一、说明
决策树不仅限于对数据进行分类 — 它们同样擅长预测数值!分类树经常成为人们关注的焦点,但决策树回归器(或回归树)是连续变量预测领域中功能强大且用途广泛的工具。
虽然我们将讨论回归树构造的机制(与分类树大多相似),但在这里,我们还将超越分类器文章中介绍的预修剪方法,如 “最小样本叶” 和 “最大树深度”。我们将探讨最常见的后修剪方法,即成本复杂性修剪,它将复杂性参数引入决策树的成本函数。

所有视觉效果:使用 Canva 专业版创作。针对移动设备进行了优化;在桌面上可能会显得过大。
二、定义
回归决策树是一种使用树状结构预测数值的模型。它根据关键功能拆分数据,从根问题开始并扩展。每个节点询问一个特征,进一步划分数据,直到到达具有最终预测的叶节点。要获得结果,您需要遵循从根到叶匹配数据特征的路径。
回归决策树通过遵循一系列数据驱动的问题来预测数值结果,并将范围缩小到最终值。
三、使用的数据集
为了演示我们的概念,我们将使用标准数据集。此数据集用于预测给定日期访问的高尔夫球手数量,包括天气展望、温度、湿度和风况等变量。
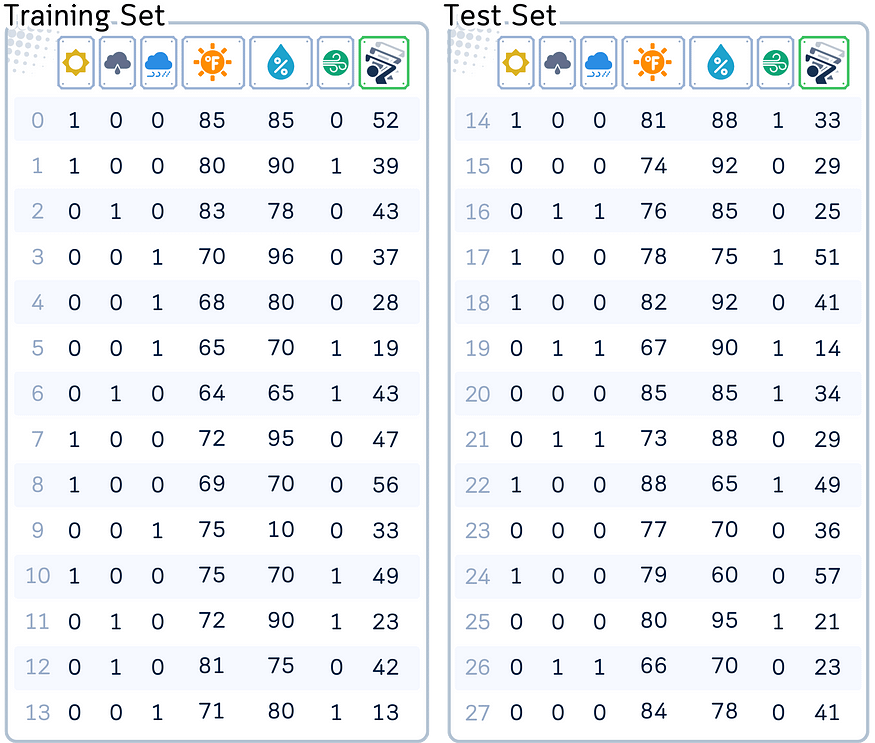
列:“Outlook”(one-hot 编码为晴天、阴天、下雨)、“Temperature”(以华氏度为单位)、“Humidity”(以 % 为单位)、“Wind”(是/否)和 “Number of Players”(数字、目标特征)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# Create dataset
dataset_dict = {
'Outlook': ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast', 'sunny', 'sunny', 'rain', 'sunny', 'overcast', 'overcast', 'rain', 'sunny', 'overcast', 'rain', 'sunny', 'sunny', 'rain', 'overcast', 'rain', 'sunny', 'overcast', 'sunny', 'overcast', 'rain', 'overcast'],
'Temp.': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0, 72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0, 88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humid.': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0, 90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0, 65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True, True, False, True, True, False, False, True, False, True, True, False, True, False, False, True, False, False],
'Num_Players': [52, 39, 43, 37, 28, 19, 43, 47, 56, 33, 49, 23, 42, 13, 33, 29, 25, 51, 41, 14, 34, 29, 49, 36, 57, 21, 23, 41]
}
df = pd.DataFrame(dataset_dict)
# One-hot encode 'Outlook' column
df = pd.get_dummies(df, columns=['Outlook'],prefix='',prefix_sep='')
# Convert 'Wind' column to binary
df['Wind'] = df['Wind'].astype(int)
# Split data into features and target, then into training and test sets
四、主要机制
回归决策树的运行方式是根据最能减少预测误差的特征递归划分数据。以下是一般过程:
- 从根节点处的整个数据集开始。
- 选择最小化特定误差指标(如均方误差或方差)的特征以拆分数据。
- 基于拆分创建子节点,其中每个子节点表示与相应特征值对齐的数据子集。
- 对每个子节点重复步骤 2-3,继续拆分数据,直到达到停止条件。
- 为每个叶节点分配一个最终预测值,通常是该节点中目标值的平均值。
五、训练步骤
我们将探讨决策树算法 CART(分类和回归树)中的回归部分。它构建二叉树,通常遵循以下步骤:
1.从根节点中的所有训练样本开始。
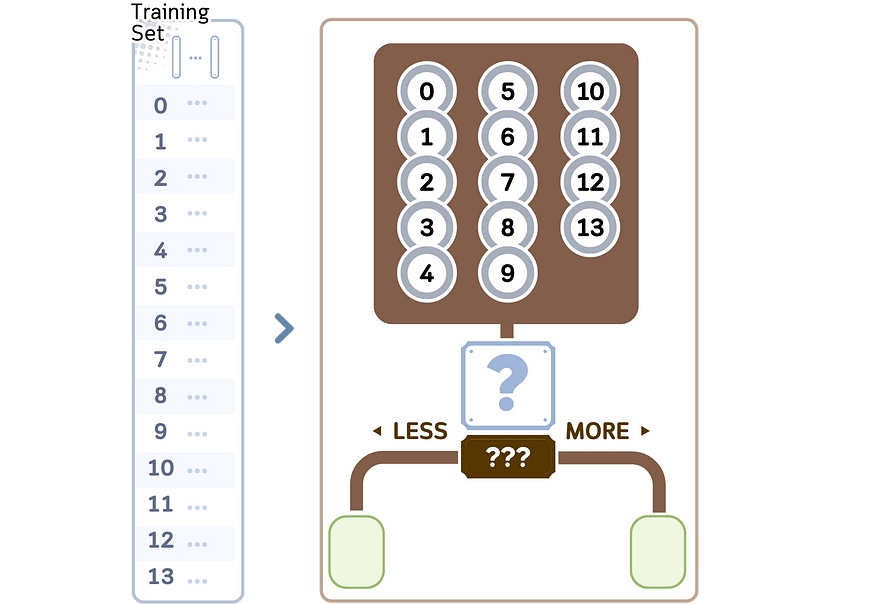
2.对于数据集中的每个特征:
a.按升序对特征值进行排序。
湾。将相邻值之间的所有中点视为可能的分割点。
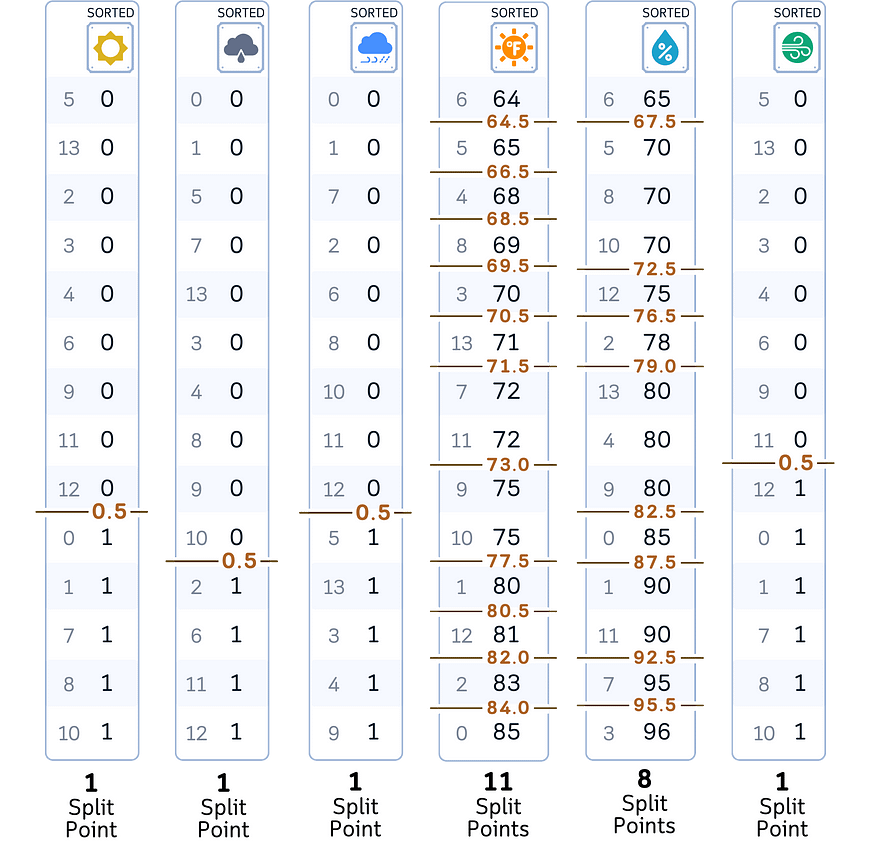
总共有 23 个分割点需要检查。
3. 对于每个可能的分裂点:
a.计算当前节点的均方误差 (MSE)。
湾。计算结果拆分的误差的加权平均值。
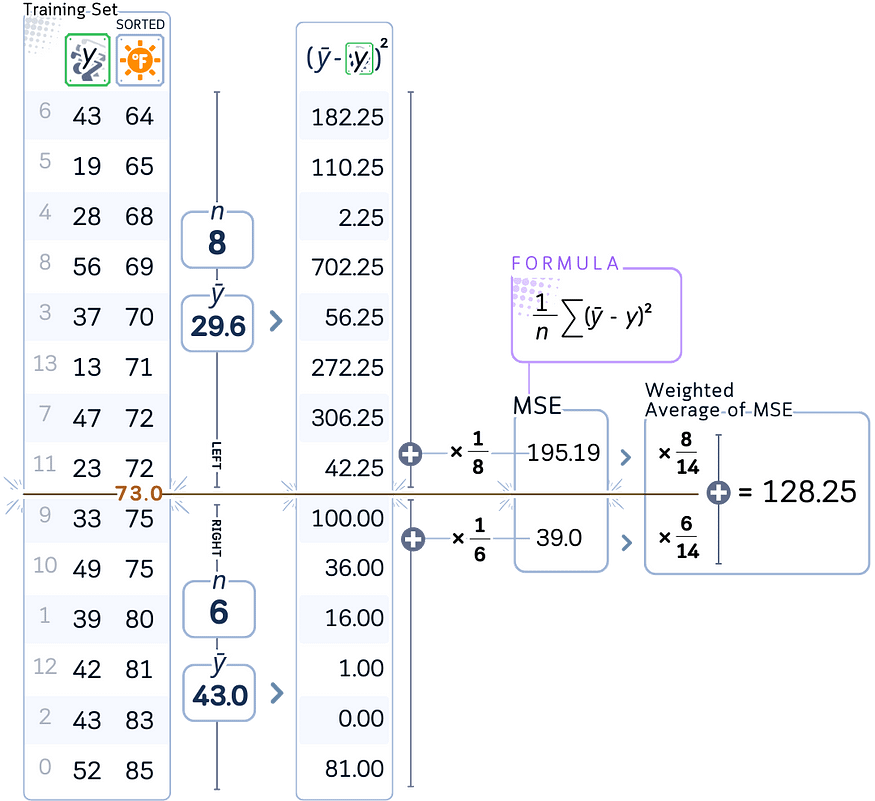
例如,我们计算了值为 73.0 的分离点“温度”的 MSE 加权平均值
4. 评估所有特征和分割点后,选择 MSE 加权平均值最低的特征和分割点。
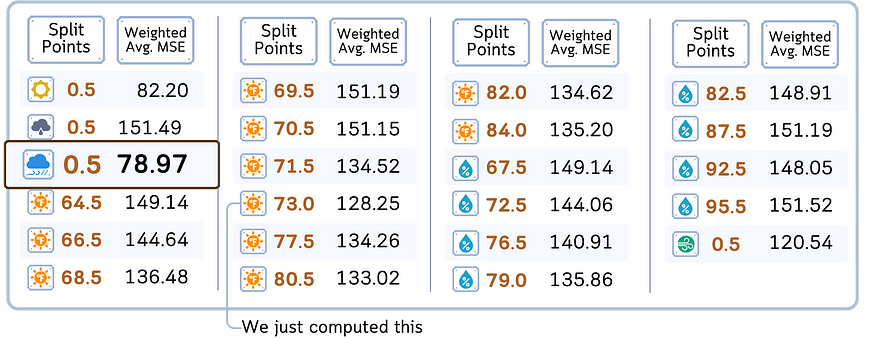
5. 根据所选特征和分割点创建两个子节点:
- 左子节点:特征值为 < = 分割点
的样本- 右子节点:特征值>分割点的样本
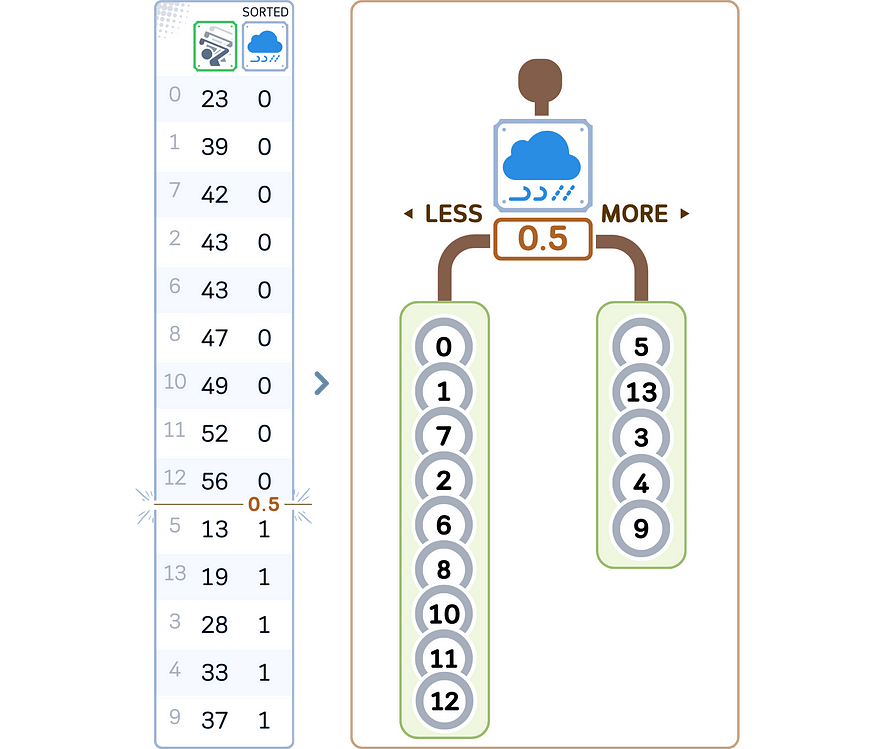
6. 对每个子节点递归重复步骤 2-5。(继续操作,直到满足停止条件。
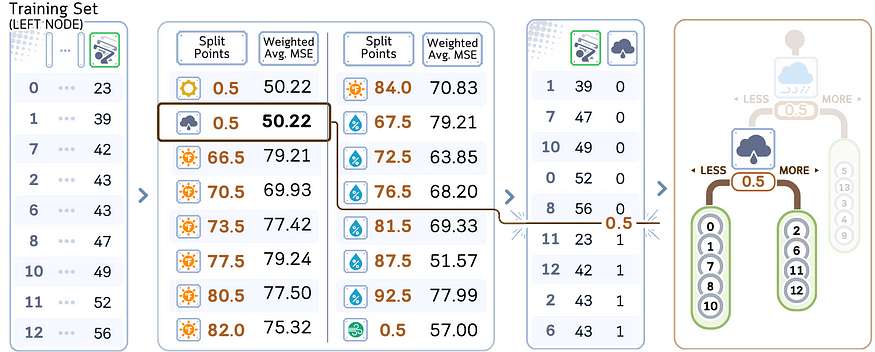
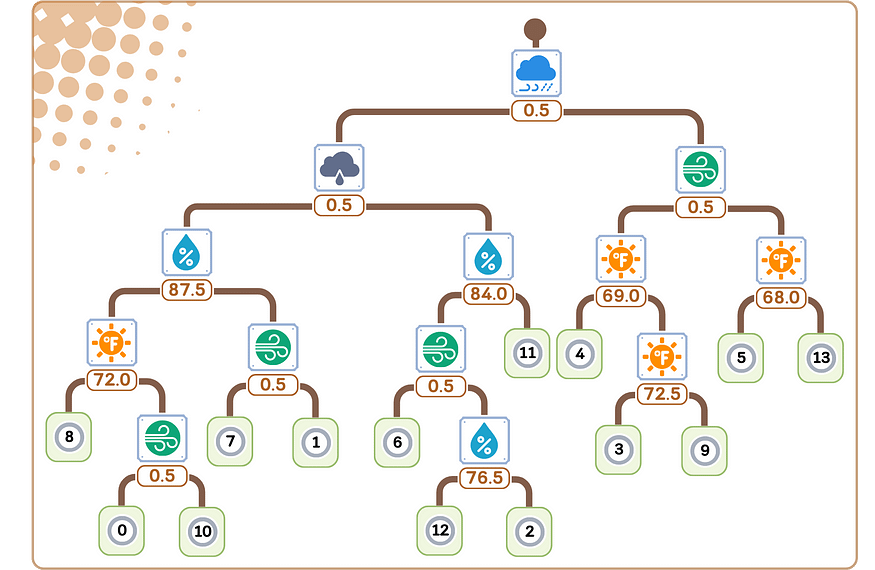
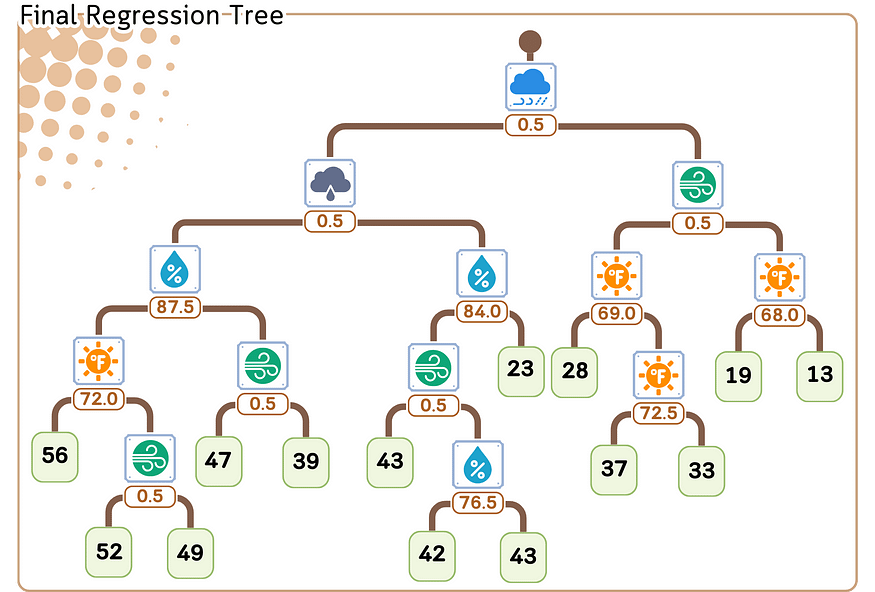
7. 在每个叶节点处,将该节点中样本的平均目标值分配为预测。
from sklearn.tree import DecisionTreeRegressor, plot_tree
import matplotlib.pyplot as plt
# Train the model
regr = DecisionTreeRegressor(random_state=42)
regr.fit(X_train, y_train)
# Visualize the decision tree
plt.figure(figsize=(26,8))
plot_tree(regr, feature_names=X.columns, filled=True, rounded=True, impurity=False, fontsize=16, precision=2)
plt.tight_layout()
plt.show()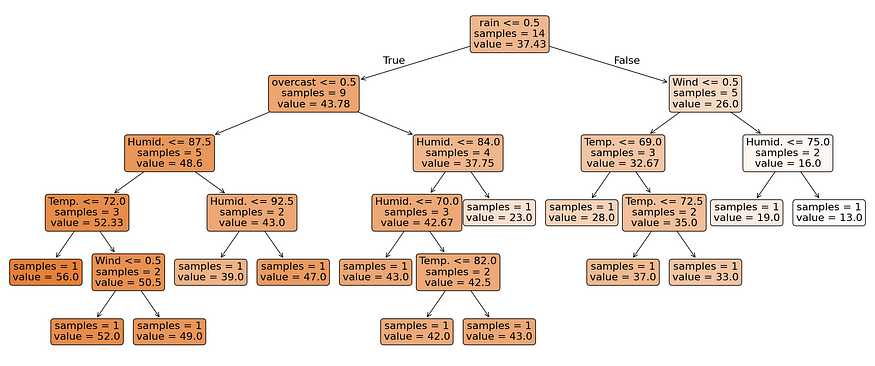
在此 scikit-learn 输出中,显示了叶节点和临时节点的样本和值。
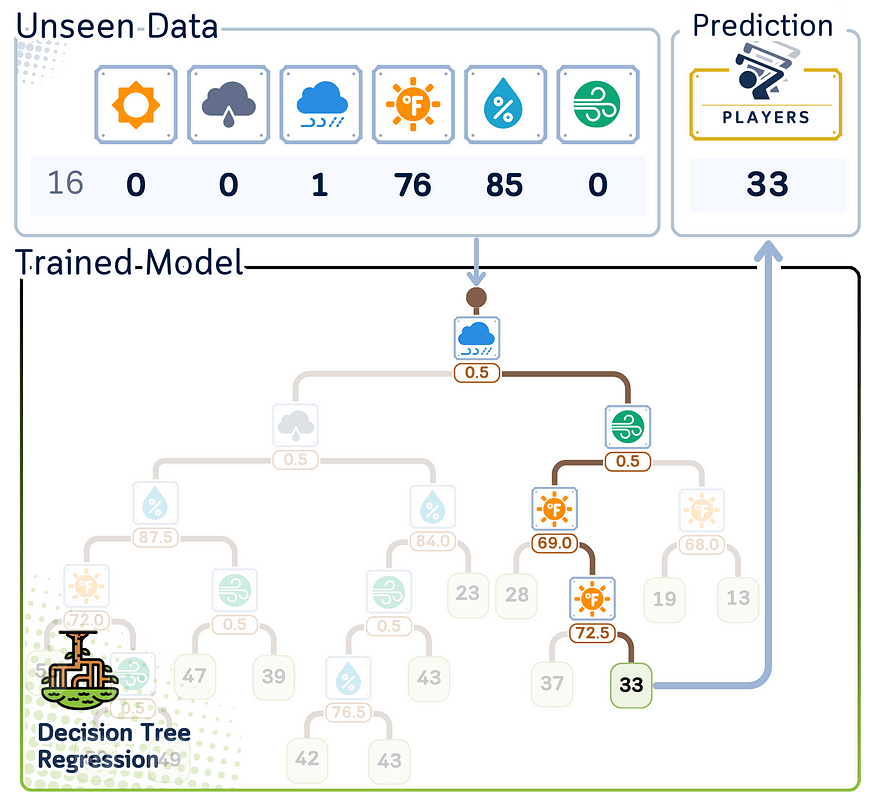
六、回归/预测步骤
以下是回归树对新数据进行预测的方式:
1. 从树的顶部(根)开始。
2. 在每个决策点(节点):
- 查看特征和拆分值。
- 如果数据点的特征值小于或相等,请向左移动。
- 如果它更大,请向右走。
3. 继续沿着树向下移动,直到到达末端(一片叶子)。
4. 预测是存储在该叶中的平均值。
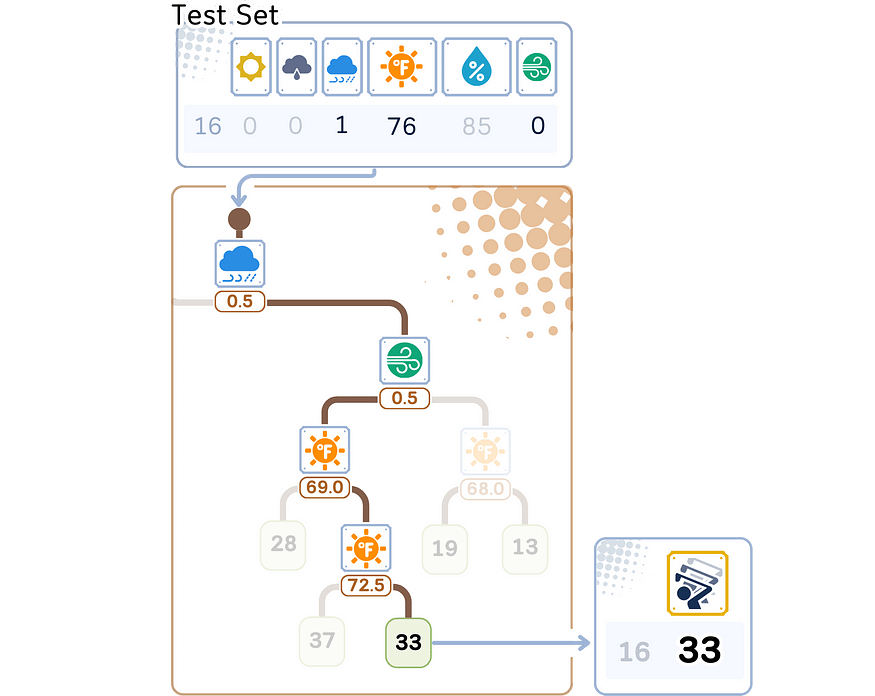
6.1 评估步骤

RMSE 的这个值比虚拟回归器的结果要好得多。
6.2 修剪前与修剪后
构建树之后,我们唯一需要担心的就是如何让树变小,以防止过拟合。一般来说,修剪方法可以分为:
6.2.1 预修剪
预修剪,也称为提前停止,涉及在训练过程中根据某些预定义的标准停止决策树的增长。这种方法旨在防止树变得过于复杂和过度拟合训练数据。常见的预修剪技术包括:
- 最大深度:限制树可以生长的深度。
- Minimum samples for split(拆分的最小样本数):需要最少的样本数才能证明拆分节点的合理性。
- Minimum samples per leaf:确保每个叶节点至少具有一定数量的样本。
- 最大叶节点数:限制树中叶节点的总数。
- 最小杂质减少量:仅允许将杂质减少指定量的拆分。
当满足指定条件时,这些方法可以阻止树木的生长,从而在树木的构建阶段有效地“修剪”树木。
6.2.2 修剪后
另一方面,后修剪允许决策树完全增长,然后将其修剪以降低复杂性。此方法首先构建一个完整的树,然后删除或折叠对模型性能没有显著影响的分支。一种常见的后修剪技术称为成本复杂性修剪。
七、成本复杂性修剪
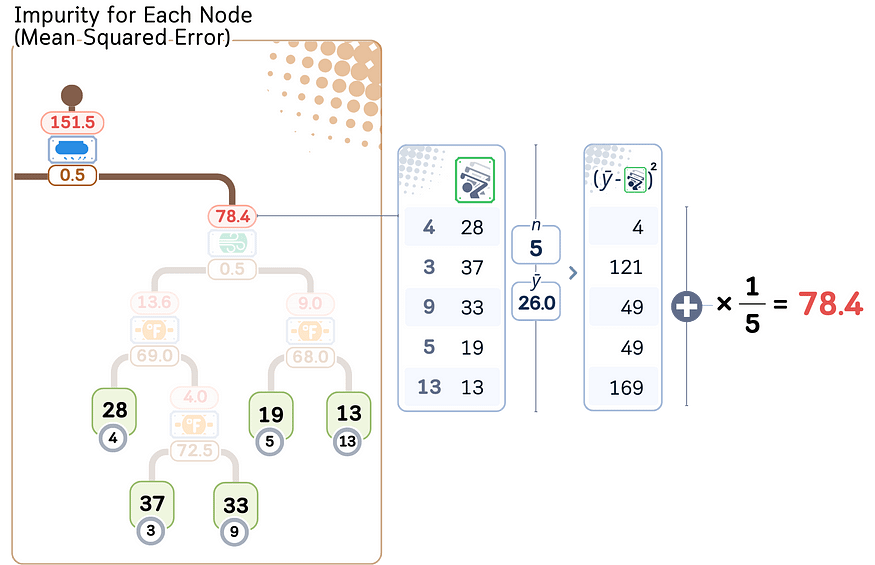
7.1 第 1 步:计算每个节点的杂质
对于每个中间节点,计算杂质(回归情况的 MSE)。然后,我们将该值从最低到最高排序。
# Visualize the decision tree
plt.figure(figsize=(26,8))
plot_tree(regr, feature_names=X.columns, filled=True, rounded=True, impurity=True, fontsize=16, precision=2)
plt.tight_layout()
plt.show()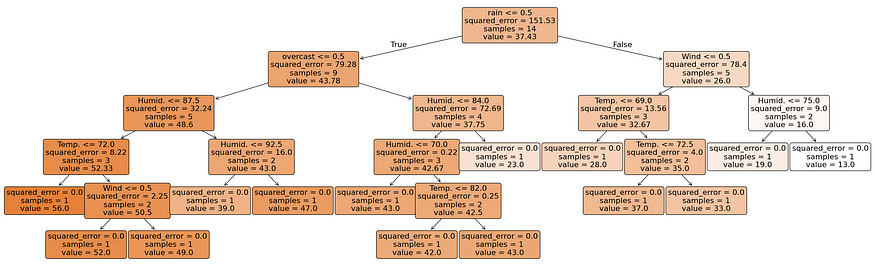
在此 scikit learn 输出中,每个节点的杂质显示为 “squared_error”。

让我们为这些临时节点命名(从 A-J)。然后,我们根据他们的 MSE 从低到高对其进行排序
7.2 第 2 步:通过修剪最薄弱的环节来创建子树
目标是从 MSE 最低的节点(= 最弱的环节)开始,逐渐将临时节点变成叶子。我们可以基于此创建一个修剪路径。
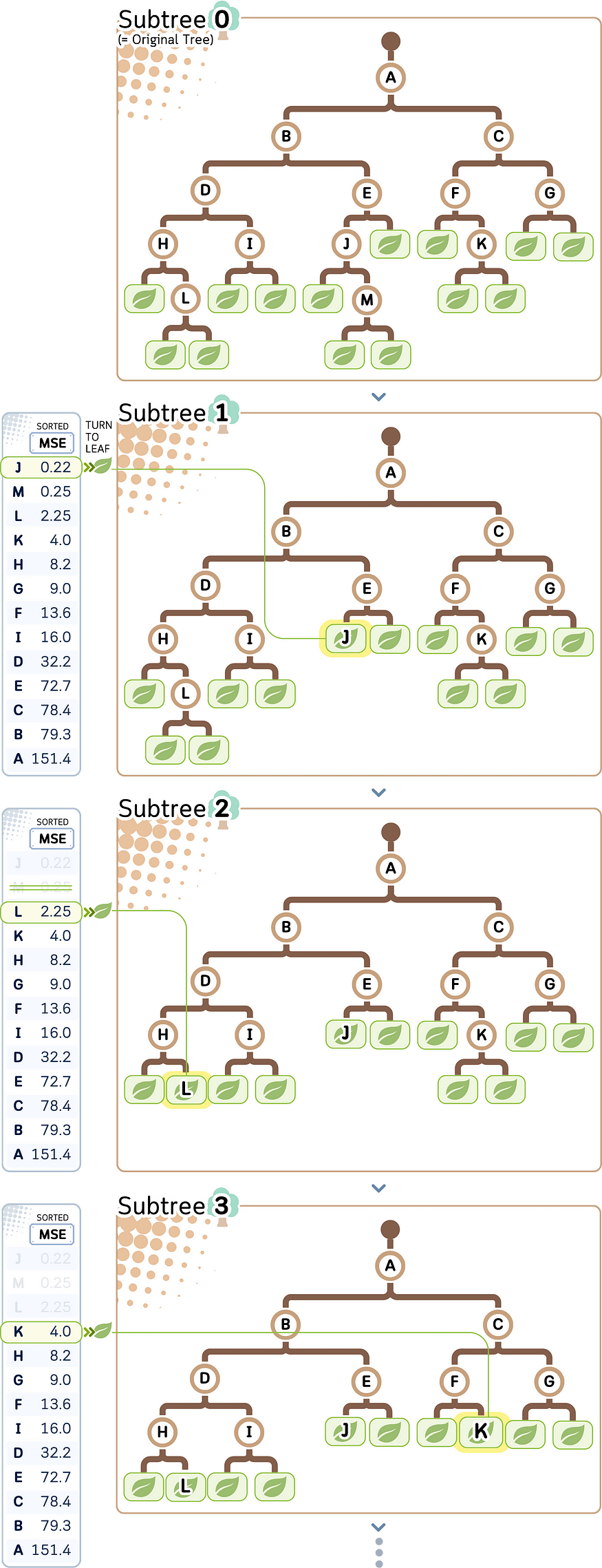
让我们根据修剪的次数 (i) 将它们命名为 “Subtree i”。从原始树开始,将在 MSE 最低的节点上修剪树(从节点 J、M(已被 J、L、K 剪切)开始)
7.3 第 3 步:计算每个子树的总叶杂质
对于每个子树 T,总叶片杂质 (R(T)) 可以计算为:
R(T) = (1/N) Σ I(L) * n_L
其中:
· L 范围在所有叶节点
上· n_L 是叶片 L
· N 是 tree
· I(L) 是叶片 L 的杂质 (MSE)
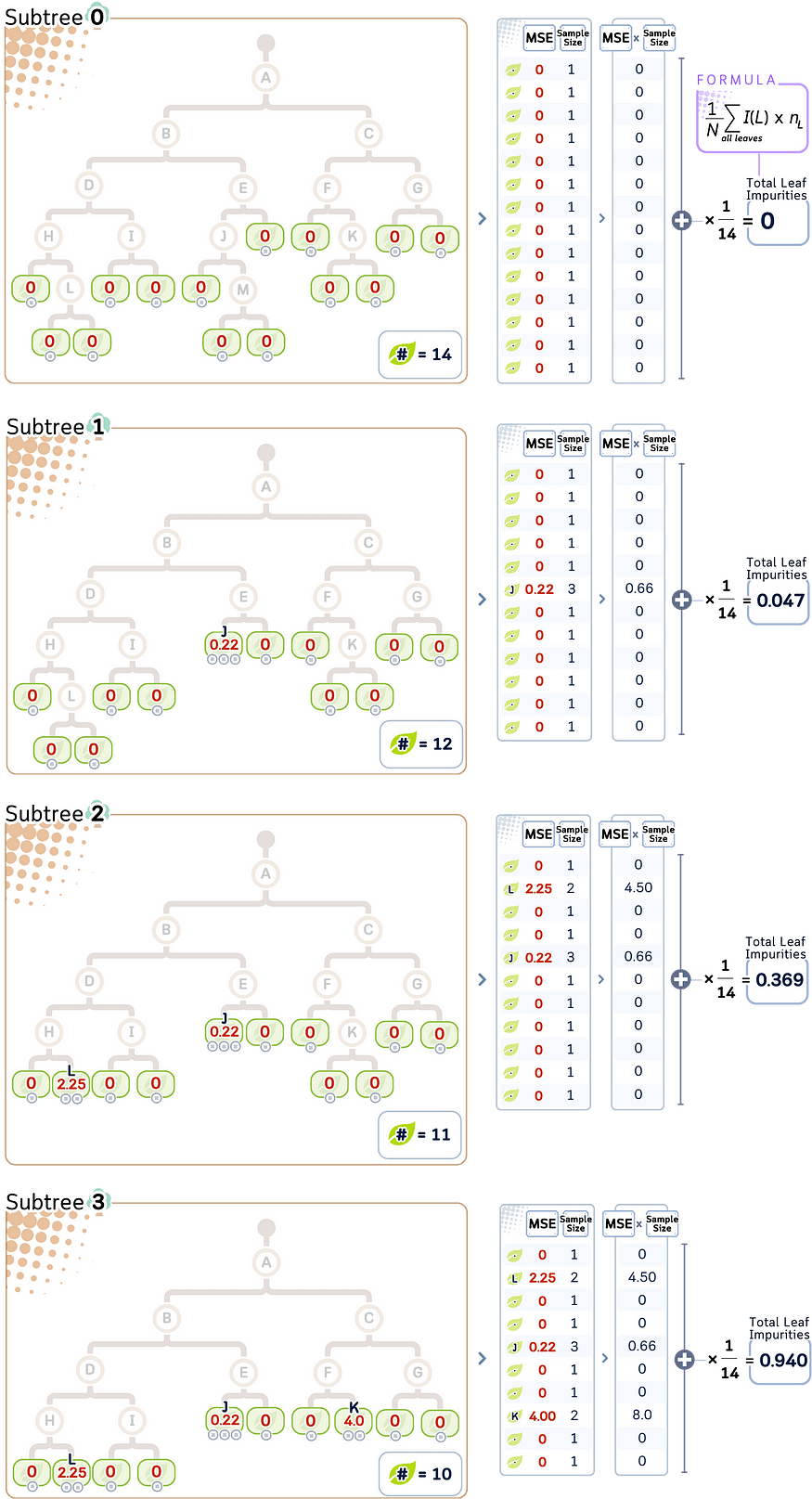
我们修剪得越多,叶子的总杂质就越高。
7.4 步骤 4:计算成本函数
为了控制何时停止将临时节点转换为叶子,我们首先使用以下公式检查每个子树 T 的成本复杂度:
成本 (T) = R(T) + α * |T|
其中:
· R(T) 为叶片总杂质
|T|是子树
中的叶节点数· α 是 complexity 参数
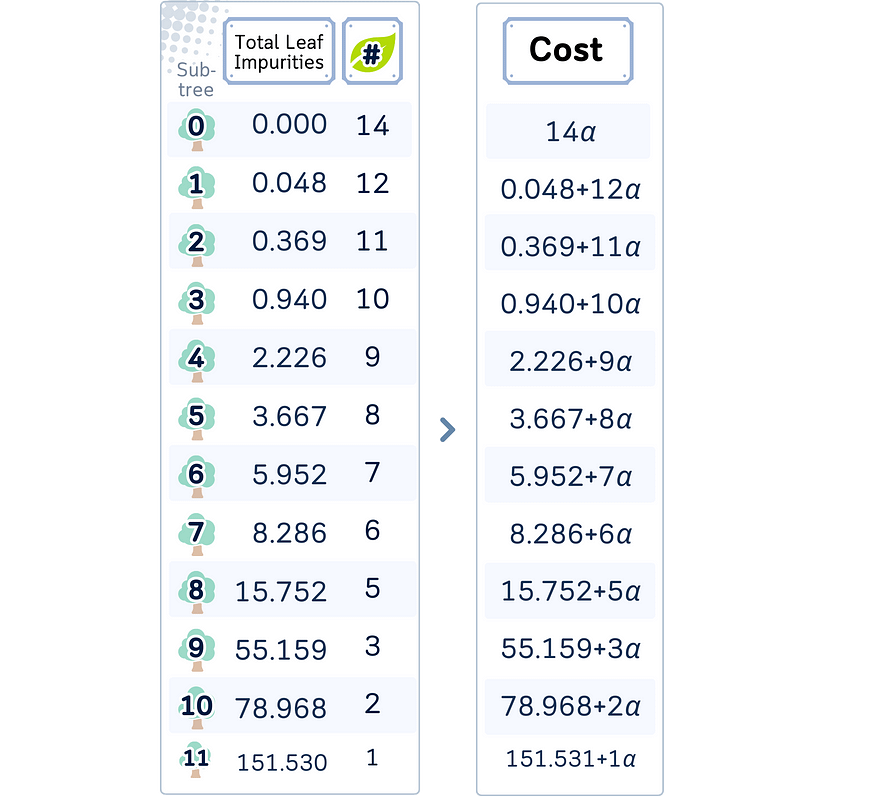
7.5 第 5 步:选择 Alpha
alpha 的值控制我们最终会得到哪个子树。成本最低的子树将是最终树。
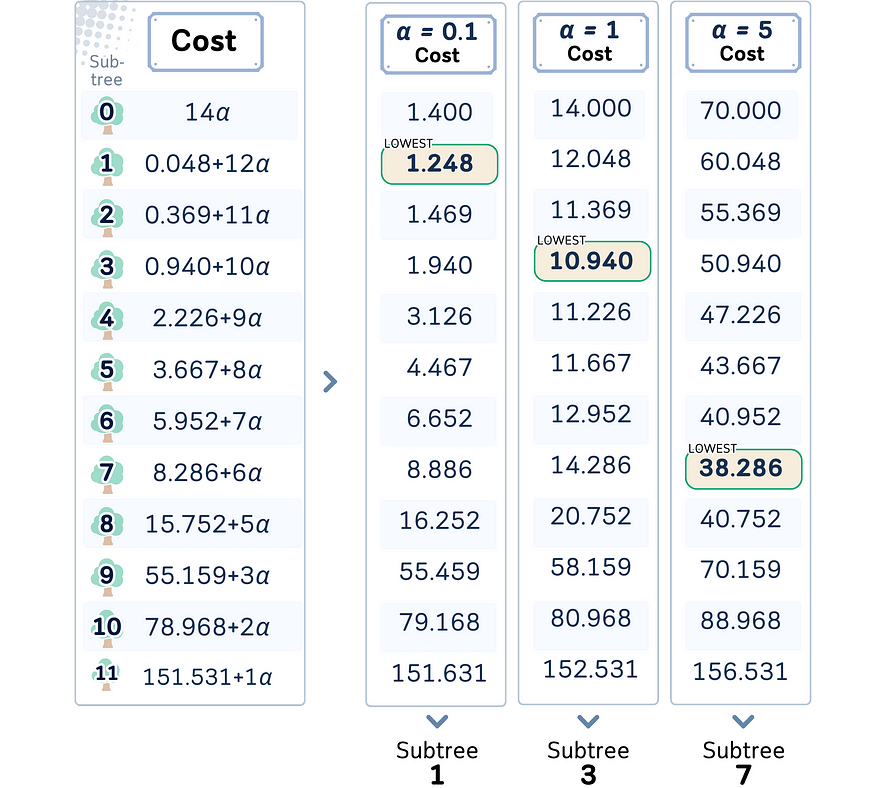
当 α 较小时,我们更关心准确性 (较大的树)。当 α 较大时,我们更关心简单性(较小的树)
虽然我们可以自由设置α,但在 scikit-learn 中,你也可以获取 α 的最小值来获取特定的子树。这称为有效α。

此有效α也可以计算。
# Compute the cost-complexity pruning path
tree = DecisionTreeRegressor(random_state=42)
effective_alphas = tree.cost_complexity_pruning_path(X_train, y_train).ccp_alphas
impurities = tree.cost_complexity_pruning_path(X_train, y_train).impurities
# Function to count leaf nodes
count_leaves = lambda tree: sum(tree.tree_.children_left[i] == tree.tree_.children_right[i] == -1 for i in range(tree.tree_.node_count))
# Train trees and count leaves for each complexity parameter
leaf_counts = [count_leaves(DecisionTreeRegressor(random_state=0, ccp_alpha=alpha).fit(X_train_scaled, y_train)) for alpha in effective_alphas]
# Create DataFrame with analysis results
pruning_analysis = pd.DataFrame({
'total_leaf_impurities': impurities,
'leaf_count': leaf_counts,
'cost_function': [f"{imp:.3f} + {leaves}α" for imp, leaves in zip(impurities, leaf_counts)],
'effective_α': effective_alphas
})
print(pruning_analysis)
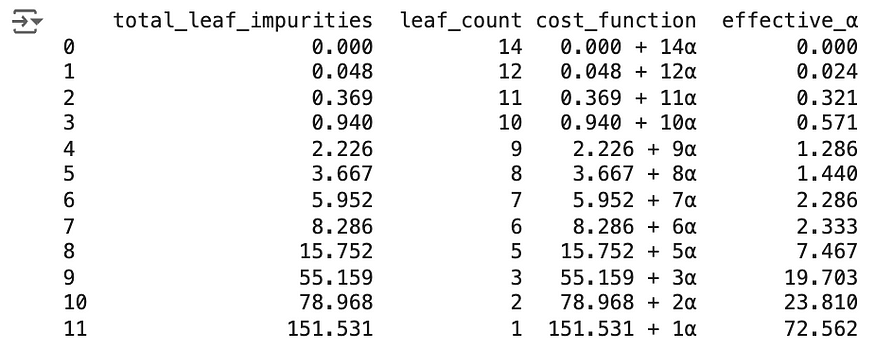
八、结语
预修剪方法通常更快且内存效率更高,因为它们首先可以防止树长得太大。
修剪后可能会创建更优化的树,因为它在做出修剪决策之前会考虑整个树结构。但是,它的计算成本可能更高。
这两种方法都旨在在模型复杂性和性能之间找到平衡,目标是创建一个可以很好地泛化到看不见的数据的模型。在预修剪和后修剪(或两者的组合)之间进行选择通常取决于特定的数据集、手头的问题,当然还有可用的计算资源。
在实践中,通常结合使用这些方法,例如应用一些预修剪标准来防止过大的树,然后使用后修剪来微调模型的复杂性。
九、决策树回归器(使用成本复杂性修剪)代码汇总
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import root_mean_squared_error
from sklearn.tree import DecisionTreeRegressor
from sklearn.preprocessing import StandardScaler
# Create dataset
dataset_dict = {
'Outlook': ['sunny', 'sunny', 'overcast', 'rain', 'rain', 'rain', 'overcast', 'sunny', 'sunny', 'rain', 'sunny', 'overcast', 'overcast', 'rain', 'sunny', 'overcast', 'rain', 'sunny', 'sunny', 'rain', 'overcast', 'rain', 'sunny', 'overcast', 'sunny', 'overcast', 'rain', 'overcast'],
'Temperature': [85.0, 80.0, 83.0, 70.0, 68.0, 65.0, 64.0, 72.0, 69.0, 75.0, 75.0, 72.0, 81.0, 71.0, 81.0, 74.0, 76.0, 78.0, 82.0, 67.0, 85.0, 73.0, 88.0, 77.0, 79.0, 80.0, 66.0, 84.0],
'Humidity': [85.0, 90.0, 78.0, 96.0, 80.0, 70.0, 65.0, 95.0, 70.0, 80.0, 70.0, 90.0, 75.0, 80.0, 88.0, 92.0, 85.0, 75.0, 92.0, 90.0, 85.0, 88.0, 65.0, 70.0, 60.0, 95.0, 70.0, 78.0],
'Wind': [False, True, False, False, False, True, True, False, False, False, True, True, False, True, True, False, False, True, False, True, True, False, True, False, False, True, False, False],
'Num_Players': [52,39,43,37,28,19,43,47,56,33,49,23,42,13,33,29,25,51,41,14,34,29,49,36,57,21,23,41]
}
df = pd.DataFrame(dataset_dict)
# One-hot encode 'Outlook' column
df = pd.get_dummies(df, columns=['Outlook'], prefix='', prefix_sep='', dtype=int)
# Convert 'Wind' column to binary
df['Wind'] = df['Wind'].astype(int)
# Split data into features and target, then into training and test sets
X, y = df.drop(columns='Num_Players'), df['Num_Players']
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.5, shuffle=False)
# Initialize Decision Tree Regressor
tree = DecisionTreeRegressor(random_state=42)
# Get the cost complexity path, impurities, and effective alpha
path = tree.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
print(ccp_alphas)
print(impurities)
# Train the final tree with the chosen alpha
final_tree = DecisionTreeRegressor(random_state=42, ccp_alpha=0.1)
final_tree.fit(X_train_scaled, y_train)
# Make predictions
y_pred = final_tree.predict(X_test)
# Calculate and print RMSE
rmse = root_mean_squared_error(y_test, y_pred)
print(f"RMSE: {rmse:.4f}")技术环境
本文使用 Python 3.7 和 scikit-learn 1.5。虽然讨论的概念通常适用,但特定代码实现可能会因版本的不同而略有不同