笔记
作业
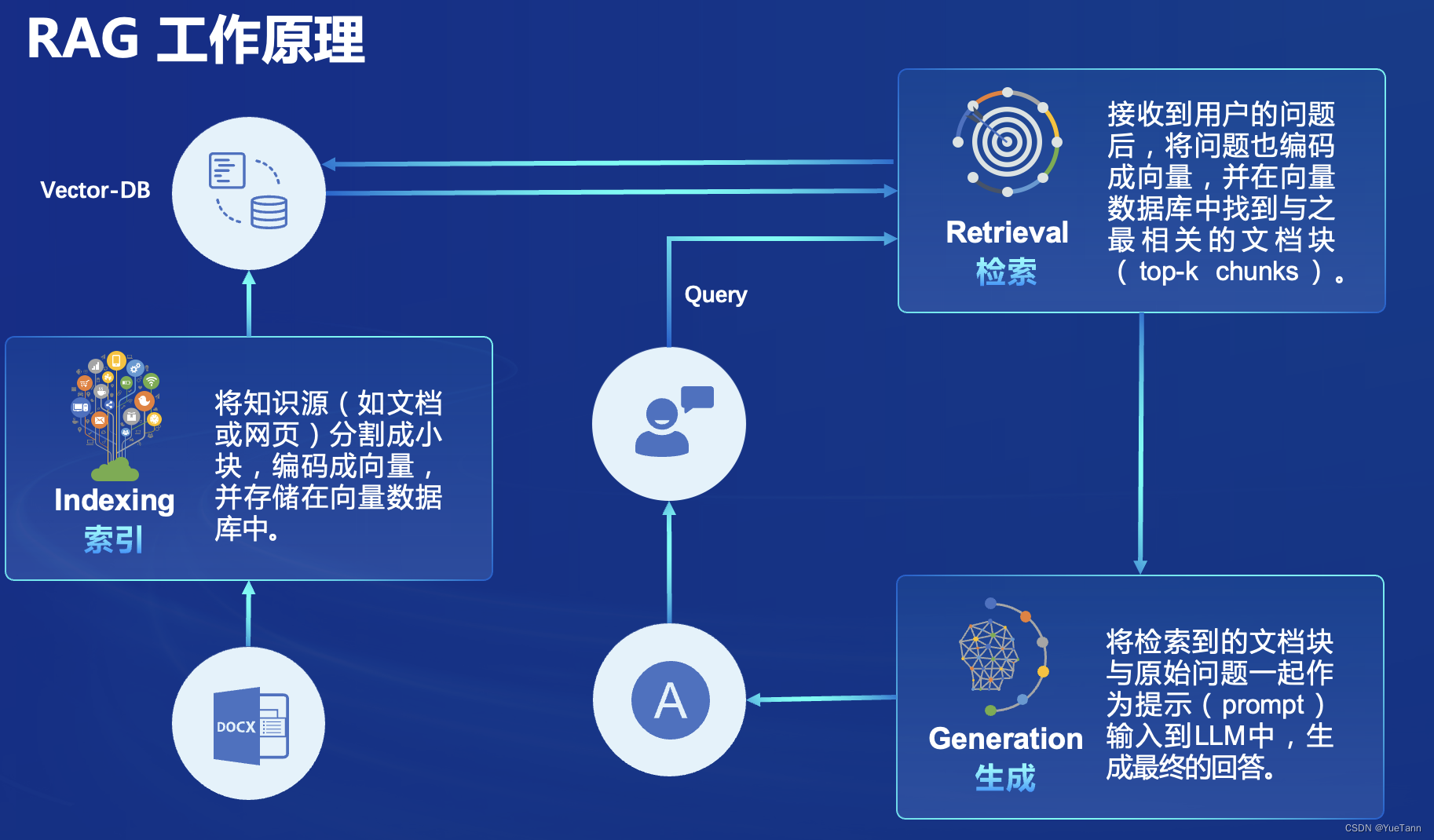
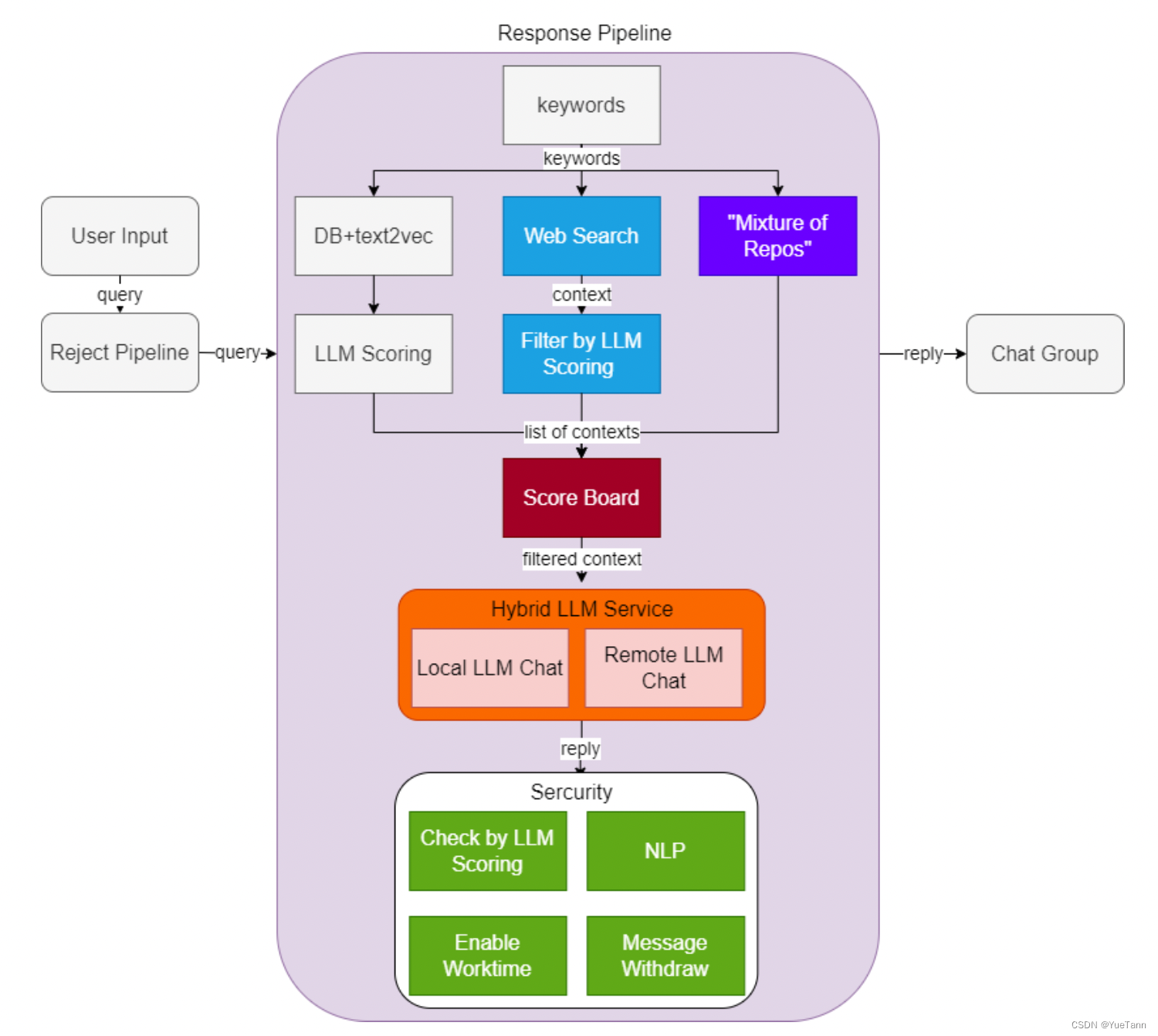
原版
- prompt控制节奏,实现类似关键词检索、主题、信息抽取等功能
- 注意这里根据llm返回的topic (prompt: 告诉我这句话的主题,直接说主题不要解释)进行召回检索(CacheRetriever), 并再次让大模型判断query与返回的检索的相关程度. 如果本地检索无相关程度高的,则进行网络检索(WebRetrieval)
- Retrieval上面套了一个CacheRetrieval, 同样的topic检索结果直接返回已经记录的. 对于新topic, 首先保持记录的cache在一定长度内(LRU?),之后就是检索Retrieval本身
- 查询与检索内容通过大模型生成
- llm service
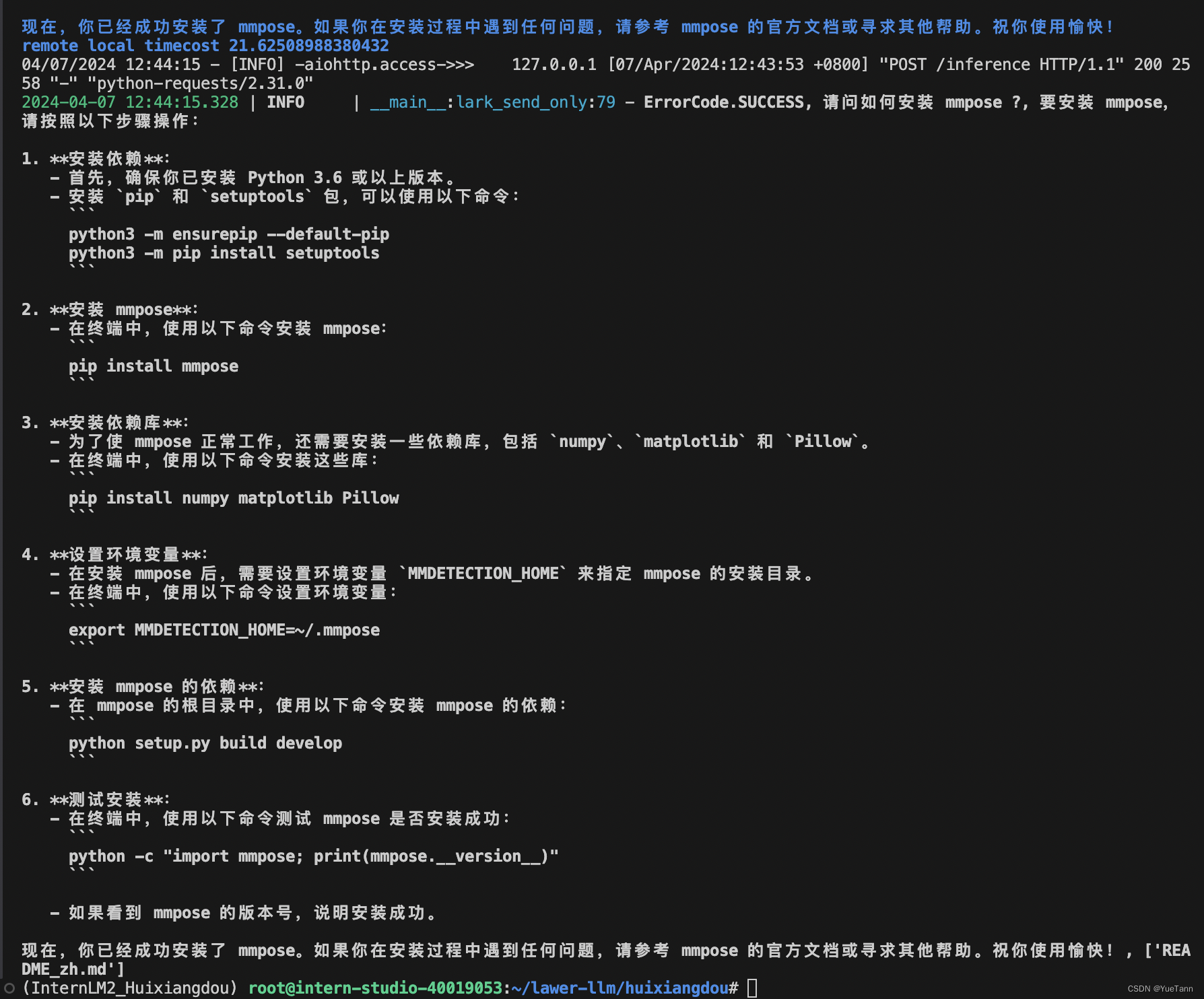
web版
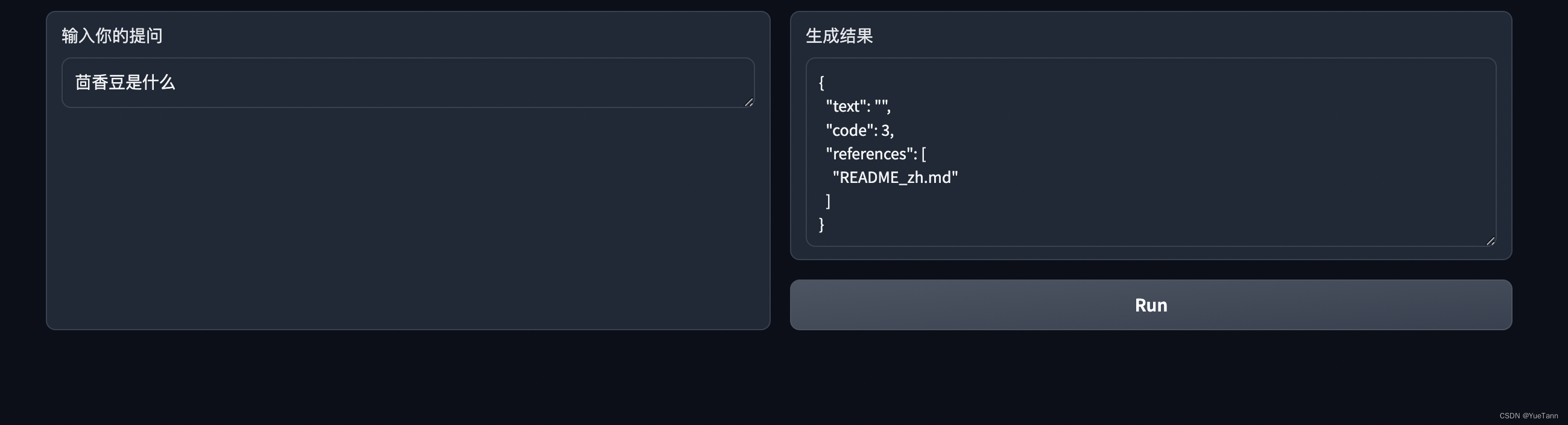
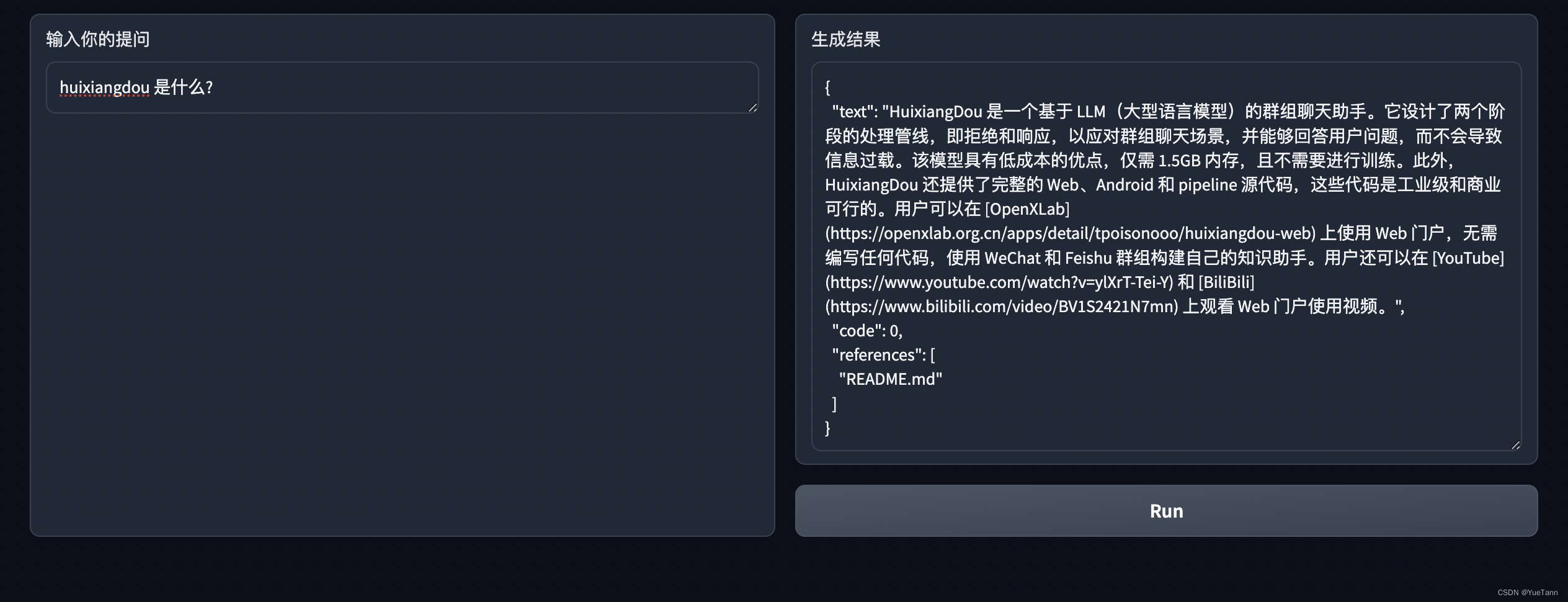
- huixiangdou拼音后有空格效果就好多了? 因为good question中的版本是有空格的
- 如何回答关于文件的知识?
- 如何进行搜索回答知识?
项目进展
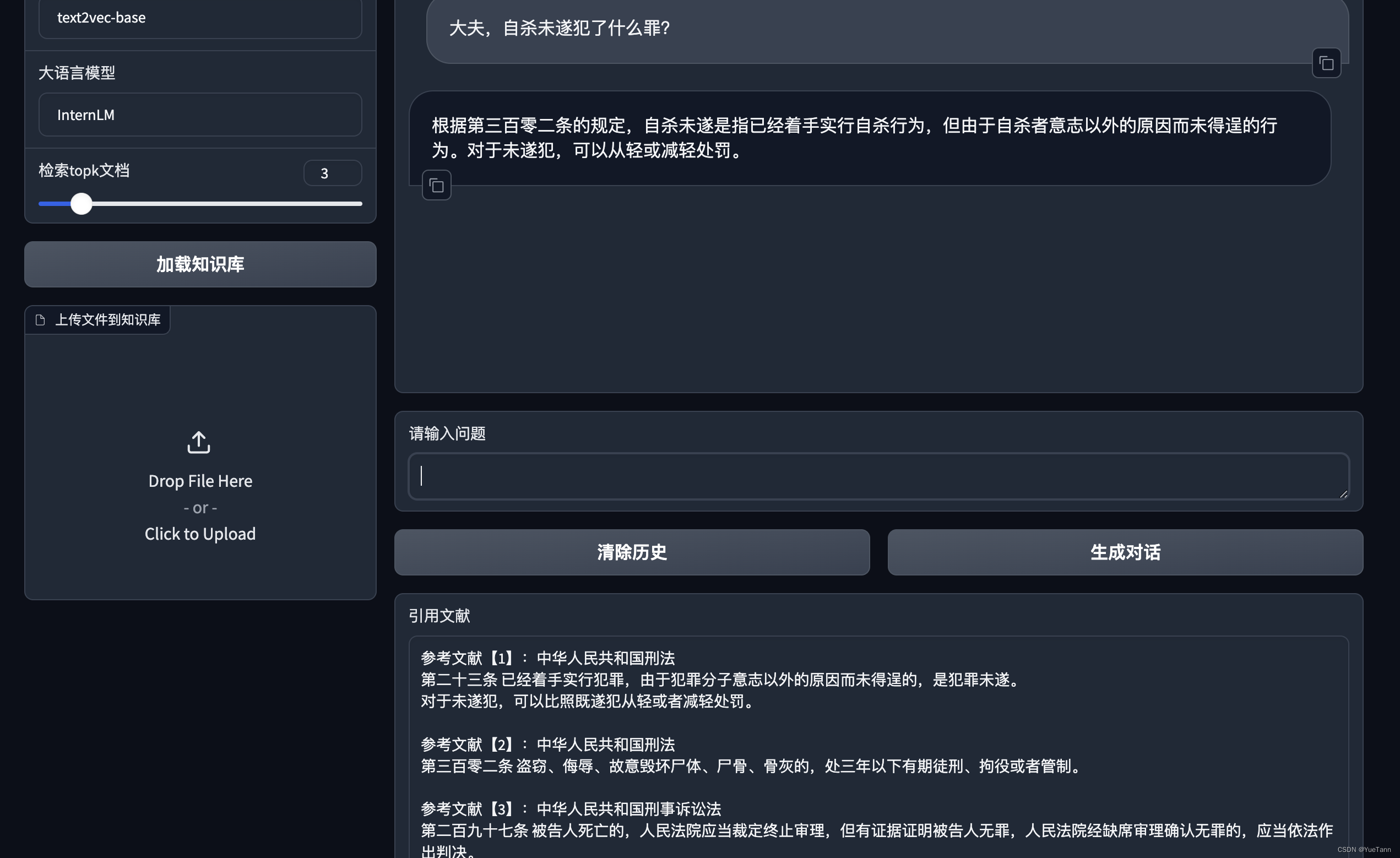
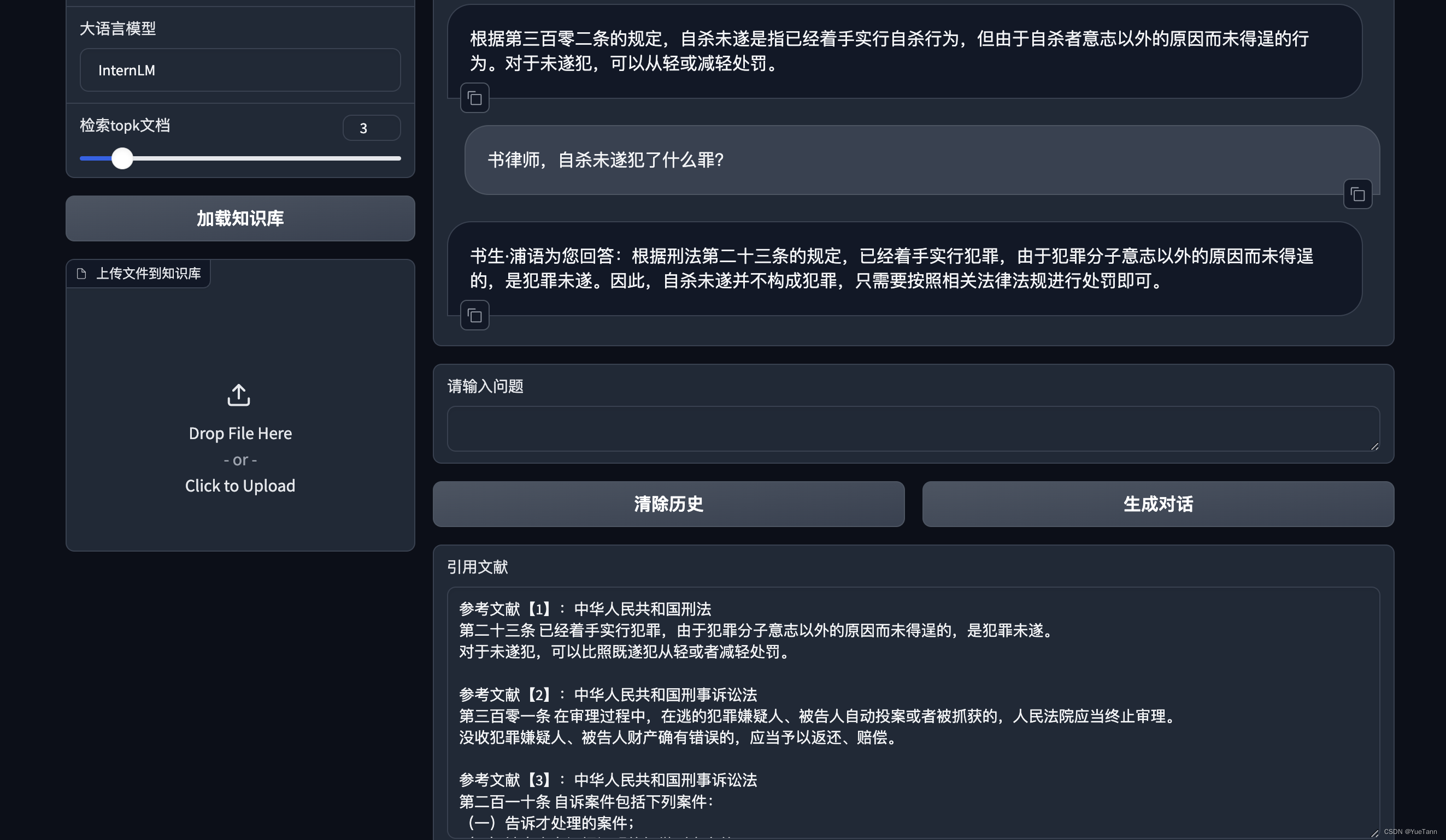
代码阅读附带基础
-
第一步就判断是否落在工作时间?第一感觉扎心,第二感觉就很有画面感了,“你们这群开发人员在阴阳怪气什么,无法无天了,别以为不知道你们在想什么,抓起来”
-
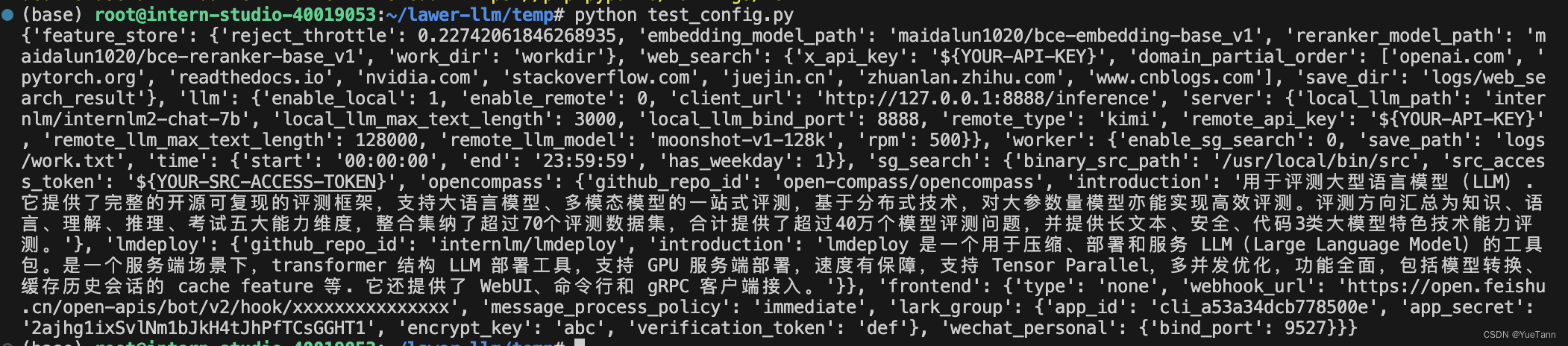
基础配置通过pytoml (新版改为tomllib)读取config.ini
-
大模型服务: 类似微服务的方式? 一个server, 一个clinet
- aiohttp倒是一个没用过的web框架
- server接受system, prompt, query返回大模型输出结果
- client调用
-
如何实现对pdf, excel, ppt的读取?
-
如何控制群聊中对话的控制? 包括多人聊,以及单人可能对话中换了topic
-
本地知识库
- 文件也作为对象更细致的进行管理, file_operation.py
- md_splitter
- text_splitter
- MarkdownHeaderTextSplitter
-
如何判断介入本地知识库搜索还是网络搜索?
Langchain