线性回归(Linear Regression)是一种基础的回归模型,用于通过一条最优拟合线来预测一个连续数值输出。它被广泛应用于统计学、机器学习和经济学等领域,主要包括简单线性回归和多元线性回归。下面详细介绍其底层原理、实现细节以及代码层面上的实现。
示例:
一元线性回归:
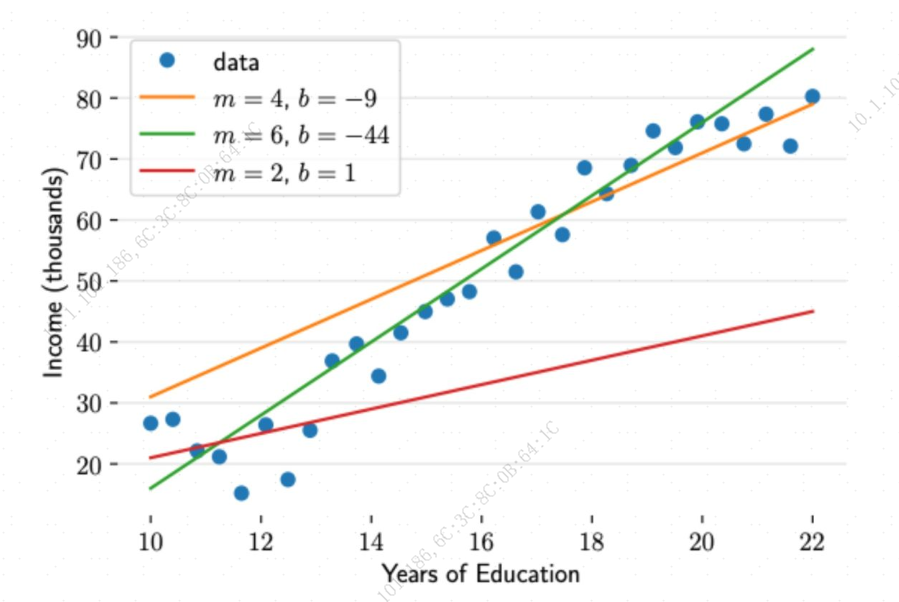
下图反映的是收入和受教育年限的关系
多元线性回归:
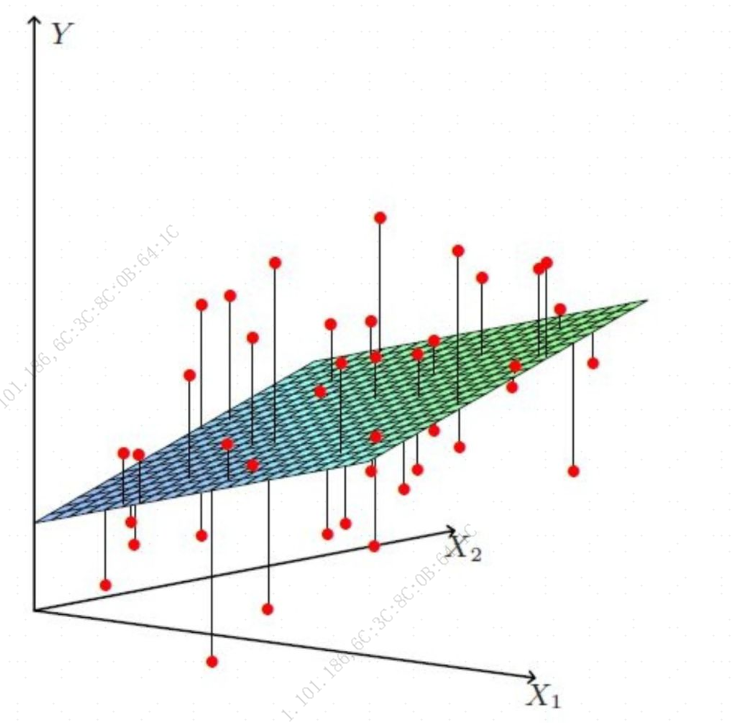
下图反映的是房间面积,所处位置,交通状况和商圈等周边这些特征值和房价的关系
1. 线性回归的基本原理
线性回归模型假设自变量 X 和因变量 y 之间的关系可以通过线性方程来描述:
其中:
- y 是因变量(目标值或预测值)
是自变量(特征)
是截距项(bias)
是特征对应的回归系数(权重)
是误差项,表示模型对数据的误差
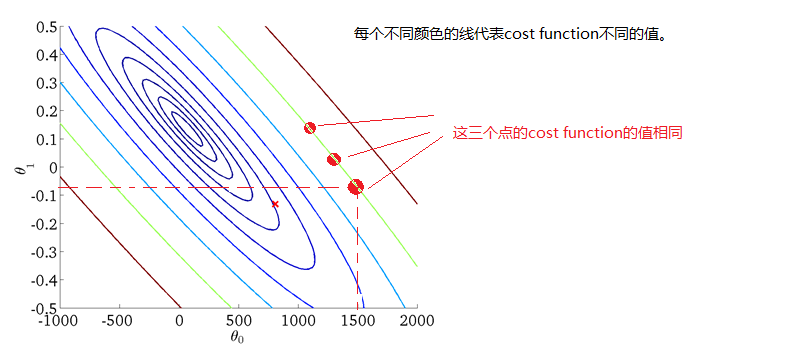
1.1 损失函数:最小化误差
为了找到最优的回归系数 β 值,需要定义一个损失函数来度量预测值和实际值之间的误差。最常用的损失函数是 均方误差(Mean Squared Error, MSE):
其中:
- m 是样本的数量
是第 i 个样本的真实值
是第 i 个样本的预测值
目标是找到一组回归系数,使得均方误差最小,即通过 最小二乘法 来求解回归系数。
1.2 参数估计方法
线性回归参数估计常用的方法有两种:
- 最小二乘法:直接对损失函数求偏导数,进而得到解析解。
- 梯度下降法:通过不断迭代来最小化损失函数,适用于特征多的情况或无解析解的模型。
最小二乘法解析解
在矩阵形式下,令 X 为特征矩阵,y 为标签向量,线性回归的解析解为:
需要注意的是, 的逆矩阵存在的条件是 X 满秩,且特征之间线性独立。
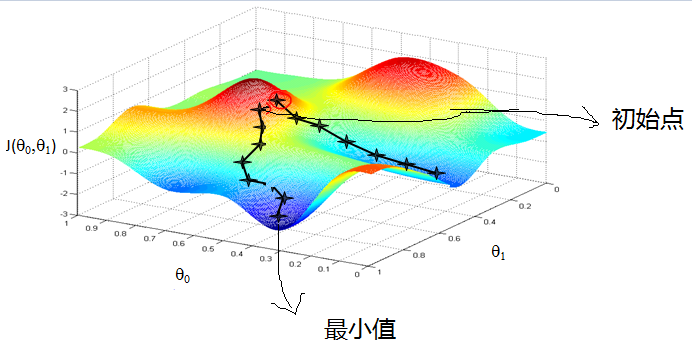
梯度下降法
在大规模数据集或特征多样的情况下,通常用 梯度下降法。其核心思想是对每个参数 按梯度更新,更新公式为:
其中 α 是学习率,控制更新的步长。梯度下降的变种还包括批量梯度下降、小批量梯度下降和随机梯度下降等。
2. 代码层面实现
Python 的 scikit-learn 库提供了简单便捷的线性回归实现,此外,statsmodels 也是一个用于统计建模的库,可以更详细地输出回归结果。
2.1 使用 scikit-learn 实现线性回归
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 假设我们有数据集 X, y
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
在 scikit-learn 中,LinearRegression 默认使用最小二乘法来求解回归系数。
2.2 使用 statsmodels 实现线性回归
statsmodels 提供了更丰富的统计信息和诊断工具,可以帮助评估回归模型的质量。
import statsmodels.api as sm
# 假设我们有数据集 X, y
X = sm.add_constant(X) # 添加截距项
model = sm.OLS(y, X) # 使用普通最小二乘法
results = model.fit() # 拟合模型
# 输出详细的回归结果
print(results.summary())
3. 线性回归模型的优缺点
优点
- 简单易理解:模型假设简单,易于解释。
- 计算高效:解析解计算较快,适合小规模数据集。
- 对线性关系有效:在自变量和因变量呈现线性关系时表现良好。
缺点
- 对异常值敏感:异常值对均方误差影响较大。
- 假设限制:假设变量之间存在线性关系,无法处理非线性问题。
- 多重共线性问题:如果特征间存在多重共线性,回归系数可能不稳定。
4. 线性回归在不同情境下的扩展
4.1 岭回归(Ridge Regression)
在线性回归基础上引入 L2 正则化项来解决多重共线性问题:
岭回归(Ridge Regression),又称 Tikhonov 正则化,是线性回归的一个扩展,用于解决多重共线性问题和过拟合问题。在特征之间存在较强的线性关系(多重共线性)时,线性回归系数可能会不稳定,岭回归通过在损失函数中加入一个 L2 正则化项,惩罚回归系数的大小,从而获得更加稳定的估计。
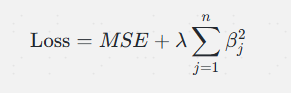
其中:
是回归系数
- λ 是正则化参数,也称为 岭系数,控制惩罚项的强度
当 λ=0 时,岭回归退化为普通线性回归;当 时,所有的回归系数
会趋向于零。
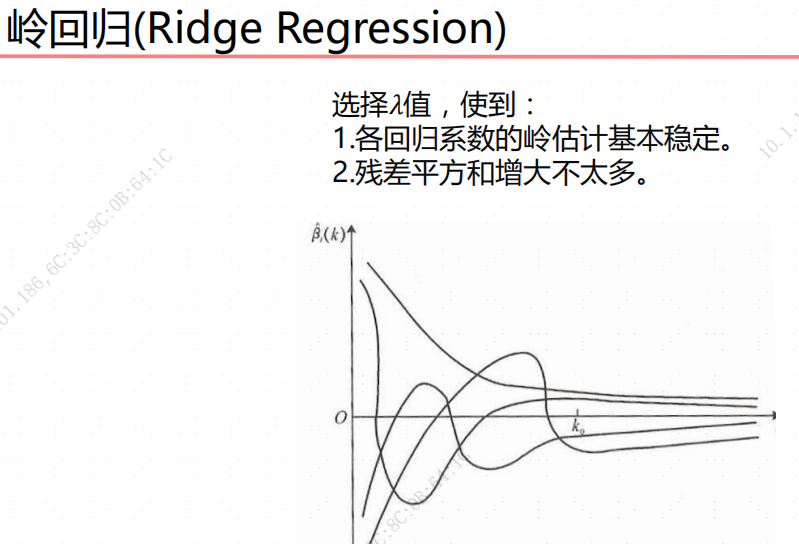
正则化项的作用
L2 正则化项的引入使得模型更倾向于较小的回归系数。这对多重共线性问题特别有效,因为此时特征之间的高度相关性会导致 β 不稳定。加入正则化项后,过大的 β 会受到惩罚,从而使得模型更加稳定。
岭回归的解析解
在矩阵形式下,岭回归的最优解可以表示为:
其中 是单位矩阵,λ 控制正则化强度。当 λ>0 时,
始终是可逆的,即使 X 存在多重共线性。
岭回归的优缺点
优点
- 有效解决多重共线性问题:对特征间高度相关的数据具有稳定性。
- 减少过拟合:正则化项可防止模型对训练数据过度拟合,从而提升泛化能力。
- 系数更稳定:相比普通线性回归,岭回归的系数对数据变化更不敏感。
缺点
- 模型解释性下降:由于正则化项的引入,岭回归的系数通常偏小,导致模型可解释性变差。
- 适用范围受限:岭回归只能对线性关系建模,不能处理显著的非线性数据。
4.2 Lasso 回归(Lasso Regression)
在损失函数中加入 L1 正则化项,实现特征选择:
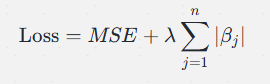
其中:
- λ 是正则化参数,控制正则化项的强度
当 λ 较大时,Lasso 回归会将一些回归系数缩小到零,从而只保留部分特征。正因如此,Lasso 回归不仅能减少过拟合,还可以作为一种特征选择方法。
L1 正则化的特性
L1 正则化的特点是会产生稀疏解,使得某些不重要的特征对应的回归系数缩小为零。这一特性使得 Lasso 回归在特征数量多于样本数量或存在许多不相关特征的数据集中表现出色,因为它可以自动去除对模型影响不大的特征。
Lasso 回归的解析解
与岭回归不同,Lasso 回归通常没有解析解,需要通过迭代算法(如坐标轴下降法)来求解。坐标轴下降法通过依次对每个回归系数进行优化,直到损失函数收敛。
Lasso 回归的优缺点
优点
- 特征选择:能够自动选择特征,将不重要的特征系数缩小为零。
- 减少过拟合:正则化项限制模型复杂度,防止过拟合。
- 适用于高维数据:在高维数据(特征数多于样本数)上,Lasso 回归效果很好,尤其是当特征之间存在较强相关性时。
缺点
- 可能不适用于所有数据集:当特征数量较少且每个特征都很重要时,Lasso 回归可能不合适,因为它会将一些特征系数缩小为零。
- 多重共线性影响:当特征高度相关时,Lasso 可能会随机选择一个特征,而忽略其他相关特征。
Lasso 回归的应用场景
- 基因筛选:在生物信息学中,Lasso 回归常用于基因筛选,将对模型预测影响较小的基因去除。
- 文本特征选择:在自然语言处理(NLP)中,Lasso 可用于选择重要的文本特征。
- 金融数据分析:在预测股票价格或经济指标时,Lasso 可用于自动选择最相关的因素。
4.3 弹性网络(Elastic Net)
弹性网络(Elastic Net)是一种结合了 岭回归 和 Lasso 回归 特性的线性回归方法。它通过同时包含 L1 和 L2 正则化项来平衡特征选择和多重共线性处理,在特征数量较多、特征间高度相关的场景下尤其有效。
结合 L1 和 L2 正则化项:
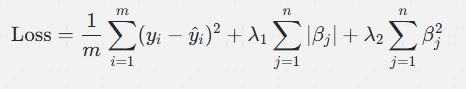
其中:
- λ1 和 λ2 分别控制 L1 和 L2 正则化的强度
正则化的控制参数
弹性网络提供一个参数 混合比 α 用于调整 L1 和 L2 的比例。定义如下:
当 α=1 时,弹性网络变为纯 Lasso 回归;当 α=0 时,弹性网络则退化为岭回归。一般来说,可以在 α∈[0,1] 范围内调整混合比,以实现对稀疏性和稳定性的平衡。
弹性网络的优缺点
优点
- 特征选择:由于包含 L1 正则化项,弹性网络具有类似 Lasso 的特征选择功能。
- 处理多重共线性:由于包含 L2 正则化项,弹性网络可以更好地处理多重共线性问题,回归系数更加稳定。
- 灵活调整:通过调节 L1 和 L2 的比例,可以在特征选择和系数稳定性之间找到适当的平衡。
缺点
- 解释性相对较低:相比于纯 Lasso 或岭回归,弹性网络的解释性稍微复杂一些,因为它同时包含了 L1 和 L2 正则化项。
- 参数选择复杂:需要同时选择 α 和 λ 的值,使得超参数调优更加复杂。
弹性网络的应用场景
- 生物信息学:在基因数据的筛选中,弹性网络可用于同时处理稀疏性和多重共线性问题。
- 文本挖掘和自然语言处理:当文本数据维度高、特征之间相关性强时,弹性网络可以选择关键的文本特征。
- 金融数据建模:在金融市场中,通常使用多维特征来预测价格走势,而弹性网络能自动选择重要的市场因素。
5. 线性回归的应用场景
- 经济预测:如房价预测、股票预测。
- 广告效果分析:分析广告投放量和销售额的关系。
- 市场分析:估算商品销量和价格、季节的关系。
6. 总结
线性回归作为回归分析中的基础模型,通过最小化均方误差来拟合数据,其实现方法包括最小二乘法和梯度下降。线性回归简单易懂,适合小规模数据集,但在特征间存在多重共线性或需要处理非线性关系时需要使用其他变体,如岭回归、Lasso 回归等。