文章目录
一、摘要
摘要:为了在同时定位与建图(SLAM)任务中实现精确且稳健的位姿估计,多传感器融合已被证明是一种有效的解决方案,因此在机器人应用中具有巨大的潜力。本文提出了FAST-LIVO,一种快速的激光雷达-惯性-视觉里程计系统,构建于两个紧耦合且直接的里程计子系统之上:视觉-惯性里程计(VIO)子系统和激光雷达-惯性里程计(LIO)子系统。LIO子系统将新扫描的原始点(而非如边缘或平面上的特征点)注册到逐步构建的点云地图中。地图点附带图像补丁,在VIO子系统中,通过最小化直接的光度误差而非提取视觉特征(如ORB或FAST角点特征)来对齐新图像。为进一步提高VIO的鲁棒性和精度,本文提出了一种新的异常点剔除方法,用于剔除位于边缘或在图像视图中被遮挡的、不稳定的地图点。在公开数据序列和自定义设备数据上的实验表明,所提系统优于其他对比系统,并能够以较低的计算成本应对复杂环境。该系统支持多线旋转激光雷达和新兴的固态激光雷达,适用于完全不同的扫描模式,且可在Intel和ARM处理器上实时运行。我们在Github上开源了本工作的代码和数据集,以造福机器人学社区。
二、介绍
近年来,同时定位与建图(SLAM)在未知环境中的实时3D重建和定位方面取得了显著进展。目前,已经有多个成功实现的框架使用单一测量传感器,如相机 [1, 2] 或激光雷达 [3]–[5]。然而,随着在现实世界中操作智能机器人的需求日益增加,而现实世界通常包含结构不清晰或纹理较少的环境,现有的单一传感器系统无法达到所需的精确且稳健的位姿估计。为解决该问题,多传感器融合技术 [6]–[9] 得到了越来越多的关注,通过结合不同传感器的优势,在传感器退化的环境中提供有效的位姿估计,显示出在机器人应用中的巨大潜力。在机器人应用中,摄像头、激光雷达和惯性测量单元(IMU)可能是SLAM任务中最广泛使用的传感器。近年来,已经提出了几种激光雷达-惯性-视觉里程计(LIVO)系统,如R2LIVE [10] 和 LVI-SAM [11],以实现稳健的状态估计。通常这些系统包含一个激光雷达-惯性里程计(LIO)子系统和一个视觉-惯性里程计(VIO)子系统,共同融合状态向量,但在数据处理时各自独立进行,未考虑测量级的耦合。这类系统往往占用较大的计算资源。为了解决这一问题,我们提出了一种快速且紧耦合的稀疏直接激光雷达-惯性-视觉里程计系统(FAST-LIVO),结合稀疏直接图像对齐和直接原始点注册的优势,以降低计算成本实现精确且可靠的位姿估计。本文的主要贡献如下:
- 提出了一种紧凑的激光雷达-惯性-视觉里程计框架,基于两个直接且紧耦合的里程计系统:LIO子系统和VIO子系统。这两个子系统通过分别融合各自的激光雷达或视觉数据与IMU,共同估计系统状态。
- 提出了一种直接且高效的VIO子系统,最大限度地重用LIO子系统构建的点云地图。具体而言,地图中的点附带先前观察到的图像补丁,并将其投影到新图像中以对齐位姿(即整个系统状态),通过最小化直接光度误差来实现。VIO子系统中的激光雷达点重用避免了视觉特征的提取、三角化或优化,并在测量级耦合了两个传感器。
- 将所提出的系统实现为一个实际的开源软件,可在Intel和ARM处理器上实时运行,并支持多线旋转激光雷达和固态激光雷达,适用于完全不同的扫描模式。
在公开数据序列(如NTU VIRAL数据集 [12])和自定义设备数据上验证了开发的系统。结果表明,所提系统优于其他同类系统,并能够在降低计算成本的同时处理传感器退化的复杂环境。
相关工作
A. 直接方法
- 直接法是实现视觉和激光雷达SLAM中快速位姿估计的最常用方法之一。与特征法不同(如[1, 3, 6, 13]),特征法需要提取显著的特征点(例如,图像中的角点和边缘像素;激光雷达扫描中的平面和边缘点),并生成稳健的特征描述子用于匹配。而直接法则通过最小化误差函数直接使用原始测量值来优化传感器位姿 [14],如使用光度误差或点到平面残差的方法 [15], [16]。这种方法省去了通常耗时的特征提取和匹配过程,从而实现快速位姿估计。由于缺乏稳健的特征匹配,直接法高度依赖于良好的状态初始化。密集直接法主要用于RGB-D相机跟踪 [17, 18, 19],其中每帧图像包含一个密集深度图,并通过图像-模型对齐进行估计。稀疏直接法 [15] 则仅使用一些精心选择的原始图像块,展示了稳健且精确的状态估计,进一步降低了与密集直接法相比的计算负载。我们的工作在LIO和VIO中保持了直接法的思路。我们的LIO系统直接采用了FAST-LIO2 [16],而VIO子系统基于类似[15]的稀疏直接图像对齐,但重用LIO子系统中构建的地图点,以节省后端(即特征对齐、滑动窗口优化和/或深度滤波)的时间消耗。
B. 激光雷达-视觉-惯性SLAM
- 在激光雷达-视觉-惯性SLAM中使用多传感器,使其能够处理多种传感器失效或部分退化的复杂环境。受此启发,已有多个激光雷达-视觉-惯性SLAM系统开发出来,例如,LIMO [20] 提取激光雷达测量中的深度信息以匹配图像特征,并基于捆绑调整在关键帧间估计运动;R2LIVE [10] 是一个紧耦合的系统,通过融合激光雷达、视觉和惯性传感器,通过提取激光雷达和图像特征后,在迭代误差状态卡尔曼滤波器框架中进行重投影误差计算 [21]。在VIO子系统中,使用滑动窗口优化进一步提高地图中视觉特征的准确性。LVI-SAM [11] 是一个类似于[10]的特征法框架,但也加入了回环闭合。这些基于特征的方法由于图像和/或激光雷达特征点的提取以及后续的滑动窗口优化,通常计算成本较高。相比之下,我们提出的FAST-LIVO使用原始激光雷达点和图像像素分别进行激光雷达扫描和图像跟踪,而不提取任何特征,从而实现了更高的计算效率。我们的FAST-LIVO的VIO子系统与DVL-SLAM [22, 23] 最为相似,后者将激光雷达点投影到新图像中并通过最小化直接光度误差进行图像跟踪。然而,DVL-SLAM仅执行帧间图像对齐,不包含任何IMU测量或激光雷达扫描配准。相比之下,我们的系统FAST-LIVO在集成卡尔曼滤波器中紧耦合了帧-地图图像对齐、激光雷达扫描配准和IMU测量。同时,我们提出了一种可靠且稳健的离群点剔除方法,当将激光雷达测量投影到图像平面时进一步提高了系统的准确性。
三、方法
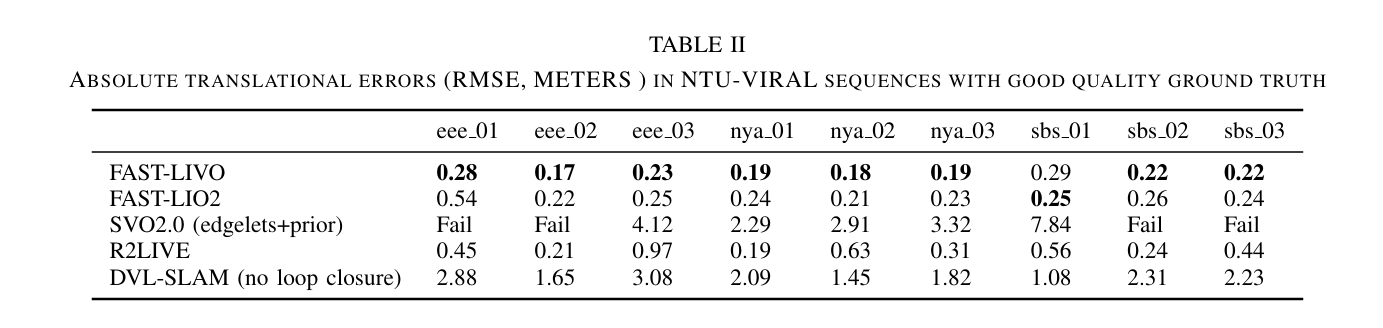
本文使用表I中的符号表示。图1展示了我们系统的概览,其中包含两个子系统:LIO子系统(蓝色部分)和VIO子系统(红色部分)。LIO子系统首先通过逆向传播法 [24] 补偿激光雷达扫描中的运动畸变,然后计算帧到地图的点到平面的残差。类似地,VIO子系统从视觉全局地图中提取当前视野内的视觉子地图,并剔除子地图中的离群点(即被遮挡或存在深度不连续的点)。接着,进行稀疏直接视觉对齐,以计算帧到地图的图像光度误差。激光雷达的点到平面残差和图像的光度误差通过误差状态迭代卡尔曼滤波器与IMU传播紧密融合。融合后的位姿用于将新点添加到全局地图中。
FAST-LIVO的状态估计是一个紧耦合的误差状态迭代卡尔曼滤波器(ESIKF),它融合了来自激光雷达、相机和惯性测量单元(IMU)的测量数据。这里我们主要解释系统模型(状态转移模型和测量模型)。读者可以参考[25]以了解流形上的迭代卡尔曼滤波器(ISIKF)的详细结构和实现。
A. boxplus“田”和boxminus“日”操作符
在本节中,我们使用“田”和“日”操作来表示流形 M 上状态的误差。具体来说,对于本文考虑的 M = S O ( 3 ) × R n \mathcal{M}=SO(3)\times R^{n} M=SO(3)×Rn,我们有:
[ R a ] ⊞ [ r b ] ≜ [ R ⋅ Exp ( r ) a + b ] , [ R 1 a ] ⊟ [ R 2 b ] ≜ [ Log ( R 2 T R 1 ) a − b ] \left[\begin{array}{l} R\\ a\end{array}\right]\boxplus\left[\begin{array}{l} r\\ b\end{array}\right]\triangleq\left[\begin{array}{l} R\cdot\operatorname{Exp}(r)\\ a+b\end{array}\right],\left[\begin{array}{l} R_{1}\\ a\end{array}\right]\boxminus\left[\begin{array}{l} R_{2}\\ b\end{array}\right]\triangleq\left[\begin{array}{l}\operatorname{Log}\left(R_{2}^{T}R_{1}\right)\\ a-b\end{array}\right] [Ra]⊞[rb]≜[R⋅Exp(r)a+b],[R1a]⊟[R2b]≜[Log(R2TR1)a−b]
其中 r ∈ R 3 , a , b ∈ R n \ r \in \mathbb{R}^3, a, b \in \mathbb{R}^n r∈R3,a,b∈Rn, Exp ( ⋅ ) \operatorname{Exp}(\cdot) Exp(⋅) 和 Log ( ⋅ ) \operatorname{Log}(\cdot) Log(⋅) 表示根据罗德里格斯公式从旋转矩阵到旋转向量的双向映射。
B. 状态转移模型
在我们的系统中,我们假设三个传感器(激光雷达、IMU 和相机)之间的时间偏移是已知的,这些可以在事先校准或同步。我们以 IMU 框架(记为 I)作为机体框架,并将第一个机体框架作为全局框架(记为 G)。此外,我们假设三个传感器刚性连接在一起,并且如表 I 所定义的外参已预先校准。然后,第 i 次 IMU 测量的离散状态转移模型为:
x i + 1 = x i ⊞ ( Δ t f ( x i , u i , w i ) ) ( 1 ) x_{i+1} = x_i \boxplus \left( \Delta t f\left(x_i, u_i, w_i\right) \right) \qquad (1) xi+1=xi⊞(Δtf(xi,ui,wi))(1)
其中 $\ \Delta t $ 是 IMU 采样周期,状态 x \ x x,输入 u \ u u,过程噪声 w \ w w 和函数 f \ f f 定义如下:
M ≜ S O ( 3 ) × R 15 , dim ( M ) = 18 x ≜ [ G R I T G p I T G v T b g T b a T G g T ] T ∈ M u ≜ [ ω m T a m T ] T , w ≜ [ n g T n a T n b g T n b a T ] T f ( x , u , w ) = [ ω m − b g − n g G v + 1 2 ( G R I ( a m − b a − n a ) + G g ) Δ t G R I ( a m − b a − n a ) + G g n b g n b a 0 3 × 1 ] ∈ R 18 \begin{align*} \mathcal{M} &\triangleq SO(3) \times \mathbb{R}^{15}, \operatorname{dim}(\mathcal{M}) = 18 \\ x &\triangleq \left[ \begin{array}{lllll} {}^G R_I^T & {}^G p_I^T & {}^G v^T & b_g^T & b_a^T & {}^G g^T \end{array} \right]^T \in \mathcal{M} \\ u &\triangleq \left[ \begin{array}{llll} \omega_m^T & a_m^T \end{array} \right]^T, \quad w \triangleq \left[ \begin{array}{lllll} n_g^T & n_a^T & n_{bg}^T & n_{ba}^T \end{array} \right]^T \\ f(x, u, w) & = \left[ \begin{array}{c} \omega_m - b_g - n_g \\ {}^G v + \frac{1}{2} \left( {}^G R_I \left( a_m - b_a - n_a \right) + {}^G g \right) \Delta t \\ {}^G R_I \left( a_m - b_a - n_a \right) + {}^G g \\ n_{bg} \\ n_{ba} \\ 0_{3 \times 1} \end{array} \right] \in \mathbb{R}^{18} \end{align*} Mxuf(x,u,w)≜SO(3)×R15,dim(M)=18≜[GRITGpITGvTbgTbaTGgT]T∈M≜[ωmTamT]T,w≜[ngTnaTnbgTnbaT]T= ωm−bg−ngGv+21(GRI(am−ba−na)+Gg)ΔtGRI(am−ba−na)+Ggnbgnba03×1 ∈R18
其中 G R I \ {}^G R_I GRI 和 G p I \ {}^G p_I GpI 分别表示全局框架中的 IMU 姿态和位置, G g \ {}^G g Gg 是全局框架中的重力向量, ω m \ \omega_m ωm 和 a m \ a_m am 是原始的 IMU 测量值, n g \ n_g ng 和 n a \ n_a na 分别是 ω m \ \omega_m ωm 和 a m \ a_m am 中的测量噪声, b a \ b_a ba 和 b g \ b_g bg 是 IMU 偏差,它们被建模为由高斯噪声 n b g \ n_{bg} nbg 和 n b a \ n_{ba} nba 分别驱动的随机游走。
C. 前向传播
我们使用前向传播来预测每个IMU输入 u i u_{i} ui 时的状态 x ^ i + 1 \hat{x}_{i+1} x^i+1 及其协方差 P ^ i + 1 \hat{P}_{i+1} P^i+1。更具体地说,通过将 (1) 中的过程噪声 w i w_{i} wi 设置为零来传播状态:
x ^ i + 1 = x ^ i ⊞ ( Δ t f ( x ^ i , u i , 0 ) ) ( 2 ) \hat{x}_{i+1} = \hat{x}_i \boxplus \left( \Delta t f\left(\hat{x}_i, u_i, 0\right) \right)\qquad (2) x^i+1=x^i⊞(Δtf(x^i,ui,0))(2)
协方差传播如下:
P ^ i + 1 = F δ x ^ P ^ i F δ x ^ T + F w Q F w T F δ x ^ = ∂ δ x ^ i + 1 ∂ δ x ^ i ∣ δ x ^ i = 0 , w i = 0 , F w = ∂ δ x ^ i + 1 ∂ w i ∣ δ x ^ i = 0 , w i = 0 ( 3 ) \begin{align*} &\hat{P}_{i+1} = F_{\delta\hat{x}}\hat{P}_i F_{\delta\hat{x}}^T + F_{w} Q F_{w}^T \\ &\left. F_{\delta\hat{x}} = \frac{\partial \delta\hat{x}_{i+1}}{\partial \delta\hat{x}_i} \right|_{\delta\hat{x}_i=0, w_i=0}, \quad F_{w} = \left. \frac{\partial \delta\hat{x}_{i+1}}{\partial w_i} \right|_{\delta\hat{x}_i=0, w_i=0} \qquad (3) \end{align*} P^i+1=Fδx^P^iFδx^T+FwQFwTFδx^=∂δx^i∂δx^i+1 δx^i=0,wi=0,Fw=∂wi∂δx^i+1 δx^i=0,wi=0(3)
其中 Q 是 w w w 的协方差, δ x ^ i ≜ x i ⊟ x ^ i \delta\hat{x}_{i} \triangleq x_{i} \boxminus \hat{x}_{i} δx^i≜xi⊟x^i, F δ x ^ F_{\delta\hat{x}} Fδx^ 和 F w F_{w} Fw 的具体形式可以在[10,24]中找到。
状态预测 (2) 和协方差 (3) 从时间 t k − 1 t_{k-1} tk−1 开始传播,这是最后一次接收到激光雷达或图像测量的时间,直到时间 t k t_k tk,这是当前接收到激光雷达或图像测量的时间,在此过程中接收到每个 IMU 测量 u i u_{i} ui 在 t k − 1 t_{k-1} tk−1 和 t k t_{k} tk 之间。初始状态和协方差在 (2) 和 (3) 中是 x ˉ k − 1 \bar{x}_{k-1} xˉk−1 和 P ˉ k − 1 \bar{P}_{k-1} Pˉk−1,这些是通过融合最后一次激光雷达或图像测量获得的(见第 IV-E 节)。我们用 x ^ k \hat{x}_{k} x^k 和 P ^ k \hat{P}_{k} P^k 分别表示直到 t k t_{k} tk 传播的状态和协方差。请注意,我们不假设激光雷达扫描和图像是同时接收的。激光雷达扫描或图像的到达将导致状态的更新,详见第 IV-E 节。
D. 帧到地图测量模型
- 激光雷达测量模型:如果在时间 t k t_k tk 接收到激光雷达扫描,我们首先执行 [24] 中提出的反向传播来补偿运动失真。扫描中的点 { L p j } \left\{ {}^{L} p_{j}\right\} { Lpj} 可以被视为在 t k t_k tk 同时采样,并在同一激光雷达局部框架 L 中表示。当将扫描点 { L p j } \left\{ {}^{L} p_{j}\right\} { Lpj} 注册到地图时,我们假设每个点都位于地图中的邻近平面上,其法向量为 u j u_{j} uj,中心点为 q j q_{j} qj。也就是说,如果将测量的 L p j {}^{L} p_{j} Lpj 从激光雷达局部框架转换到全局框架,使用真实状态(即姿态) x k x_{k} xk,则残差应为零:
0 = r l ( x k , L p j ) = u j T ( G T I k I T L L p j − q j ) ( 4 ) 0 = r_{l}\left(x_{k},{}^{L} p_{j}\right) = u_{j}^{T}\left({}^{G} T_{I_{k}}{}^{I} T_{L}{}^{L} p_{j} - q_{j}\right) \qquad (4) 0=rl(xk,Lpj)=ujT(GTIkITLLpj−qj)(4)
在实践中,为了找到邻近平面,我们使用预测状态 x ^ k \hat{x}_{k} x^k 的姿态将 L p j {}^{L} p_{j} Lpj 转换到全局框架,通过 G p ^ j = G T ^ I k I T L L p j {}^{G}\hat{p}_{j} = {}^{G}\hat{T}_{I_{k}}{}^{I} T_{L}{}^{L} p_{j} Gp^j=GT^IkITLLpj 并搜索激光雷达全局地图中最近的 5 个点,该地图由增量式 kd-tree 结构,ikd-tree[16] 组织,以拟合一个平面。然后,(4) 中的方程为状态 x k x_{k} xk 定义了一个隐式测量模型。为了考虑 L p j {}^{L} p_{j} Lpj 中的测量噪声,该方程通过一个因子 Σ l \Sigma_{l} Σl 加权。

- 稀疏直接视觉对齐测量模型:与[15]中的帧到帧图像对齐不同,我们通过从粗到细的方式最小化光度误差来执行稀疏直接帧到地图图像对齐,见图 2。具体来说,如果在时间 t k t_k tk 接收到图像,我们从全局视觉地图中提取落在图像视场(FoV)内的地图点 { G p } \{Gp\} { Gp}(见第 V-B.2 节)。对于每个地图点 G p Gp Gp,它已经附带了在不同先前图像中观察到的补丁(见第 V-B 节),我们选择在当前图像中观察该点与最近观测角度的图像路径作为参考路径(记为 Q i Q_{i} Qi)。
然后,将地图点 G p i {}^{G} p_{i} Gpi 转换到当前图像 I k ( ⋅ ) I_{k}(\cdot) Ik(⋅) 使用真实状态(即姿态) x k x_{k} xk, Q i Q_{i} Qi 与当前图像中相应路径之间的光度误差应为零:
0 = r c ( x k , G p i ) = I k ( π ( I T C − 1 G T I k − 1 G p i ) ) − A i Q i ( 5 ) 0 = r_{c}\left(x_{k}, {}^{G} p_{i}\right) = I_{k}\left(\pi\left({}^{I} T_{C}^{-1} {}^{G} T_{I_{k}}^{-1} {}^{G} p_{i}\right)\right) - A_{i} Q_{i} \qquad (5) 0=rc(xk,Gpi)=Ik(π(ITC−1GTIk−1Gpi))−AiQi(5)
其中 π ( ⋅ ) \pi(\cdot) π(⋅) 是针孔投影模型。方程 5 定义了状态 x k x_k xk 的另一个隐式测量模型,并进行了优化(见第 IV-E 节,在三个层次上,每个层次上的当前图像和参考路径都是从前一个层次中减半采样的。优化从最粗略的层次开始,一个层次收敛后,优化进入下一个更细的层次。从最粗略的层次开始,一个层次收敛后,优化进入下一个更细的层次。为了考虑图像 I k I_{k} Ik 中的测量噪声,该方程通过一个因子 Σ c \Sigma_{c} Σc 加权。
E. 误差状态迭代卡尔曼滤波器更新
从第 IV-C 节得出的传播状态 x ^ k \hat{x}_{k} x^k 和协方差 P ^ k \hat{P}_{k} P^k 为 x k x_{k} xk 提供了先验分布,如下所示:
x k ⊟ x ^ k ∼ N ( 0 , P ^ k ) . ( 6 ) x_k \boxminus \hat{x}_k \sim \mathcal{N}(0, \hat{P}_k). \qquad (6) xk⊟x^k∼N(0,P^k).(6)
结合 (6) 中的先验分布,(4) 中的激光雷达测量分布和 (5) 中的视觉测量分布,我们获得了 x k x_{k} xk 的最大后验估计(MAP):
min x k ∈ M ( ∥ x k ⊟ x ^ k ∥ P ^ k 2 + ∑ j = 1 m l ∥ r l ( x k , L p j ) ∥ Σ l 2 + ∑ i = 1 m c ∥ r c ( x k , G p i ) ∥ Σ c 2 ) ( 7 ) \begin{align*} \min_{x_{k} \in \mathcal{M}} & \left( \left\| x_{k} \boxminus \hat{x}_{k} \right\|_{\hat{P}_{k}}^{2} + \sum_{j=1}^{m_{l}} \left\| r_{l} \left( x_{k}, {}^{L}p_{j} \right) \right\|_{\Sigma_{l}}^{2} \right. \\ & \left. + \sum_{i=1}^{m_{c}} \left\| r_{c} \left( x_{k}, {}^{G}p_{i} \right) \right\|_{\Sigma_{c}}^{2} \right) \qquad (7) \end{align*} xk∈Mmin(∥xk⊟x^k∥P^k2+j=1∑ml rl(xk,Lpj) Σl2+i=1∑mc rc(xk,Gpi) Σc2)(7)
其中 ∥ x ∥ Σ 2 = x T Σ − 1 x \|x\|_{\Sigma}^{2} = x^{T}\Sigma^{-1} x ∥x∥Σ2=xTΣ−1x。请注意,如果在 t k t_{k} tk 接收到激光雷达扫描,则 7 只与 IMU 传播融合激光雷达残差 r l r_{l} rl(即 m c = 0 m_{c}=0 mc=0)。类似地,如果在 t k t_{k} tk 接收到图像,7 只与 IMU 传播融合视觉光度误差 r c r_{c} rc(即 m l = 0 m_{l}=0 ml=0)。
7 中的优化是非凸的,可以通过高斯-牛顿方法迭代求解。这种迭代优化已被证明等同于迭代卡尔曼滤波器[21]。为了处理流形约束 M \mathcal{M} M,在每次优化迭代中,我们通过第 IV-A 节中的田操作在当前状态估计的切空间(即误差状态)中参数化状态。求解出的误差状态随后更新当前状态估计,并进入下一次迭代,直到收敛。收敛后的状态估计,记为 x ‾ k \overline{x}_{k} xk,和 (7) 在收敛处的黑塞矩阵,记为 P ‾ k \overline{P}_k Pk,用于传播第 IV-C 节中描述的传入 IMU 测量。收敛后的状态也用于更新第 V-A 节和第 V-B 节中全局地图的新激光雷达扫描。
F. 地图
我们的地图由一个点云地图(激光雷达全局地图)组成,用于 LIO 子系统,以及一个附带补丁的点地图(视觉全局地图用于 VIO 子系统)。
A. 激光雷达全局地图
我们的激光雷达全局地图采用了 FAST-LIO2[16],它由所有过去的 3D 点组成,这些点被组织进一个增量式 kd-tree 结构 ikd-Tree[26] 中。ikd-Tree 提供了点查询、插入和删除的接口。它还在内部按给定分辨率对点云地图进行下采样,反复监控其树结构,并通过重建相应子树动态平衡树结构。当接收到新的激光雷达扫描时,我们使用预测的姿态在 ikd-Tree 中查询每个点的最近点(第 IV-D.1 节)。在扫描与 IMU 融合以获得 x k x_k xk(第 IV-E 节)之后,我们使用它将扫描点转换到全局框架,并以 LIO 速率将它们插入到 ikd-Tree 中。
B. 视觉全局地图
视觉全局地图是以前观察到的激光雷达点的集合。每个点都附带了多个从观察它的图像中提取的补丁。视觉全局地图的数据结构和更新如下所述:
-
数据结构:为了快速找到当前视场(FoV)内的可视化地图点,我们使用轴对齐的体素来包含视觉全局地图中的点。体素大小相同,并通过哈希表进行快速索引。一个体素中包含的点会保存其位置、从不同参考图像中提取的多个补丁金字塔,以及每个补丁金字塔的相机姿态。
-
视觉子地图和异常值排除:即使体素的数量远少于视觉地图点的数量,确定哪些体素在当前帧 FoV 内可能仍然非常耗时,特别是当地图点(因此体素)数量很大时。为了解决这个问题,我们为最新的激光雷达扫描的每个点查询这些体素。这可以通过查询体素哈希表非常高效地完成。如果相机 FoV 与激光雷达大致对齐,那么落在相机 FoV 内的地图点很可能包含在这些体素中。因此,可以通过这些体素中包含的点,然后进行 FoV 检查来获得视觉子地图。
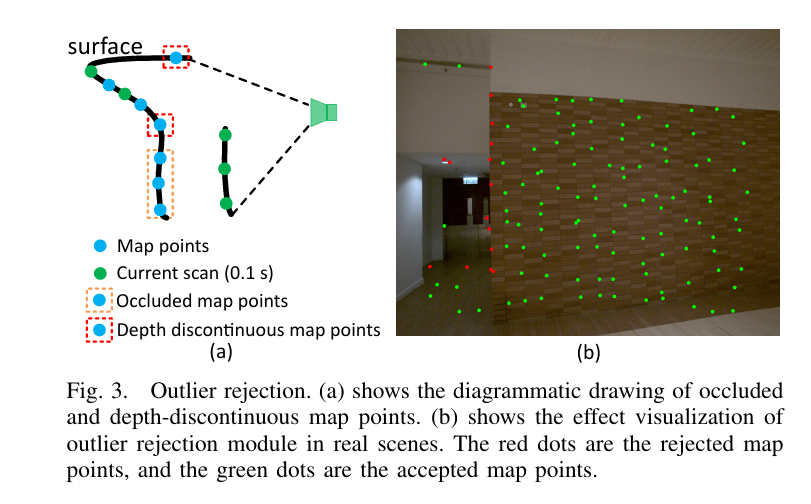
视觉子地图可能包含在当前图像帧中被遮挡或具有不连续深度的地图点,这严重降低了 VIO 的准确性。为了解决这个问题,我们使用 x k x_k xk 中的预测姿态将视觉子地图中的所有点投影到当前帧上,并保留每个 40 x 40 像素网格中的最低深度点。此外,我们将最新的激光雷达扫描中的点投影到当前帧上,并检查它们是否遮挡了在 9 x 9 邻居内投影的任何地图点,方法是检查它们的深度。被遮挡的地图点被排除(见图 3),其余的将用于对齐当前图像(第 IV-D.2 节)。
- 更新视觉全局地图:在一个新的图像帧被对齐(第 IV-D.2 节)之后,我们将当前图像中的补丁附加到 FoV 内的地图点上,以便这些地图点可能有具有均匀分布视角的有效补丁。具体来说,我们在帧对齐后选择具有高光度误差的地图点,如果距离上次添加地图点已经超过了 20 帧,我们将其添加到视觉全局地图中,并附上当前图像中的补丁。
如果地图点附加了补丁,或者当前帧中的地图点与其在上次添加补丁的参考帧中的像素位置相差超过 40 像素,我们将为其添加一个新的补丁。新的补丁从当前图像中提取,大小为 8 x 8 像素。连同金字塔一起,我们还附加了帧姿态到地图点。除了向地图点添加补丁外,我们还需要向视觉全局地图添加新的地图点。为此,我们将当前图像划分为 40 x 40 像素的网格,并在其上投影最新的激光雷达扫描中的点。在每个网格中梯度最高的投影激光雷达点将被添加到视觉全局地图中,并提取相应的补丁和图像姿态。为了避免将位于边缘的激光雷达点添加到视觉地图中,我们跳过具有高局部曲率的边缘点[3, 13]。
四、结果