人工智能咨询培训老师叶梓 转载标明出处
由于检索器的不完美和检索语料库中的噪声,检索到的内容可能包含误导性甚至错误的信息,这对生成质量构成了重大挑战。为了解决这一问题,来自弗吉尼亚大学计算机科学系的研究者提出了一种名为INSTRUCTRAG的新框架。
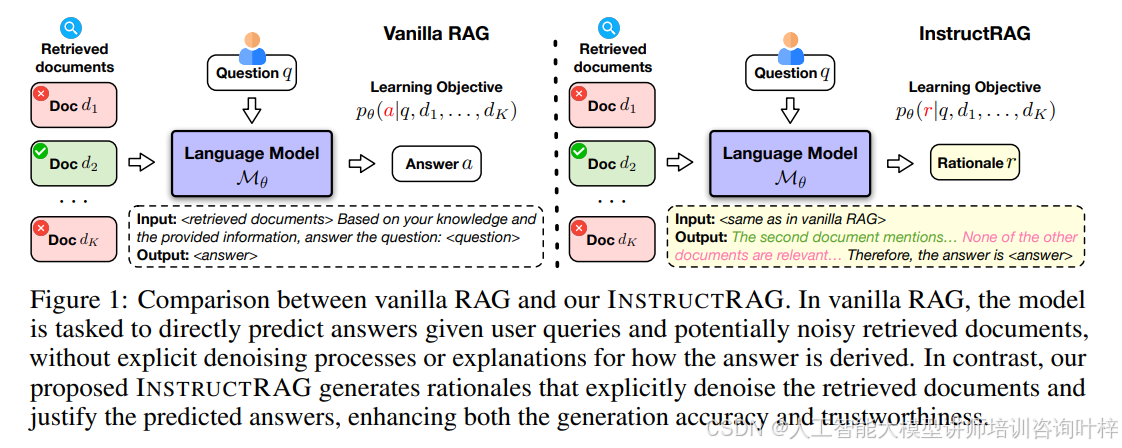
Figure1展示了传统的RAG(检索增强型生成)与论文提出的INSTRUCTRAG方法之间的对比。在传统的RAG中,模型直接从用户查询和可能嘈杂的检索文档中预测答案,没有显式的去噪过程或解释答案如何得出。而INSTRUCTRAG生成理由,明确去噪检索文档并证明预测的答案,从而提高生成的准确性和可信度。
想要掌握如何将大模型的力量发挥到极致吗?2024年10月26日(今晚8点)叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。
留言“参加”即可来叶老师的直播间互动,1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。互动交流,畅谈工作中遇到的实际问题。
方法
INSTRUCTRAG的方法重点放在了如何使大模型在检索到的内容中明确去噪,以提高信息生成的准确性。该方法包含两个步骤,如Figure 2所示。
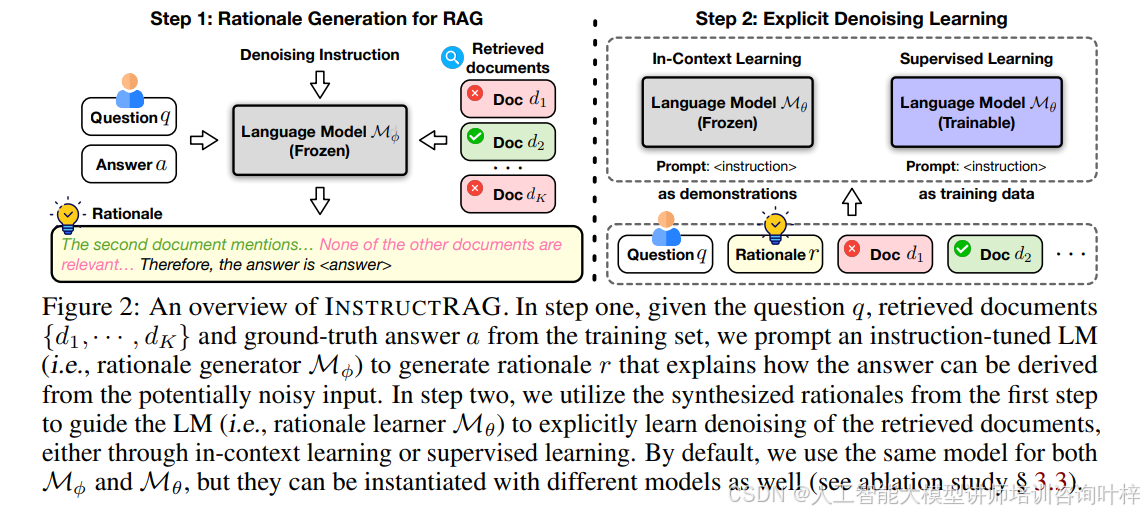
第一步:理由生成
在这一步中,给定一个问题q、从训练集中检索到的文档{d1, ..., dK}以及真实答案a,研究者们使用一个经过指令调整的语言模型(理由生成器Mϕ),来生成一个解释性的理由r,这个理由r阐述了如何从可能嘈杂的输入中推导出答案。这一过程不需要额外的监督,而是通过指令来引导模型自我合成去噪的理由。
第二步:明确的去噪学习
在第二步中,利用第一步合成的理由来指导大模型(理由学习器Mθ),通过上下文学习或监督学习来明确学习检索文档的去噪。这个过程可以通过两种方式进行:一种是作为上下文学习的例子,另一种是作为监督微调的数据。Figure 2中展示了这一过程的概览,其中理由生成器Mϕ和理由学习器Mθ可以是同一个模型,也可以是不同的模型。

在Table 1中,提供了理由生成的具体提示模板。输入包括与给定问题相关的文档,输出是理由ri。这个过程中,模型需要识别出有助于回答问题的文档,并解释这些内容如何引导出正确答案。
算法1 INSTRUCTRAG详细描述了整个INSTRUCTRAG过程,包括训练数据的生成和两种学习模式——上下文学习和微调。在训练数据生成阶段,对于每个问题-答案对,通过理由生成器Mϕ合成去噪理由r,并将其添加到训练数据中。在学习阶段,模型可以采用上下文学习或微调的方式来学习去噪。

研究者们还探讨了使用基于大模型的理由生成器(即Mϕ)的必要性。与简单的启发式方法相比,基于大模型的理由生成器能够更准确地匹配相关文档,并且即使在没有真实答案参考的情况下,也能产生高质量的理由。

通过Table 10和Table 11中的示例,可以看出INSTRUCTRAG-ICL和INSTRUCTRAG-FT两种不同的学习方法如何利用合成的理由来指导模型生成去噪的理由。这些理由不仅提供了高质量的显式去噪监督,还有助于在不同领域中的泛化能力。
实验
Table 2介绍了数据集的统计信息和检索设置。例如,PopQA数据集包含12,868个训练样本和1,399个测试样本,使用的检索器是Contriever,Top-K Recall@K为68.7。这表明在检索的前5个文档中,有68.7%的概率包含了正确答案。
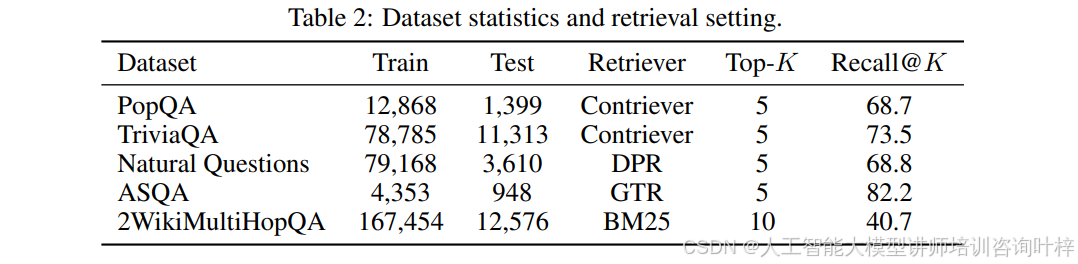
Table 2还展示了其他数据集的统计信息,如TriviaQA、Natural Questions、ASQA和2WikiMultiHopQA。这些数据集被用来验证INSTRUCTRAG在不同知识密集型任务中的有效性。研究者们使用了包括BM25、DPR、GTR和Contriver在内的多种检索器,并测量了它们的Recall@K值,以评估检索质量。
在评估指标方面,研究者们采用了准确率(accuracy)、引文精确度(citation precision)和引文召回率(citation recall)等标准指标。这些指标能够衡量模型生成的答案是否包含真实答案,并且能够处理语义等价性的问题,这是通过采用LLM-as-a-judge进行进一步评估的。
在基线比较方面,研究者们将INSTRUCTRAG与多种RAG基线方法进行了比较,包括无需训练和可训练的设置。例如,他们比较了INSTRUCTRAG与普通的监督式微调(SFT)、RetRobust和Self-RAG等方法的性能。这些基线方法在不同的数据集上进行了测试,以确保公平比较。
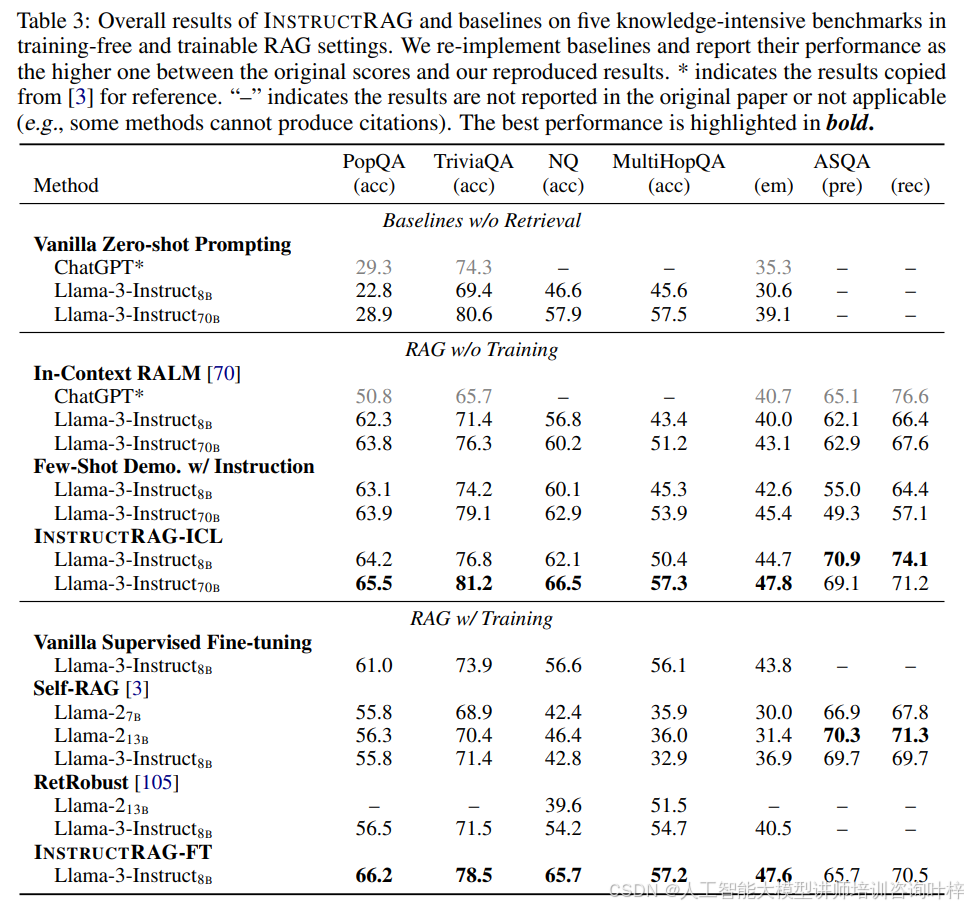 Table 3展示了INSTRUCTRAG与基线方法在五个知识密集型基准测试中的总体实验结果。结果表明,INSTRUCTRAG在无需训练和可训练的场景中均一致性地超越了现有的RAG方法,平均相对提高了8.3%的准确率。这一结果证明了INSTRUCTRAG在提高检索增强型生成任务的噪声鲁棒性方面的有效性。
Table 3展示了INSTRUCTRAG与基线方法在五个知识密集型基准测试中的总体实验结果。结果表明,INSTRUCTRAG在无需训练和可训练的场景中均一致性地超越了现有的RAG方法,平均相对提高了8.3%的准确率。这一结果证明了INSTRUCTRAG在提高检索增强型生成任务的噪声鲁棒性方面的有效性。
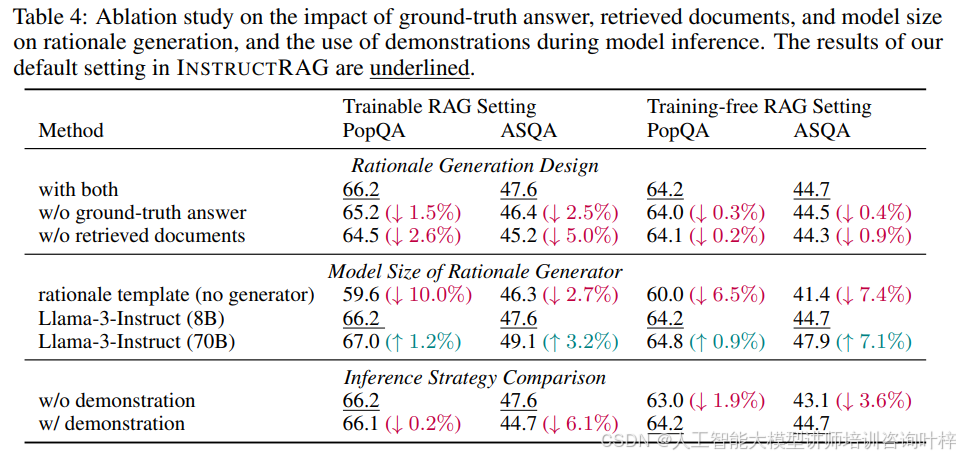 研究者们还进行了消融研究,探讨了真实答案、检索文档和模型大小对理由生成的影响,以及在模型推理期间使用示例的影响。这些消融研究的结果在Table 4中得到了展示。
研究者们还进行了消融研究,探讨了真实答案、检索文档和模型大小对理由生成的影响,以及在模型推理期间使用示例的影响。这些消融研究的结果在Table 4中得到了展示。
实验部分通过在多个数据集上进行广泛的测试,验证了INSTRUCTRAG方法在提高大模型在检索增强型任务中的去噪能力和生成准确性方面的有效性。通过与现有技术的比较,INSTRUCTRAG展现了其在不同设置下的优越性能。