使用肘部法则(Elbow Method)来确定最佳K值是聚类分析中的常用方法,以下是详细的步骤和解释,适合初学者在生产环境中实现。
1. 环境准备
确保已经安装并配置好PySpark环境。你需要有一个可用的Spark集群或本地Spark环境。
2. 数据准备
确保有用户行为数据,这些数据应该经过清洗和预处理。以下是一个简化的加载数据的示例:
from pyspark.sql import SparkSession
# 创建 SparkSession
spark = SparkSession.builder \
.appName("ElbowMethodExample") \
.getOrCreate()
# 加载数据(假设数据在CSV文件中)
df = spark.read.csv("path_to_user_logs.csv", header=True, inferSchema=True)
# 数据清洗(去除缺失值和重复记录)
df = df.dropna(subset=["view_depth", "time_spent", "cart_additions"]).dropDuplicates()
3. 特征工程
将特征向量化,为K-Means聚类做准备。使用VectorAssembler来构建特征向量:
from pyspark.ml.feature import VectorAssembler
# 将特征合并为一个向量
assembler = VectorAssembler(inputCols=["view_depth", "time_spent", "cart_additions"], outputCol="features")
data = assembler.transform(df)
4. 计算不同K值的聚类成本
肘部法则的核心思想是计算不同K值下的聚类成本(即每个聚类的总误差平方和SSE),并通过可视化SSE随K值变化的趋势来确定最佳K值。
以下是详细的实现步骤:
步骤 4.1:计算每个K值的SSE
使用循环遍历不同的K值(例如2到10),并记录每个K值对应的SSE。
from pyspark.ml.clustering import KMeans
# 存储每个K值的SSE
cost = []
K = range(2, 11) # K值范围从2到10
for k in K:
# 创建KMeans模型
kmeans = KMeans(featuresCol="features", k=k)
model = kmeans.fit(data)
# 计算每个模型的SSE
cost.append(model.summary.trainingCost)
步骤 4.2:输出SSE结果
打印每个K值对应的SSE值,以便进行后续分析。
# 打印每个K值的SSE
for k, sse in zip(K, cost):
print(f"K={k}, SSE={sse}")
5. 可视化SSE与K值的关系
通过图表可视化SSE随K值变化的趋势,以便直观分析最佳K值。
步骤 5.1:绘制图表
可以使用matplotlib库进行可视化。首先,确保在环境中安装matplotlib:
pip install matplotlib然后,使用以下代码绘制图表:
import matplotlib.pyplot as plt
# 绘制肘部法则图
plt.figure(figsize=(8, 5))
plt.plot(K, cost, marker='o')
plt.title('Elbow Method for Optimal K')
plt.xlabel('Number of clusters (K)')
plt.ylabel('SSE')
plt.xticks(K)
plt.grid()
plt.show()
6. 确定最佳K值
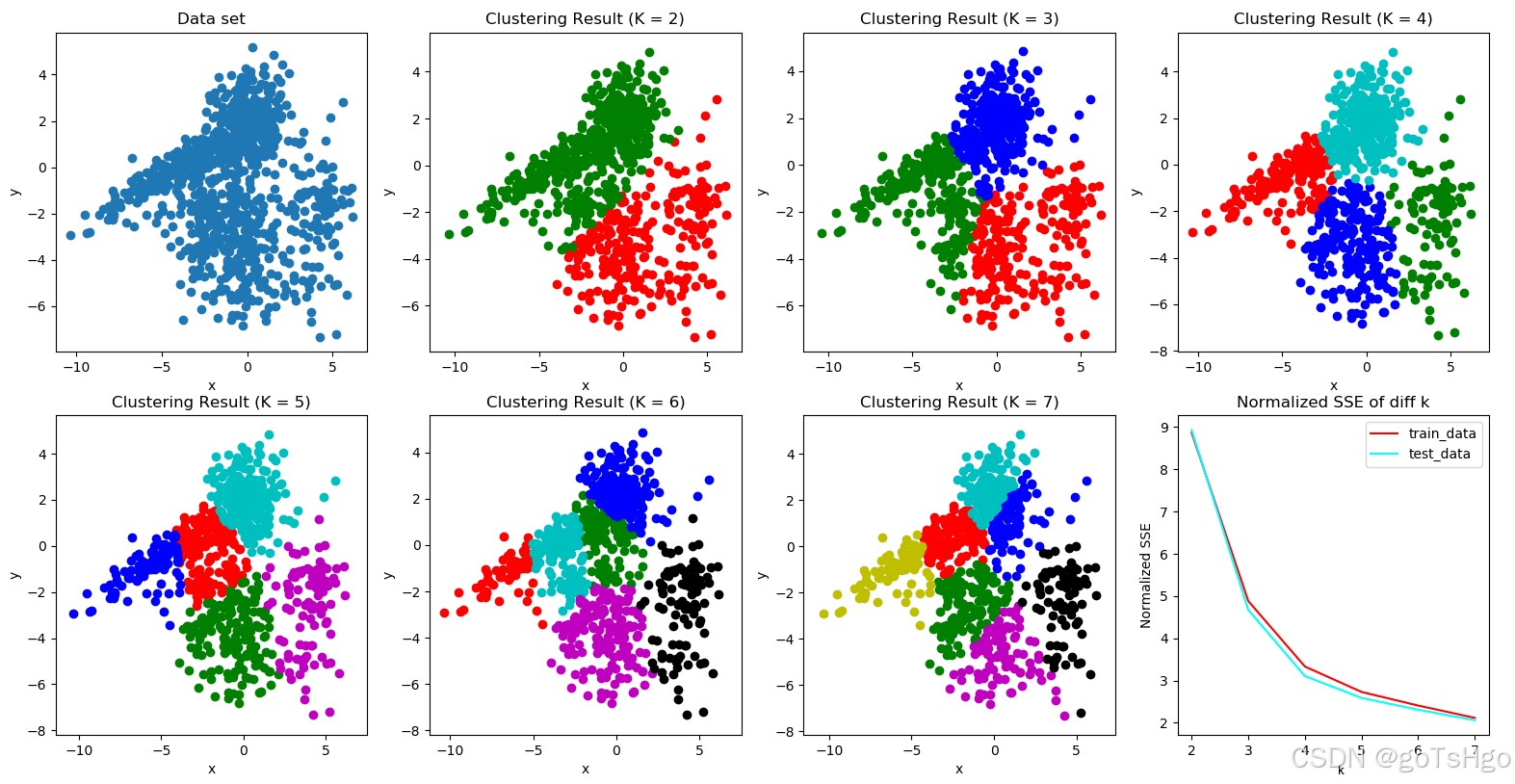
在图表中观察K值与SSE的关系,找到“SSE减少减缓”或“肘部”位置,这个位置对应的K值即为最佳K值。例如,如果SSE在K=4到5之间的下降幅度明显减小,那么K=4可能是一个合理的选择。
7. 应用最佳K值进行聚类
确定最佳K值后,可以使用该K值重新训练K-Means模型:
# 假设最佳K值为4
optimal_k = 4
kmeans = KMeans(featuresCol="features", k=optimal_k)
model = kmeans.fit(data)
# 预测用户群组
predictions = model.transform(data)
# 查看聚类结果
predictions.select("features", "prediction").show(5)
下图可以发现当k=4或者5时是最佳的情况。SSE图像下降幅度最大放缓的情况在4-5之间。
8. 总结
通过以上步骤,您可以使用肘部法则确定最佳K值并进行用户聚类分析。这一过程包括数据加载、特征工程、SSE计算、可视化分析和模型训练,适合初学者在生产环境中实现。