前段时间,社区开源了一款通用 OCR 大模型 - GOT-OCR2.0,效果非常惊艳,不到一个月,HuggingFace 上,模型权重下载量高达 202K!
最近打算在项目中用到它,顺便做一个测评,分享给大家。
1. GOT-OCR2.0 简介
号称将 OCR 推进到了 2.0 时代,它到底强在哪?
GOT-OCR2.0 将大模型引入到 OCR 中,使得多样化的文本识别成为可能,包括:标准文本识别、格式化文本识别、细粒度 OCR 以及多页文档的 OCR。
总结来看,GOT模型具有以下特点:
- 模型轻量:整个模型参数量只有 580M。
- 端到端处理:模型由编码器和解码器组成。
- 输入多样性:处理包括文本、公式、表格、图表、乐谱和几何形状在内的各种光学信号。
- 输出灵活性:能够生成纯文本或格式化结果。支持 html 输出,非常适合给大模型食用。
整体模型框架: 模型训练分为三个阶段。
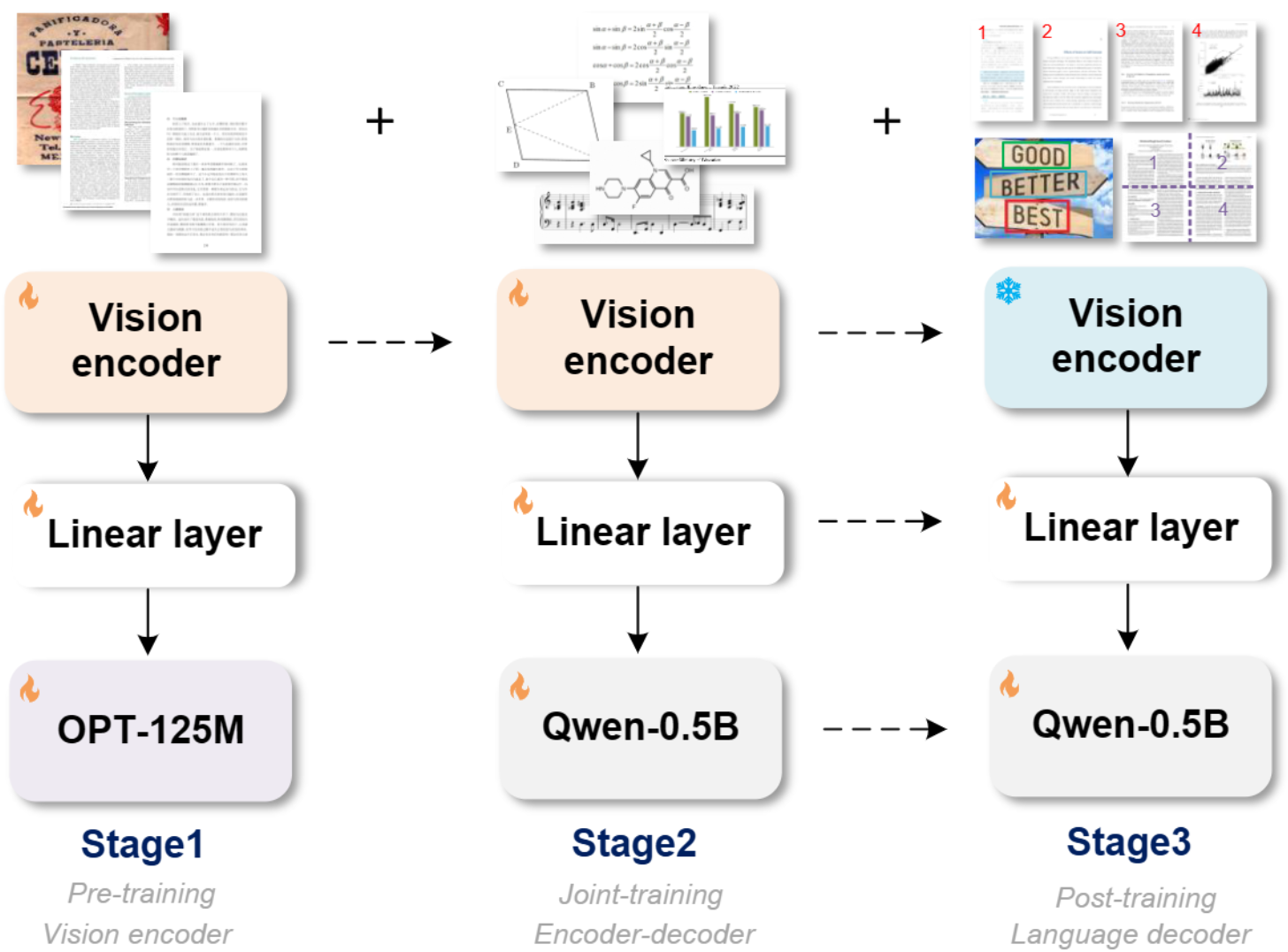
识别效果咋样?
-
文档识别:
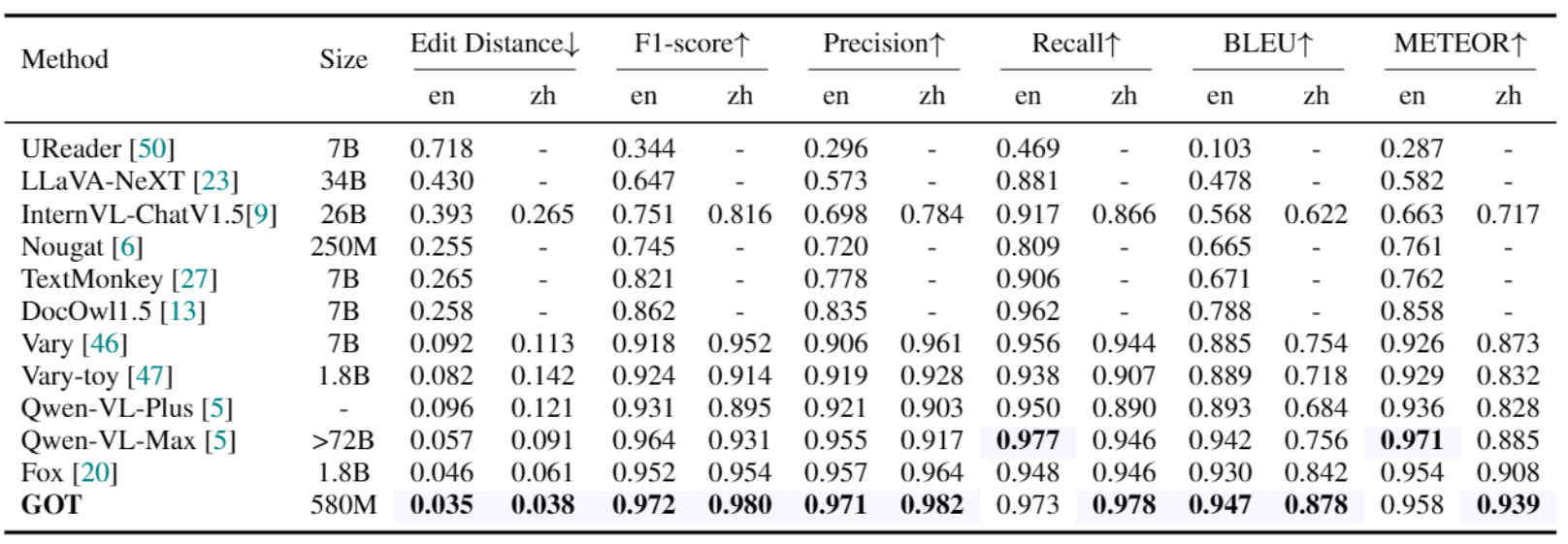
-
场景文字识别
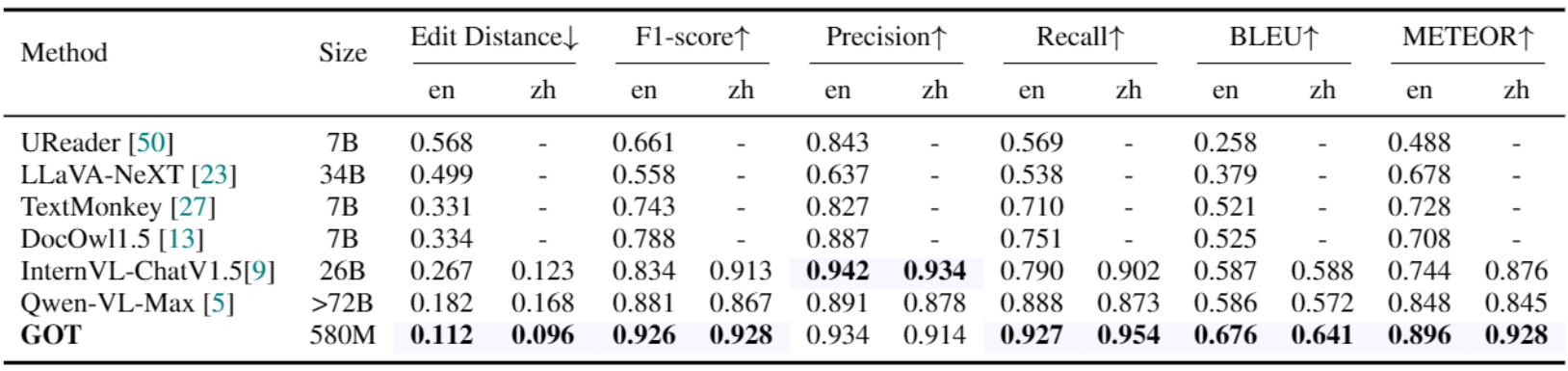
上述两张表:只用了 qwen2:0.5b 这样的小模型,GOT 完爆多模态大模型!

所以:专业的事还得交给专业的模型去做!
既然这么强悍,咱必须本地整起来,实测一番看看。
2. GOT-OCR2.0 本地部署
2.1 环境准备
参考官方,准备好环境:
git clone https://github.com/Ucas-HaoranWei/GOT-OCR2.0.git
cd GOT-OCR2.0/GOT-OCR-2.0-master/
conda create -n got python=3.10 -y
conda activate got
pip install -e .
2.2 模型下载
模型托管在 huggingface 上,国内小伙伴无法下载,可以参考下方代码,用国内镜像下载,并指定本地存放位置:
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download ucaslcl/GOT-OCR2_0 --local-dir ckpts/GOT-OCR2_0
2.3 服务端
我们采用FastAPI 编写服务端代码。
首先,加载模型:
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('ckpts/GOT-OCR2_0', trust_remote_code=True)
model = AutoModel.from_pretrained('ckpts/GOT-OCR2_0', trust_remote_code=True, low_cpu_mem_usage=True, device_map='cuda', use_safetensors=True, pad_token_id=tokenizer.eos_token_id)
model = model.eval().cuda()
然后,定义请求体:
class OcrRequest(BaseModel):
image : str # base64编码的图片
ocr_type : str = 'ocr'
ocr_box: str = None
ocr_color: str = None
render: bool = False
save_render_file: str = None
定义核心功能:
@app.post('/ocr')
async def ocr(request: OcrRequest):
image_data = base64.b64decode(request.image)
ocr_type = request.ocr_type
ocr_box = request.ocr_box
ocr_color = request.ocr_color
render = request.render
save_render_file = request.save_render_file
image_name = f"{time.time()}.jpg"
with open(image_name, 'wb') as f:
f.write(image_data)
res = model.chat(tokenizer, image_name, ocr_type=ocr_type, ocr_box=ocr_box, ocr_color=ocr_color, render=render, save_render_file=save_render_file)
os.remove(image_name)
return res
最后,指定 GPU,启动服务:
export CUDA_VISIBLE_DEVICES=3
nohup uvicorn got_server:app --host 0.0.0.0 --port 3004 > server.log 2>&1 &
大概需要占用 6 G显存:

2.4 客户端
客户端请求,首先需要对图像进行 base64 编码:
def image_to_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
然后,编写请求函数:
def test_api():
image_path = '2.png' # 修改为你的图片路径
base64_image = image_to_base64(image_path)
data = {
"image": f"{base64_image}",
"ocr_type": "ocr"
}
st = time.time()
response = requests.post("http://localhost:3004/ocr", json=data) # 修改为你的API地址
print(f"请求耗时:{time.time() - st}s")
print(response.json())
3. GOT-OCR2.0 案例实测
3.1 高考语文案例测试
在网上找了一段高考语文试卷:

在 GOT-OCR 之前,猴哥一直用的 OCR 工具是百度家的 paddle-ocr,不了解的小伙伴可参考之前的教程:【Python实战】如何优雅地实现文字 & 二维码检测?
所以,我们先来用 paddle-ocr 测试下,结果如下:
一、选择题(每小题3分,共30分)
1.下列词语中,字形、字音、字义完全正确的一项是:
A.恍然大悟(wu)毕恭毕敬(jing)耳濡目染(ru)
B.恍若隔世(ruo)毕其功于一役(bi)耳熟能详(rén)
C.恍若未闻(wén)毕恭毕敬(jing)耳提面命(ming)
D.恍若身临其境(jing)毕其功于一役(qi)耳濡目染(ru)
你看,paddle-ocr 对标点符号是无法搞定的。
接下来,上 GOT-OCR,结果如下:
一、选择题(每小题 3 分,共 30 分)
1. 下列词语中,字形、字音、字义完全正确的一项是:
A. 恍然大悟(wù) 毕恭毕敬(jìng) 耳濡目染(rú)
B. 恍若隔世(ruò) 毕其功于一役(bì) 耳熟能详(rén)
C. 恍若未闻(wén) 毕恭毕敬(jìng) 耳提面命(mìng)
D. 恍若身临其境(jìng) 毕其功于一役(qí) 耳濡目染(rú)
强啊,所有标点符号无一遗漏。只是,耗时略长,且和图片尺寸强相关。
3.2 小学数学案例测试
我又找了一段小学数学试卷。
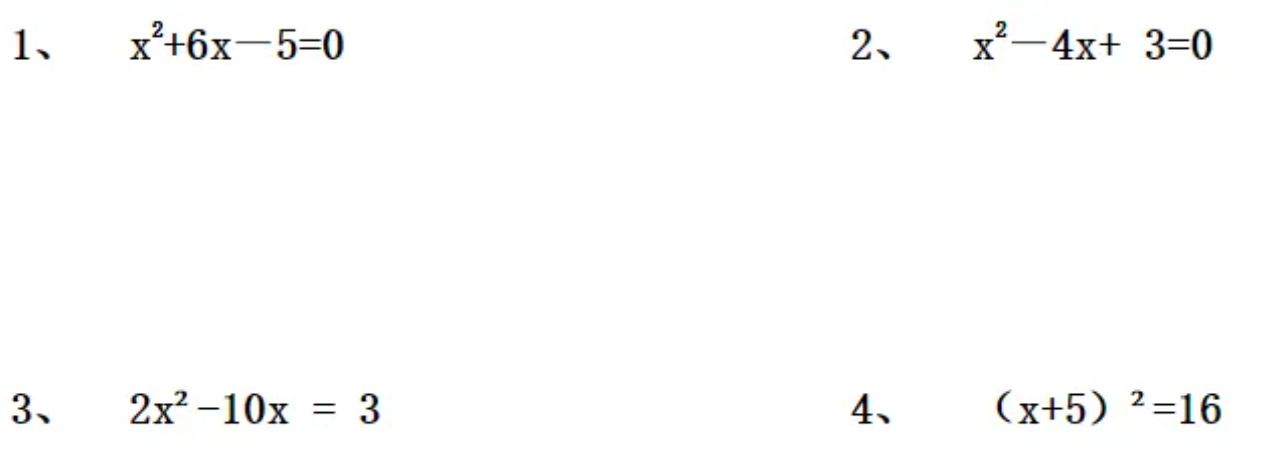
“ocr_type”: “ocr” 代表全文本输出,我们来看看结果:
1、x²+6x-5=0 2、x²-4x+3=0 3、2x²-10x=3 4、 (x+5)²=16
你看,上标全部搞定,这张图片耗时 1.5 s。
当然,如果你希望得到格式化输出,可以指定"ocr_type": “format” 。
在 format 格式下,可以指定渲染成 html,为此,请求体可以定义如下:
data = {
"image": f"{base64_image}", # 添加前缀
"ocr_type": "format",
"render": True,
"save_render_file": '1.html'
}
再来看下输出结果-Latex格式的表格:
\begin{tabular}{llll}
1、 & \(x^{2}+6 x-5=0\) & 2 & \(x^{2}-4 x+3=0\) \\
& & & \\
3、 & \(2 x^{2}-10 x=3\) & 4 & \((x+5)^{2}=16\)
\end{tabular}
渲染生成的 html 如下:
用浏览器打开 html 文件看看,Nice!
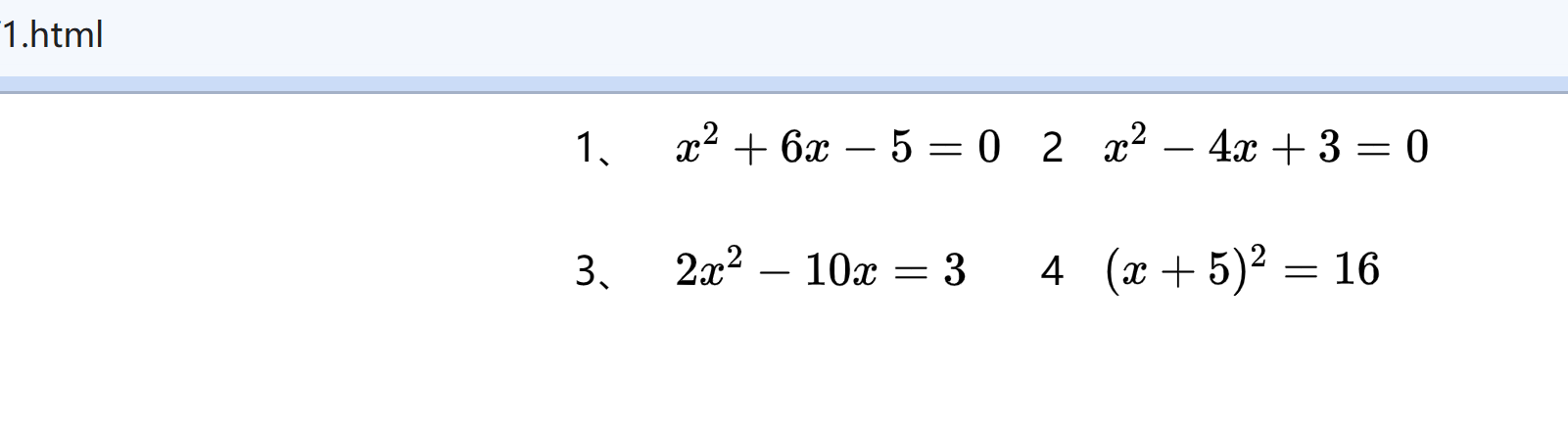
3.2 乐谱案例测试
咱再给它上点难度,在网上找了一段乐谱图片:

这张图片足足耗时 24.8 s,输出结果类似下面这样:
!!!COM:爱我中华
**kern **kern
*clefF4 *clefG2
*k[] *k[]
*M44 *M44
=- =-
2A 2c 2f 4.aa
. 8ff
8A 8c 8f 8ff
8r 4ff
4.A 4.c 4.f .
. 4ff
看得懂么?没关系,大模型能看懂就行:

最后,我们再来看下渲染生成的 html:
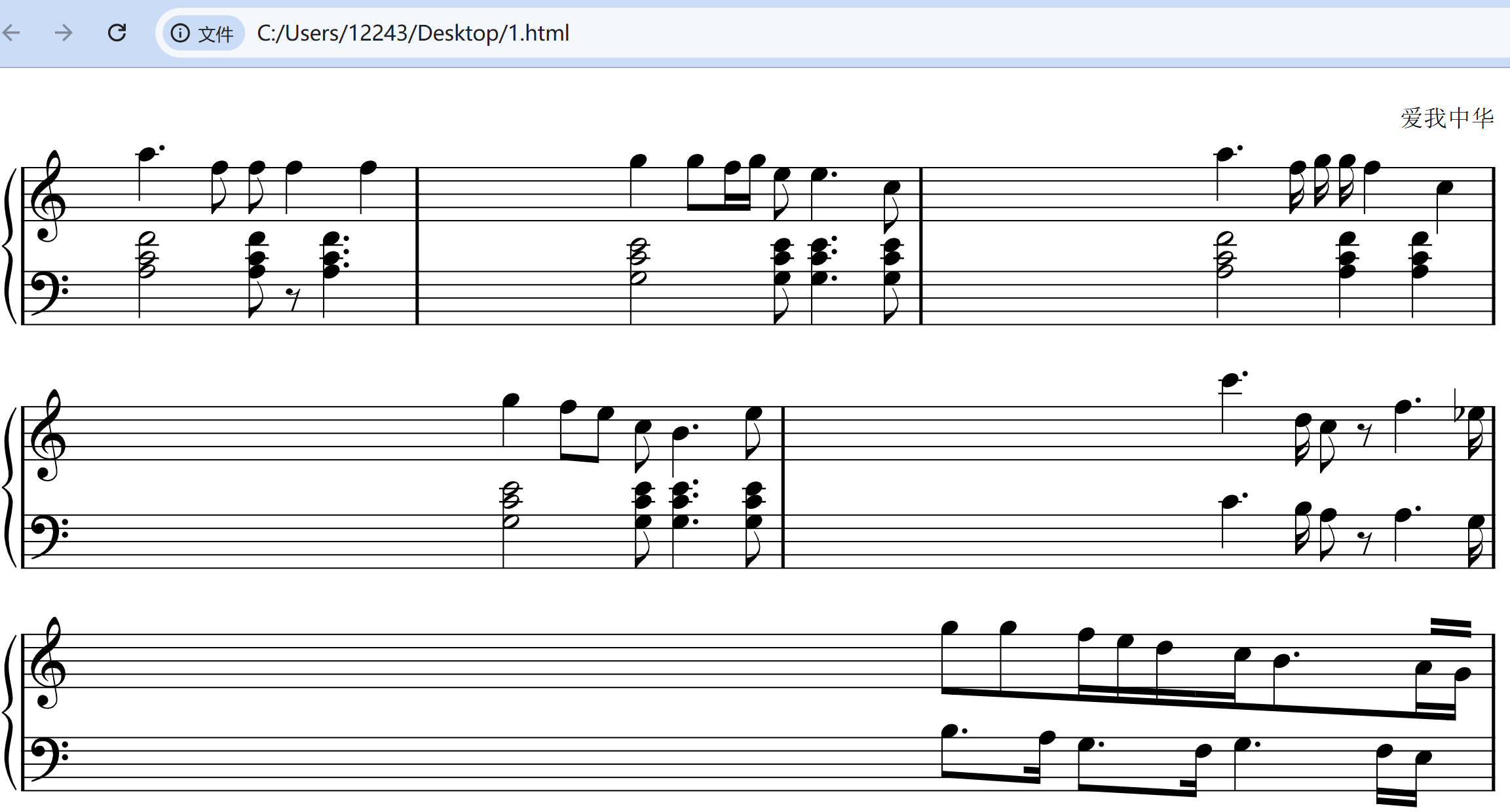
太强了!
当然,GOT 能完成的 OCR 任务还有很多,感兴趣的小伙伴快去试试吧~
写在最后
本文带大家本地部署并实测了将 OCR 带入 2.0 时代的 GOT-OCR。
如果对你有帮助,欢迎点赞收藏备用。
OCR 相当于 LLM 的眼睛,有了专业的读图工具,再结合 LLM,会碰撞出什么火花呢?尽情发挥你的想象吧,我们下期来聊。
为方便大家交流,新建了一个 AI 交流群,欢迎感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,公众号后台「联系我」,拉你进群。