先上结论:ChatGPT本质只是预测下一个单词的概率!

一、神经网络:ChatGPT的智能引擎
ChatGPT的核心是神经网络,这是一种模拟人类大脑的计算模型。人类大脑由大约1000亿个神经元组成,它们通过复杂的网络传递电信号,每个神经元的激活取决于接收到的信号以及连接的权重。

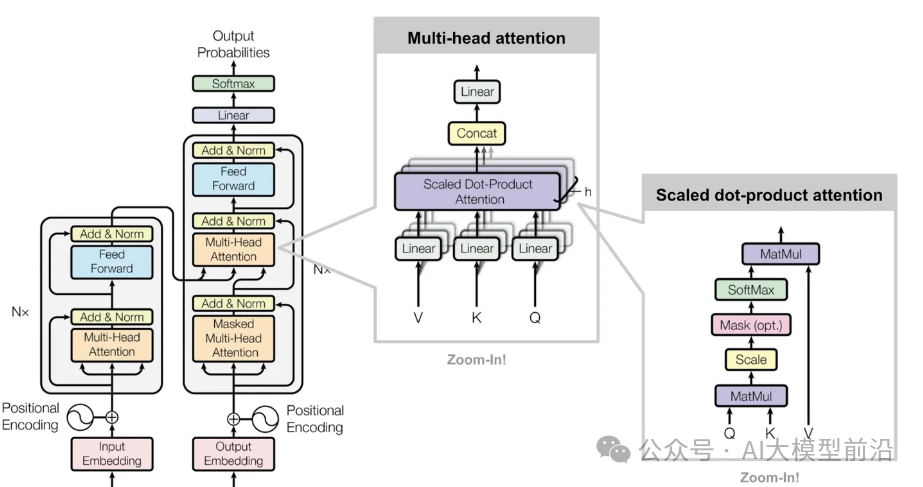
ChatGPT通过构建类似的网络结构,使用人工神经元和权重来处理信息。它最显著的特征是Transformer架构,该架构为文本token序列的处理提供了类似的方式,并引入了“注意力”概念。ChatGPT的目标是基于训练数据续写文本,其运作分为三个阶段:获取token序列的embedding,**通过神经网络操作产生新的embedding,最后生成下一个token的概率数组。**整个过程由神经网络实现,权重由训练数据决定。

二、训练的艺术:从数据到智能
ChatGPT的训练过程是一种艺术。它需要大量的输入输出样例来学习,通过不断调整权重来逼近理想的输出。这个过程涉及到损失函数,它衡量当前输出与目标输出之间的差距,并指导权重的更新。

**ChatGPT本质只是预测下一个单词的概率,通过训练不断接近这个目标。**随着训练样本的增加,模型的性能逐渐提升。

三、生成文本:1750亿次计算的背后
ChatGPT生成文本的速度受限于其庞大的计算需求。每次生成新的词或词的一部分,都需要进行包含1750亿个权重的计算。尽管这些计算可以并行执行,但每个新标记的生成仍然需要巨大的计算资源。
四、高昂的训练成本:数十亿美元的代价
大型语言模型的训练成本极高,因为每个权重都需要参与计算。如果需要n个词的训练数据来设置权重,那么训练过程可能需要n*n个计算步骤。这导致了训练成本的急剧上升。
**五、**未来的训练革新
尽管数据的获取和使用似乎是一个限制,但神经网络可以通过数据增强和模拟环境来获取新的数据。此外,AI生成的数据也可以用于训练,这为数据的无限可能性提供了新的思路。
未来可能会有更好的方法来训练神经网络。当前的训练方法受限于GPU的数量和计算能力,但未来的硬件和算法创新可能会突破这一瓶颈。此外,神经网络的结构和训练过程也可能发生变革,以实现更高效的智能。

总结
ChatGPT的成功不仅仅是技术的胜利,更是对人类语言和思维模式的一种深刻理解。它表明,人类语言在结构上可能比我们想象的更简单、更规律。这可能是一次智能水平提升的巨大机遇。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
本文转自 https://mp.weixin.qq.com/s/qnNFzMO0Sud8aoLOlPVOug,如有侵权,请联系删除。