Hadoop3.0.0完全分布式集群搭建
1、前言
Hadoop环境搭建分为三种形式:单机模式、伪分布式模式、完全分布模式
单机模式—— 在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统。
伪分布式—— 也是在一台单机上运行,但不同的是Java进程模仿分布式运行中的各类节点。即一台机器上,既当NameNode,又当DataNode,或者说既是JobTracker又是TaskTracker。没有所谓的在多台机器上进行真正的分布式计算,故称为“伪分布式”。
完全分布式—— 真正的分布式,由3个及以上的实体机或者虚拟机组成的机群。一个Hadoop集群环境中,NameNode,SecondaryName和DataNode是需要分配在不同的节点上,也就需要三台服务器。
前两种模式一般用在开发或测试环境下,生产环境下都是搭建完全分布式模式。
从分布式存储的角度来说,集群中的节点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。
从分布式应用的角度来说,集群中的节点由一个JobTracker和若干个TaskTracker组成。JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。
2、准备工作
集群中三个节点(juju-1【主】、juju-2【备】、juju-3【备】)。注:节点主机名根据自己实际修改即可。(搭建Hadoop集群的每个节点用户名相同)。
其实我们可以直接去Hadoop官网,上面有完整的集群搭建步骤说明。安装Hadoop之前需要安装Java(Hadoop是java开发的,编译及运行都需要使用JDK)和ssh(Hadoop需要通过ssh来启动各个节点的进程)。
3、环境准备
安装vmware linux虚拟机
操作系统:CentOS7
机器:虚拟机3台-----从第一台克隆就可以(master, slave1, slave2 )
JDK:1.8(jdk-8u291-linux-x64.tar.gz)
Hadoop:3.0.0(下载Hadoop-3.0.0)
4、集群搭建步骤
4.1 每台机器安装&配置JDK(1台做好后,克隆出其它机器)
-
创建目录 opt/java
-
上传jdk安装包到 opt/java/
-
在jdk压缩包目录下(我的路径是opt/java/)解压: tar -xvf jdk-8u291-linux-x64.tar.gz
-
追加环境变量 vi /etc/profile
export JAVA_HOME=opt/java/jdk1.8
export CLASSPATH=.:${
JAVA_HOME}/jre/lib/rt.jar:${
JAVA_HOME}/lib/dt.jar:${
JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${
JAVA_HOME}/bin
-
使环境变量生效(xshell页面刷新): source /etc/profile
-
检测jdk正确安装: java -version

5、修改每台机器主机名(hostname)
hostnamectl set-hostname master (立即生效)
hostnamectl set-hostname slave1 (立即生效)
hostnamectl set-hostname slave2 (立即生效)
修改每台机器/etc/hosts文件
vi /etc/hosts

这里的192.168.0.104等是你自己的主机的 IP,查看方式:
xshell或者SecureCRT都行,输入 ifconfig 就可以查。
修改完之后,互ping其它机器,能互ping则说明修改OK,例:在 master 上 ping slave1。
6、配置ssh,实现无密码登录
输入ssh-keygen -t rsa生成公钥和私钥,如下 例子,如果出现冒号就一路回车。
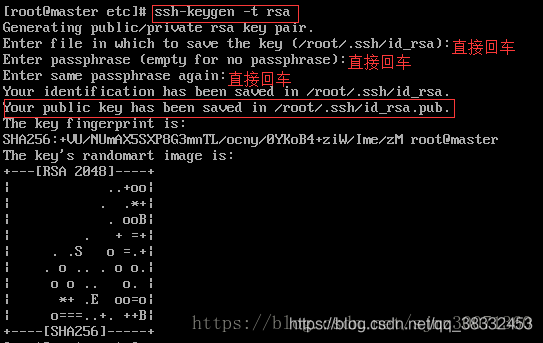
一般公钥私钥都会保存在 root/.ssh下:

然后,去root/.ssh目录下,把新生成的id_rsa.pub中的公钥复制,粘贴到 authorized_keys 文件下,也可以使用命令:cat id_rsa.pub > authorized_keys。
最后,将master上的authorized_keys放到其它机器上(三台主机同步,就是三台主机中的authorized_keys文件是一样的)。
测试是否成功:
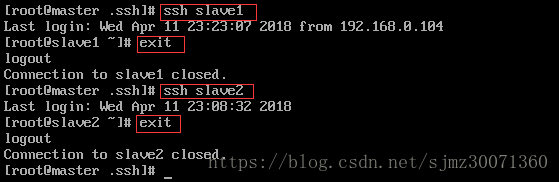
7、开始配置hadoop
1) 在 opt 目录下创建 hadoop文件夹
2) 上传hadoop安装包hadoop-3.0.0.tar.gz到 /opt/hadoop/
3) 解压 tar -xvf hadoop-3.0.0.tar.gz
4) 追加环境变量 vi /etc/profile(其它机器也要相应配置一次hadoop环境变量)
export HADOOP_HOME=/opt/hadoop/hadoop-3.0.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5) 使环境变量生效 source /etc/profile
6) 确认环境变量配置OK,输入命令:
hadoop version
若出现:Hadoop-3.0.0(如果年的不是3.0,那出现你自己的版本就对了)
7) 创建HDFS存储目录
cd /opt/hadoop
mkdir hdfs
cd hdfs
mkdir name data tmp
其中 /opt/hadoop/hdfs/name --存储namenode文件
/opt/hadoop/hdfs/data --存储数据
/opt/hadoop/hdfs/tmp --存储临时文件
8) 修改/opt/hadoop/hadoop-2.9.0/etc/hadoop/hadoop-env.sh文件,设置JAVA_HOME为实际路径,否则启动集群时,会提示路径找不到
例:

9) 修改/opt/hadoop/hadoop-2.9.0/etc/hadoop/yarn-env.sh文件,设置JAVA_HOME为实际路径
例:

11) 配置/opt/hadoop/hadoop-3.0.0/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>juju-ha</value>
</property>
<property>
<name>dfs.ha.namenodes.juju-ha</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.juju-ha.nn1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.juju-ha.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.juju-ha.nn2</name>
<value>slave1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.juju-ha.nn2</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.juju-ha</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.juju-ha</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.juju-ha</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/beh/dfs/name</value>
</property>
&l