温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
开题报告
一、开题报告名称
Python+大模型气象预测系统
二、研究的目的和意义
天气预测一直是人们关注的焦点,准确的天气预测对于农业、交通、能源、旅游等众多领域都有着重要的意义。随着大数据时代的到来,天气数据的获取和处理变得更加便捷,这也为天气预测分析提供了更多的可能性和工具。本研究旨在利用Python语言结合大模型技术,构建一套完整的天气数据预测分析及可视化系统,实现对大量天气数据的快速处理和分析,提高天气预测的准确性和时效性,对于提高社会经济效益和保障人民生产生活安全具有重要的现实意义。
三、研究的指导思想
本研究将基于数据驱动的方法,结合Python编程语言和机器学习算法,对天气数据进行挖掘和预测。通过可视化技术,将预测结果进行直观展示,提高预测结果的可解释性和实用性。研究将遵循科学严谨的态度,注重理论与实践相结合,力求在气象预测领域取得创新性的研究成果。
四、研究目标和假设
本研究的主要目标是构建一套基于Python的天气数据预测分析及可视化系统,该系统应包括以下功能:
- 数据收集与预处理:通过合适的数据源收集历史天气数据,并进行数据清洗和预处理,为后续的分析和预测提供可用的数据集。
- 特征提取与建模:对预处理后的数据进行特征提取,利用机器学习算法建立天气预测模型。
- 预测结果评估:采用合适的评估指标对预测结果进行评估,验证模型的有效性和可靠性。
- 可视化展示与系统实现:利用Python的可视化库,将预测结果进行可视化展示,设计并实现一个完整的天气数据预测分析及可视化系统。
假设通过该系统,能够实现对未来一段时间内的天气状况进行准确预测,并为用户提供直观、易于理解的预测结果。
五、研究内容
本研究的主要内容包括以下几个方面:
- 数据收集:从气象观测站、卫星遥感、雷达、数值预报模型等多种渠道获取历史天气数据,包括温度、湿度、气压、风速等指标。
- 数据预处理:对收集到的数据进行清洗和格式化,处理缺失值和异常值,并进行数据标准化或归一化处理。
- 特征选择:使用相关性分析、特征重要性评分等方法确定对预测结果有影响的特征。
- 模型选择与训练:选择合适的机器学习算法(如循环神经网络RNN、长短时记忆网络LSTM等)建立预测模型,并使用历史数据进行训练。
- 模型评估与优化:通过交叉验证等方法评估模型的性能,调整超参数(如学习率、批次大小等)以优化模型。
- 预测结果可视化:利用Python的可视化库(如Matplotlib、Seaborn等)将预测结果以图表的形式展示出来。
六、研究的步骤和进度
本研究计划分为以下几个阶段进行:
- 第一阶段(1-2个月):完成研究背景和国内外研究现状的调研工作,明确研究目标和任务。
- 第二阶段(3-4个月):进行数据收集、预处理和特征提取工作,建立初步的天气预测模型。
- 第三阶段(5-6个月):完成模型的训练和调优工作,进行预测结果评估。
- 第四阶段(7-8个月):开发系统后台功能,包括数据处理和分析模块的实现。
- 第五阶段(9-10个月):开发系统前端功能,完成用户界面的设计和实现。
- 第六阶段(11-12个月):进行系统测试和性能优化工作,完善论文写作并准备答辩。
七、研究方法和资料获取途径
本研究将采用以下研究方法:
- 文献调查:查阅相关文献,了解国内外在天气预测领域的研究进展和技术方法。
- 数据收集:通过气象观测站、卫星遥感、雷达、数值预报模型等多种渠道获取历史天气数据。
- 实验研究:利用Python编程语言和机器学习算法对数据进行处理和分析,建立预测模型并进行评估。
- 可视化展示:利用Python的可视化库将预测结果进行直观展示。
研究资料的获取途径主要包括:
- 气象数据源:从公开的气象网站、API(如OpenWeatherMap)或历史气象数据库获取数据。
- 文献数据库:查阅中国知网、万方等文献数据库中的相关文献。
- 网络爬虫技术:利用Python编写网络爬虫程序,从相关网站抓取数据。
八、研究的成果形式
本研究的成果形式将包括:
- 研究报告:撰写详细的研究报告,介绍研究背景、方法、过程和结果。
- 论文:撰写学术论文,投稿至相关学术期刊或会议。
- 软件系统:开发一套基于Python的天气数据预测分析及可视化系统,包括后台数据处理和前台用户界面两个部分。
- 演示视频:录制系统发布和功能操作演示视频,展示系统的实际运行效果。
九、研究的组织机构和人员分工
本研究由XXX大学XXX学院XXX专业的研究团队负责实施,团队成员包括XXX教授(负责人)、XXX讲师(技术指导)以及XXX名本科生(研究助理)。具体分工如下:
- XXX教授:负责研究方案的制定、进度监督和论文撰写指导。
- XXX讲师:负责技术指导和模型开发工作,协助解决研究过程中的技术难题。
- 本科生:负责数据收集、预处理和可视化展示工作,参与模型训练和评估过程。
以上是本研究的开题报告内容,希望能够为后续的研究工作提供明确的指导和方向。
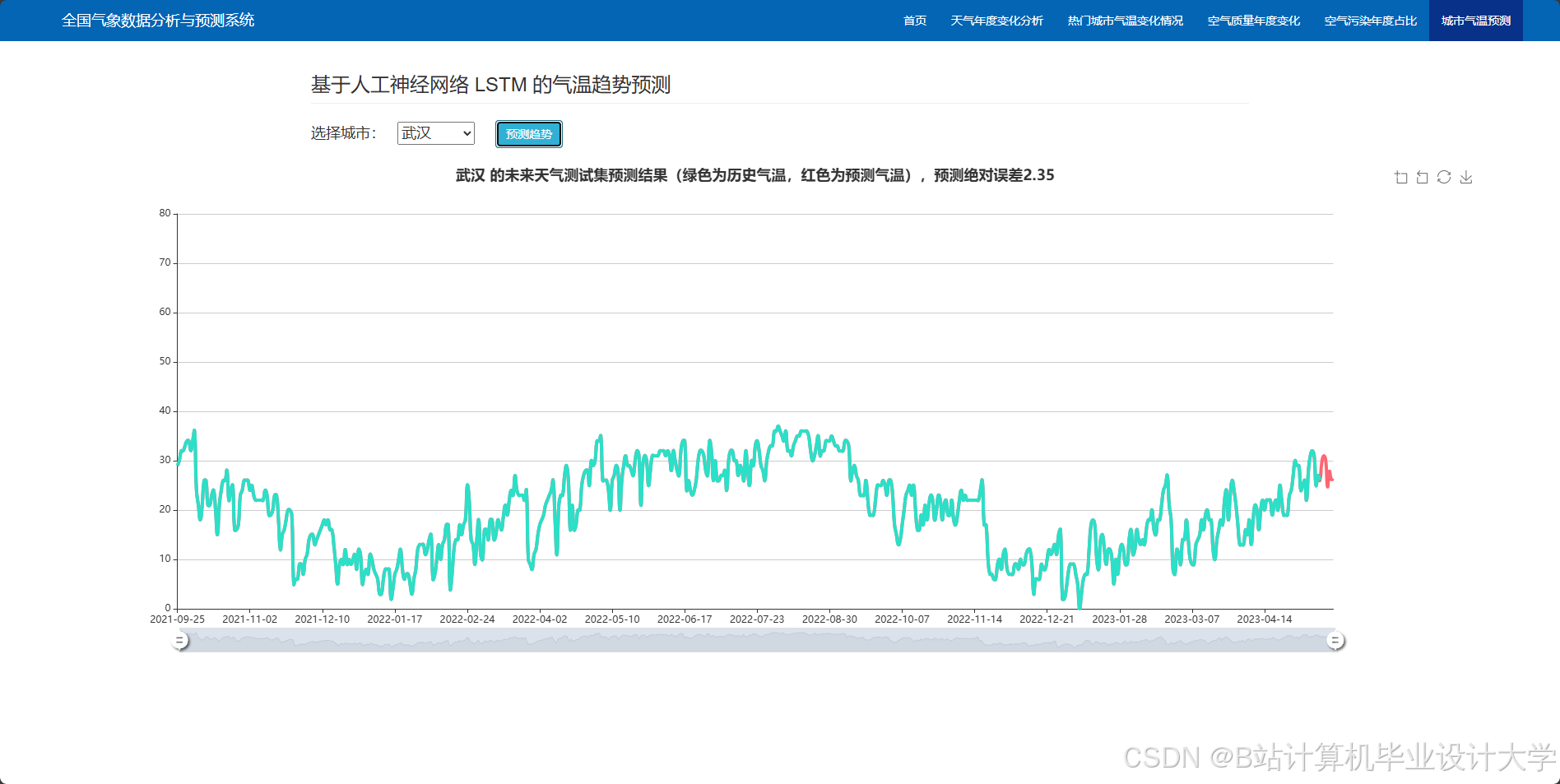
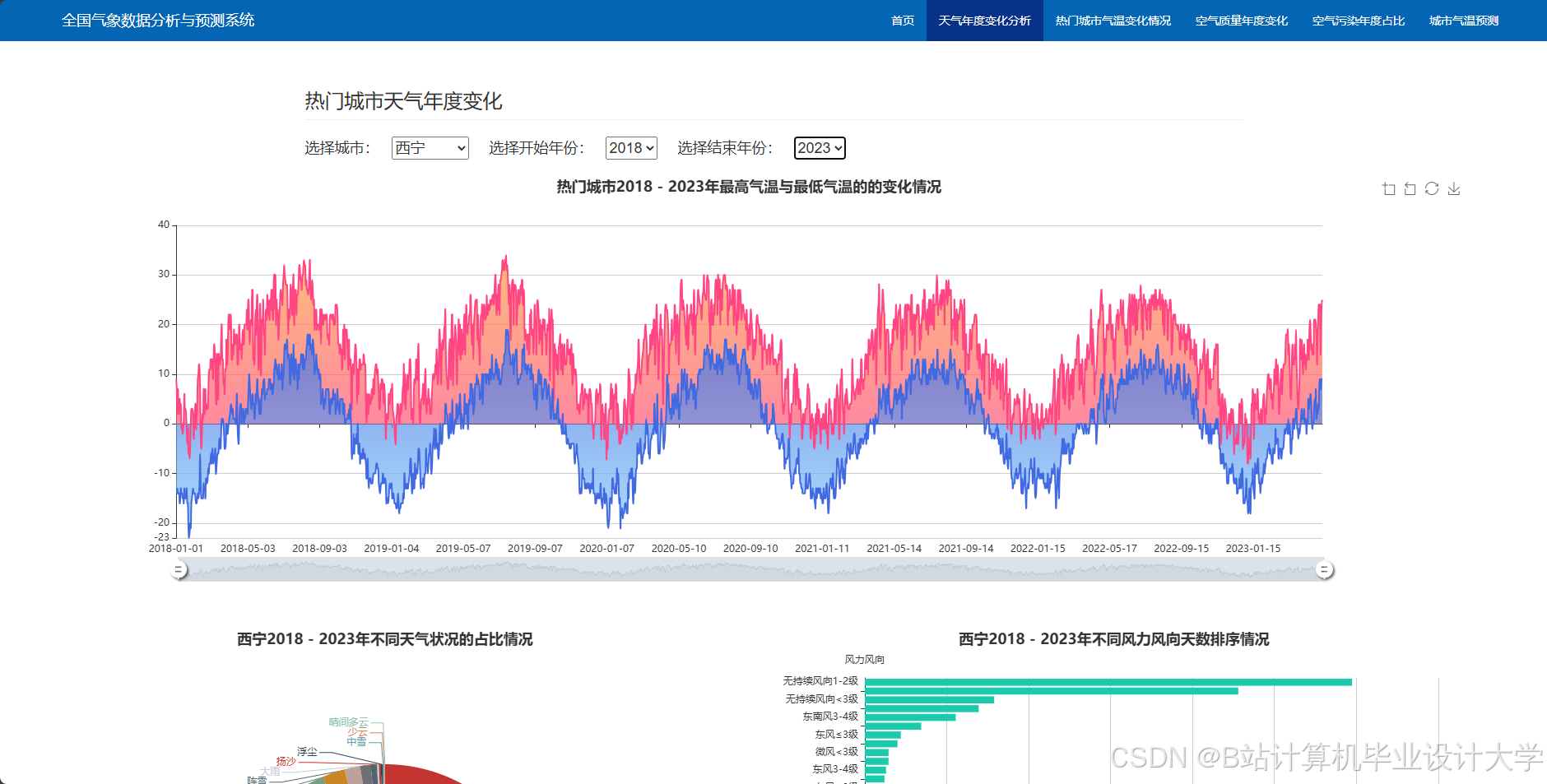
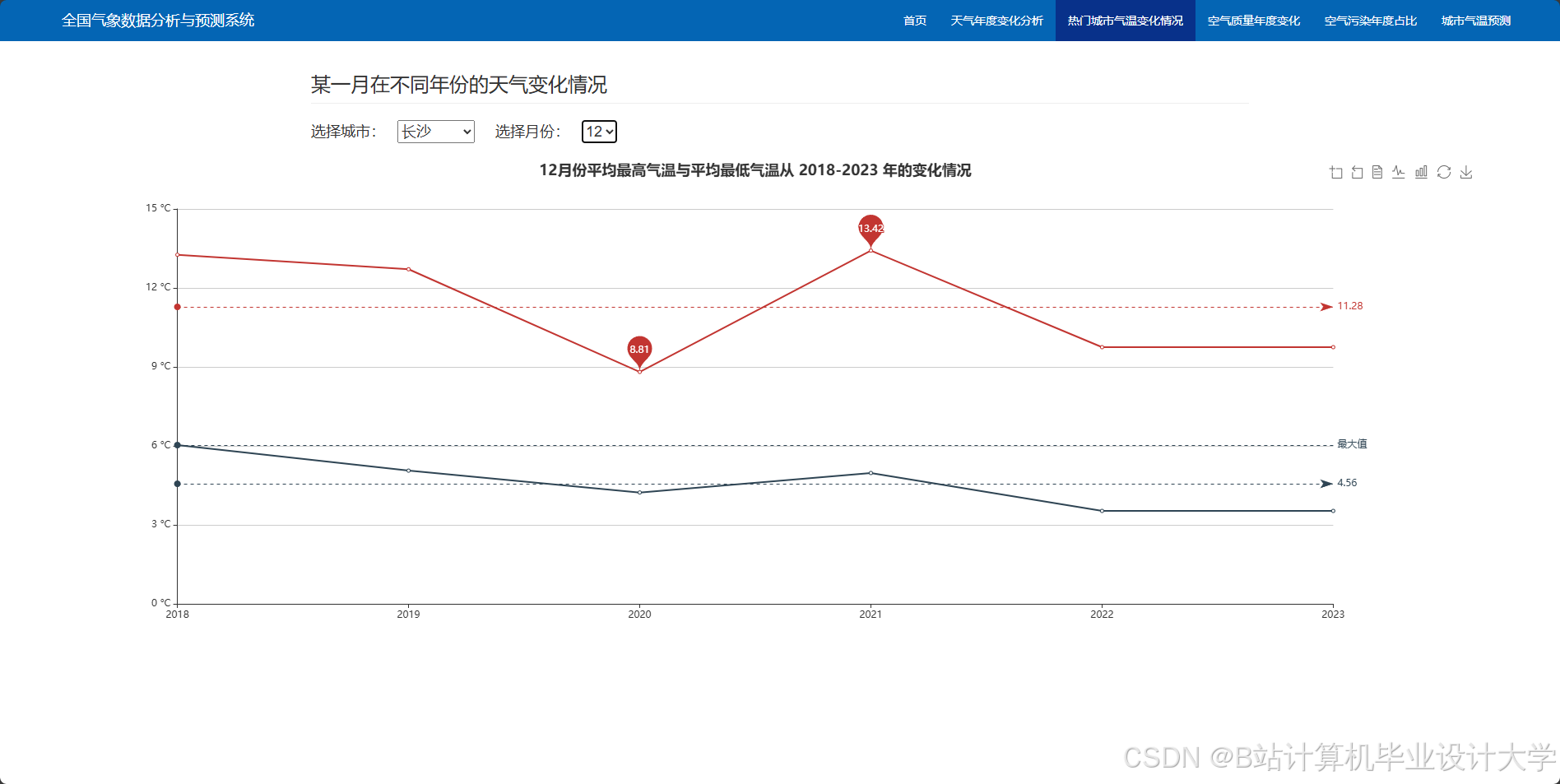
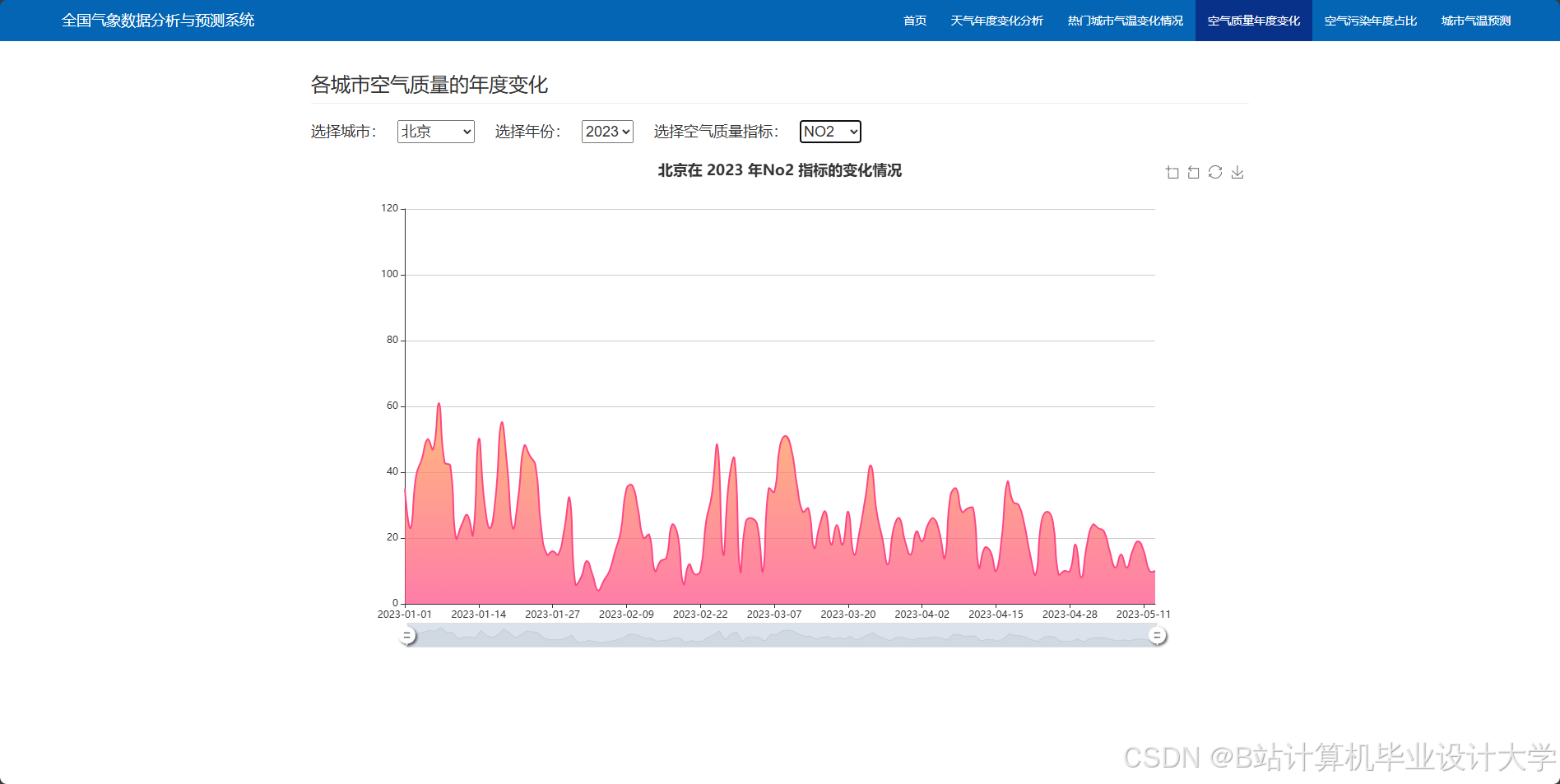
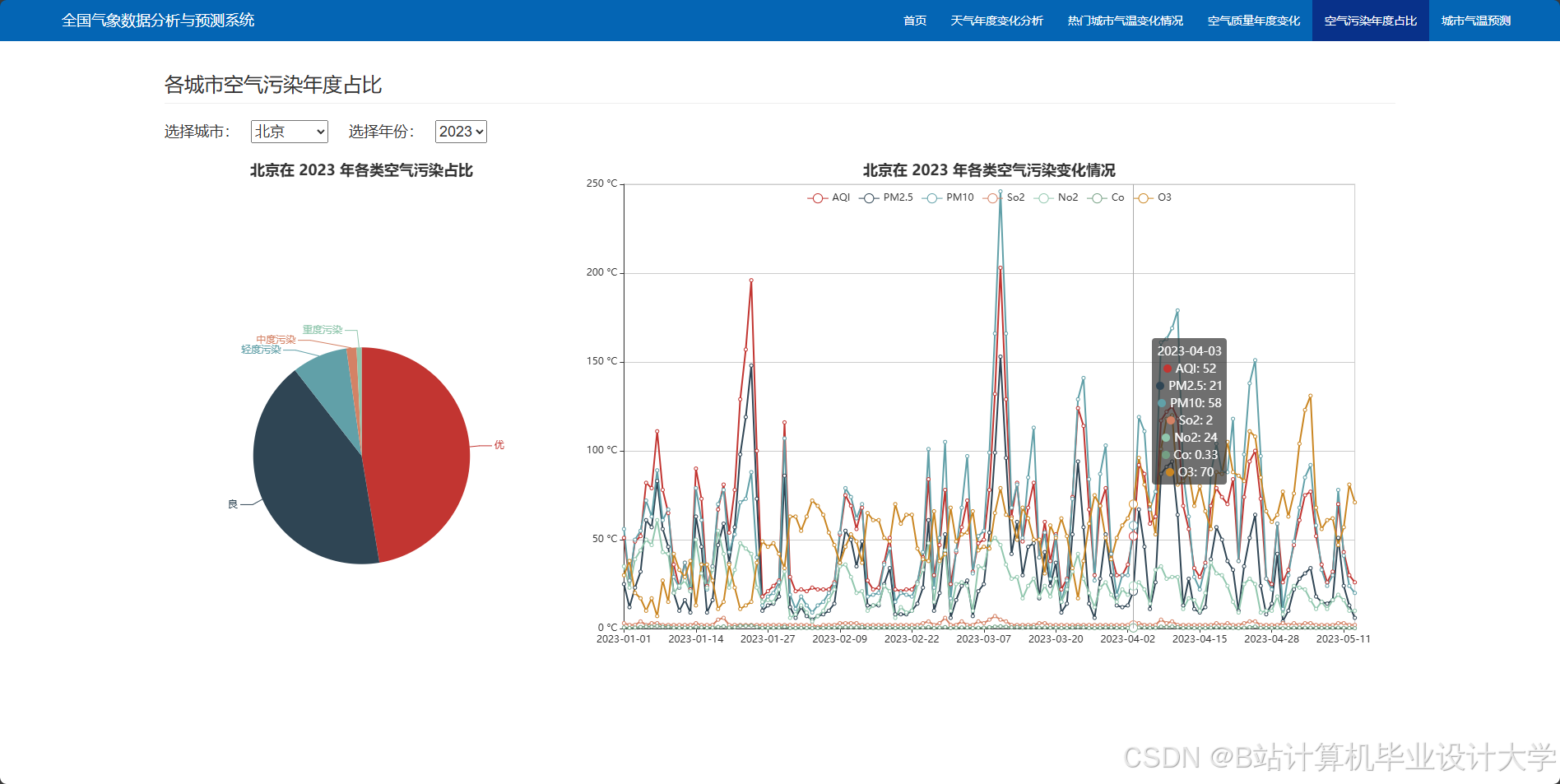
编写一个完整的气象预测深度学习算法代码涉及多个步骤,包括数据预处理、模型构建、训练和评估。以下是一个简化的示例,使用Python和TensorFlow/Keras库来构建和训练一个基本的神经网络模型进行气象预测。
假设我们有一个CSV文件weather_data.csv,其中包含日期、温度、湿度、风速等特征,以及我们要预测的目标变量(例如,未来一天的温度)。
1. 导入必要的库
python复制代码
import pandas as pd |
|
import numpy as np |
|
from sklearn.model_selection import train_test_split |
|
from sklearn.preprocessing import StandardScaler |
|
from tensorflow.keras.models import Sequential |
|
from tensorflow.keras.layers import Dense, LSTM |
|
from tensorflow.keras.optimizers import Adam |
|
import matplotlib.pyplot as plt |
2. 数据预处理
python复制代码
# 读取数据 |
|
data = pd.read_csv('weather_data.csv') |
|
# 假设CSV文件包含以下列:['date', 'temperature', 'humidity', 'wind_speed', 'target_temperature'] |
|
# 提取特征和目标变量 |
|
features = data[['temperature', 'humidity', 'wind_speed']] |
|
target = data['target_temperature'] |
|
# 将日期列转换为时间特征(可选,这里简单处理) |
|
# data['date'] = pd.to_datetime(data['date']) |
|
# data['day_of_year'] = data['date'].dt.dayofyear |
|
# features = data[['day_of_year', 'temperature', 'humidity', 'wind_speed']] |
|
# 标准化特征 |
|
scaler = StandardScaler() |
|
features_scaled = scaler.fit_transform(features) |
|
# 创建时间序列数据 |
|
def create_sequences(data, seq_length): |
|
xs, ys = [], [] |
|
for i in range(len(data) - seq_length): |
|
x = data[i:i + seq_length] |
|
y = target[i + seq_length] |
|
xs.append(x) |
|
ys.append(y) |
|
return np.array(xs), np.array(ys) |
|
SEQ_LENGTH = 10 # 使用过去10天的数据预测未来一天的温度 |
|
X, y = create_sequences(features_scaled, SEQ_LENGTH) |
|
# 划分训练集和测试集 |
|
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
|
# 重塑输入数据以符合LSTM输入要求 [samples, time steps, features] |
|
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], X_train.shape[2])) |
|
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], X_test.shape[2])) |
3. 构建模型
python复制代码
model = Sequential() |
|
model.add(LSTM(50, return_sequences=True, input_shape=(SEQ_LENGTH, features.shape[1]))) |
|
model.add(LSTM(50)) |
|
model.add(Dense(1)) |
|
model.compile(optimizer=Adam(learning_rate=0.001), loss='mean_squared_error') |
4. 训练模型
python复制代码
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.1, verbose=1) |
5. 评估模型
python复制代码
# 预测 |
|
y_pred = model.predict(X_test) |
|
# 计算均方误差(MSE) |
|
mse = np.mean((y_test - y_pred.flatten()) ** 2) |
|
print(f'Mean Squared Error: {mse}') |
|
# 可视化结果 |
|
plt.figure(figsize=(10, 5)) |
|
plt.plot(y_test, label='True Values') |
|
plt.plot(y_pred, label='Predicted Values') |
|
plt.legend() |
|
plt.show() |
注意事项
- 数据预处理:实际项目中,数据预处理可能更加复杂,包括处理缺失值、异常值、特征工程等。
- 模型选择:LSTM(长短期记忆网络)适合处理时间序列数据,但根据具体任务和数据,可能需要尝试其他模型,如GRU、CNN或Transformer。
- 超参数调优:学习率、批次大小、层数、神经元数量等超参数对模型性能有显著影响,可以通过网格搜索或随机搜索进行调优。
- 评估指标:除了MSE,还可以考虑其他评估指标,如MAE(平均绝对误差)、R²(决定系数)等。
这个示例代码提供了一个基本的框架,实际应用中需要根据具体需求进行调整和优化。