当今数字化时代,机器学习(Machine Learning)已经成为了人工智能的核心组成部分。随着数据的爆炸式增长和计算能力的提升,机器学习技术得以快速发展,并在各个领域展现出巨大的潜力。在这个过程中,机器学习不仅成为了科学家和工程师的利器,也渗透到了我们日常生活的方方面面,从推荐系统到语音助手,再到自动驾驶汽车,无不展现出其强大的应用价值。
然而,对于很多人来说,机器学习仍然是一个神秘的领域。许多人听说过它,但却不太了解它的工作原理。机器学习究竟是什么?它如何工作?为何如此强大?本文将带您深入探索机器学习的概念,并着重介绍其中两种重要的方法:监督学习(Supervised Learning)和非监督学习(Unsupervised Learning)。
1.什么是机器学习
机器学习的概念源于人类对于模仿和理解人类学习过程的渴望。想象一下,当我们教孩子学习区分苹果和橙子时,我们不是向他们详细解释每种水果的特征,而是通过展示大量的例子来帮助他们理解。机器学习的目标与此类似,它试图通过向计算机展示大量的数据样本,使计算机能够从中学习并提取规律,从而做出准确的预测或执行特定任务。
换句话说,机器学习是一种让计算机从数据中学习的方法,而不需要显式地编写规则或指令。传统的编程方法通常涉及手动编写大量的代码来告诉计算机如何执行特定的任务,而机器学习则采用了一种更加灵活的方法:让计算机通过数据自行发现规律并作出决策。
这种能力的实现离不开大量的数据和强大的计算能力。随着互联网和各种传感器技术的发展,我们正处于数据爆炸的时代,这为机器学习提供了丰富的数据资源。同时,随着计算机硬件和算法的不断进步,我们能够以前所未有的速度和规模处理这些数据,并从中提取有价值的信息。

2.机器学习的应用场景
机器学习的应用场景十分多样,展现了其在各个领域的重要性和广泛应用。从科学研究到商业领域,机器学习都扮演着关键角色。谈及机器学习时,有许多激动人心的应用案例可以彰显其巨大潜力。以下是三个典型例子:
-
语音识别(Speech Recognition):
语音识别技术利用机器学习算法,使计算机能够理解和识别人类语言。通过大量的语音样本数据进行训练,机器学习模型可以学习到语言的特征和模式,并将其转换为文字形式。例如,智能助手如Apple的Siri、亚马逊的Alexa以及谷歌的Google Assistant等,就是基于语音识别技术开发的,它们能够理解用户的语音指令并作出相应的响应。

-
图像分类(Image Classification):
图像分类是另一个常见的机器学习应用领域,它使计算机能够自动识别图像中的物体或场景。通过向计算机展示大量带有标签的图像,机器学习模型可以学习到不同物体的特征和模式,并能够准确地将新的图像分类到正确的类别中去。例如,图像搜索引擎、智能相册应用和自动驾驶汽车中的视觉感知系统,都是基于图像分类技术构建的。
-
个性化推荐系统(Personalized Recommendation Systems):
个性化推荐系统利用机器学习算法,分析用户的历史行为和偏好,从而向他们推荐最符合其兴趣的内容或产品。通过收集用户的点击、浏览、购买等数据,机器学习模型可以建立用户的兴趣模型,并基于此进行个性化推荐。例如,视频流媒体平台如Netflix和YouTube、电子商务网站如Amazon和淘宝,都利用个性化推荐系统来提高用户体验和销售效率。
3.监督学习和非监督学习
监督学习和非监督学习之所以被视为机器学习的两个主要分支,是因为它们代表了不同的解决问题的方式和数据类型的处理方式。监督学习侧重于预测和分类任务,需要标签数据的指导;而非监督学习则更注重数据的结构和模式的发现,适用于无标签数据的处理。这两种方法的结合为我们提供了丰富的工具箱,以解决各种现实世界的问题,并推动了机器学习领域的不断发展。
监督学习
监督学习(Supervised Learning)是一种机器学习的方法,其核心思想是通过使用带有标签的数据来训练模型,从而使模型能够学习输入数据与输出标签之间的关系。这意味着对于每个训练样本,我们都知道其对应的输入特征以及正确的输出标签。监督学习的目标是训练一个模型,使其能够从输入特征预测出正确的输出标签。
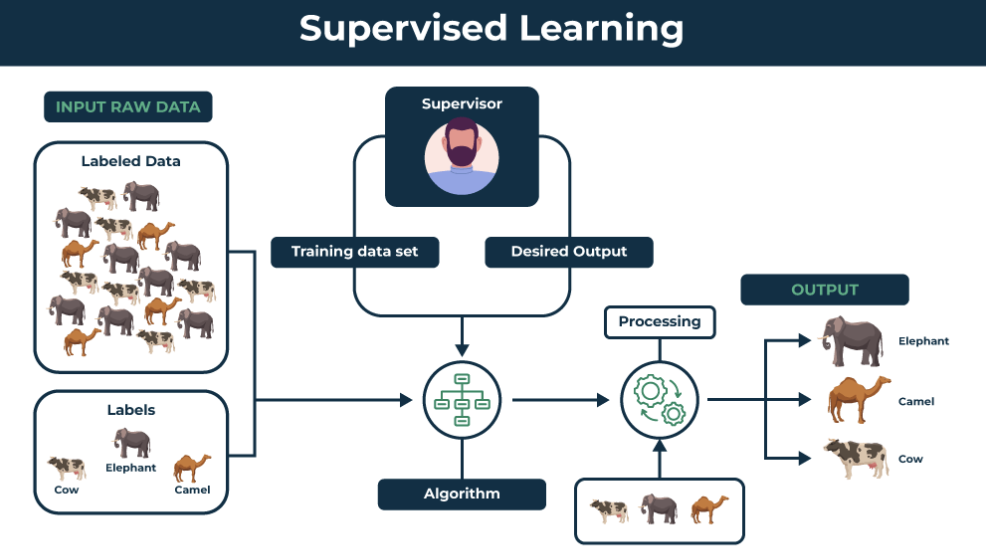

监督学习的原理基于统计学和最优化理论。在监督学习中,我们通常定义一个模型,它具有一组参数,这些参数用来描述输入数据和输出标签之间的关系。然后,我们使用带有标签的训练数据来调整模型的参数,使其能够最大程度地拟合训练数据,并在未见过的数据上进行准确的预测。
监督学习的主要算法包括线性回归、逻辑回归、决策树、支持向量机等。每种算法都有其特定的优势和适用场景,但它们的基本原理都是相似的:通过学习训练数据来调整模型的参数,从而使模型能够准确地预测未知数据的输出标签。
监督学习在各个领域都有广泛的应用
- 分类任务:
-
图像分类: 举例来说,监督学习可以应用于图像分类任务中。比如,一个模型可以通过学习大量带有标签的猫和狗的图像,来区分图像中的动物是猫还是狗。这种技术在图像搜索引擎、安防监控系统等方面有着广泛的应用。
-
文本分类: 另一个例子是文本分类任务,比如垃圾邮件检测。通过监督学习,模型可以学习识别电子邮件中的垃圾信息,并将其分类到垃圾邮件文件夹中,这有助于提高用户的电子邮件体验。
- 回归任务:
-
房价预测: 在房地产行业中,监督学习可以用于预测房价。通过学习历史房屋销售数据以及房屋特征(如面积、地理位置等),模型可以预测未来房屋的销售价格,这对于买家和卖家都具有重要意义。
-
股票价格预测: 另一个例子是股票价格预测。通过监督学习,模型可以学习历史股票价格数据以及与之相关的因素(如公司财务状况、市场趋势等),从而预测未来股票价格的走势,这对于投资者制定投资策略具有重要价值。

- 预测任务:
-
天气预测: 天气预测是另一个广泛应用监督学习的领域。通过监督学习,模型可以学习大量的气象数据和地理信息,以预测未来几天甚至几周的天气情况。这对于农业、航空、航海等行业都具有重要的影响。
-
交通流量预测: 最后,交通流量预测也是一个常见的预测任务。通过监督学习,模型可以学习历史交通流量数据以及与之相关的因素(如时间、天气、道路状况等),从而预测未来某个时间段某个地点的交通流量,这有助于优化交通管理和规划道路建设。
(2)非监督学习
非监督学习(Unsupervised Learning)作为机器学习的一种重要方法,致力于从未标记的数据中挖掘信息,揭示数据之间的内在联系和结构。与监督学习不同,非监督学习不依赖预先定义的输出标签,而是通过数据本身的特征进行学习和分析。这种方法的灵活性使得非监督学习适用于各种类型的数据,从而帮助我们更深入地理解数据的本质,发现其中的潜在模式和价值,为进一步的数据挖掘、分析和决策提供了重要的基础。
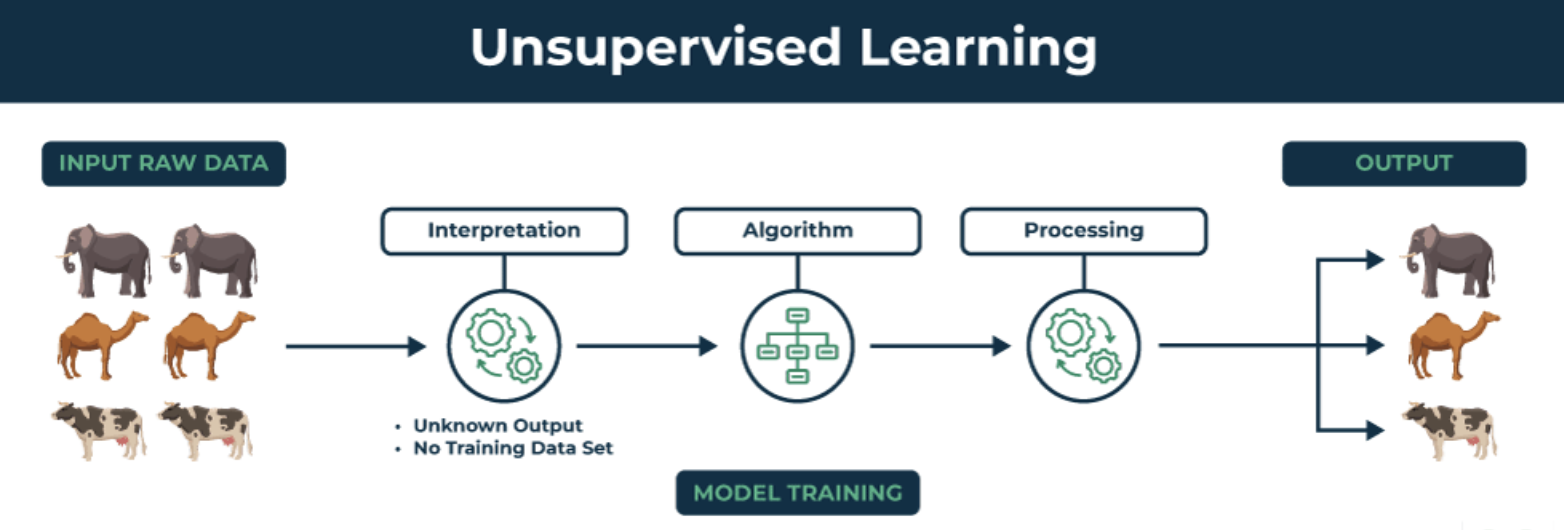
-
图像聚类
想象一下你有一堆未标记的图片,它们来自不同的场景、主题和风格。通过非监督学习中的图像聚类算法,可以将这些图片自动分组,形成相似主题或内容的图片集合,比如将自然风景、动物、人物等分到不同的组别中。 -
社交网络分析
社交网络中有大量的用户,他们之间通过各种方式相互联系。非监督学习可以应用于社交网络分析,将用户分组或发现用户之间的共同兴趣。例如,通过分析用户之间的互动行为和信息分享,可以发现具有相似兴趣爱好的用户群体,从而为社交网络平台提供更精准的推荐和个性化服务。
-
文本主题建模
假设你有大量未标记的文本数据,如新闻文章、博客帖子或社交媒体消息。通过非监督学习中的文本主题建模技术,可以自动发现文本数据中的主题和话题。这有助于理解文本内容的结构和含义,从而为信息检索、内容推荐等任务提供支持。