CLIP
论文
Learning Transferable Visual Models From Natural Language Supervision
模型结构
CLIP 模型有两个主要组件,一个文本编码器和一个图像编码器。对于文本编码器,使用了Transformer;对于图像编码器采用了ResNet和Vision Transformer(ViT)。

算法原理
CLIP通过最大化文本-图像匹配得分同时训练一个图像编码器和文本编码器。

环境配置
Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run --shm-size 50g --network=host --name=clip --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it <your IMAGE ID> bash
python setup.py install
Dockerfile(方法二)
docker build -t <IMAGE_NAME>:<TAG> .
docker run --shm-size 50g --network=host --name=clip --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it <your IMAGE ID> bash
python setup.py install
Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
DTK驱动:dtk24.04.1
python:python3.10
torch: 2.1.0
torchvision: 0.16.0
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
2、其它非特殊库参照requirements.txt安装
python setup.py install
数据集
无
训练
无
推理
python tests/simple_test.py --pt <model_name or model_name.pt>
python tests/zero_shot_prediction.py --pt <model_name or model_name.pt>
python tests/linear_probe.py --pt <model_name or model_name.pt>
注意:使用model_name.pt会读取pretrained_models文件夹下的已下载模型,使用模型名称model_name则会自动下载模型。
result
python tests/zero_shot_prediction.py --pt ViT-B-32.pt
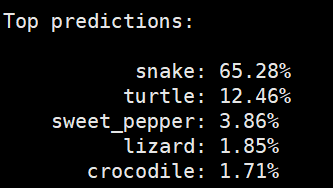
精度
无
应用场景
算法类别
图像分类
热点应用行业
电商,绘画,交通
预训练权重
下载模型后放入pretrained_models文件夹中(需要自行创建)。
原始链接
RN50 / RN101 / RN50x4 / RN50x16 / RN50x64 / ViT-B/32 / ViT-B/16 / ViT-L/14 / ViT-L/14@336px
SCNet 高速通道