摘要
这篇论文介绍了一种用于语义分割的自监督预训练方法,名为LOCA(Location-Aware Self-Supervised Transformers)。该方法旨在通过结合位置感知的自监督学习来提升模型在语义分割任务上的表现。由于像素级标注的获取成本高昂,预训练成为了提高模型性能的关键步骤。然而,现有的预训练算法主要使用图像级目标,这些目标并不涉及空间信息,这在需要空间推理的下游任务中可能是次优的。LOCA方法通过使用补丁级聚类和相对位置预测任务来促进密集特征的出现,实验表明,这种预训练方式能够在多样化的语义分割数据集上取得有竞争力的表现。
概述
拟解决的问题:
- 语义分割模型训练所需的空间标注获取成本高、耗时且费力。
- 现有的神经网络预训练方法主要依赖图像级目标,这些目标不包含空间信息,对于需要空间推理的任务(如语义分割)可能不是最佳选择。
创新之处:
- 提出了一种新颖的位置感知自监督预训练方法(LOCA),通过补丁级聚类和相对位置预测任务来促进模型学习对象部分及其空间排列。
- LOCA方法通过预测查询视图相对于参考视图的位置,以及通过聚类生成伪标签来训练模型,这有助于模型在没有显式空间标注的情况下学习空间推理。
- 该方法在多个语义分割基准数据集上显示出优于现有监督和非监督表示学习方法的性能。
方法
论文提出了一种新颖的自监督预训练方法LOCA,通过结合补丁级的聚类和相对位置预测任务,促使模型学习对象部分及其空间排列,以提升在语义分割等空间推理任务上的表现。LOCA利用查询-参考机制,让模型预测查询视图中的补丁相对于参考视图的位置,并通过随机掩码参考补丁特征来增加任务难度。此外,它还采用基于聚类的伪标签来准备模型进行语义分割任务。通过这种方式,LOCA能够在无需像素级标注的情况下,学习到对下游任务有用的空间感知特征。
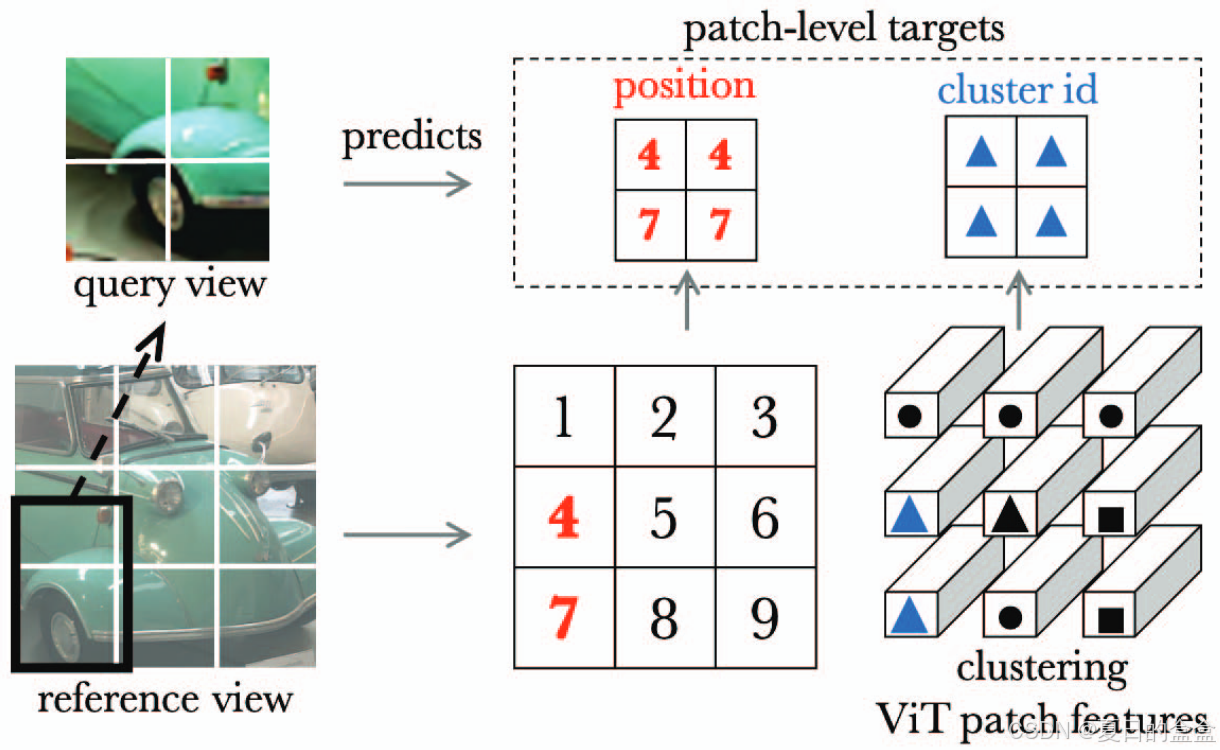
生成查询和参考视图:给定一张图像 x,通过随机数据增强(如翻转、裁剪、缩放和颜色抖动)生成参考视图 和查询视图
。查询视图和参考视图由于经过独立的增强操作,通常会有不同的图像统计特性。
将参考视图和查询视图划分为 P×P 分辨率的非重叠补丁。参考视图被展平为 (196)个补丁(256x256),查询视图被展平为
(36)个补丁。使用ViT处理这些视图,得到补丁级别的表示矩阵
和
。
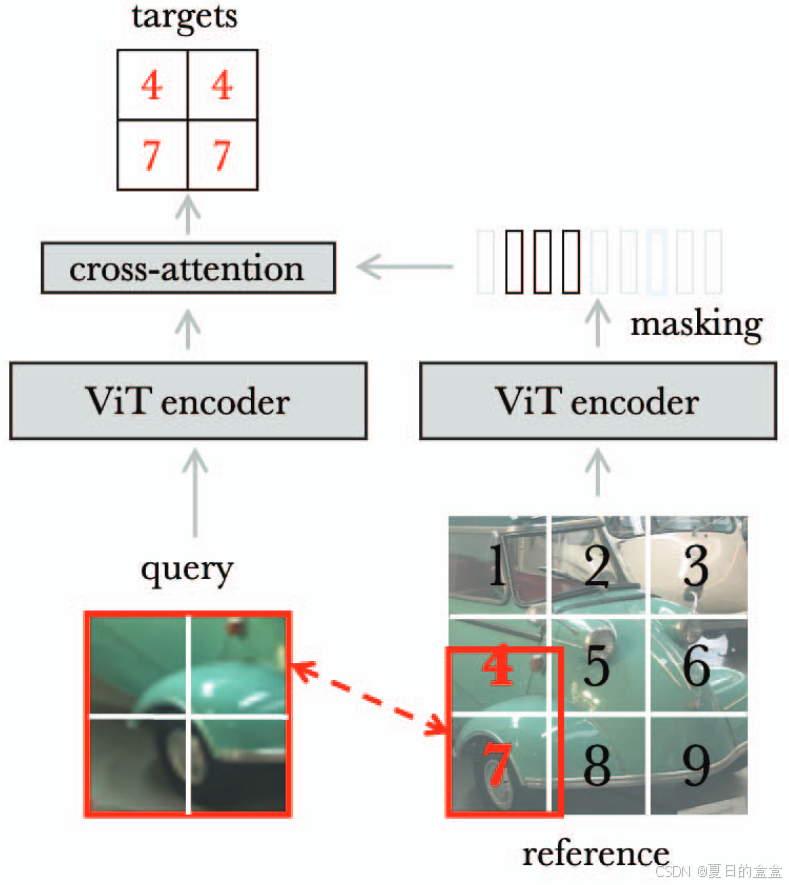
位置预测:为了鼓励网络学习不同对象部分及其空间排列,LOCA方法引入了相对补丁位置预测任务。具体来说,每个查询补丁表示需要预测其在参考视图中相应补丁的位置。这通过一个单层交叉注意力(cross-attention)变换块 g 实现,其中查询是从 计算的,而键和值是从
获得的。最终的位置分类层 W 用于预测每个查询补丁的位置。
位置损失:
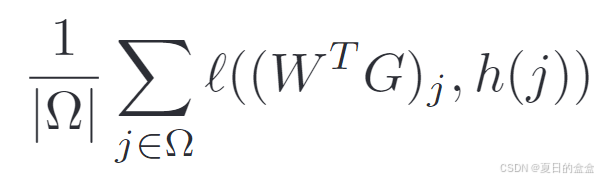
其中,Ω 是查询中与参考视图相交的补丁位置集合,ℓ 是softmax交叉熵损失,是查询表示在查看参考后的结果,h(j) 是查询补丁 j 在参考视图中的对应位置。
随机掩码:为了增加任务的难度并改善转移性能,LOCA方法通过随机掩码参考补丁特征来限制查询可以看到的参考信息。这通过在交叉注意力块 g 的输入中随机丢弃一部分参考补丁特征来实现。
![]()
其中m为随机掩码,掩码比率为 η 。
补丁级聚类:在监督设置中训练语义分割通常被转换为 K 个预定义类别上的每个补丁分类问题:
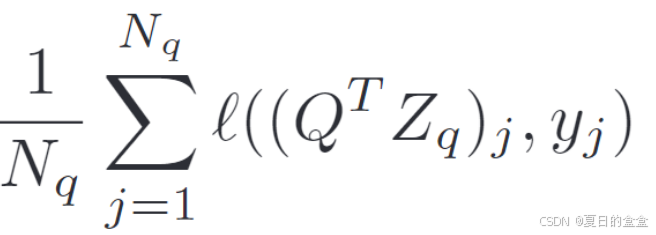
其中 Q 是可学习类别原型的矩阵,而 ℓ是 softmax 交叉熵损失。这个问题由补丁级注释监督。然而,由于我们无法访问此类注释,故LOCA方法引入了基于聚类的伪标签来准备ViT特征进行语义分割任务。通过将参考视图的补丁j表示聚类分成 K 个簇,这些簇作为伪类别。然后,根据参考视图中相应位置的补丁表示与这些聚类中心的相似度,为查询补丁生成软聚类分配(或伪标签):
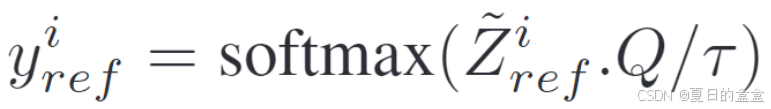
其中,用i = h(j)和τ 温度参数控制分布的锐度。请注意,正如SSL中通常做的那样,我们用一个2层多层感知器(MLP)投影了表示 和
,得到新的特征。由于我们已经用聚类伪标签取代了昂贵的每个补丁标签监督,我们可以最小化以下目标:
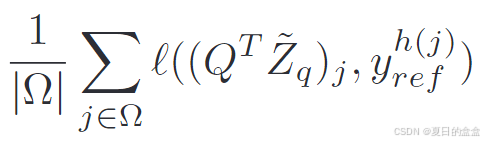
优化:LOCA通过最小化位置分类损失和聚类损失的总和来进行训练。通过反向传播更新处理查询视图的ViT、交叉注意力块、聚类原型和位置分类层的参数。
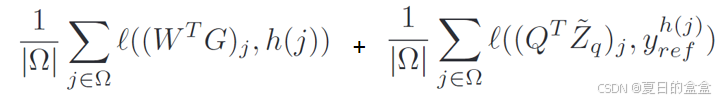
实施和评估:我们在 ImageNet 数据集上训练 LOCA,没有学习率为 0.001(余弦调度)、批量大小为 1024,权重衰减为 0.1,adamn。训练了 600 个 epoch 和 100 个 epoch 的分析。我们通过对 11 个语义分割基准的端到端微调进行评估。
结论
LOCA作为一种自监督预训练方法,能够在多个语义分割数据集上取得优异的性能。该方法证明了结合位置信息的自监督学习对于提高模型在空间推理任务上的性能是有效的。此外,LOCA在数据和模型规模上的扩展性表明,它有潜力成为大规模语义分割预训练的有力候选方法。未来的工作可能会探索将LOCA与全局图像级目标结合,以进一步提高性能。