Java XML API
Java XML教程 - Java XML API
SAX API
下面是关键的SAX API的摘要:
| 类 | 用法 |
|---|---|
| SAXParserFactory | 创建由系统属性javax.xml.parsers.SAXParserFactory确定的解析器的实例。 |
| SAXParser | SAXParser接口定义了几个重载的parse()方法。 |
| SAXReader | SAXParser包装一个SAXReader,并从SAXParser的getXMLReader()方法返回。 |
| DefaultHandler | DefaultHandler实现了ContentHandler,ErrorHandler,DTDHandler,和EntityResolver接口。 通过使用DefaultHandler,我们可以只覆盖我们需要的那些。 |
| ContentHandler | 此接口定义回调方法,如startDocument,endDocument,startElement和endElement。 这些方法在识别XML标记时调用。它还定义了被调用的方法characters()当解析器遇到XML元素中的文本时。它定义被调用的processingInstruction()当解析器遇到内联处理指令时。 |
| ErrorHandler | 它使用error(),fatalError()和warning()方法来响应各种解析错误。 默认的错误处理程序只会抛出致命错误和的异常忽略验证错误。 |
| DTDHandler | 用于处理DTD |
| EntityResolver | 它的resolveEntity()方法用于标识数据。 |
我们通常实现大多数 ContentHandler 方法。
为了提供更稳健的实现,我们可以从ErrorHandler实现方法。
SAX包
SAX解析器在下表中列出的软件包中定义。
| 包 | 描述 |
|---|---|
| org.xml.sax | 定义SAX接口。 |
| org.xml.sax.ext | 定义用于更高级SAX处理的SAX扩展。 |
| org.xml.sax.helpers | 定义SAX API的辅助类。 |
| javax.xml.parsers | 定义SAXParserFactory类,它返回SAXParser。 |
DOM API
javax.xml.parsers.DocumentBuilderFactory 类返回一个 DocumentBuilder 实例。
我们使用 DocumentBuilder 实例来产生一个 Document 对象退出XML文档。
构建器由系统属性 javax.xml.parsers.DocumentBuilderFactory 确定。
DocumentBuilder 中的 newDocument()方法可以创建一个实现 org.w3c.dom.Document 接口的空Document。
我们可以使用其中一个构建器的解析方法来创建一个 Document 从现有的XML文档。
DOM包
文档对象模型实现在中定义下表中列出的软件包。
| 包 | 描述 |
|---|---|
| org.w3c.dom | 定义XML文档的DOM编程接口。 |
| javax.xml.parsers | 定义DocumentBuilderFactory类和DocumentBuilder类。 |
XSLT API
TransformerFactory 创建一个 Transformer 对象。
XSLT API在下表中显示的包中定义。
| 包 | 描述 |
|---|---|
| javax.xml.transform | 定义TransformerFactory和Transformer类。 我们可以从变换器对象调用transform()方法来进行变换。 |
| javax.xml.transform.dom | 用于从DOM创建输入和输出对象的类。 |
| javax.xml.transform.sax | 用于从SAX解析器创建输入对象和从SAX事件处理程序输出对象的类。 |
| javax.xml.transform.stream | 用于从I / O流创建输入对象和输出对象的类。 |
StAX APIs
StAX为开发人员提供了SAX和DOM解析器的替代方法。
StAX可以用更少的内存进行高性能流过滤,处理和修改。
StAX是用于流式XML处理的标准的双向拉解析器接口。
StAX提供比SAX更简单的编程模型,并且比DOM更高的内存效率。
StAX可以解析和修改XML流作为事件。
StAX包
StAX APIs在下表中显示的包中定义。
| 包 | 描述 |
|---|---|
| javax.xml.stream | 定义迭代XML文档元素的XMLStreamReader接口。 定义XMLStreamWriter接口,指定如何写入XML。 |
| javax.xml.transform.stax | 提供StAX特定的转换API。 |
Java SAX API简介
Java XML教程 - Java SAX API简介
Java SAX XML解析器代表Simple API for XML(SAX)解析器。
SAX是一种用于访问XML文档的事件驱动的串行访问机制。
此机制经常用于传输和接收XML文档。
SAX是一种状态独立处理,其中元素的处理不依赖于其他元素。StAX是状态相关处理。
SAX是一个事件驱动模型。 当使用SAX解析器时,我们提供了回调方法,并且解析器在读取XML数据时调用它们。
在SAX中,我们不能回到文档的早期部分,我们只能处理元素逐个元素,从开始到结束。
何时使用SAX
SAX是快速和高效的,并且它对于状态无关的过滤是有用的。当遇到元素标记和时,SAX解析器调用一个方法当发现文本时调用不同的方法。
SAX比DOM要求更少的内存,因为SAX不像DOM那样创建XML数据的内部树结构。
使用SAX解析XML文件
在下面我们将看到一个输出所有SAX事件的演示应用程序。它是从包中扩展 DefaultHandler org.xml.sax.helpers 如下。
public class Main extends DefaultHandler {
以下代码设置了解析器并启动它:
SAXParserFactory spf = SAXParserFactory.newInstance();
spf.setNamespaceAware(true);
spf.setValidating(true);
parser = spf.newSAXParser();
parser.parse(file, this);
这些代码行创建一个SAXParserFactory实例,由 javax.xml.parsers.SAXParserFactory 系统属性的设置决定。
工厂被设置为支持XML命名空间将 setNamespaceAware 设置为 true 然后通过 newSAXParser()方法从工厂获取SAXParser实例。
然后它处理开始文档和结束文档事件:
public void startDocument() {
System.out.println("Start document: ");
}
public void endDocument() {
System.out.println("End document: ");
}
之后,它使用 System.out.println 打印消息一旦方法是由解析器调用。
遇到开始标记或结束标记时,根据需要,将标记的名称作为String传递到 startElement 或 endElement 方法。
当遇到开始标记时,它定义的任何属性都会在 Attributes 列表中传递。
public void startElement(String uri, String localName, String qname, Attributes attr) {
System.out.println("Start element: local name: " + localName + " qname: " + qname + " uri: "
+ uri);
}
元素中的字符作为字符数组传递,以及字符数和指向第一个字符的数组的偏移量。
public void characters(char[] ch, int start, int length) {
System.out.println("Characters: " + new String(ch, start, length));
}
完整的代码。
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class Main extends DefaultHandler {
private static Main handler = null;
private SAXParser parser = null;
public static void main(String args[]) {
if (args.length == 0) {
System.out.println("No file to process. Usage is:" + "\njava TrySAX <filename>");
return;
}
File xmlFile = new File(args[0]);
handler = new Main();
handler.process(xmlFile);
}
private void process(File file) {
SAXParserFactory spf = SAXParserFactory.newInstance();
spf.setNamespaceAware(true);
spf.setValidating(true);
System.out.println("Parser will " + (spf.isNamespaceAware() ? "" : "not ")
+ "be namespace aware");
System.out.println("Parser will " + (spf.isValidating() ? "" : "not ") + "validate XML");
try {
parser = spf.newSAXParser();
System.out.println("Parser object is: " + parser);
} catch (SAXException e) {
e.printStackTrace(System.err);
System.exit(1);
} catch (ParserConfigurationException e) {
e.printStackTrace(System.err);
System.exit(1);
}
System.out.println("\nStarting parsing of " + file + "\n");
try {
parser.parse(file, this);
} catch (IOException e) {
e.printStackTrace(System.err);
} catch (SAXException e) {
e.printStackTrace(System.err);
}
}
public void startDocument() {
System.out.println("Start document: ");
}
public void endDocument() {
System.out.println("End document: ");
}
public void startElement(String uri, String localName, String qname, Attributes attr) {
System.out.println("Start element: local name: " + localName + " qname: " + qname + " uri: "
+ uri);
}
public void endElement(String uri, String localName, String qname) {
System.out.println("End element: local name: " + localName + " qname: " + qname + " uri: "
+ uri);
}
public void characters(char[] ch, int start, int length) {
System.out.println("Characters: " + new String(ch, start, length));
}
public void ignorableWhitespace(char[] ch, int start, int length) {
System.out.println("Ignorable whitespace: " + new String(ch, start, length));
}
}
上面的代码生成以下结果。

错误处理程序
解析器可以生成三种错误:
- 致命错误
- 错误
- 警告
当发生致命错误时,解析器无法继续。
对于非致命错误和警告,默认错误处理程序不会生成异常,也不会显示任何消息。
下面的行安装我们自己的错误处理程序。
reader.setErrorHandler(new MyErrorHandler());
MyErrorHandler 类实现标准 org.xml.sax.ErrorHandler 接口,并定义一种方法来获取任何SAXParseException提供的异常信息。
完整的代码。
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.ErrorHandler;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import org.xml.sax.XMLReader;
class MyErrorHandler implements ErrorHandler {
public void warning(SAXParseException e) throws SAXException {
show("Warning", e);
throw (e);
}
public void error(SAXParseException e) throws SAXException {
show("Error", e);
throw (e);
}
public void fatalError(SAXParseException e) throws SAXException {
show("Fatal Error", e);
throw (e);
}
private void show(String type, SAXParseException e) {
System.out.println(type + ": " + e.getMessage());
System.out.println("Line " + e.getLineNumber() + " Column " + e.getColumnNumber());
System.out.println("System ID: " + e.getSystemId());
}
}
// Installation and Use of an Error Handler in a SAX Parser
public class SAXCheck {
static public void main(String[] arg) throws Exception {
boolean validate = false;
validate = true;
SAXParserFactory spf = SAXParserFactory.newInstance();
spf.setValidating(validate);
XMLReader reader = null;
SAXParser parser = spf.newSAXParser();
reader = parser.getXMLReader();
reader.setErrorHandler(new MyErrorHandler());
InputSource is = new InputSource("test.xml");
reader.parse(is);
}
}
XML模式验证
我们可以在使用SAXParser解析期间打开XML模式验证。
import java.io.File;
import javax.xml.XMLConstants;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import javax.xml.validation.Schema;
import javax.xml.validation.SchemaFactory;
public class Main {
public static void main(String args[]) throws Exception {
String language = XMLConstants.W3C_XML_SCHEMA_NS_URI;
SchemaFactory factory = SchemaFactory.newInstance(language);
Schema schema = factory.newSchema(new File("yourSchema"));
SAXParserFactory spf = SAXParserFactory.newInstance();
spf.setSchema(schema);
SAXParser parser = spf.newSAXParser();
// parser.parse(...);
}
}
DefaultHandler
以下代码显示了当使用DefaultHandler时我们不需要实现所有的方法,我们只需要提供实现我们关心的方法。
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class Main {
public static void main(String args[]) throws Exception {
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
DefaultHandler handler = new DefaultHandler() {
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
System.out.println(qName);
}
public void characters(char ch[], int start, int length)
throws SAXException {
System.out.println(new String(ch, start, length));
}
};
saxParser.parse(args[0], handler);
}
}
以下代码通过覆盖DefaultHandler中的错误处理程序方法来处理SAX错误
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import org.xml.sax.helpers.DefaultHandler;
public class Main {
public static void main(String[] argv) throws Exception {
SAXParserFactory factory = SAXParserFactory.newInstance();
factory.setValidating(true);
SAXParser parser = factory.newSAXParser();
SaxHandler handler = new SaxHandler();
parser.parse("sample.xml", handler);
}
}
class SaxHandler extends DefaultHandler {
public void startElement(String uri, String localName, String qName, Attributes attrs)
throws SAXException {
if (qName.equals("order")) {
}
}
public void error(SAXParseException ex) throws SAXException {
System.out.println("ERROR: [at " + ex.getLineNumber() + "] " + ex);
}
public void fatalError(SAXParseException ex) throws SAXException {
System.out.println("FATAL_ERROR: [at " + ex.getLineNumber() + "] " + ex);
}
public void warning(SAXParseException ex) throws SAXException {
System.out.println("WARNING: [at " + ex.getLineNumber() + "] " + ex);
}
}
ContentHandler
下面的代码选择实现 ContentHandler 接口并提供所有必要方法的实现。
它还实现 ErrorHandler 接口。
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.ErrorHandler;
import org.xml.sax.InputSource;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import org.xml.sax.XMLReader;
public class Main {
static public void main(String[] arg) throws Exception {
String filename = "yourXML.xml";
// Create a new factory that will create the parser.
SAXParserFactory spf = SAXParserFactory.newInstance();
// Create the XMLReader to be used to parse the document.
SAXParser parser = spf.newSAXParser();
XMLReader reader = parser.getXMLReader();
// Specify the error handler and the content handler.
reader.setErrorHandler(new MyErrorHandler());
reader.setContentHandler(new MyContentHandler());
// Use the XMLReader to parse the entire file.
InputSource is = new InputSource(filename);
reader.parse(is);
}
}
class MyContentHandler implements ContentHandler {
private Locator locator;
/**
* The name and of the SAX document and the current location within the
* document.
*/
public void setDocumentLocator(Locator locator) {
this.locator = locator;
System.out.println("-" + locator.getLineNumber() + "---Document ID: "
+ locator.getSystemId());
}
/** The parsing of a document has started.. */
public void startDocument() {
System.out.println("-" + locator.getLineNumber()
+ "---Document parse started");
}
/** The parsing of a document has completed.. */
public void endDocument() {
System.out.println("-" + locator.getLineNumber()
+ "---Document parse ended");
}
/** The start of a namespace scope */
public void startPrefixMapping(String prefix, String uri) {
System.out.println("-" + locator.getLineNumber()
+ "---Namespace scope begins");
System.out.println(" " + prefix + "=\"" + uri + "\"");
}
/** The end of a namespace scope */
public void endPrefixMapping(String prefix) {
System.out.println("-" + locator.getLineNumber()
+ "---Namespace scope ends");
System.out.println(" " + prefix);
}
/** The opening tag of an element. */
public void startElement(String namespaceURI, String localName, String qName,
Attributes atts) {
System.out.println("-" + locator.getLineNumber()
+ "---Opening tag of an element");
System.out.println(" Namespace: " + namespaceURI);
System.out.println(" Local name: " + localName);
System.out.println(" Qualified name: " + qName);
for (int i = 0; i < atts.getLength(); i++) {
System.out.println(" Attribute: " + atts.getQName(i) + "=\""
+ atts.getValue(i) + "\"");
}
}
/** The closing tag of an element. */
public void endElement(String namespaceURI, String localName, String qName) {
System.out.println("-" + locator.getLineNumber()
+ "---Closing tag of an element");
System.out.println(" Namespace: " + namespaceURI);
System.out.println(" Local name: " + localName);
System.out.println(" Qualified name: " + qName);
}
/** Character data. */
public void characters(char[] ch, int start, int length) {
System.out.println("-" + locator.getLineNumber() + "---Character data");
showCharacters(ch, start, length);
}
/** Ignorable whitespace character data. */
public void ignorableWhitespace(char[] ch, int start, int length) {
System.out.println("-" + locator.getLineNumber() + "---Whitespace");
showCharacters(ch, start, length);
}
/** Processing Instruction */
public void processingInstruction(String target, String data) {
System.out.println("-" + locator.getLineNumber()
+ "---Processing Instruction");
System.out.println(" Target: " + target);
System.out.println(" Data: " + data);
}
/** A skipped entity. */
public void skippedEntity(String name) {
System.out.println("-" + locator.getLineNumber() + "---Skipped Entity");
System.out.println(" Name: " + name);
}
/**
* Internal method to format arrays of characters so the special whitespace
* characters will show.
*/
public void showCharacters(char[] ch, int start, int length) {
System.out.print(" \"");
for (int i = start; i < start + length; i++)
switch (ch[i]) {
case "\n":
System.out.print("\\n");
break;
case "\r":
System.out.print("\\r");
break;
case "\t":
System.out.print("\\t");
break;
default:
System.out.print(ch[i]);
break;
}
System.out.println("\"");
}
}
class MyErrorHandler implements ErrorHandler {
public void warning(SAXParseException e) throws SAXException {
show("Warning", e);
throw (e);
}
public void error(SAXParseException e) throws SAXException {
show("Error", e);
throw (e);
}
public void fatalError(SAXParseException e) throws SAXException {
show("Fatal Error", e);
throw (e);
}
private void show(String type, SAXParseException e) {
System.out.println(type + ": " + e.getMessage());
System.out.println("Line " + e.getLineNumber() + " Column "
+ e.getColumnNumber());
System.out.println("System ID: " + e.getSystemId());
}
}
定位器
以下代码显示了如何从DefaultHandler访问Locator接口。
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class Main{
public static void main(String[] args) throws Exception {
SAXParserFactory factory = SAXParserFactory.newInstance();
factory.setValidating(true);
SAXParser parser = factory.newSAXParser();
parser.parse("sample.xml", new SampleOfXmlLocator());
}
}
class SampleOfXmlLocator extends DefaultHandler {
private Locator locator;
public void setDocumentLocator(Locator locator) {
this.locator = locator;
}
public void startElement(String uri, String localName, String qName, Attributes attrs)
throws SAXException {
if (qName.equals("order")) {
System.out.println("here process element start");
} else {
String location = "";
if (locator != null) {
location = locator.getSystemId(); // XML-document name;
location += " line " + locator.getLineNumber();
location += ", column " + locator.getColumnNumber();
location += ": ";
}
throw new SAXException(location + "Illegal element");
}
}
}
Java DOM简介
Java XML教程 - Java DOM简介
DOM是标准的树结构,其中每个节点包含来自XML结构的一个组件。
XML文档中两种最常见的节点类型是元素节点和文本节点。
使用Java DOM API,我们可以创建节点,删除节点,更改其内容,并遍历节点层次结构。
何时使用DOM
文档对象模型标准是为XML文档操作而设计的。
DOM的用意是语言无关的。Java的DOM解析器没有利用Java的面向对象的特性优势。
混合内容模型
文本和元素在DOM层次结构中混合。这种结构在DOM模型中称为混合内容。
例如,我们有以下xml结构:
<yourTag>This is an <bold>important</bold> test.</yourTag>
DOM节点的层级如下,其中每行代表一个节点:
ELEMENT: yourTag
+ TEXT: This is an
+ ELEMENT: bold
+ TEXT: important
+ TEXT: test.
yourTag 元素包含文本,后跟一个子元素,后跟另外的文本。
节点类型
为了支持混合内容,DOM节点非常简单。标签元素的“内容"标识它是的节点的类型。
例如,<yourTag> 节点内容是元素 yourTag的名称。
DOM节点API定义 nodeValue(), nodeType()和 nodeName()方法。
对于元素节点< yourTag> nodeName()返回yourTag,而nodeValue()返回null。
对于文本节点 + TEXT:这是一个nodeName()返回#text,nodeValue()返回“This is an"。
例子
以下代码显示了如何使用DOM解析器来解析xml文件并获取一个 org.w3c.dom.Document 对象。
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
public class Main {
public static void main(String[] args) throws Exception {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = null;
db = dbf.newDocumentBuilder();
Document doc = db.parse(new File("games.xml"));
}
}
例2
以下代码显示如何执行DOM转储。
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.ErrorHandler;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
public class Main{
static public void main(String[] arg) throws Exception{
String filename = "input.xml";
boolean validate = true;
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setValidating(validate);
dbf.setNamespaceAware(true);
dbf.setIgnoringElementContentWhitespace(true);
DocumentBuilder builder = dbf.newDocumentBuilder();
builder.setErrorHandler(new MyErrorHandler());
InputSource is = new InputSource(filename);
Document doc = builder.parse(is);
TreeDumper td = new TreeDumper();
td.dump(doc);
}
}
class TreeDumper {
public void dump(Document doc) {
dumpLoop((Node)doc,"");
}
private void dumpLoop(Node node,String indent) {
switch(node.getNodeType()) {
case Node.CDATA_SECTION_NODE:
System.out.println(indent + "CDATA_SECTION_NODE");
break;
case Node.COMMENT_NODE:
System.out.println(indent + "COMMENT_NODE");
break;
case Node.DOCUMENT_FRAGMENT_NODE:
System.out.println(indent + "DOCUMENT_FRAGMENT_NODE");
break;
case Node.DOCUMENT_NODE:
System.out.println(indent + "DOCUMENT_NODE");
break;
case Node.DOCUMENT_TYPE_NODE:
System.out.println(indent + "DOCUMENT_TYPE_NODE");
break;
case Node.ELEMENT_NODE:
System.out.println(indent + "ELEMENT_NODE");
break;
case Node.ENTITY_NODE:
System.out.println(indent + "ENTITY_NODE");
break;
case Node.ENTITY_REFERENCE_NODE:
System.out.println(indent + "ENTITY_REFERENCE_NODE");
break;
case Node.NOTATION_NODE:
System.out.println(indent + "NOTATION_NODE");
break;
case Node.PROCESSING_INSTRUCTION_NODE:
System.out.println(indent + "PROCESSING_INSTRUCTION_NODE");
break;
case Node.TEXT_NODE:
System.out.println(indent + "TEXT_NODE");
break;
default:
System.out.println(indent + "Unknown node");
break;
}
NodeList list = node.getChildNodes();
for(int i=0; i<list.getLength(); i++)
dumpLoop(list.item(i),indent + " ");
}
}
class MyErrorHandler implements ErrorHandler {
public void warning(SAXParseException e) throws SAXException {
show("Warning", e);
throw (e);
}
public void error(SAXParseException e) throws SAXException {
show("Error", e);
throw (e);
}
public void fatalError(SAXParseException e) throws SAXException {
show("Fatal Error", e);
throw (e);
}
private void show(String type, SAXParseException e) {
System.out.println(type + ": " + e.getMessage());
System.out.println("Line " + e.getLineNumber() + " Column "
+ e.getColumnNumber());
System.out.println("System ID: " + e.getSystemId());
}
}
错误处理程序
以下代码显示了如何在使用DOM解析器解析XML时处理错误。
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.xml.sax.ErrorHandler;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
public class DOMCheck {
static public void main(String[] arg) {
boolean validate = true;
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setValidating(validate);
dbf.setNamespaceAware(true);
try {
DocumentBuilder builder = dbf.newDocumentBuilder();
builder.setErrorHandler(new MyErrorHandler());
InputSource is = new InputSource("person.xml");
Document doc = builder.parse(is);
} catch (SAXException e) {
System.out.println(e);
} catch (ParserConfigurationException e) {
System.err.println(e);
} catch (IOException e) {
System.err.println(e);
}
}
}
class MyErrorHandler implements ErrorHandler {
public void warning(SAXParseException e) throws SAXException {
show("Warning", e);
throw (e);
}
public void error(SAXParseException e) throws SAXException {
show("Error", e);
throw (e);
}
public void fatalError(SAXParseException e) throws SAXException {
show("Fatal Error", e);
throw (e);
}
private void show(String type, SAXParseException e) {
System.out.println(type + ": " + e.getMessage());
System.out.println("Line " + e.getLineNumber() + " Column " + e.getColumnNumber());
System.out.println("System ID: " + e.getSystemId());
}
}
例3
以下代码显示了如何递归访问DOM树中的所有节点。
import java.io.File;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class Main {
public static void main(String[] argv) throws Exception{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setValidating(true);
factory.setExpandEntityReferences(false);
Document doc = factory.newDocumentBuilder().parse(new File("file.xml"));
visit(doc, 0);
}
public static void visit(Node node, int level) {
NodeList list = node.getChildNodes();
for (int i = 0; i < list.getLength(); i++) {
Node childNode = list.item(i);
visit(childNode, level + 1);
}
}
}
例4
下面的代码显示了如何将XML片段转换为DOM片段。
import java.io.File;
import java.io.StringReader;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.DocumentFragment;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.xml.sax.InputSource;
public class Main {
public static void main(String[] argv) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setValidating(true);
Document doc = factory.newDocumentBuilder().parse(new File("infilename.xml"));
String fragment = "<fragment>aaa</fragment>";
factory = DocumentBuilderFactory.newInstance();
Document d = factory.newDocumentBuilder().parse(new InputSource(new StringReader(fragment)));
Node node = doc.importNode(d.getDocumentElement(), true);
DocumentFragment docfrag = doc.createDocumentFragment();
while (node.hasChildNodes()) {
docfrag.appendChild(node.removeChild(node.getFirstChild()));
}
Element element = doc.getDocumentElement();
element.appendChild(docfrag);
}
}
例5
下面的代码显示了如何解析XML字符串:使用DOM和StringReader。
import java.io.StringReader;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.CharacterData;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
public class Main {
public static void main(String arg[]) throws Exception{
String xmlRecords = "<data><employee><name>A</name>"
+ "<title>Manager</title></employee></data>";
DocumentBuilder db = DocumentBuilderFactory.newInstance().newDocumentBuilder();
InputSource is = new InputSource();
is.setCharacterStream(new StringReader(xmlRecords));
Document doc = db.parse(is);
NodeList nodes = doc.getElementsByTagName("employee");
for (int i = 0; i < nodes.getLength(); i++) {
Element element = (Element) nodes.item(i);
NodeList name = element.getElementsByTagName("name");
Element line = (Element) name.item(0);
System.out.println("Name: " + getCharacterDataFromElement(line));
NodeList title = element.getElementsByTagName("title");
line = (Element) title.item(0);
System.out.println("Title: " + getCharacterDataFromElement(line));
}
}
public static String getCharacterDataFromElement(Element e) {
Node child = e.getFirstChild();
if (child instanceof CharacterData) {
CharacterData cd = (CharacterData) child;
return cd.getData();
}
return "";
}
}
上面的代码生成以下结果。

Java DOM编辑
Java XML教程 - Java DOM编辑
属性
以下代码显示如何向元素添加属性。
import java.io.StringWriter;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.DOMImplementation;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class Main {
public static void main(String[] argv) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
DOMImplementation impl = builder.getDOMImplementation();
Document doc = impl.createDocument(null, null, null);
Element e1 = doc.createElement("api");
doc.appendChild(e1);
Element e2 = doc.createElement("java");
e1.appendChild(e2);
e2.setAttribute("url", "http://www.www.w3cschool.cn");
//transform the DOM for showing the result in console
DOMSource domSource = new DOMSource(doc);
Transformer transformer = TransformerFactory.newInstance().newTransformer();
transformer.setOutputProperty(OutputKeys.OMIT_XML_DECLARATION, "yes");
transformer.setOutputProperty(OutputKeys.METHOD, "xml");
transformer.setOutputProperty(OutputKeys.ENCODING, "ISO-8859-1");
transformer.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "4");
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
StringWriter sw = new StringWriter();
StreamResult sr = new StreamResult(sw);
transformer.transform(domSource, sr);
System.out.println(sw.toString());
}
}
上面的代码生成以下结果。

复制属性
public void dupAttributes(Document doc) {
Element root = doc.getDocumentElement();
Element personOne = (Element)root.getFirstChild();
Element personTwo = (Element)personOne.getNextSibling();
Element personThree = (Element)personTwo.getNextSibling();
Attr deptAttr = personOne.getAttributeNode("dept");
personOne.removeAttributeNode(deptAttr);
String deptString = deptAttr.getValue();
personTwo.setAttribute("dept",deptString);
personThree.setAttribute("dept",deptString);
String mailString = personOne.getAttribute("mail");
personTwo.setAttribute("mail",mailString);
String titleString = personOne.getAttribute("title");
personOne.removeAttribute("title");
personThree.setAttribute("title",titleString);
}
删除两个属性
public void delAttribute(Document doc) {
Element root = doc.getDocumentElement();
Element person = (Element)root.getFirstChild();
person.removeAttribute("extension");
person.removeAttribute("dept");
}
元素
import java.io.StringWriter;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.DOMImplementation;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
public class Main {
public static void main(String[] argv) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
DOMImplementation impl = builder.getDOMImplementation();
Document doc = impl.createDocument(null, null, null);
Node root = doc.createElement("A");
doc.appendChild(root);
Node stanza = doc.createElement("B");
root.appendChild(stanza);
Node line = doc.createElement("C");
stanza.appendChild(line);
line.appendChild(doc.createTextNode("test"));
line = doc.createElement("Line");
stanza.appendChild(line);
line.appendChild(doc.createTextNode("test"));
//transform the DOM for showing the result in console
DOMSource domSource = new DOMSource(doc);
Transformer transformer = TransformerFactory.newInstance().newTransformer();
transformer.setOutputProperty(OutputKeys.OMIT_XML_DECLARATION, "yes");
transformer.setOutputProperty(OutputKeys.METHOD, "xml");
transformer.setOutputProperty(OutputKeys.ENCODING, "ISO-8859-1");
transformer.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "4");
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
StringWriter sw = new StringWriter();
StreamResult sr = new StreamResult(sw);
transformer.transform(domSource, sr);
System.out.println(sw.toString());
}
}
上面的代码生成以下结果。

以下代码显示如何从父代删除元素。
public void deleteFirstElement(Document doc) {
Element root = doc.getDocumentElement();
Element child = (Element)root.getFirstChild();
root.removeChild(child);
}
文本节点
以下代码显示如何向元素添加文本节点。
import java.io.StringWriter;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.bootstrap.DOMImplementationRegistry;
import org.w3c.dom.ls.DOMImplementationLS;
import org.w3c.dom.ls.LSOutput;
import org.w3c.dom.ls.LSSerializer;
public class Main {
public static void main(String[] argv) throws Exception {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setNamespaceAware(true);
DocumentBuilder db = dbf.newDocumentBuilder();
Document doc = db.newDocument();
Element root = doc.createElementNS(null, "person"); // Create Root Element
Element item = doc.createElementNS(null, "name"); // Create element
item.appendChild(doc.createTextNode("Jeff"));
root.appendChild(item); // Attach element to Root element
item = doc.createElementNS(null, "age"); // Create another Element
item.appendChild(doc.createTextNode("28"));
root.appendChild(item); // Attach Element to previous element down tree
item = doc.createElementNS(null, "height");
item.appendChild(doc.createTextNode("1.80"));
root.appendChild(item); // Attach another Element - grandaugther
doc.appendChild(root); // Add Root to Document
DOMImplementationRegistry registry = DOMImplementationRegistry
.newInstance();
DOMImplementationLS domImplLS = (DOMImplementationLS) registry
.getDOMImplementation("LS");
LSSerializer ser = domImplLS.createLSSerializer(); // Create a serializer
// for the DOM
LSOutput out = domImplLS.createLSOutput();
StringWriter stringOut = new StringWriter(); // Writer will be a String
out.setCharacterStream(stringOut);
ser.write(doc, out); // Serialize the DOM
System.out.println("STRXML = " + stringOut.toString()); // DOM as a String
}
}
上面的代码生成以下结果。
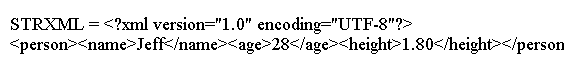
以下代码显示了如何通过插入和替换编辑文本。
public void edit3(Document doc) {
int count;
int offset;
Element root = doc.getDocumentElement();
Element place = (Element)root.getFirstChild();
Text name = (Text)place.getFirstChild().getFirstChild();
Text directions = (Text)place.getLastChild().getFirstChild();
offset = 7;
name.insertData(offset," black");
offset = 5;
count = 4;
directions.replaceData(offset,count,"right");
}
通过剪切和粘贴修改文本
public void edit(Document doc) {
int length;
int count;
int offset;
Element root = doc.getDocumentElement();
Element place = (Element)root.getFirstChild();
Text name = (Text)place.getFirstChild().getFirstChild();
Text directions = (Text)place.getLastChild().getFirstChild();
length = name.getLength();
count = 4;
offset = length - 4;
name.deleteData(offset,count);
length = directions.getLength();
count = 6;
offset = length - count;
String bridge = directions.substringData(offset,count);
name.appendData(bridge);
count = 5;
offset = 4;
directions.deleteData(offset,count);
}
通过替换修改文本
public void edit(Document doc) {
Element root = doc.getDocumentElement();
Element place = (Element)root.getFirstChild();
Text name = (Text)place.getFirstChild().getFirstChild();
Text directions = (Text)place.getLastChild().getFirstChild();
name.setData("AAA");
directions.setData("BBB");
}
注释
以下代码显示如何为XML创建注释节点。
import java.io.File;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Comment;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class Main {
public static void main(String[] argv) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setValidating(true);
factory.setExpandEntityReferences(false);
Document doc = factory.newDocumentBuilder().parse(new File("filename"));
Element element = doc.getDocumentElement();
Comment comment = doc.createComment("A Document Comment");
element.getParentNode().insertBefore(comment, element);
}
}
处理指令
下面的代码显示了如何添加ProcessingInstruction。
public void addProcessingInstruction(Document doc) {
Element root = doc.getDocumentElement();
Element folks = (Element)root.getLastChild();
ProcessingInstruction pi;
pi = (ProcessingInstruction)doc.createProcessingInstruction(
"validate",
"phone=\"lookup\"");
root.insertBefore(pi,folks);
}
CDATA
以下代码显示如何添加CDATA到XML文档。
public void addCDATA(Document doc) {
Element root = doc.getDocumentElement();
Element place = (Element)root.getFirstChild();
Element directions = (Element)place.getLastChild();
String dirtext =
">>>\n" +
"<<<\n" +
"&&&\n" +
"<><><>.";
CDATASection dirdata = doc.createCDATASection(dirtext);
directions.replaceChild(dirdata,directions.getFirstChild());
}
克隆
public void duplicatePerson(Document doc) {
Element root = doc.getDocumentElement();
Element origPerson = (Element)root.getFirstChild();
Element newPerson = (Element)origPerson.cloneNode(true);
root.appendChild(newPerson);
}
Java XSLT
Java XML教程 - Java XSLT
可扩展样式表语言转换(XSLT)标准定义类,用于使用XPath寻址XML数据和进行转换数据以其他形式。
JAXP包括XSLT的解释实现。
XSL,XSLT和XPath
可扩展样式表语言(XSL)有三个主要子组件:
| 组件 | 描述 |
|---|---|
| XSL-FO | 格式化对象标准。 我们可以定义字体大小,页面布局和对象呈现的其他方面。 |
| XSLT | 它定义了从XML到其他格式的转换。例如,使用XSLT从XML文档生成HTML。 |
| XPath | XPath是一种规范语言,我们可以用它来创建一个元素的路径。 |
JAXP转换包
以下是对JAXP Transformation API的包的描述:
| 包 | 描述 |
|---|---|
| javax.xml.transform | 这个包定义了返回Transformer对象的工厂类。 我们可以使用输入和输出对象配置Transformer,并调用其transform()方法来执行转换。 |
| javax.xml.transform.dom | 定义DOMSource和DOMResult类,用于将DOM用作转换中的输入或输出。 |
| javax.xml.transform.sax | 定义SAXSource和SAXResult类,用于在转换中使用SAX作为输入或输出。 |
| javax.xml.transform.stream | 定义StreamSource和StreamResult类,以将I/O流用作转换的输入或输出。 |
XPath表达式指定用于选择一组XML节点的模式。
XSLT模板可以使用这些模式来选择节点并应用转换。
使用XPath表达式,我们可以引用元素的文本和属性。XPath规范定义了七种类型的节点:
- 根
- 元素
- 文本
- 属性
- 注释
- 处理指令
- 命名空间
XPath寻址
XML文档是树结构的节点集合。
XPath使用路径符号在XML中寻址节点。
-
正斜杠/是路径分隔符。
- 文档根目录的绝对路径以/开头。
- 相对路径可以从任何其他开始。
- 双重周期
..表示父节点。 - 单个期间
.表示当前节点。
在XPath /h1/h2 中选择位于h1元素下的所有h2元素。
要选择一个特定的h2元素,我们使用方括号 [] 来索引。
例如, /h1[4]/h2 [5] 将选择第五个 h2 在第四个 h1 元素下。
要引用属性,请在属性名称前加上@符号。例如, @type 是指 type 属性。
h1/@type选择 h1 元素的 type 属性。
XPath表达式
XPath表达式可以使用通配符,运算符及其自身的函数。
表达式 @type="unordered"指定一个属性名为 type ,其值为无序。
表达式 h1[@ type="unordered"] 选择所有 h1 元素其 type 属性值是无序的。
例子
假设我们将电话数据存储在以下XML文档中。
<PHONEBOOK> <PERSON> <NAME>Joe Wang</NAME> <EMAIL>[email protected]</EMAIL> <TELEPHONE>202-999-9999</TELEPHONE> <WEB>www.w3cschool.cn</WEB> </PERSON> <PERSON> <NAME>Karol</name> <EMAIL>[email protected]</EMAIL> <TELEPHONE>306-999-9999</TELEPHONE> <WEB>www.w3cschool.cn</WEB> </PERSON> <PERSON> <NAME>Green</NAME> <EMAIL>[email protected]</EMAIL> <TELEPHONE>202-414-9999</TELEPHONE> <WEB>www.w3cschool.cn</WEB> </PERSON> </PHONEBOOK>
我们将使用以下XSLT将上述XML转换为HTML文件。
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:template match="/"> <html> <head> <title>Directory</title> </head> <body> <table border="1"> <tr> <th>Name</th> <th>Telephone</th> <th>Email</th> </tr> <xsl:for-each select="PHONEBOOK/PERSON"> <xsl:sort/> <tr> <td><xsl:value-of select="NAME"/></td> <td><xsl:value-of select="TELEPHONE"/></td> <td><xsl:value-of select="EMAIL"/></td> </tr> </xsl:for-each> </table> </body> </html> </xsl:template> </xsl:stylesheet>
从上面的代码,我们可以看到数据将被转换为HTML表。
我们使用下面的代码来做转换。
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.stream.StreamResult;
import javax.xml.transform.stream.StreamSource;
public class Main {
public static void main(String args[]) throws Exception {
StreamSource source = new StreamSource(args[0]);
StreamSource stylesource = new StreamSource(args[1]);
TransformerFactory factory = TransformerFactory.newInstance();
Transformer transformer = factory.newTransformer(stylesource);
StreamResult result = new StreamResult(System.out);
transformer.transform(source, result);
}
}
例2
以下代码显示了如何使用Stax解析器转换xml。
import java.io.File;
import java.io.FileInputStream;
import java.io.FileWriter;
import javax.xml.XMLConstants;
import javax.xml.stream.XMLEventReader;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLOutputFactory;
import javax.xml.transform.stream.StreamSource;
import javax.xml.validation.Schema;
import javax.xml.validation.SchemaFactory;
import javax.xml.validation.Validator;
public class Main {
public static void main(String[] args) throws Exception {
SchemaFactory sf = SchemaFactory
.newInstance(XMLConstants.W3C_XML_SCHEMA_NS_URI);
System.out.println("schema factory instance obtained is " + sf);
Schema schema = sf.newSchema(new File(args[0]));
System.out.println("schema obtained is = " + schema);
Validator validator = schema.newValidator();
String fileName = args[1].toString();
String fileName2 = args[2].toString();
javax.xml.transform.Result xmlResult = new javax.xml.transform.stax.StAXResult(
XMLOutputFactory.newInstance().createXMLStreamWriter(
new FileWriter(fileName2)));
javax.xml.transform.Source xmlSource = new javax.xml.transform.stax.StAXSource(
getXMLEventReader(fileName));
validator.validate(new StreamSource(args[1]));
validator.validate(xmlSource, xmlResult);
}
private static XMLEventReader getXMLEventReader(String filename)
throws Exception {
XMLInputFactory xmlif = null;
XMLEventReader xmlr = null;
xmlif = XMLInputFactory.newInstance();
xmlif.setProperty(XMLInputFactory.IS_REPLACING_ENTITY_REFERENCES,
Boolean.TRUE);
xmlif.setProperty(XMLInputFactory.IS_SUPPORTING_EXTERNAL_ENTITIES,
Boolean.FALSE);
xmlif.setProperty(XMLInputFactory.IS_NAMESPACE_AWARE, Boolean.TRUE);
xmlif.setProperty(XMLInputFactory.IS_COALESCING, Boolean.TRUE);
FileInputStream fis = new FileInputStream(filename);
xmlr = xmlif.createXMLEventReader(filename, fis);
return xmlr;
}
}
例3
以下代码使用 DOMSource 作为变换输入。
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Result;
import javax.xml.transform.Source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.xml.sax.InputSource;
public class Main {
public static void main(String[] argv) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new InputSource(new InputStreamReader(new FileInputStream(
"inputFile.xml"))));
Transformer xformer = TransformerFactory.newInstance().newTransformer();
xformer.setOutputProperty(OutputKeys.METHOD, "xml");
xformer.setOutputProperty(OutputKeys.INDENT, "yes");
xformer.setOutputProperty("http://xml.apache.org/xslt;indent-amount", "4");
xformer.setOutputProperty(OutputKeys.OMIT_XML_DECLARATION, "yes");
Source source = new DOMSource(document);
Result result = new StreamResult(new File("result.xml"));
xformer.transform(source, result);
}
}
例4
以下代码显示了如何使用XPath更改特定元素。
import java.io.File;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
public class Main {
public static void main(String[] args) throws Exception {
Document doc = DocumentBuilderFactory.newInstance().newDocumentBuilder().parse(
new InputSource("data.xml"));
XPath xpath = XPathFactory.newInstance().newXPath();
NodeList nodes = (NodeList) xpath.evaluate("//employee/name[text()="old"]", doc,
XPathConstants.NODESET);
for (int idx = 0; idx < nodes.getLength(); idx++) {
nodes.item(idx).setTextContent("new value");
}
Transformer xformer = TransformerFactory.newInstance().newTransformer();
xformer.transform(new DOMSource(doc), new StreamResult(new File("data_new.xml")));
}
}
Java StAX
Java XML教程 - Java StAX
StAX是为了解决SAX和DOM API中的限制而创建的。
StAX API允许我们请求下一个事件(拉动事件),并允许状态以过程方式存储。
XML解析有两种编程模型:流和文档对象模型(DOM)。
DOM模型涉及创建表示整个文档树的内存对象。DOM树可以自由导航。 成本是一个大的内存占用。这对于小文档来说是可以的,但是当文档变得更大时,内存消耗可能会迅速上升。
流是指其中XML数据被串行解析的编程模型。在文档中,我们只能在一个位置查看XML数据。这意味着我们需要在读取XML文档之前知道XML结构。用于XML处理的流模型在存在内存限制时很有用。
拉式解析vs推式解析
当我们想获取(拉取)XML数据时,我们做流式拉解析。
当解析器发送数据时,无论客户端是否准备好使用它,我们都进行流式推送解析。
StAX拉解析器可以过滤XML文档并忽略元素不必要。
StAX是一个双向API,通过它我们可以读取和写入XML文档。 SAX是只读的。
SAX是一个推送API,而StAX是拉式。
例子
此程序演示如何使用StAX解析器。它打印XHTML网页的所有超链接链接。
import java.io.InputStream;
import java.net.URL;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamReader;
public class Main {
public static void main(String[] args) throws Exception {
URL url = new URL("http://www.w3c.org");
InputStream in = url.openStream();
XMLInputFactory factory = XMLInputFactory.newInstance();
XMLStreamReader parser = factory.createXMLStreamReader(in);
while (parser.hasNext()) {
int event = parser.next();
if (event == XMLStreamConstants.START_ELEMENT) {
if (parser.getLocalName().equals("a")) {
String href = parser.getAttributeValue(null, "href");
if (href != null)
System.out.println(href);
}
}
}
}
}
例2
下面的代码显示了如何使用XML流读取器加载XML文档。
import java.io.File;
import java.io.FileInputStream;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamException;
import javax.xml.stream.XMLStreamReader;
public class Main {
public static void main(String[] args) throws Exception {
File file = new File("yourXML.xml");
FileInputStream inputStream = new FileInputStream(file);
XMLInputFactory inputFactory = XMLInputFactory.newInstance();
XMLStreamReader reader = inputFactory.createXMLStreamReader(inputStream);
System.out.println(reader.getVersion());
System.out.println(reader.isStandalone());
System.out.println(reader.standaloneSet());
System.out.println(reader.getEncoding());
System.out.println(reader.getCharacterEncodingScheme());
parseRestOfDocument(reader);
}
private static void parseRestOfDocument(XMLStreamReader reader)
throws XMLStreamException {
while (reader.hasNext()) {
int type = reader.next();
switch (type) {
case XMLStreamConstants.START_ELEMENT:
System.out.println(reader.getLocalName());
if (reader.getNamespaceURI() != null) {
String prefix = reader.getPrefix();
if (prefix == null) {
prefix = "[None]";
}
System.out.println("prefix = "" + prefix + "", URI = ""
+ reader.getNamespaceURI() + """);
}
if (reader.getAttributeCount() > 0) {
for (int i = 0; i < reader.getAttributeCount(); i++) {
System.out.println("Attribute (name = ""
+ reader.getAttributeLocalName(i) + "", value = ""
+ reader.getAttributeValue(i) + "")");
String attURI = reader.getAttributeNamespace(i);
if (attURI != null) {
String attPrefix = reader.getAttributePrefix(i);
if (attPrefix == null || attPrefix.equals("")) {
attPrefix = "[None]";
}
System.out.println("prefix=" + attPrefix + ",URI=" + attURI);
}
}
}
break;
case XMLStreamConstants.END_ELEMENT:
System.out.println("XMLStreamConstants.END_ELEMENT");
break;
case XMLStreamConstants.CHARACTERS:
if (!reader.isWhiteSpace()) {
System.out.println("CD:" + reader.getText());
}
break;
case XMLStreamConstants.DTD:
System.out.println("DTD:" + reader.getText());
break;
case XMLStreamConstants.SPACE:
System.out.println(" ");
break;
case XMLStreamConstants.COMMENT:
System.out.println(reader.getText());
break;
default:
System.out.println(type);
}
}
}
}
XMLStreamWriter
以下代码显示了如何使用 XMLStreamWriter 输出xml。
import javax.xml.stream.XMLOutputFactory;
import javax.xml.stream.XMLStreamWriter;
public class Main {
public static void main(String[] args) throws Exception {
XMLOutputFactory factory = XMLOutputFactory.newInstance();
XMLStreamWriter writer = factory.createXMLStreamWriter(System.out);
writer.writeStartDocument("1.0");
writer.writeStartElement("catalog");
writer.writeStartElement("book");
writer.writeAttribute("id", "1");
writer.writeStartElement("code");
writer.writeCharacters("I01");
writer.writeEndElement();
writer.writeStartElement("title");
writer.writeCharacters("This is the title");
writer.writeEndElement();
writer.writeStartElement("price");
writer.writeCharacters("$2.95");
writer.writeEndElement();
writer.writeEndDocument();
writer.flush();
writer.close();
}
}
上面的代码生成以下结果。
![]()
XMLEventReader
import java.io.FileReader;
import java.io.Reader;
import java.util.Iterator;
import javax.xml.namespace.QName;
import javax.xml.stream.XMLEventReader;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.events.Attribute;
import javax.xml.stream.events.Characters;
import javax.xml.stream.events.EndElement;
import javax.xml.stream.events.StartElement;
import javax.xml.stream.events.XMLEvent;
public class Main {
public static void main(String[] args) throws Exception {
XMLInputFactory factory = XMLInputFactory.newInstance();
Reader fileReader = new FileReader("Source.xml");
XMLEventReader reader = factory.createXMLEventReader(fileReader);
while (reader.hasNext()) {
XMLEvent event = reader.nextEvent();
if (event.isStartElement()) {
StartElement element = (StartElement) event;
System.out.println("Start Element: " + element.getName());
Iterator iterator = element.getAttributes();
while (iterator.hasNext()) {
Attribute attribute = (Attribute) iterator.next();
QName name = attribute.getName();
String value = attribute.getValue();
System.out.println("Attribute name/value: " + name + "/" + value);
}
}
if (event.isEndElement()) {
EndElement element = (EndElement) event;
System.out.println("End element:" + element.getName());
}
if (event.isCharacters()) {
Characters characters = (Characters) event;
System.out.println("Text: " + characters.getData());
}
}
}
}
XMLEventWriter
import java.util.Arrays;
import java.util.List;
import javax.xml.stream.XMLEventFactory;
import javax.xml.stream.XMLEventWriter;
import javax.xml.stream.XMLOutputFactory;
import javax.xml.stream.events.Attribute;
import javax.xml.stream.events.Characters;
import javax.xml.stream.events.EndDocument;
import javax.xml.stream.events.EndElement;
import javax.xml.stream.events.StartDocument;
import javax.xml.stream.events.StartElement;
public class Main {
public static void main(String[] args) throws Exception {
XMLOutputFactory outputFactory = XMLOutputFactory.newInstance();
XMLEventWriter writer = outputFactory.createXMLEventWriter(System.out);
XMLEventFactory xmlEventFactory = XMLEventFactory.newInstance();
StartDocument startDocument = xmlEventFactory.createStartDocument("UTF-8", "1.0");
writer.add(startDocument);
StartElement startElement = xmlEventFactory.createStartElement("", "", "My-list");
writer.add(startElement);
Attribute attribute = xmlEventFactory.createAttribute("version", "1");
List attributeList = Arrays.asList(attribute);
List nsList = Arrays.asList();
StartElement startElement2 = xmlEventFactory.createStartElement("", "", "Item",
attributeList.iterator(), nsList.iterator());
writer.add(startElement2);
StartElement codeSE = xmlEventFactory.createStartElement("", "", "code");
writer.add(codeSE);
Characters codeChars = xmlEventFactory.createCharacters("I001");
writer.add(codeChars);
EndElement codeEE = xmlEventFactory.createEndElement("", "", "code");
writer.add(codeEE);
StartElement nameSE = xmlEventFactory.createStartElement(" ", " ", "name");
writer.add(nameSE);
Characters nameChars = xmlEventFactory.createCharacters("a name");
writer.add(nameChars);
EndElement nameEE = xmlEventFactory.createEndElement("", "", "name");
writer.add(nameEE);
StartElement contactSE = xmlEventFactory.createStartElement("", "", "contact");
writer.add(contactSE);
Characters contactChars = xmlEventFactory.createCharacters("another name");
writer.add(contactChars);
EndElement contactEE = xmlEventFactory.createEndElement("", "", "contact");
writer.add(contactEE);
EndDocument ed = xmlEventFactory.createEndDocument();
writer.add(ed);
writer.flush();
writer.close();
}
}
上面的代码生成以下结果。
![]()
StreamFilter
import java.io.FileInputStream;
import javax.xml.namespace.QName;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamReader;
import javax.xml.stream.events.XMLEvent;
public class Main implements javax.xml.stream.StreamFilter {
public static void main(String[] args) throws Exception {
String filename = "yourXML.xml";
XMLInputFactory xmlif = null;
xmlif = XMLInputFactory.newInstance();
xmlif.setProperty(XMLInputFactory.IS_REPLACING_ENTITY_REFERENCES,
Boolean.TRUE);
xmlif.setProperty(XMLInputFactory.IS_SUPPORTING_EXTERNAL_ENTITIES,
Boolean.FALSE);
xmlif.setProperty(XMLInputFactory.IS_NAMESPACE_AWARE, Boolean.TRUE);
xmlif.setProperty(XMLInputFactory.IS_COALESCING, Boolean.TRUE);
System.out.println("FACTORY: " + xmlif);
System.out.println("filename = " + filename);
FileInputStream fis = new FileInputStream(filename);
XMLStreamReader xmlr = xmlif.createFilteredReader(
xmlif.createXMLStreamReader(fis), new Main());
int eventType = xmlr.getEventType();
printEventType(eventType);
while (xmlr.hasNext()) {
eventType = xmlr.next();
printEventType(eventType);
printName(xmlr, eventType);
printText(xmlr);
if (xmlr.isStartElement()) {
printAttributes(xmlr);
}
printPIData(xmlr);
}
}
public static final String getEventTypeString(int eventType) {
switch (eventType) {
case XMLEvent.START_ELEMENT:
return "START_ELEMENT";
case XMLEvent.END_ELEMENT:
return "END_ELEMENT";
case XMLEvent.PROCESSING_INSTRUCTION:
return "PROCESSING_INSTRUCTION";
case XMLEvent.CHARACTERS:
return "CHARACTERS";
case XMLEvent.COMMENT:
return "COMMENT";
case XMLEvent.START_DOCUMENT:
return "START_DOCUMENT";
case XMLEvent.END_DOCUMENT:
return "END_DOCUMENT";
case XMLEvent.ENTITY_REFERENCE:
return "ENTITY_REFERENCE";
case XMLEvent.ATTRIBUTE:
return "ATTRIBUTE";
case XMLEvent.DTD:
return "DTD";
case XMLEvent.CDATA:
return "CDATA";
}
return "UNKNOWN_EVENT_TYPE";
}
private static void printEventType(int eventType) {
System.out.print("EVENT TYPE(" + eventType + "):");
System.out.println(getEventTypeString(eventType));
}
private static void printName(XMLStreamReader xmlr, int eventType) {
if (xmlr.hasName()) {
System.out.println("HAS NAME: " + xmlr.getLocalName());
} else {
System.out.println("HAS NO NAME");
}
}
private static void printText(XMLStreamReader xmlr) {
if (xmlr.hasText()) {
System.out.println("HAS TEXT: " + xmlr.getText());
} else {
System.out.println("HAS NO TEXT");
}
}
private static void printPIData(XMLStreamReader xmlr) {
if (xmlr.getEventType() == XMLEvent.PROCESSING_INSTRUCTION) {
System.out.println(" PI target = " + xmlr.getPITarget());
System.out.println(" PI Data = " + xmlr.getPIData());
}
}
private static void printAttributes(XMLStreamReader xmlr) {
if (xmlr.getAttributeCount() > 0) {
System.out.println("\nHAS ATTRIBUTES: ");
int count = xmlr.getAttributeCount();
for (int i = 0; i < count; i++) {
QName name = xmlr.getAttributeName(i);
String namespace = xmlr.getAttributeNamespace(i);
String type = xmlr.getAttributeType(i);
String prefix = xmlr.getAttributePrefix(i);
String value = xmlr.getAttributeValue(i);
System.out.println("ATTRIBUTE-PREFIX: " + prefix);
System.out.println("ATTRIBUTE-NAMESP: " + namespace);
System.out.println("ATTRIBUTE-NAME: " + name.toString());
System.out.println("ATTRIBUTE-VALUE: " + value);
System.out.println("ATTRIBUTE-TYPE: " + type);
}
} else {
System.out.println("HAS NO ATTRIBUTES");
}
}
public boolean accept(XMLStreamReader reader) {
if (!reader.isStartElement() && !reader.isEndElement()) {
return false;
} else {
return true;
}
}
}