-
在本章节中,我们会探索对象中的原型
-
这是很少有人讲解的内容,我们会认识原型,理解原型的作用,并且细化原型(显式原型、隐式原型)
-
函数的原型上,有两个重要属性,prototype与constructor,他们都是做什么的?
-
[[prototype]]、prototype、__proto__都分别表示了什么?他们是一样的内容吗? -
在new操作符下,函数变成构造函数,这些原型又会发生什么变化?构造函数如何与原型进行结合?
-
在内存中,原型与构造函数之间的联系是怎么样的?
-
-
在本次章节中,我们都会进行深入学习
一、对象的原型
对象的原型是一个可以被其他对象继承属性和方法的模板。在JavaScript中,每个对象都有一个指向其原型的链接,而从原型继承来的方法和属性定义了对象的共通行为
从我的理解角度来看,对象的原型可以被看作是对象中的“万物之源”或“根本大法”,就像《易经》中描述的“太极生两仪,两仪生四象”,对象的原型是所有行为和特性的基础
1.1. 认识原型
-
JavaScript当中每个对象都有一个特殊的内置属性
[[prototype]],这个属性是一个链接,指向另一个对象(即该对象的原型),可以直接理解为这个特殊的内置属性被称为对象的原型-
而这个原型,我们一般称为
隐式原型,因为我们看不到,以后也不会去修改这个原型,甚至不会去直接使用这个原型 -
但我们会利用这个底层原理来进行使用
-
-
那么这个对象有什么用呢?
-
当我们通过
引用对象的属性key来获取一个value时,它会触发[[Get]]的操作 -
这个操作会首先检查该属性是否有对应的属性,如果有的话就使用它
-
如果对象中没有改属性,那么会访问对象
[[prototype]]内置属性指向的对象上的属性
-
表15-1 [[Get]]与[[Set]]总结
| 操作 | 描述 | 原型链的作用 |
|---|---|---|
[[Get]] |
当尝试访问对象的属性时触发。如果对象本身没有该属性,则会沿原型链向上查找,直到找到为止或到达原型链的顶端 | 如果对象自身没有指定的属性,则会通过原型链向上查找这个属性 |
[[Set]] |
当尝试设置对象的属性时触发。如果属性存在于对象上且属性是可写的,就直接设置。如果对象上不存在该属性,会根据原型链和属性的writable状态确定是否在对象上创建新属性 | 如果对象自身没有这个属性,且原型链上有这个属性且属性是只读的,则不会在对象上创建并设置该属性。如果原型链上的属性是可写的,或原型链上没有该属性,则可以在对象上创建新属性 |
function A() {}
A.prototype.x = 10;
var obj = new A();
console.log(obj.x); // 10,通过[[Get]]操作,沿原型找到x
obj.x = 20; // 设置x,通过[[Set]]操作,obj现在有自己的x
console.log(obj.x); // 20,直接从obj自身获取
-
那么如果通过字面量直接创建一个对象,这个对象也会有这样的属性吗?如果有,应该如何获取这个属性呢?
-
答案是有的,只要是对象都会有这样的一个内置属性,不管我们对象里有没有内容,都是一样的
-
-
获取的方式有两种:
-
方式一:通过对象的
__proto__属性可以获取到原型对象(但是这个是早期浏览器自己添加的,存在一定的兼容性问题) -
方式二:通过
Object.getPrototypeOf方法可以获取到
-
var obj = {name:"XiaoYu"}
var foo = {}
console.log(obj.__proto__);
console.log(foo.__proto__);

-
通过在Node环境下的打印,我们可以认为说刚才的对象相当于:
var obj = {name:"XiaoYu",__proto__:{}}
var foo = {__proto__:{}}
-
并且通过了对比,浏览器控制台和Node环境下是有很大的区别的,浏览器控制台做出了特殊处理,所以
__proto__存在了很多属性-
我们在正式使用的时候,是没办法去使用
__proto__,因为它并不是ECMAScript 标准中定义的方法,是非标准的,但我们可以通过ES5以后的语法Object.getPrototypeOf方法来获取,从而实现类似的效果 -
在编程语境中,“Of”常用于强调一个函数或方法是对特定对象或数据进行操作。这里的“Of”字面意义上可以理解为“属于”
-
而在这里就可以进行一个直译:获取属于xxx的原型类型,当然,我们可以理解为这里的原型类型就是我们所说的原型对象
-
-
在开发调试中,我们会用
obj.__proto__来测试会方便一点,在正式使用中,则需要使用Object.getPrototypeOf(obj)-
但不管通过哪一种方式,结果其实都一样,在Node环境,该是空对象还是空对象。控制台之所以有这些属性是因为浏览器的特殊处理,不会因我们使用getPrototypeOf而发生改变
-
而我们之所以不提倡使用非标准特性,在于它没有被保证,当下可以使用,但未来可就不一定了(可能被弃用)。程序稳定性的优先度是非常高了,所有非标准特性都应该是我们应该避免的,而并非只有
__proto__一个。使用标准方法可以确保代码的长期兼容性 -
而且非标准的特性,不同的JavaScript引擎可能会有不同的实现方式,这可能影响性能和行为的一致性。这在后续维护的话,会很实在的添加心智负担,以前最突出的就是IE,几乎每一份代码都需要专门为IE单独适配,那是一段令开发者非常难受的时间,但至少现在IE是淘汰了,我们可以不再去顾虑它了
-
//通常情况下我们是不能使用__proto__这个原型的,如果真的想要获取这个对象的话,有提供另一个办法供我们获取
var obj = {name:"小余"}
//获取obj的原型,是ES5之后提供的方法,不是浏览器提供的
console.log(Object.getPrototypeOf(obj));//node打印出来的结果:[Object: null prototype] {}
-
最后我需要说,
__proto__并不是[[prototype]],因为[[prototype]]是ECMAScript规范的一部分,而__proto__不是-
Object.getPrototypeOf() 获取到的才是
[[prototype]],因为这个方法是ECMAScript 5标准的一部分,并且在所有现代浏览器中都得到了支持
-
1.2. 原型有什么用?
-
当我们从一个对象中获取某一个属性时,它会触发[[get]]操作
-
第一步:在当前对象进行
[[get]]操作,也是我们所说的查找属性,然后调用属性 -
一旦第一步没有查找到属性,就会进入第二步:在这个过程中还会涉及到原型链的概念,但我们目前对原型还没理解,原型链的部分则暂时跳过
-
var obj = {name:"小余"}
console.log(obj.age)//像这样取值的时候就会触发get操作,操作分2步
//1.在当前对象中去查找对应的属性,如果找到就直接使用
//2.如果没有找到,会沿着原型去查找,也就是var obj = {name:"小余",__proto__:{}},先从前面开始找,没找到再从__proto__(原型)找
-
虽然第二步我们暂时跳过,但可以看一下这个效果
-
obj对象本身是没有name属性的,所以会进入第二步骤,查找对应的
__proto__身上的属性上
-
//我们在上面是找不到obj的age属性的,因为我们都没有定义age这个属性,age除了obj.age = 18这种方式之外,还可以直接赋值在原型中,也能够找到,这就是顺着原型去查找的
var obj = {name:"小余"}
obj.__proto__.age = 18
console.log(obj.age)//18
//为什么要这么麻烦,要放到原型中,不直接放到对象里面呢?这是为了方便我们后续实现继承
1.3. 函数的原型prototype
-
那么上面的东西对于我们的构造函数创建对象来说有什么用呢?我们不知道
-
它的意义是非常重大的,接下来我们继续来探讨,prototype和[[prototype]]是两个不同的概念,我们在之前有专门讲解过
[[]]所具备的含义
-
-
这里我们引入一个新的概念:所有的函数都有一个prototype的属性:
-
这个
prototype属性被称为显示原型属性,和隐式原型[[prototype]]有点区别
-
function foo(){
}
函数作为对象来说,它也是有[[prototype]]隐式原型的
console.log(foo.__proto__)//{}
//函数因为它是一个函数,所以还会多出来一个显示原型属性,叫做prototype
console.log(foo.prototype)//{},这个属性是没有兼容性问题的,ECMA一开始就定义了这个属性
-
我们可能会问题,是不是因为函数是一个对象,所以它有prototype的属性呢?
-
不是的,因为它是一个函数,才有了这个特殊的属性
-
而不是它是一个对象,所以有这个特殊的属性,对象是没有这个特殊属性的
-
var obj = {}
console.log(obj.prototype)//obj就没有这个属性,undefined
-
理解
prototype(显示原型)和[[Prototype]](隐式原型)之间的区别是掌握JavaScript原型链和继承机制的关键。这两个概念经常让初学者混淆,但它们在JavaScript对象模型中扮演着非常不同的角色-
在本章节中,我们已经大致了解两种原型都是什么情况了,但为了后面学习原型链的理解难度不会太过陡峭,我们还需要要清楚这两者的区别
-
归属不同:
prototype是函数对象(特别是构造函数)特有的属性;而[[Prototype]]是所有对象都有的内部属性。我们说过的,函数也是一种对象,所以函数也会具备所有对象都有的[[prototype]] -
功能不同:构造函数的
prototype属性定义了通过这个构造函数创建的所有对象实例的原型,从而实现属性和方法的继承;对象的[[Prototype]]属性指向其原型对象,是对象实际的原型链的一部分,用于实现基于原型的属性查找或继承 -
设置方式:
prototype是在定义构造函数时附带的,通常可以直接修改;[[Prototype]]通常在对象创建时由解释器自动设置,可以通过Object.setPrototypeOf()、Object.create()或使用__proto__(非标准,不推荐)修改
-
-
显示原型是基于原型的继承的主要方式
1.4. 再看new操作符
我们前面讲过new关键字的步骤如下:
-
在内存中创建一个新的对象(空对象)
-
这个对象内部的[[prototype]]属性会被赋值为该构造函数的prototype属性(后面详细讲)
-
在函数中,我们的隐式原型会指向与显式原型。我们有说过,显式原型是函数特有的,而隐式原型则是所有对象都有
-
在上面我特地说了,函数会同时拥有显式和隐式原型,那你看,这个显式隐式都有,我要听谁的?难道跟我们学习this指向一样,去用优先度判断吗?
//代码的内部实现如下
function foo(){
var moni = {}
this = {}
this.__proto__ = foo.prototype//隐式原型指向显示原型
}
-
那这次就不是优先度判断了,而是隐式原型会直接指向于函数特有的显式原型,那显式和隐式不就一样了吗?JS官方为什么要这样做?如果作用一样的话,那何必折腾出一个显式原型出来?
-
通过我们下方的
全等对比案例中可以看出,他们不仅值一样,连引用的位置都是分毫不差的 -
坦白的说,在这里,显式隐式的概念变得模糊,很容易混淆,我们很难去想到JS官方为什么要这么做。这是因为我们缺少了一点重要的内容
继承机制还没学,所以这里是想不到的,不要纠结在这里,隐式指向与显式就是来自继承机制,知识在很多时候并不是线性的 -
但有一点可以现在就掌握,不管原型是隐式还是显式的,它们都是桥梁的作用,是
构造函数和其创建的对象之间的桥梁
-
function foo(){
}
var f1 = new foo()
var f2 = new foo()
//这就是构造函数的f1跟f2的隐式原型会指向函数的显示原型
console.log(f1.__proto__ === foo.prototype);//true
console.log(f2.__proto__ === foo.prototype);//true
-
现在对这个概念感觉稍微无法串联起来,感觉这个原型与原型之间好像有一条道路桥梁进行连接起来,这个桥梁可以是显式隐式原型,但更准确的说法是
继承机制,继承机制真正把它们联系在了一起,这个整体就是原型链-
但不用担心,把疑惑暂时藏在心里,在后续的原型链章节中,我们会一步步的揭开,有时候答案并不在当下而在未来
-
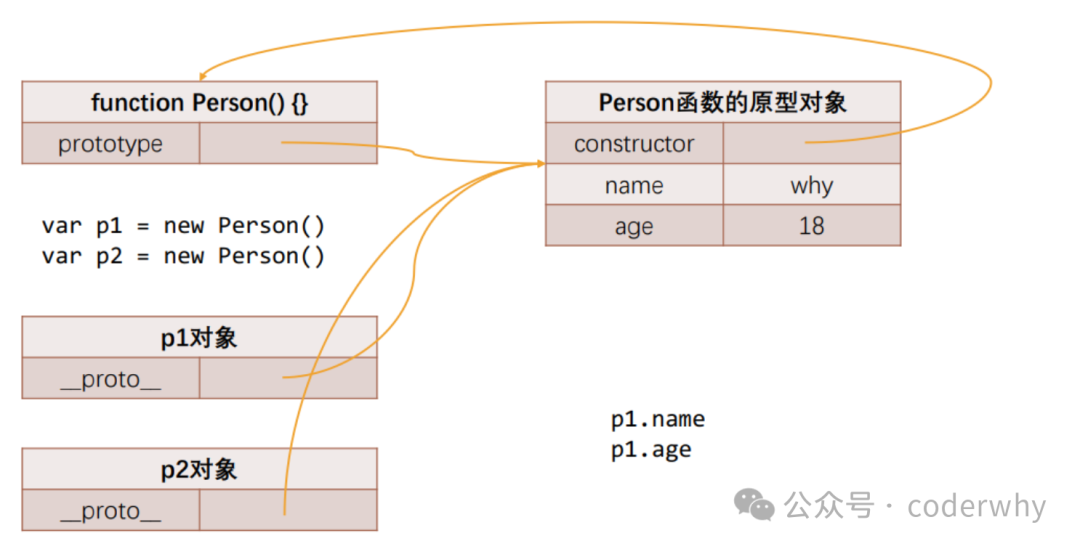
二、Person构造函数原型内存图
-
函数的内存图,我们在学习作用域链的时候已经画过很多了
-
接下来,我们要继续在函数的内存中,继续补充新的内容了
-
function Person(){
}
console.log(Person.prototype);
-
Person函数本身也是存在隐式原型的,而隐式原型指向于显式原型
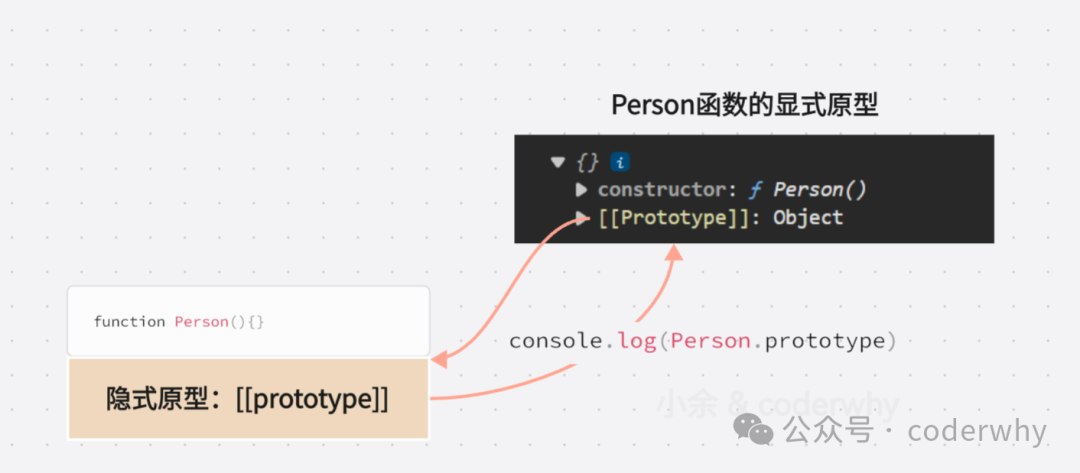
-
我们通过打印Person函数中的显式原型prototype,能够看到在显式原型中,存在着隐式原型[[prototype]]
-
所以这其实是一个相互指向的过程,先有隐式原型指向于显式原型,并且大家尝试点开的话,会发现显式原型与隐式原型结果相同,形成闭环,如图15-2
-
为什么会形成这种原因,我们在下面学到constructor的时候,打开就能够揭晓原因
-
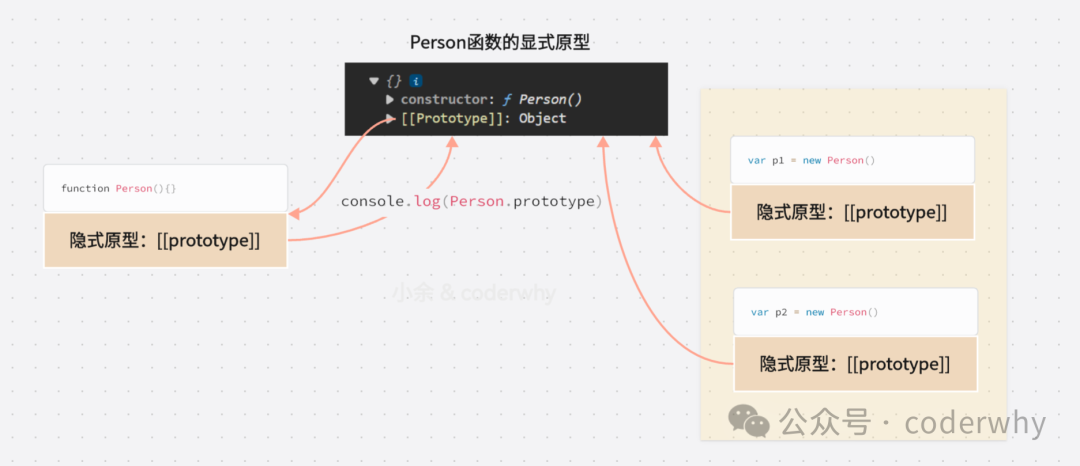
function Person(){
}
var p1 = new Person()
var p2 = new Person()
-
Person函数是存在于堆内存当中的,而p1与p2也是一样的,因为通过new创建出来的也是对象,对象自然是在堆内存当中的,并且这些内容都位于GO,也就是全局当中
-
由于在这里没有区别,所以GO和堆内存所对应的图形,我们就进行一个省略
-
p1与p2作为对象,是没有显式原型的,也就是只有
__proto__,更精准的说,只有[[prototype]] -
我们上面说明new操作符的
第二步骤时,说明此对象的隐式原型[[prototype]]会指向于该构造函数的prototype属性。而该构造函数就是Person函数
-
-
因此,只要指向于同一处地方的操作,不管表面如何迷惑我们,它的核心逻辑都是没有变化的,内存表达如图15-3
-
内存地址都是一样的,行为验证表达如图15-4
-
console.log(p1.__proto__ === p2.__proto__);
//函数的执行体创建p1的对象,还有p2的对象,这个是我们一开始就通过var p1 = new Person()还有var p2 = new Person()达成的,这个对象`new Person`是构造函数,前面我们已经学习过了,然后他们身上是有隐式原型__proto__的,而隐式原型是会指向Person函数的原型对象的显示原型prototype。总结就是p1跟p2指向了构造函数,构造函数的隐式原型指向了函数的显示原型。这也就造就了下面两个true相等的原因
console.log(p1.__proto__ === Person.prototype);//true
console.log(p2.__proto__ === Person.prototype);//true
//假设地址是0x100,那上面三个操作全都是0x100 === 0x100
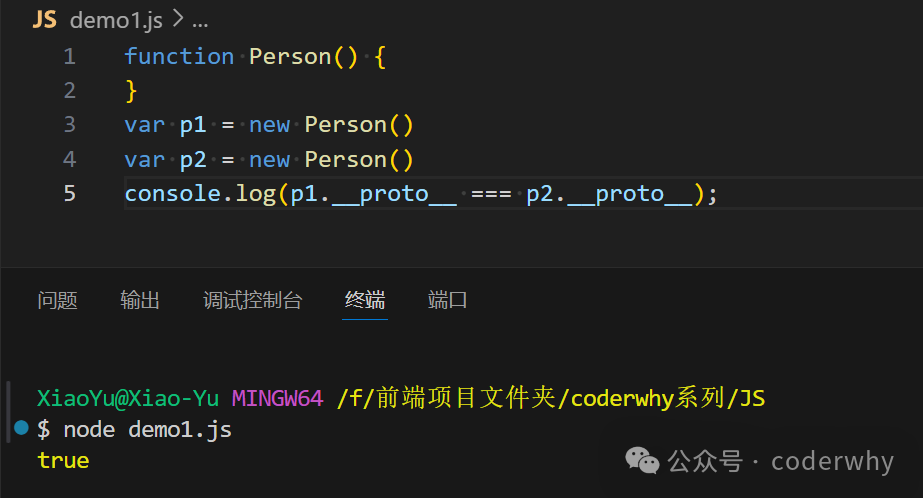
-
最后,我们放出简化的内存指向图,从结构的角度来看,应该会更加清晰一些
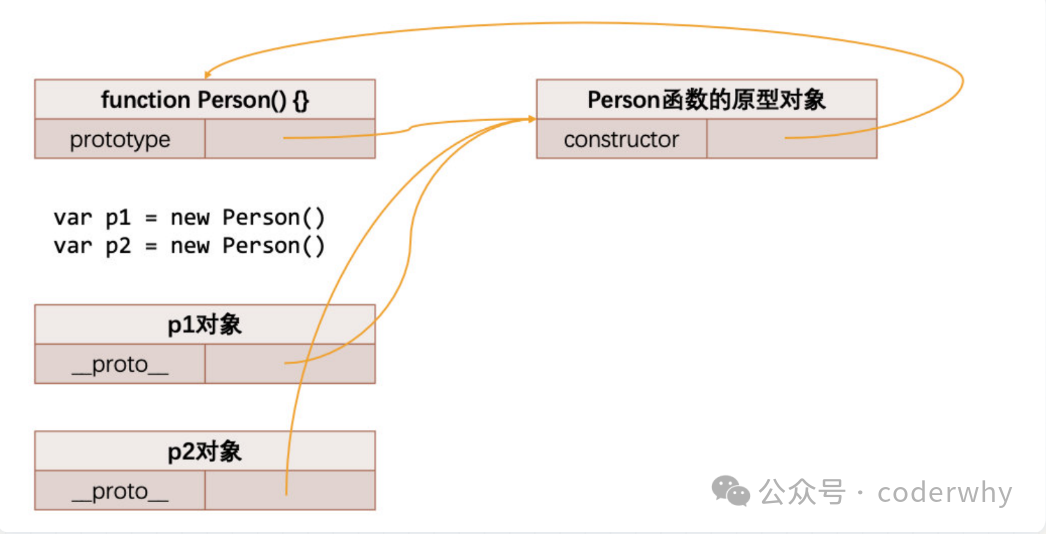
-
这里的指向,跟之前学习作用域链是有点类似的,指向的依旧是以内存地址的形式进度表达,如图15-5
-
2.1. 赋值为新的对象
-
我们前面有简要讲解了一下内容的查找规则,找到则调用,找不到则沿着原型继续查找
-
现在我们要做一件事情:如果我p1里没有name这个属性,我有几种方法可以通过
p1.name获取到name内容。这是一道考验我们对原型理解的面试题-
一共有三种,一种是我们之前尝试过的事情,把name放到p1的隐式原型去
-
但在这里,我要说明另外两种方式:
-
name放到Person的显式原型中,考察了我们是否知道new操作符的第二步骤
-
name放到p2的隐式原型去
-
-
啊哈,这其实就像变戏法一样,我想聪明的大家一定发现了规律。由于内存指向都是一样的地方,导致说,这道题的核心在于,我们能够找到几条通往构造函数的显式原型的路
function Person(){
}
var p1 = new Person()
var p2 = new Person()
//想要取到对象中没有的属性的办法:可以在原型中直接加上去,那在p1中找不到就会去原型上找,然后就可以找到了
p1.__proto__.name = "小余"
console.log(p1.name);//小余
//但其实还有更好的办法,我们可以直接放在函数Person的显示原型里面,然后按照顺序,p1里面找不到就去p1自己的隐式原型__proto__找,如果也找不到就会继续往上追溯到Person的显式原型prototype中找,那这回可算找到了
Person.prototype.name = "XiaoYu"
console.log(p1.name);//XiaoYu
//如果我们对p2的隐式原型进行修改,一样会作用到p1身上,这是为什么?
//规范回答:new操作符导致的:这个对象内部的[[prototype]]属性会被赋值为该构造函数的prototype属性;那么也就意味着我们通过Person构造函数创建出来的所有对象的[[prototype]]属性都指向Person.prototype
//理解回答:因为p2的隐式原型会指向Person的显式原型prototype,而p1最终也是会指向到Person的显式原型,所以他们会找到同一个地方,所以就会导致p2隐式原型的改动也会影响到p1隐式原型的改动,因为他们最终追溯到的都是一样的地方
p2.__proto__.name = "coderwhy"
console.log(p1.name);//coderwhy
-
所以,我要开始简化了
-
在我的眼里,可以是这样的一种情况
-
0x100 = "小余"
console.log(0x100);//小余
0x100 = "XiaoYu"
console.log(0x100);//XiaoYu
0x100 = "coderwhy"
console.log(0x100);//coderwhy
假设我们有一个内存地址 `0x100`,这个地址可以存储不同的值
- 最初,假设在地址 `0x100` 存储了值 "小余"
- 随后,我们更新了这个地址存储的值为 "XiaoYu"
- 最后,我们再次更新,将其改为 "coderwhy"
在每一个过程阶段,我都获取了一次值,所以每一次都会发生变化
-
如果大家理解了,那恭喜大家,我们已经不知不觉中,学习了Vue和React中实现响应式的部分原理
三、函数原型上的属性
在JavaScript中,函数原型(通常指的是函数的 prototype(显式原型) 属性)上的属性代表了所有通过该函数构造出的对象实例所共享的属性和方法。这些属性和方法不是存储在每个实例自身上,而是存储在实例的原型对象上,即函数的 prototype 属性所指向的对象。这种机制是JavaScript实现继承和共享方法的核心
3.1. prototype添加属性
-
在prototype添加属性这件事情,其实我们在第十章节手写显式绑定的三个函数的时候,是做过类似的事情的,只不过我们添加的是方法
-
那么属性要怎么添加,跟方法一样吗?
-
//往函数原型中添加方法
Function. prototype.xxx = function(){}
-
是的,这个添加过程是一样的,而添加在哪一层就需要根据我们的使用范围需求了
-
此时,我们又多了一个困惑点,我不知道这个使用范围,到底分了几层,可能有点迷茫
-
我们之前在手写显式绑定函数的时候,添加在Function身上,到处都能用。而此时添加在Person身上,使用范围是不是缩小了,具体缩小了多少?我不知道
-
这些困惑,答案都在原型链中,我们从后面的原型链文章中寻找答案
-
-
在这里,我们修改prototype是更合适的,从名字上就更能够说明,
显式在这里有主动的含义-
虽然
__proto__不能完全表示[[prototype]],但就表达上,其实是一个意思的 -
我们说过,通过
[[]]所划定起来的内容,都是偏向于底层的,最好是不要去动 -
而且修改
prototype本就是原型继承的设计初衷,它鼓励我们在定义阶段就设定好所有实例共享的属性和方法。而动态修改[[Prototype]]则被视为一种“hack”手段,应当避免,除非在特殊情况下必须这样做 -
通过修改构造函数的
prototype属性来设置原型,就是在创建对象(实例)之前完成的(定义阶段),不会影响已存在的实例
-
function Person() {
}
//我把属性加入Person显式原型中
Person.prototype.name = "why"
Person.prototype.age = 18
var p1 = new Person()
var p2 = new Person()
console.log(p1.name,p2.age);
3.2. constructor属性
-
事实上原型对象上面是有一个属性的:constructor,被称为构造器
-
默认情况下原型上都会添加一个属性叫做constructor,这个constructor指向创建实例对象的构造函数。在我们看构造函数内存图的时候,就已经观察到了这一点
-
而这个属性在原型继承中扮演着重要的角色,因为它保持了原型链上各级对象与其构造函数之间的联系
-
-
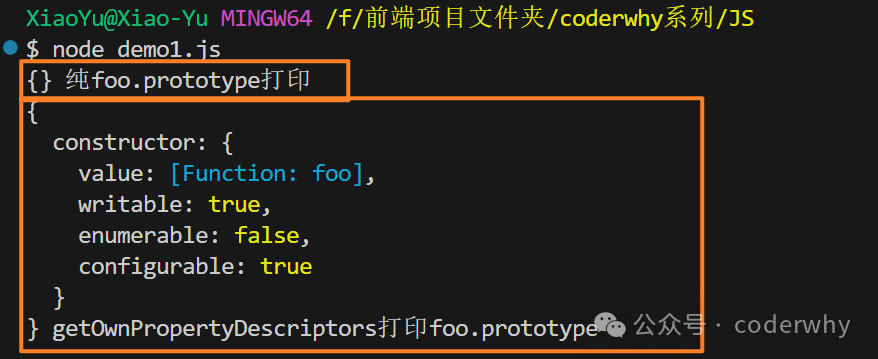
constructor在以往进行打印的时候,内在是空的,但其实并不是的
-
默认是存在属性描述符的,只是被设置了不可枚举,导致我们看不到
-
通过getOwnPropertyDescriptors可以看到内在属性,如图15-7
-
function foo(){
}
console.log(foo.prototype,"纯foo.prototype打印")//打印出来是个空对象{},但是事实上该对象并不是空的,只是因为可枚举属性被设置为了false
console.log(Object.getOwnPropertyDescriptors(foo.prototype),"getOwnPropertyDescriptors打印foo.prototype");
-
constructor属性是被ECMA要求必须添加的,不存在兼容性的问题,那ECMA为什么要这么做呢?
-
主要原因是为了维护构造函数与其创建的对象之间的显式关联
-
我想大家通过上面图片中可以看到,枚举出来的不止是属性描述符,还有一个value是我们的foo函数,就是通过这个value还实现的构造函数和其创建对象的显示关联
-
而这也是为什么会形成显式、隐式原型闭环的原因,从new创建出来的对象:隐式原型指向于显式原型,而显式原型内的constructor的value居然又是一个foo构造函数
而我们知道构造函数同时具备隐式原型和显式原型,在这里就形成闭环。实际上,这是一个设计决策,确保原型链的完整性和可追溯性
-
//我们知道是事实上这个并不是空的,只是因为可枚举属性被设置为了false,那就可以采取另一种方式,将他的枚举属性设置为true,那就可以看到了
function foo(){
}
Object.defineProperty(foo.prototype,"constructor",{
enumerable:true,
configurable:true,
writable:true,
value:"小余"
})
console.log(foo.prototype.constructor);//能够打印出来constructor属性了
//但如果将上面defineProperty给注释掉的话,foo.prototype.constructor就会打印出另一个结果:[Function: foo]
//prototype.constructor = 构造函数本身,也就是foo函数
-
我们来验证一下这句话:prototype.constructor = 构造函数本身,也就是foo函数
function foo(){
}
console.log(foo.prototype.constructor.name);//foo
//我们知道构造函数本身都是有名字的,通过在foo.prototype.constructor,也就是构造函数本身的基础上,打印了name,果然出来了foo这个名字
-
所以来个总结:
-
在原本各种指向的基础上,在我们追溯到显式函数身上,也就是上面原型图中的Person的原型对象prototype之后,由Person原型对象身上的constructor又指回了foo这个构造函数本身。这样就形成了一个完美的循环
-
所谓的“无限嵌套”实际上是原型链结构的一个自然表现,它确保了从任何一个对象都能追溯到其构造函数,但这种追溯最终会在原型链的顶端停止
-
这种思想的表达形式是非常精妙的,就像是早已注定的命运,不管如何选择
-
//我们知道这里形成了循环后,我们甚至能做出来一些骚操作
function foo(){
}
//闭环
console.log(foo.prototype.constructor.prototype.constructor.prototype.constructor.name) //foo
//我们让他们两者之间不断的互相循环,最终又回到的构造函数本身,然后取出来了构造函数的名字
四、重写原型对象
这个互相引用是会回收的,因为JS的垃圾回收机制是
标记清除,是从根节点开始看有没有引用的
重写原型对象指的是将一个构造函数的
prototype属性设置为一个新的对象,而不是向现有的prototype对象添加或修改属性。这种做法通常用于重新定义整个原型链,或者在实现继承时完全替换一个类的行为和属性
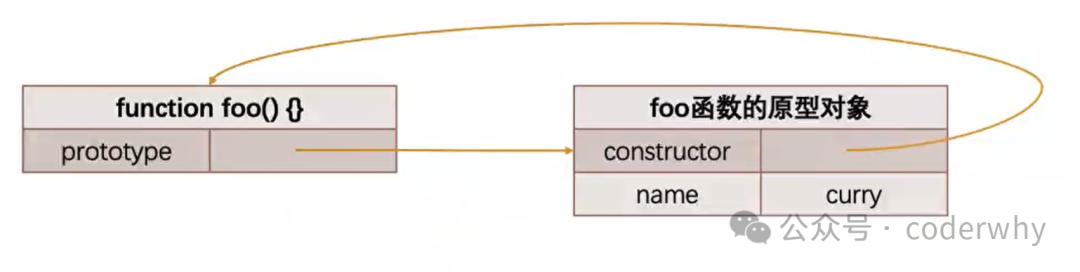
当我们使用重写原型方法之后,也就是在内存里又创建了一个对象,内存图如下(代码在下面的代码块中):
-
foo函数不再指向它的原型对象了,而是指向新的对象了,刚指向的时候,这个新对象连constructor都没有
-
指向新对象之后,foo函数的原型对象就会被销毁掉,因为我们js的垃圾回收机制是采用标记清除法(详细的内容往回翻)
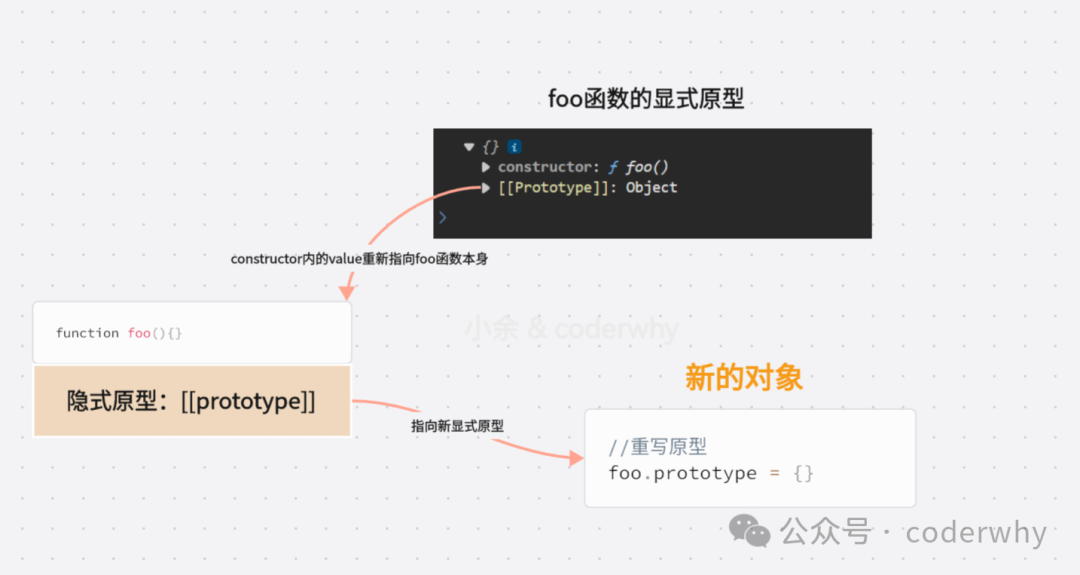
-
而当我们填入内容之后,就可以访问到其内容,如图15-10

-
如果我们需要在原型上添加过多的属性,通常我们会重新整个原型对象:
-
这样,整体的结构性也会更强,更紧密
-
//没有重写之前
Person.prototype.name = "小余"
Person.prototype.age = 20
Person.prototype.learn = function(){
console.log(this.name+"在学习");
}
function Person(){
}
//重写之后:修改之后是不是简洁很多,去掉了很多重复的元素了
Person.prototype = {//这种对象形式的写法意味着直接在内存里创建了一个新的对象
name:"小余",
age:20,
learn:function(){
console.log(this.name+"在学习");
}
}
前面我们说过, 每创建一个函数, 就会同时创建它的prototype对象, 这个对象也会自动获取constructor属性;
-
而我们这里相当于给prototype重新赋值了一个对象, 那么这个新对象的constructor属性, 会指向Object构造函数, 而不是Person构造函数了
-
这是因为当我们通过赋值一个新对象给
Person.prototype时,这个新对象是普通的对象字面量,并不自动包含constructor属性。因此,该属性需要显式定义,否则它会继承自Object.prototype(默认情况),也就是Person.prototype.constructor实际上指向了Object,而不是Person的原因,如图15-11
function Person(){
}
Person.prototype = {
name:"小余",
age:18,
height:1.88
}
//注意多出来的这两个步骤
var f1 = new Person()
console.log(f1.name+"今年"+f1.age);//小余今年18,这里能够打印出来,但是最终指向的地方已经变成新的对象了(原因是因为我们重写了原型对象,通俗的说就是我们在prototype不再一个个等于慢慢写,而是直接使用对象的形式,省去了重复的Person.prototype.xxx = xx,这样的效果就刚刚上面说的一样,相当于在内存中创建了新的对象,构造函数Person的指向也就跟着发生了变化),不再是Person的显式原型了

-
这时候问题就来了,那原来的就这么不要了吗?根据上面的图,我们如果想抛弃原来的那个显式原型的话,是不是还缺少了点什么?

-
缺少了constructor啦,就是构造函数的标志,我们的
新显式原型还没有constructor指向回foo函数形成闭环 -
所以我们只要给新对象加上constructor指回foo对象就完工了,原配显式原型就被完整替代了,如图15-12
-
-
接下来,就通过代码来实现这一点操作
-
通过之前所学的
defineProperty方法即可实现
-
function foo(){
}
foo.prototype = {
//constructor:Person,//注意这里,这里是我们添加上来的,但是跟原版仍然有点区别,那就是原版的enumerable是为false的,而这样添加的enumerable为true,也就是可枚举的。所以真实开发中我们一般不这么添加,真实开发的添加方法我放在下面了,也就是我们刚刚所学的方式,能够解决我们通过目前这种方式添加时enumerable为true的问题
name:"小余",
age:18,
height:1.88
}
var f1 = new foo()
//真实开发中我们通过Object.defineProperty方式添加constructor
Object.defineProperty(foo.prototype,"constructor",{
enumerable:false,
writable:true,
configurable:true,
value:foo
})
console.log(f1.name+"今年"+f1.age);
五、创建对象 – 构造函数和原型组合
我们在这里的构造函数的方式创建对象时,有一个弊端:会创建出重复的函数,如果我们使用的属性和参数都是一样的,我们应该怎么做?在之前我们已经掌握了工厂模式和构造函数两种方式了
-
那么有没有办法让所有的对象去共享这些函数数据呢?
-
我们如果将这些函数数据放到Person.prototype的对象上可以吗?
//错误写法
function Person(name,age,sex,address){
Person.prototype.name = name,
Person.prototype.age = age,
Person.prototype.sex = sex,
Person.prototype.address = address
}
var p1 = new Person("小余",18,"男","福建")
console.log(p1.name);//小余
var p2 = new Person("coderwhy",35,"男","广州")
console.log(p1.name);//coderwhy
//没错,这是错误写法,不能够这么写,因为我们在Person其实会创建一个空对象,然后绑定在this身上调用返回(内部实现,看不到的),我们往p1,p2传入数据,第一时间肯定是先去p1跟p2各自的身上找,但很显然,我们在Person里面的代码,是直接放到他的显式原型上面了,而Person本身就什么都没有,所有当p1的数据放到显式原型上后,p2的数据紧随其后跟着放上去了,就会直接在显式原型中直接覆盖掉p1的数据。当我们使用p1.name的时候,本身找不到,紧接着去隐式原型中找,没找到,再去显式原型中找,这次找到了,但是找到的是被p2覆盖掉的数据,所有当我们p1.name拿出来的时候就会是p2的name数据
-
那样做显然是不行的,正确的写法应该数据绑定通过this来去进行判定,而共通的函数则放到原型之中
-
因为数据原型是大家一起共享的,可谓是牵一发而动全身,一不小心就会覆盖掉之前的内容,弊端和var声明变量是一样的
-
这样内容就会通过this的new绑定,捆绑到对应的p1与p2当中了
-
而将方法定义在
Person.prototype上,而不是this身上,所有通过Person构造函数创建的实例都可以访问这些方法,而不需要在每个对象上创建这些方法的副本。这不仅节省了内存,也保证了方法的一致性,也不存在像数据一样的覆盖问题
-
//正确写法
function Person(name,age,sex,address){
this.name = name,
this.age = age,
this.sex = sex,
this.address = address
// this.eating = function(){
// console.log(this.name+"今天吃烤地瓜了");
// }
}
//由于函数如果放在Person里面,那每次都会在构造函数中创建出一个新的,但是里面的内容其实都是一样的,所以最好的方式就是放在原型中,需要的时候顺着原型链找过去
Person.prototype.eating = function(){
console.log(this.name+"今天吃烤地瓜了");
}
Person.prototype.running = function(){
console.log(this.name+"今天跑了五公里");
}
var p1 = new Person("小余",18,"男","福建")
var p2 = new Person("coderwhy",35,"男","广州")
console.log(p1.name);//小余 不会发生覆盖的问题了
-
并且,我们的函数原型并不写在函数Person的内部,这是因为:
-
每次当
new Person()被调用时,Person.prototype.eating方法如果在内部的话,就都会被重新赋值。意味着即使这个方法在所有实例中是共享的,每创建一个新的Person实例,方法也会被重新设置一次。这是不必要的性能开销,因同一个函数被重复创建和赋值 -
通常,原型上的方法应该是稳定的,不需要在每次创建实例时都进行修改或重新赋值。将原型的赋值放在构造函数内部,违反了这一原则
-