5 获得了显著更多的知识(MMLU:85+),并在编程能力(HumanEval 85+)和数学能力(MATH 80+)方面有了大幅提升。此外,新模型在指令执行、生成长文本(超过 8K 标记)、理解结构化数据(例如表格)以及生成结构化输出特别是 JSON 方面取得了显著改进。 Qwen2.5 模型总体上对各种system prompt更具适应性,增强了角色扮演实现和聊天机器人的条件设置功能。与 Qwen2 类似,Qwen2.5 语言模型支持高达 128K tokens,并能生成最多 8K tokens的内容。
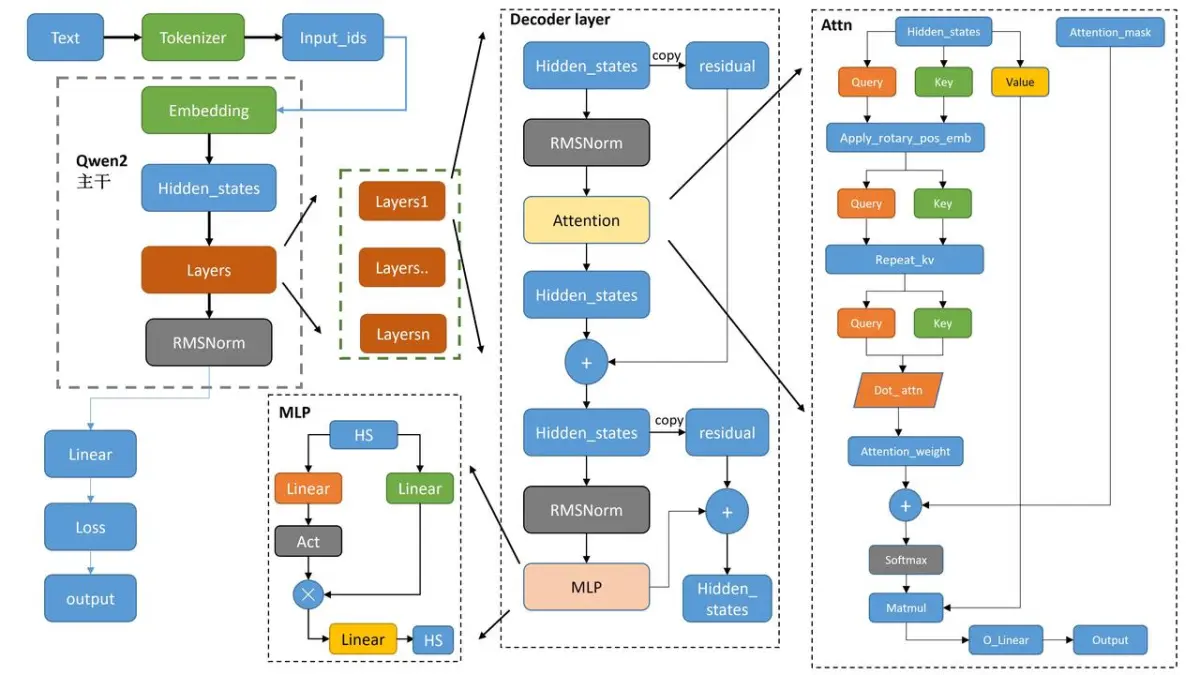
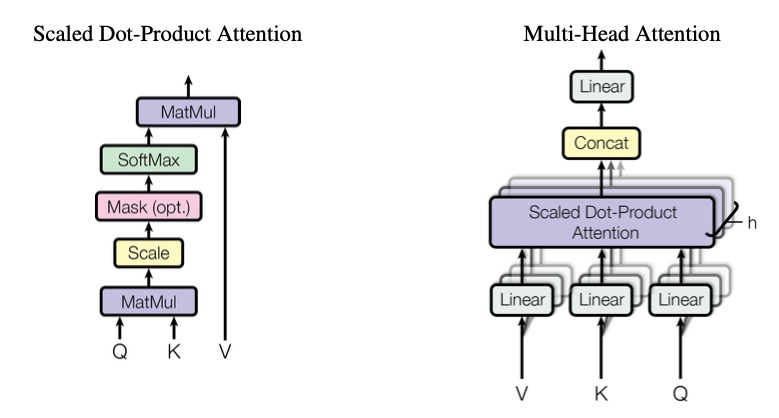
算法原理
Qwen2.5仍然是一个典型decoder-only的transformers大模型结构,主要包括文本输入层、embedding层、decoder层、输出层及损失函数。
环境配置
Docker(方法一)
推荐使用docker方式运行, 此处提供光源拉取docker镜像的地址与使用步骤
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.2-py3.10
docker run -it --shm-size=1024G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name qwen2.5_72B_pytorch <your IMAGE ID> bash # <your IMAGE ID>为以上拉取的docker的镜像ID替换,本镜像为:4555f389bc2a
cd /path/your_code_data/
cd LLaMA-Factory
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install e . -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install deepspeed-0.12.3+gita724046.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl
Tips:以上dtk驱动、python、torch、vllm等DCU相关工具版本需要严格一一对应。
Dockerfile(方法二)
此处提供dockerfile的使用方法
docker build -t qwen2.5:latest .
docker run -it --shm-size=1024G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name qwen2.5_pytorch qwen2.5 bash
cd /path/your_code_data/
cd LLaMA-Factory
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install e . -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install deepspeed-0.12.3+gita724046.abi1.dtk2404.torch2.1.0-cp310-cp310-manylinux_2_31_x86_64.whl
Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装。
DTK驱动:dtk24.04.2
python:3.10
torch:2.1.0
flash-attn:2.0.4
vllm:0.5.0
xformers:0.0.25
triton:2.1.0
deepspeed:0.12.3
apx:1.1.0
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
其它非深度学习库参照requirement.txt安装:
cd /path/your_code_data/
cd LLaMA-Factory
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install e . -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
数据集
使用alpaca_gpt4_zh数据集,已经包含在data目录中,具体文件为alpaca_gpt4_data_zh.json
训练数据目录结构如下,用于正常训练的完整数据集请按此目录结构进行制备:
── data
├── alpaca_zh_demo.json
├── alpaca_en_demo.json
├── identity.json
└── ...
训练
使用LLaMA-Factory框架微调
单机单卡(LoRA-finetune)
# 注意:根据自己的模型切换.yaml文件中的模型位置并调整其他参数
# 单卡推理将模型改为较小size的模型地址
cd /path/your_code_data/
cd LLaMA-Factory
HIP_VISIBLE_DEVICES=0 FORCE_TORCHRUN=1 llamafactory-cli train examples/train_lora/qwen2.5_lora_sft_ds3.yaml
单机多卡(LoRA-finetune)
4卡微调
#四卡微调72B模型需要使用ZeRO Offload 优化的技术,使用CPU来缓解部分GPU显存占用
HIP_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train examples/train_lora/qwen2.5_lora_sft_offload_ds3.yaml
8卡微调
#lora微调
llamafactory-cli train examples/train_lora/qwen2.5_lora_sft_ds3.yaml
推理
使用vllm框架推理
单机单卡
#注意:根据自己的模型切换文件中的模型位置并调整其他参数
cd /path/your_code_data/
python ./inference_vllm/Qwen2.5_7B_inference.py
单机多卡
python ./inference_vllm/Qwen2.5_72B_inference.py
其中,prompts为提示词,model为模型路径,tensor_parallel_size=4为使用卡数。
result
使用的加速卡:8张 K100_AI 模型:qwen2.5-72B

精度
模型:qwen2.5-72B
数据: identity,alpaca_zh_demo,alpaca_en_demo
训练模式:LoRA finetune;zero3训练
硬件:8卡,k100 AI
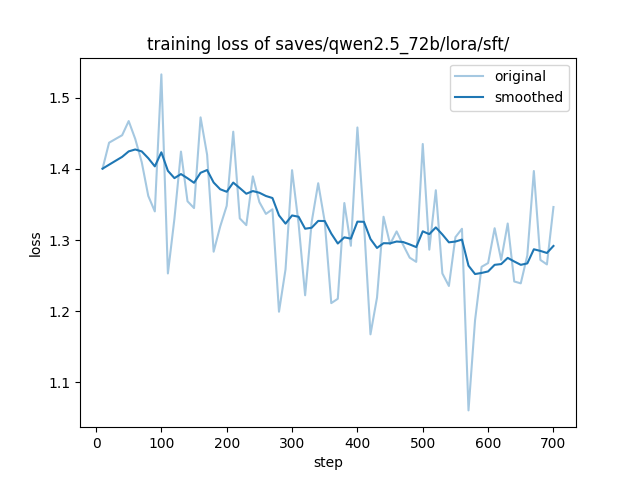
在DCU上训练的收敛情况:
应用场景
算法类别
对话问答
热点应用行业
科研,教育,政府,金融
预训练权重
qwen2.5-7B-Instruct模型下载SCNet链接
qwen2.5-72B-Instruct模型下载SCNet链接
其他size的模型可在SCNet进行搜索下载