前言
在信息技术日新月异的今天,我们正站在技术的最前沿,探索着如何利用最新的科技手段提升工作效率,创造更大的价值。近年来,随着人工智能技术的不断进步,智能文档处理工具以其高效、准确的特点,迅速成为开发者们的新宠。而在CSDN第五届“1024程序员节”上,合合信息正式发布的智能文档处理“百宝箱”,更是将这一趋势推向了新的高潮。
一、背景与趋势
随着数字化时代的到来,信息量的爆炸式增长使得文档处理成为了一项庞大的任务。无论是企业内部的管理文件,还是外部客户提供的合同、报告等,都需要人们投入大量的时间和精力进行阅读、解析和处理。传统的文档处理方式不仅效率低下,而且容易出错,难以满足现代企业的快速响应需求。
此时,人工智能技术的崛起为文档处理带来了革命性的变化。通过深度学习、自然语言处理等技术,智能文档处理工具能够自动解析文档内容,提取关键信息,并以结构化的形式呈现出来。这种自动化的处理方式不仅提高了工作效率,还降低了人为错误的概率,为企业数字化转型提供了有力支持。
二、智能文档处理“百宝箱”介绍
在CSDN“1024程序员节”上,合合信息推出的智能文档处理“百宝箱”备受瞩目。这款“百宝箱”集合了多种先进的文档处理工具,旨在为我们提供一站式的高效解决方案。

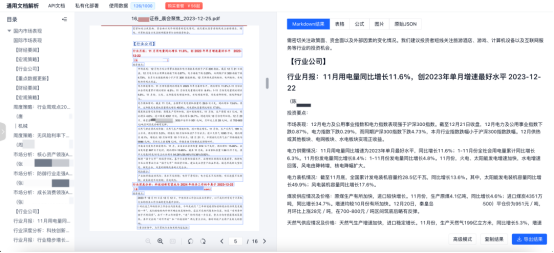
1. 可视化文档解析前端TextIn ParseX
TextIn ParseX是“百宝箱”中的一款核心工具,它提供了可视化文档解析的强大功能,极大地提升了文档处理的效率和准确性。通过这款工具,开发者们不仅可以直观地看到文档解析后的效果,还能对解析结果进行细致的校对和修改,从而确保了文档信息的精准无误。
技术框架:ParseX-Frontend是基于React框架开发的,使用了ES6语言,能够清晰地展示OCR或PDF解析的结果,并提供了丰富的可视化和交互功能。
功能特点:
1、预览渲染,支持主流图片格式和PDF文件的预览渲染,提供缩放和旋转功能。
2、Markdown结果渲染,支持各级标题、图片、公式的渲染展示。

3、元素提取与位置溯源,能够提取并展示各类解析元素,如表格、公式、图片等,并支持解析元素文档位置溯源,即原文画框标注各元素位置,可以点击画框跳转解析结果,也可以点击解析结果跳转原文画框。
4、目录还原,能够还原展示各层级目录树,并支持点击跳转相应章节。
5、灵活的参数配置,支持接口调用选项参数,可以配置不同参数组合,获取相应解析结果。
6、便捷的复制导出功能,支持复制和导出Markdown文件,以及复制解析后的表格和图片。
应用场景:ParseX-Frontend适用于OCR或PDF解析结果审核校对、效果测评场景,也适用于翻译软件等一系列需要可视化比对的工具。
2. 向量化acge-embedding模型
acge-embedding模型是“百宝箱”中的另一款重磅工具,它通过将海量的文本数据转化为有方向、有数值的列表(即向量),实现了文本的高效表示和检索。这款模型的出现,为文档处理和信息检索领域带来了革命性的变化。具体来说,acge-embedding模型利用先进的嵌入技术,将文本数据转化为向量形式。这些向量不仅保留了文本的语义信息,还使得相似的文本在向量空间中具有相近的距离。这种特性使得我们可以方便地进行文本相似性计算和分类操作。例如,在内容审核、意图分析和情感分析等场景中,acge-embedding模型能够准确地判断文本的语义类别和情感倾向,为后续的决策提供支持。
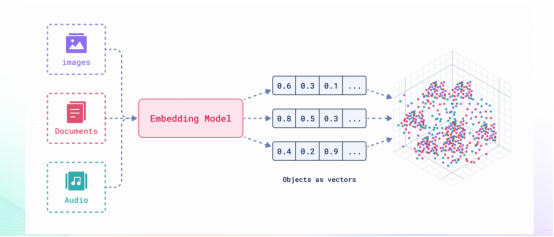
技术背景:acge_text_embedding模型由TextIn团队开发,在C-MTEB(Chinese Massive Text Embedding Benchmark)评测中登顶第一,展现了卓越的性能。
核心优势:
1、俄罗斯套娃表征学习(MRL)框架,类似于俄罗斯套娃结构,生成的嵌入向量也是一个嵌套结构,旨在创建一个嵌套的、多粒度的表示向量。每个较小的向量都是较大向量的一部分,且可以独立用于不同的任务。
2、多粒度表示,通过MRL技术,实现了从粗到细的层次化表示,一次训练即可获取不同维度的表征。
3、策略学习与持续学习,采用策略学习训练方式,显著提升了检索、聚类、排序等任务上的性能;同时,持续学习训练方式克服了神经网络存在的灾难性遗忘问题。
4、高效与灵活,支持可变输出维度,用户可以根据实际需求输入维度参数,获得指定维度的向量,大大降低了推理和部署的成本。
应用场景:
1、搜索引擎,根据查询字符串和文档之间的向量相似性来排名搜索结果,提供更加准确和相关的内容。
2、文本分类和聚类,将文本数据转换为数值型向量表示,使得分类算法可以根据文本向量与不同类别之间的相似性来进行分类或聚类。
3、推荐系统,帮助构建用户和项目的表示特征,使得推荐系统能够根据用户历史行为或偏好,计算用户向量与项目向量之间的相似度,从而向用户推荐具有相关性的项目。
4、异常检测,将文本数据映射到一个向量空间中,并通过度量文本向量与正常数据之间的距离或相似性来识别异常值。
3. 文档解析测评工具markdown_tester
在选择文档解析工具时,如何评估其性能是一个关键问题。合合信息在“百宝箱”中提供了文档解析测评工具markdown_tester,为开发者们提供了一个科学、客观的评估标准,极大地简化了这一复杂过程。markdown_tester通过针对表格、段落、标题、阅读顺序以及公式等文档中的关键元素进行深入的定量测评,确保了评估结果的全面性和准确性。其生成的直观的雷达图,更是将测评结果以图形化的方式清晰展现。在雷达图上,各个文档解析工具在不同指标上的表现一目了然,这不仅包括基本的文本识别准确性,还涵盖了解析的深度、广度以及处理复杂文档结构的能力。
技术特点:该工具针对表格、段落、标题、阅读顺序、公式等进行了定量测评,具有便捷的使用方式和丰富的测评维度。
使用方式:支持上传任意样本进行测试,并按照指定的文件夹结构放置待测评样本和真值文件。通过运行指定的命令即可开始测评。
应用场景:适用于文档处理、OCR技术、大模型问答等场景下的文档解析效果评估。它能够帮助用户迅速、高效地评估各款解析产品在业务场景下的表现,并减少不必要的复杂性。

三、智能文档处理“百宝箱”的应用场景
智能文档处理“百宝箱”以其强大的功能和广泛的应用场景,成为了开发者们的新宠。以下是“百宝箱”配合文档解析技术在几个典型场景中的应用案例:
1.知识库开发
在数字化转型的浪潮中,知识库成为企业获取竞争优势的重要工具。然而,搭建知识库并非易事,文件解析的精度直接影响知识库数据的准确性。智能文档处理“百宝箱”中的文档解析测评工具能够全面、定量评估公式、表格等关键指标的解析效果,帮助开发者筛选出最适合的文档解析工具。同时,通过acge文本向量化模型,可以对制造业等行业的海量数据源进行统一管理和集成,增强知识库的全面性和准确性。

2.智能文档抽取
在业务实践中,开发者经常需要从非结构化文本中提取文字、图片等信息。智能文档处理“百宝箱”配合强大的文档解析能力,能够准确识别并提取文档中的文本、图像、表格等元素。此外,前端组件还支持对解析结果进行可视化交互和编辑修正,以实现更高精度的解析效果。这一功能在智能文档抽取场景中尤为重要,可以帮助开发者快速、准确地获取所需信息。
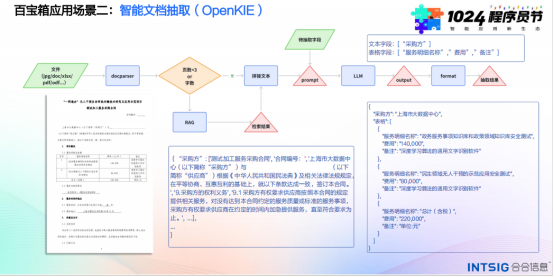
3.大模型预训练语料与数据治理快速入库
随着大模型时代的到来,对高质量语料和数据的需求愈发迫切。合合信息文档解析产品能够处理多种语言和多种文档材料,包括金融报告、国家标准、学术论文等,为大模型提供丰富的预训练语料。同时,通过高效、准确的文档解析能力,可以实现对数据的快速入库和治理,为大模型的训练和应用提供有力支持。

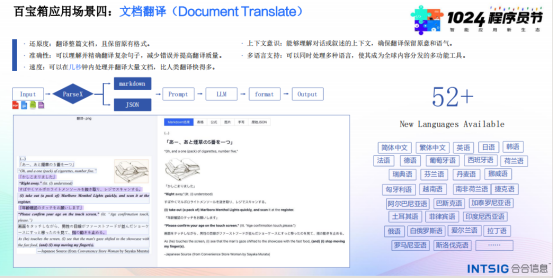
4.文档翻译
在全球化的背景下,文档翻译成为越来越重要的应用场景。文档解析技术能够理解并精确翻译复杂句子,保留原有格式和上下文意识。同时,支持多种语言的翻译,成为全球内容分发的多功能工具。这一功能在跨国企业、国际贸易等领域中具有广泛的应用价值。
5.其他应用场景
除了以上几个主要应用场景外,智能文档处理“百宝箱”还可以应用于其他多个领域。例如,在电子档解析和扫描档识别方面,能够准确识别无线表、跨页表格、页眉、页脚、公式、图像等元素;在云服务综合体验方面,速度快、服务稳定,能够处理大量文档并快速返回结果;此外,还支持公有云API接口,方便开发者将智能文档处理技术集成到自己的应用中。
总结
智能文档处理“百宝箱”通过TextIn ParseX可视化前端、acge-embedding模型和markdown_tester测评工具,为开发者提供了从文档解析、内容管理到性能评估的全面解决方案,显著提升了复杂文档的解析与检索效率,支持多种应用场景,推动了技术共享与协同创新,为开发者提供了高效便捷的支持,提升了效率并激发了技术创新的可能性。
大家如果需要了解更多文档处理权益,可以点击下方链接,获得最新资讯及福利。
https://www.textin.com/activity?tag=znwd-bbx&btn=tj&code=mkt-csdn241024&from=csdn-prtg